Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Tracing can be augmented and customized by adding Metadata. Metadata includes your own custom attributes, user ids, session ids, prompt templates, and more.
Add Attributes, Metadata, Users
Learn how to add custom metadata and attributes to your traces
Instrument Prompt Templates and Prompt Variables
Learn how to define custom prompt templates and variables in your tracing.
Learn how to load a file of traces into Phoenix
Learn how to export trace data from Phoenix
Learn how to block PII from logging to Phoenix
Learn how to selectively block or turn off tracing
Learn how to send only certain spans to Phoenix
Learn how to trace images
Phoenix uses projects to group traces. If left unspecified, all traces are sent to a default project.
In the notebook, you can set the PHOENIX_PROJECT_NAME environment variable before adding instrumentation or running any of your code.
In python this would look like:
Note that setting a project via an environment variable only works in a notebook and must be done BEFORE instrumentation is initialized. If you are using OpenInference Instrumentation, see the Server tab for how to set the project name in the Resource attributes.
Alternatively, you can set the project name in your register function call:
If you are using Phoenix as a collector and running your application separately, you can set the project name in the Resource attributes for the trace provider.
Projects work by setting something called the Resource attributes (as seen in the OTEL example above). The phoenix server uses the project name attribute to group traces into the appropriate project.
Typically you want traces for an LLM app to all be grouped in one project. However, while working with Phoenix inside a notebook, we provide a utility to temporarily associate spans with different projects. You can use this to trace things like evaluations.
Learn how to use the phoenix.otel library
Learn how you can use basic OpenTelemetry to instrument your application.
Learn how to use Phoenix's decorators to easily instrument specific methods or code blocks in your application.
Setup tracing for your TypeScript application.
Learn about Projects in Phoenix, and how to use them.
Understand Sessions and how they can be used to group user conversations.
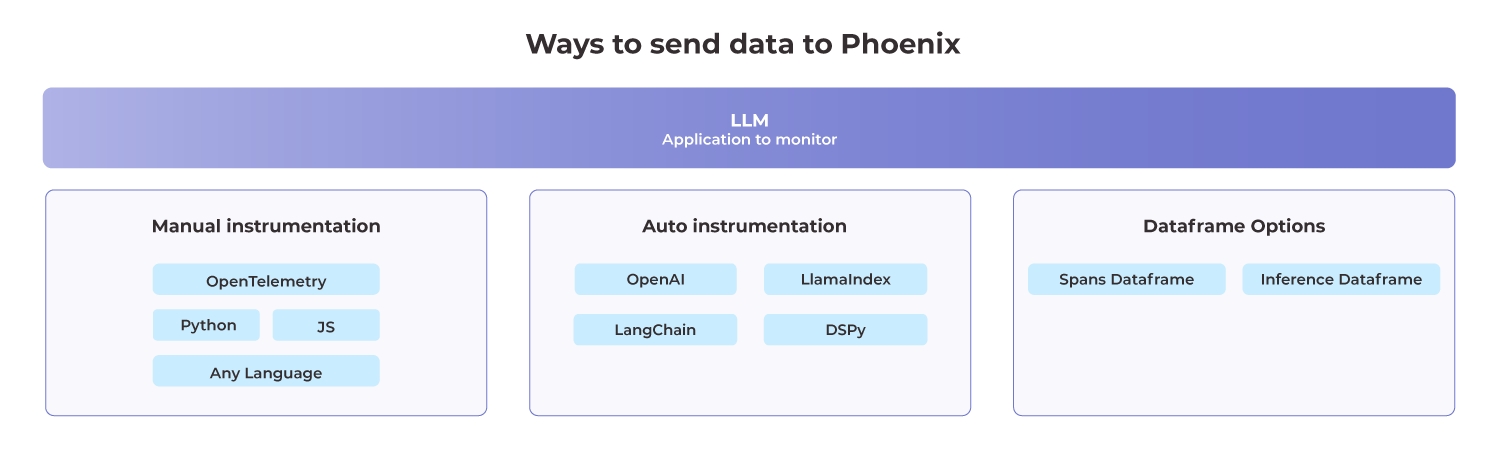
Phoenix supports loading data that contains OpenInference traces. This allows you to load an existing dataframe of traces into your Phoenix instance.
Usually these will be traces you've previously saved using Save All Traces.
Before accessing px.Client(), be sure you've set the following environment variables:
import os
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key=..."
