Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Phoenix offers key modules to measure the quality of generated results as well as modules to measure retrieval quality.
Response Evaluation: Does the response match the retrieved context? Does it also match the query?
Retrieval Evaluation: Are the retrieved sources relevant to the query?
Evaluation of generated results can be challenging. Unlike traditional ML, the predicted results are not numeric or categorical, making it hard to define quantitative metrics for this problem.
Phoenix offers LLM Evaluations, a module designed to measure the quality of results. This module uses a "gold" LLM (e.g. GPT-4) to decide whether the generated answer is correct in a variety of ways. Note that many of these evaluation criteria DO NOT require ground-truth labels. Evaluation can be done simply with a combination of the input (query), output (response), and context.
LLM Evals supports the following response evaluation criteria:
QA Correctness - Whether a question was correctly answered by the system based on the retrieved data. In contrast to retrieval Evals that are checks on chunks of data returned, this check is a system level check of a correct Q&A.
Hallucinations - Designed to detect LLM hallucinations relative to retrieved context
Toxicity - Identify if the AI response is racist, biased, or toxic
Response evaluations are a critical first step to figuring out whether your LLM App is running correctly. Response evaluations can pinpoint specific executions (a.k.a. traces) that are performing badly and can be aggregated up so that you can track how your application is running as a whole.
Phoenix also provides evaluation of retrieval independently.
The concept of retrieval evaluation is not new; given a set of relevance scores for a set of retrieved documents, we can evaluate retrievers using retrieval metrics like precision, NDCG, hit rate and more.
LLM Evals supports the following retrieval evaluation criteria:
Relevance - Evaluates whether a retrieved document chunk contains an answer to the query.
Retrieval is possibly the most important step in any LLM application as poor and/or incorrect retrieval can be the cause of bad response generation. If your application uses RAG to power an LLM, retrieval evals can help you identify the cause of hallucinations and incorrect answers.
With Phoenix's LLM Evals, evaluation results (or just Evaluations for short) is data consisting of 3 main columns:
label: str [optional] - a classification label for the evaluation (e.g. "hallucinated" vs "factual"). Can be used to calculate percentages (e.g. percent hallucinated) and can be used to filter down your data (e.g. Evals["Hallucinations"].label == "hallucinated")
score: number [optional] - a numeric score for the evaluation (e.g. 1 for good, 0 for bad). Scores are great way to sort your data to surface poorly performing examples and can be used to filter your data by a threshold.
explanation: str [optional] - the reasoning for why the evaluation label or score was given. In the case of LLM evals, this is the evaluation model's reasoning. While explanations are optional, they can be extremely useful when trying to understand problematic areas of your application.
Let's take a look at an example list of Q&A relevance evaluations:
correct
The reference text explains that YC was not or...
1
correct
To determine if the answer is correct, we need...
1
incorrect
To determine if the answer is correct, we must...
0
correct
To determine if the answer is correct, we need...
1
These three columns combined can drive any type of evaluation you can imagine. label provides a way to classify responses, score provides a way to assign a numeric assessment, and explanation gives you a way to get qualitative feedback.
With Phoenix, evaluations can be "attached" to the spans and documents collected. In order to facilitate this, Phoenix supports the following steps.
Querying and downloading data - query the spans collected by phoenix and materialize them into DataFrames to be used for evaluation (e.g. question and answer data, documents data).
Running Evaluations - the data queried in step 1 can be fed into LLM Evals to produce evaluation results.
Logging Evaluations - the evaluations performed in the above step can be logged back to Phoenix to be attached to spans and documents for evaluating responses and retrieval. See here on how to log evaluations to Phoenix.
Sorting and Filtering by Evaluation - once the evaluations have been logged back to Phoenix, the spans become instantly sortable and filterable by the evaluation values that you attached to the spans. (An example of an evaluation filter would be Eval["hallucination"].label == "hallucinated")
By following the above steps, you will have a full end-to-end flow for troubleshooting, evaluating, and root-causing an LLM application. By using LLM Evals in conjunction with Traces, you will be able to surface up problematic queries, get an explanation as to why the the generation is problematic (e.x. hallucinated because ...), and be able to identify which step of your generative app requires improvement (e.x. did the LLM hallucinate or was the LLM fed bad context?).\
For a full tutorial on LLM Ops, check out our tutorial below.
