Two Essentials for ML Service-Level Performance Monitoring

Aparna Dhinakaran
Co-founder & Chief Product Officer
Over the last decade, a wave of renewed interest in machine learning has encouraged countless researchers to attempt to solve problems with state of the art machine learning techniques. It feels like every month some paper is published with a novel use of machine learning to solve a task that was previously impossible; however, outside of the research lab there has also been an explosion of applications using machine learning to deliver novel experiences.
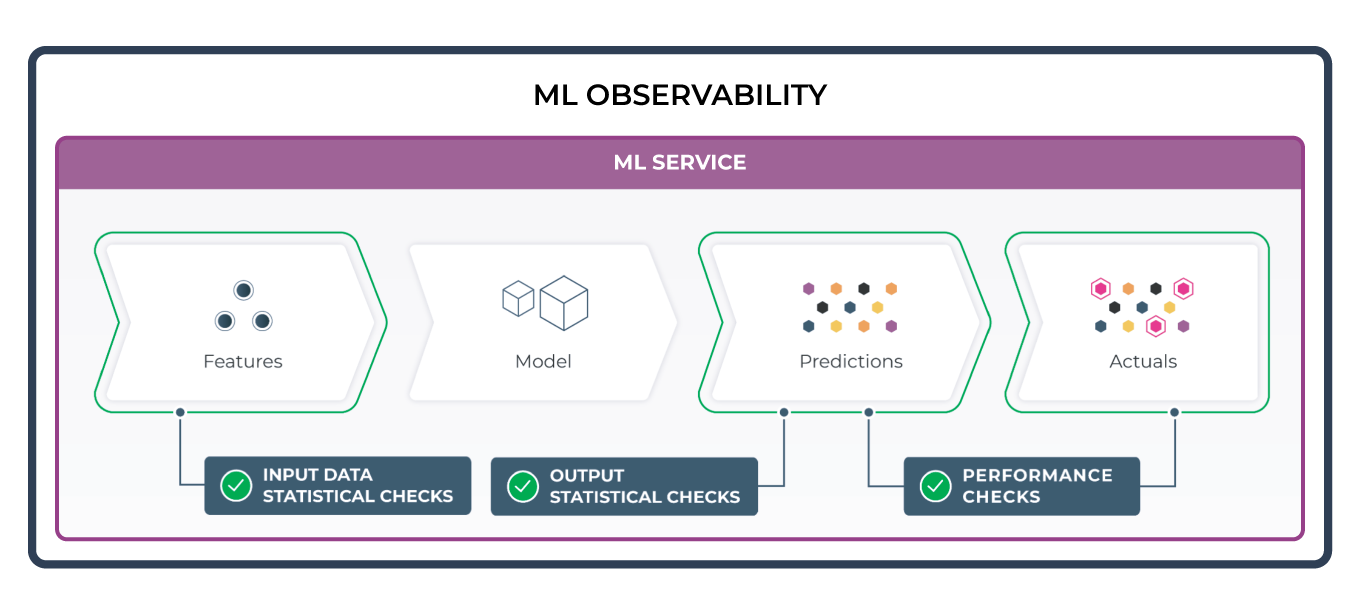
In the process of productionizing machine learning, the field has uncovered a whole host of new problems that engineering teams are now trying to tackle. In order for an ML system to be successful, it isn’t sufficient to just understand the data going in and out of the ML system or monitor its performance over time. When viewed as an overall service, the ML application also has to be measured by its overall service performance.
In this piece we will talk about the often overlooked field of service-level ML performance by breaking down how it can be measured and improved.