ARIZE MACHINE LEARNING COURSE
 The Fundamentals
The Fundamentals
Top Service Monitoring Metrics

Co-authored by Bob Nugman, ML Engineer at Doordash
One particular challenge that ML practitioners face when deploying models into production environments is ensuring a reliable experience for their users. Just imagine, it’s 3 am and you awake to a frantic phone call. You hop into a meeting and the CTO is on the line, asking questions. The number of purchases has suddenly plummeted in the newly launched market, resulting in a massive loss of revenue every minute. Social media has suddenly filled with an explosion of unsavory user reports. The clock is ticking. Your team is scrambling, but it’s unclear where to even start. Did a model start to fail in production? As the industry attempts to turn machine learning into an engineering practice, we need to start talking about solving this ML reliability problem.
An important part of engineering is ensuring reliability in our products, and those that incorporate machine learning should be no exception. At the end of the day, your users aren’t going to give you a pass because you are using the latest and greatest machine learning models in your product. They are simply going to expect things to work.
To frame our discussion about reliability in ML, let’s first take a look at what the field of software engineering has learned about shipping reliable software.
Reliability in Software
The Why
Virtually any modern technological enterprise needs a robust Reliability Engineering program. The scope and shape of such a program will depend on the nature of the business, and the choices will involve the trade-offs around complexity, velocity, cost, etc.
A particularly important trade-off is between velocity (“moving fast”) and reliability (“not breaking things”). Some domains, such as fraud detection, require both.
Adding ML into the mix makes things even more interesting.
Consider setting the goal of 99.95% availability. This gives us an outage budget of 5 minutes per week. The vast majority of outages (well over 90% in our experience) are triggered by human-introduced changes to code and/or configuration. This now also increasingly includes changes to production ML models and data pipelines.
It is common to have changes to production systems’ code and configuration to occur nearly continuously, with each change having the potential for creating an outage-inducing incident. Similarly, with increased reliance on ML, there’s an increasing appetite for high-velocity production delivery of ML systems, again with a risk of making a change that introduces a regression or an outage.
Allowing ourselves just one incident per week, the challenge then becomes to detect and fully mitigate an incident within five minutes, if we are to meet this goal. How?
There needs to be a systematic Reliability Program.
What Are the Three Pillars of Reliability?
A successful reliability program will have the following elements. Each will be covered in more detail below.