Evaluating tasks performed by LLMs can be difficult due to their complexity and the diverse criteria involved. Traditional methods like rule-based assessment or similarity metrics (e.g., ROUGE, BLEU) often fall short when applied to the nuanced and varied outputs of LLMs.
For instance, an AI assistant’s answer to a question can be:
not grounded in context
repetitive, repetitive, repetitive
grammatically incorrect
excessively lengthy and characterized by an overabundance of words
incoherent
The list of criteria goes on. And even if we had a limited list, each of these would be hard to measure
To overcome this challenge, the concept of "LLM as a Judge" employs an LLM to evaluate another's output, combining human-like assessment with machine efficiency.
Here’s the step-by-step process for using an LLM as a judge:
Identify Evaluation Criteria - First, determine what you want to evaluate, be it hallucination, toxicity, accuracy, or another characteristic. See our pre-built evaluators for examples of what can be assessed.
Craft Your Evaluation Prompt - Write a prompt template that will guide the evaluation. This template should clearly define what variables are needed from both the initial prompt and the LLM's response to effectively assess the output.
Select an Evaluation LLM - Choose the most suitable LLM from our available options for conducting your specific evaluations.
Generate Evaluations and View Results - Execute the evaluations across your data. This process allows for comprehensive testing without the need for manual annotation, enabling you to iterate quickly and refine your LLM's prompts.
Using an LLM as a judge significantly enhances the scalability and efficiency of the evaluation process. By employing this method, you can run thousands of evaluations across curated data without the need for human annotation.
This capability will not only speed up the iteration process for refining your LLM's prompts but will also ensure that you can deploy your models to production with confidence.
It can be hard to understand in many cases why an LLM responds in a specific way. The explanation feature of Phoneix allows you to get a Eval output and an explanation from the LLM at the same time. We have found this incredibly useful for debugging LLM Evals.
The flag above can be set with any of the templates or your own custom templates. The example below is from a relevance Evaluation.
from phoenix.evals import (
RAG_RELEVANCY_PROMPT_RAILS_MAP,
RAG_RELEVANCY_PROMPT_TEMPLATE,
OpenAIModel,
download_benchmark_dataset,
llm_classify,
)
model = OpenAIModel(
model_name="gpt-4",
temperature=0.0,
)
#The rails is used to hold the output to specific values based on the template
#It will remove text such as ",,," or "..."
#Will ensure the binary value expected from the template is returned
rails = list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values())
relevance_classifications = llm_classify(
dataframe=df,
template=RAG_RELEVANCY_PROMPT_TEMPLATE,
model=model,
rails=rails,
)
#relevance_classifications is a Dataframe with columns 'label' and 'explanation'The LLM Evals library is designed to support the building of any custom Eval templates.
Follow the following steps to easily build your own Eval with Phoenix
To do that, you must identify what is the metric best suited for your use case. Can you use a pre-existing template or do you need to evaluate something unique to your use case?
Then, you need the golden dataset. This should be representative of the type of data you expect the LLM eval to see. The golden dataset should have the “ground truth” label so that we can measure performance of the LLM eval template. Often such labels come from human feedback.
Building such a dataset is laborious, but you can often find a standardized one for the most common use cases (as we did in the code above)
The Eval inferences are designed or easy benchmarking and pre-set downloadable test inferences. The inferences are pre-tested, many are hand crafted and designed for testing specific Eval tasks.
from phoenix.evals import download_benchmark_dataset
df = download_benchmark_dataset(
task="binary-hallucination-classification", dataset_name="halueval_qa_data"
)
df.head()Then you need to decide which LLM you want to use for evaluation. This could be a different LLM from the one you are using for your application. For example, you may be using Llama for your application and GPT-4 for your eval. Often this choice is influenced by questions of cost and accuracy.