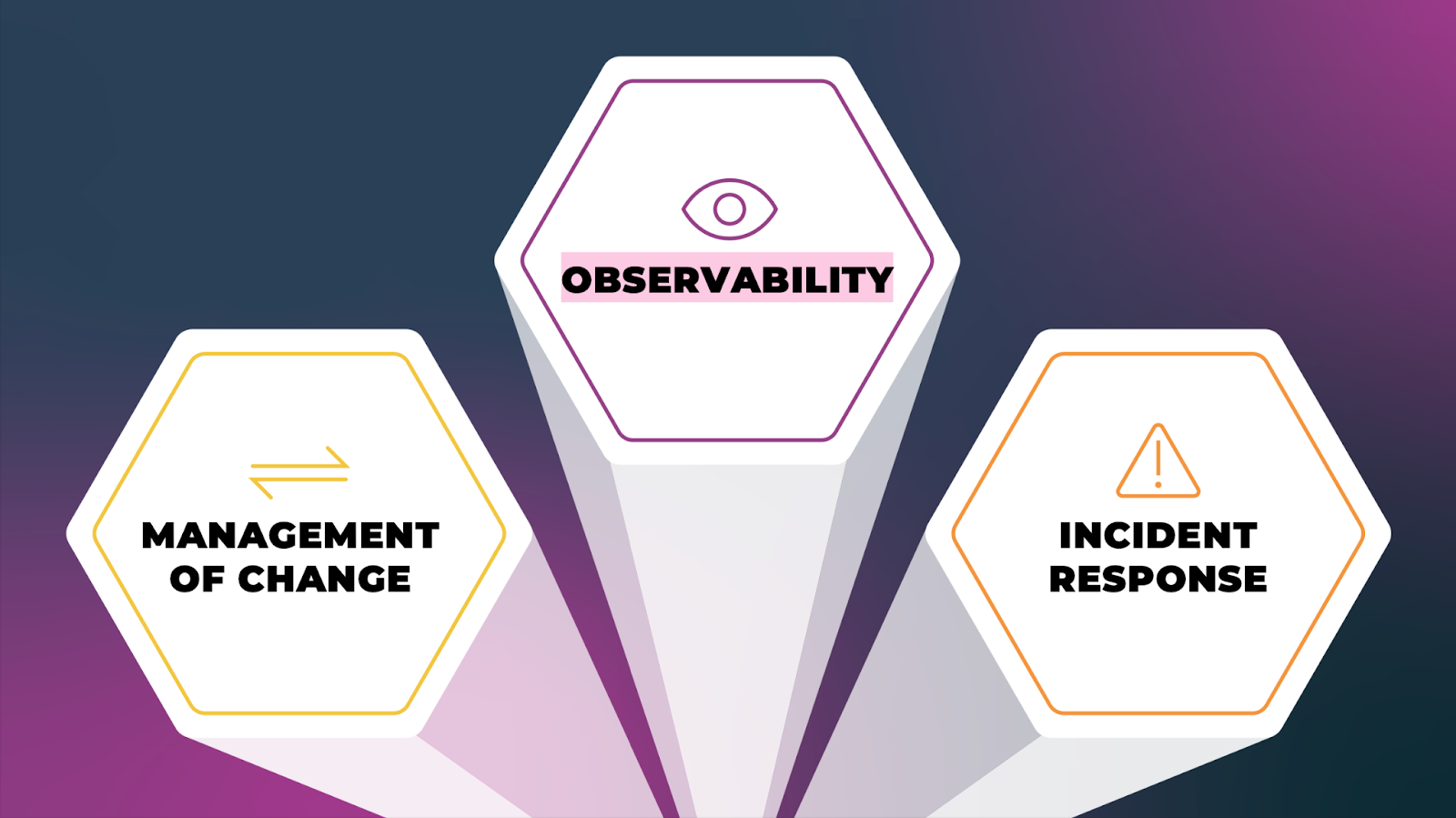
- Observability: Capability to detect, explore, and make sense of the regressions
- Management of Change: tooling and practices to ensure that every change introduced (code, configuration, business rules, infrastructure, etc) is discoverable, observable, rolled out gradually, mitigable, revertible.
- Incident Response: When (not if) an incident occurs, a pre-existing plan and capability is in place, to first mitigate and then revert the impact of the incident. The process of incident response includes the initiation of the post-incident phase, including Blameless Post Mortems, the findings of which feedback into improvement of all of the Three Pillars.
These three pillars exert pressure on the entire engineering process, technological stack, as well as the organization’s culture.
Let us explore the goals and some of the properties of each.
Observability
A successful observability solution will enable us to:
- Detect a regression quickly
- Inform a path to rapid and efficient mitigation.
- Once the issue has been mitigated, inform the causes of the issue, so that the problem can be fully analyzed, understood, and addressed, usually through the Post Mortem process.
To be efficient, observability tools and practices need to be standardized across the org, while enabling the flexibility to meet the needs of every team. An observability team should formulate best practices and implement tools to enable developers to meet their observability needs, consistently and with minimum effort.
Management of Change
As noted above, most outages are triggered by one of the many changes to code and configuration. The goal of a Management of Change system is to ensure the changes are introduced in a centralized, systematic fashion which supports our reliability goals.
Similar to Observability, management of change (code, configuration, infra, ML models, etc) should be standardized across the org, while accommodating varying needs between teams. This is best achieved with a dedicated owner(s) for the management of change tooling and practices.
An example of well-constructed Management of Change capability presented by Sebastian Yates.
Incident Response
Despite our best preparation, truly unimaginable things will happen. At that time, a response should not look like an engineering activity with brainstorming, problem-solving, etc. It should look like an incident response, with a predefined structure, rehearsed roles, sharp specialized tools, and a mandate to operate.
Importantly, the other two pillars, Observability and Management of Change, are crucial for mounting a successful Incident Response capability.
Reliability in Machine Learning
Now that we have taken a look into what reliability means in the broad world of software engineering, let’s take our learnings to understand what problems the field of ML Ops needs to solve to help companies deploy reliable applications with machine-learned components.