Now comes the core component that we are trying to benchmark and improve: the eval template.
You can adjust an existing template or build your own from scratch.
Be explicit about the following:
What is the input? In our example, it is the documents/context that was retrieved and the query from the user.
What are we asking? In our example, we’re asking the LLM to tell us if the document was relevant to the query
What are the possible output formats? In our example, it is binary relevant/irrelevant, but it can also be multi-class (e.g., fully relevant, partially relevant, not relevant).
In order to create a new template all that is needed is the setting of the input string to the Eval function.
MY_CUSTOM_TEMPLATE = '''
You are evaluating the positivity or negativity of the responses to questions.
[BEGIN DATA]
************
[Question]: {question}
************
[Response]: {response}
[END DATA]
Please focus on the tone of the response.
Your answer must be single word, either "positive" or "negative"
'''The above template shows an example creation of an easy to use string template. The Phoenix Eval templates support both strings and objects.
model = OpenAIModel(model_name="gpt-4",temperature=0.6)
positive_eval = llm_classify(
dataframe=df,
template= MY_CUSTOM_TEMPLATE,
model=model
)The above example shows a use of the custom created template on the df dataframe.
#Phoenix Evals support using either strings or objects as templates
MY_CUSTOM_TEMPLATE = " ..."
MY_CUSTOM_TEMPLATE = PromptTemplate("This is a test {prompt}")You now need to run the eval across your golden dataset. Then you can generate metrics (overall accuracy, precision, recall, F1, etc.) to determine the benchmark. It is important to look at more than just overall accuracy. We’ll discuss that below in more detail.
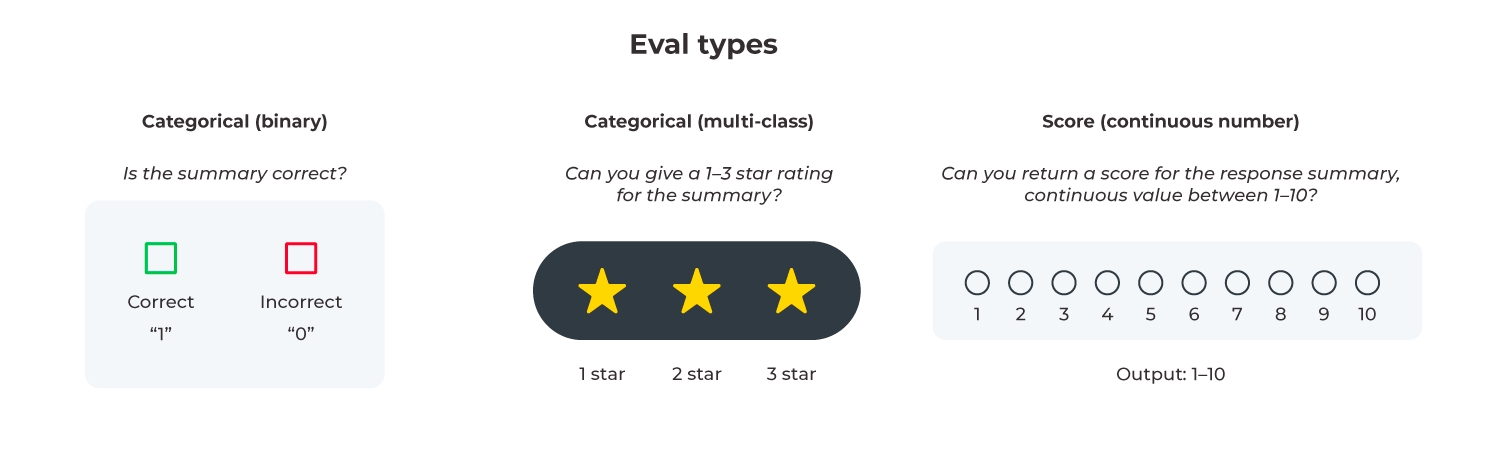
There are a multiple types of evaluations supported by the Phoenix Library. Each category of evaluation is categorized by its output type.
Categorical (binary) - The evaluation results in a binary output, such as true/false or yes/no, which can be easily represented as 1/0. This simplicity makes it straightforward for decision-making processes but lacks the ability to capture nuanced judgements.
Categorical (Multi-class) - The evaluation results in one of several predefined categories or classes, which could be text labels or distinct numbers representing different states or types.
Score - The evaluation results is a numeric value within a set range (e.g. 1-10), offering a scale of measurement.
Although score evals are an option in Phoenix, we recommend using categorical evaluations in production environments. LLMs often struggle with the subtleties of continuous scales, leading to inconsistent results even with slight prompt modifications or across different models. Repeated tests have shown that scores can fluctuate significantly, which is problematic when evaluating at scale.
Categorical evals, especially multi-class, strike a balance between simplicity and the ability to convey distinct evaluative outcomes, making them more suitable for applications where precise and consistent decision-making is important.
To explore the full analysis behind our recommendation and understand the limitations of score-based evaluations, check out our research on LLM eval data types.
Evaluating multi-agent systems involves unique challenges compared to single-agent evaluations. This guide provides clear explanations of various architectures, strategies for effective evaluation, and additional considerations.
A multi-agent system consists of multiple agents, each using an LLM (Large Language Model) to control application flows. As systems grow, you may encounter challenges such as agents struggling with too many tools, overly complex contexts, or the need for specialized domain knowledge (e.g., planning, research, mathematics). Breaking down applications into multiple smaller, specialized agents often resolves these issues.
Modularity: Easier to develop, test, and maintain.
Specialization: Expert agents handle specific domains.
Control: Explicit control over agent communication.
Multi-agent systems can connect agents in several ways:
Network
Agents can communicate freely with each other, each deciding independently whom to contact next.
Assess communication efficiency, decision quality on agent selection, and coordination complexity.
Supervisor
Agents communicate exclusively with a single supervisor that makes all routing decisions.
Evaluate supervisor decision accuracy, efficiency of routing, and effectiveness in task management.
Supervisor (Tool-calling)
Supervisor uses an LLM to invoke agents represented as tools, making explicit tool calls with arguments.
Evaluate tool-calling accuracy, appropriateness of arguments passed, and supervisor decision quality.
Hierarchical
Systems with supervisors of supervisors, allowing complex, structured flows.
Evaluate communication efficiency, decision-making at each hierarchical level, and overall system coherence.
Custom Workflow
Agents communicate within predetermined subsets, combining deterministic and agent-driven decisions.
Evaluate workflow efficiency, clarity of communication paths, and effectiveness of the predetermined control flow.
There are a few different strategies for evaluating multi agent applications.
1. Agent Handoff Evaluation
When tasks transfer between agents, evaluate:
Appropriateness: Is the timing logical?
Information Transfer: Was context transferred effectively?
Timing: Optimal handoff moment.
2. System-Level Evaluation
Measure holistic performance:
End-to-End Task Completion
Efficiency: Number of interactions, processing speed
User Experience
3. Coordination Evaluation
Evaluate cooperative effectiveness:
Communication Quality
Conflict Resolution
Resource Management
Multi-agent systems introduce added complexity:
Complexity Management: Evaluate agents individually, in pairs, and system-wide.
Emergent Behaviors: Monitor for collective intelligence and unexpected interactions.
Evaluation Granularity:
Agent-level: Individual performance
Interaction-level: Agent interactions
System-level: Overall performance
User-level: End-user experience
Performance Metrics: Latency, throughput, scalability, reliability, operational cost
Adapt single-agent evaluation methods like tool-calling evaluations and planning assessments.
See our guide on agent evals and use our pre-built evals that you can leverage in Phoenix.
Focus evaluations on coordination efficiency, overall system efficiency, and emergent behaviors.
See our docs for creating your own custom evals in Phoenix.
Structure evaluations to match architecture:
Bottom-Up: From individual agents upward.
Top-Down: From system goals downward.
Hybrid: Combination for comprehensive coverage.