To do so, let’s turn back our story about the late-night call from your CTO that we discussed a bit earlier. To give some more context, let’s say that the model that ranks your search results for your e-commerce company is returning strange results and is severely impacting customer conversions. Let’s take what happens here step by step.
The first step in the response to the problem has happened even before you got invited to the call with your CTO. The problem has been discovered and the relevant people have been alerted. This is likely the result of a metric monitoring system that is responsible for ensuring important business metrics don’t go off track.
Next using your ML observability tooling, which we will talk a bit more about in a second, you are able to determine that the problem is happening in your search model since the proportion of users who are engaging with your top n-links returned has dropped significantly.
After learning this you rely on your model management system to either roll back to your previous search ranking model or deploy a naive model that can hold you over in the interim. This mitigation is what stops your company from losing (as much) money every minute since every second counts for users being served incorrect products.
Now that things are somewhat working again, you need to look back to your model observability tools to understand what happened with your model. There are a number of things that could have gone wrong here, some of which could inform your mitigation strategy, so it’s important to quickly start understanding what went wrong.
Lastly, once you have discovered the root cause of the issue, you have to come up with a solution to it, ranging from fixing a data source, retraining your model, to going back to the drawing board to devise a new model architecture.
Now let’s take a deeper dive into each of these pieces that enable ML reliability in production products.
Observability

The key ingredient in making any system reliable is the ability to introspect the inner workings of the system. In the same way that a mechanic needs to peer under the hood of a car to see if your engine is running smoothly, an ML engineer needs to be able to peer under the hood of their model to understand how their model is fairing in production. While this seems obvious, many companies have been flying blind when it comes to deploying machine learning. Measuring your model’s performance via aggregate performance metrics is not observability.
The best way to think about ML observability is how effectively your team can detect a problem with your model’s performance, perform mitigation to the problem to stop the bleeding, identify the root cause of the regression, and perform remediation or solution to the problem. It’s important to note that having the ability to detect a problem does not constitute full observability into an ML system. Without the ability to introspect to find the root cause or weight the sum of contributing factors, any resolution is going to be some form of guesswork.
To better illustrate what kind of things your tooling should be looking for, we first need to understand what are some things that can go wrong?
So what can go wrong?
What you should observe really depends on what can go wrong.
There are many different model failure modes and production challenges when working with ML models, each of which requires you to observe additional information in your system.

To start, the first step in the battle is detecting that an issue has occurred. How this is typically done is to measure a model performance metric such as running accuracy, RMSE, f1, etc. One catch is that this isn’t as easy as it sounds. In the ideal case, you know the ground truth of your model’s prediction pretty quickly after the model has made the decision, making it easy to determine how well your model is doing in production. Take, for example, predicting which ad a user might click on. You have a result around how well you did almost immediately after the model makes the decision. The user either clicked on it or they didn’t!
Many applications of ML don’t have this luxury of real-time ground truth, in which case proxy performance metrics such as relevant business metrics might be used instead. On top of model performance metrics, you may want to monitor service health metrics such as prediction latency, to ensure your service is providing a good experience for your users.
Once a regression has been detected by monitoring model performance or service health metrics, you need more information to understand what might be going on with your model. Some things that are important to keep tabs on to help with incident response:
Service:
- Latency of model predictions and user-facing latency
- Service downtime (pretty similar to software)
Data:
- New values in production unseen before in training
- Noisy or missing values in the data can have a big impact on the features consumed by a model.
Model:
- The underlying task that the model is performing can drift slowly or quickly change overnight!
- Your model may be biased in a way that was not designed (are some unexpected subsets of your users getting measurably different outcomes)
- Your model may be performing particularly poorly on some subsets of data (need to store and make sense of your model errors)
For each of these potential production challenges, your ML Observability tool should enable your team to detect regressions and drill into them to best understand why they happened and what you can do about it.
We can talk about ML observability all day, so let’s move on to how you best manage shipping updates to your model in production.
Management of Change
Every time you push new changes into production, you risk introducing your users to issues that your team did not foresee and protect against.
In fact, let’s say for the sake of it that your search model is regressing on your hypothetical e-commerce platform due to a new model rollout. Now that your business metrics caught that something was going wrong, and your observability tooling pinpointed the search model, what do we do about it? We alluded previously to the difference between mitigation and remediation. Here, since we are rapidly losing the company money, it’s likely that the best course of action is to stop the bleeding as quickly as possible (mitigate the issue).
One option we may have is to revert back to the previous model we had deployed. Alternatively, we could ship our naive model, a model that may not have as good of performance but works consistently pretty well. In our case, this might just be displaying the exact results returned from elastic search.
To best protect against these potential issues from occurring rapidly and dramatically for the users of your product, ML systems should follow similar rollout procedures to those of software deployments.
In the same way that software is typically tested using static test cases to ensure that the code is not regressing any behavior, ML systems should also undergo static validation tests before deployment. For example, if you are shipping an autonomous driving service, running your new model through some standardized deterministic simulator routes might allow you to catch some obvious regressions.
While static validation is exceedingly important for improving the quality of your shipping product, there is no replacement for what you learn about a model in production. Let’s talk about how you can get these learnings from your production model without risking a full outage or a degraded experience for all of your users.
You may want to ship your model to a subset of your users first to detect issues early and before all of your users catch a whiff of the issue. This technique is commonly referred to as a canary deployment.
As you gradually roll out your changes if a problem is detected via your ML monitoring systems, you should be able to easily and quickly revert back to a previous model version along with its corresponding software version.
Another topic that is closely related is the idea of shadow deployment. In a shadow deployment, you would start to feed the inputs that your existing model is seeing in production to your new model before you ship it. So while your users are still experiencing the predictions and user experience provided by the existing model, you can start to measure how your new model is performing and make any necessary changes to get it ready for prime-time.
One additional benefit of a shadow deployment is that you can perform experiments with multiple candidate models in a shadow deployment and choose the one that is able to perform best on your current production data.
Now that we have some techniques to help us improve the quality of our deployments, let’s talk about what you can do when you find an issue with your production model after you have deployed it into production.
Incident Response
Okay so we discovered an issue with our model in production, what should we do about it? This very much depends on your model application, but here we will talk about some general strategies about how to handle an issue in the short term (mitigation) and work towards the real fix (remediation).
Mitigation
To start, just as with software, you may be able to roll back to a previous model version and corresponding software/configuration. This mitigation strategy might help you if you promoted a bad model that got past your validation procedures; however, this will not always solve your issue. It’s possible that your input data distribution or the underlying task of the model has changed, making the older model also a poor choice to have in production.
Another strategy that can work in some cases is to deploy a naive version of your model. This may generally have lower performance than your more complex model, but it may do better in the face of change in input and expected output distributions. The model doesn’t need to be machine-learned and can just be a simple heuristic-based model. This strategy may help you buy time while you rework your more complex, but more performant model.
Remediation
This brings us to the most common advice that is given to resolve an incident caused by an ML model in production: Just retrain it! This advice is common because it covers a lot of potential failure modes for a model. If the input data has shifted or the underlying task has changed, retraining on newer production data might be able to solve your issue. The world changes over time, and it’s possible your model needs to be regularly retrained to stay relevant.

Retraining strategies could encompass a whole other technical article, so let’s skip to the abridged version. You have some options when you retrain your model:
You can choose to upsample certain subsets of your data, potentially to fix issues regarding unintended bias or underperformance for a category of your data.
You also can sample the newer production data to build new training sets to use if you think that the shift in your input/output distributions is here to stay.
If you think that this shift in distributions is temporary and potentially seasonal, you can train a new version of your model on the data from this seasonal period and deploy it, or turn to engineering features to help your model understand this seasonal indicator in the function it is trying to approximate.
It’s possible that your model’s performance may have dipped due to the introduction of a new category of examples that it had not seen in it’s training. If this category of examples is sufficiently different you may need an entirely new model to handle these particular examples. The process of training a separate model and employing a higher-level model to determine which to use for a particular example is commonly referred to as a federation.
The last option we will talk about here is going back to the drawing board. If retraining hasn’t helped restore performance and your older models also fail to do the job, it’s possible that the task has changed significantly enough to require some of the following: a new model architecture, new features, new data processing steps.
Conclusion
It took years for the software world to get behind the reliability framework we outlined above. With the three pillars of observability, management of change, and incidence response, we can translate the reliability gains from the world of software to the world of ML applications. It’s now up to the ML Ops space to provide the tools that we desperately need to make ML applications reliable.