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com"If you're self-hosting Phoenix, ignore the client headers and change the collector endpoint to your endpoint.
import phoenix as px
# Re-launch the app using trace data
px.launch_app(trace=px.TraceDataset(df))
# Load traces into an existing Phoenix instance
px.Client().log_traces(trace_dataset=px.TraceDataset(df))
# Load traces into an existing Phoenix instance from a local file
px.launch_app(trace=px.TraceDataset.load('f7733fda-6ad6-4427-a803-55ad2182b662', directory="/my_saved_traces/"))You can also launch a temporary version of Phoenix in your local notebook to quickly view the traces. But be warned, this Phoenix instance will only last as long as your notebook environment is runing
# Load traces from a dataframe
px.launch_app(trace=px.TraceDataset.load(my_traces))
# Load traces from a local file
px.launch_app(trace=px.TraceDataset.load('f7733fda-6ad6-4427-a803-55ad2182b662', directory="/my_saved_traces/"))Tracing can be paused temporarily or disabled permanently.
If there is a section of your code for which tracing is not desired, e.g. the document chunking process, it can be put inside the suppress_tracing context manager as shown below.
from phoenix.trace import suppress_tracing
with suppress_tracing():
# Code running inside this block doesn't generate traces.
# For example, running LLM evals here won't generate additional traces.
...
# Tracing will resume outside the block.
...Calling .uninstrument() on the auto-instrumentors will remove tracing permanently. Below is the examples for LangChain, LlamaIndex and OpenAI, respectively.
LangChainInstrumentor().uninstrument()
LlamaIndexInstrumentor().uninstrument()
OpenAIInstrumentor().uninstrument()
# etc.Span annotations can be an extremely valuable basis for improving your application. The Phoenix client provides useful ways to pull down spans and their associated annotations. This information can be used to:
build new LLM judges
form the basis for new datasets
help identify ideas for improving your application
from phoenix.client import Client
client = Client()
spans = client.spans.get_spans_dataframe(
project_identifier="default", # you can also pass a project id
)If you only want the spans that contain a specific annotation, you can pass in a query that filters on annotation names, scores, or labels.
from phoenix.client import Client
from phoenix.client.types.span import SpanQuery
client = Client()
query = SpanQuery().where("annotations['correctness']")
spans = client.spans.get_spans_dataframe(
query=query,
project_identifier="default", # you can also pass a project id
)The queries can also filter by annotation scores and labels.
from phoenix.client import Client
from phoenix.client.types.span import SpanQuery
client = Client()
query = SpanQuery().where("annotations['correctness'].score == 1")
# query = SpanQuery().where("annotations['correctness'].label == 'correct'")
spans = client.spans.get_spans_dataframe(
query=query,
project_identifier="default", # you can also pass a project id
)This spans dataframe can be used to pull associated annotations.
annotations = client.spans.get_span_annotations_dataframe(
spans_dataframe=spans,
project_identifier="default",
)Instead of an input dataframe, you can also pass in a list of ids:
annotations = client.spans.get_span_annotations_dataframe(
span_ids=list[spans.index],
project_identifier="default",
)The annotations and spans dataframes can be easily joined to produce a one-row-per-annotation dataframe that can be used to analyze the annotations!
annotations.join(spans, how="left")from phoenix.trace import using_project
# Switch project to run evals
with using_project("my-eval-project"):
# all spans created within this context will be associated with
# the "my-eval-project" project.
# Run evaluations here...Annotating traces is a crucial aspect of evaluating and improving your LLM-based applications. By systematically recording qualitative or quantitative feedback on specific interactions or entire conversation flows, you can:
Track performance over time
Identify areas for improvement
Compare different model versions or prompts
Gather data for fine-tuning or retraining
Provide stakeholders with concrete metrics on system effectiveness
Phoenix allows you to annotate traces through the Client, the REST API, or the UI.
To learn how to configure annotations and to annotate through the UI, see Annotating in the UI
To learn how to add human labels to your traces, either manually or programmatically, see Annotating via the Client
To learn how to evaluate traces captured in Phoenix, see Running Evals on Traces
To learn how to upload your own evaluation labels into Phoenix, see Log Evaluation Results
For more background on the concept of annotations, see Annotations
How to track sessions across multiple traces
Sessions UI is available in Phoenix 7.0 and requires a db migration if you're coming from an older version of Phoenix.
A Session is a sequence of traces representing a single session (e.g. a session or a thread). Each response is represented as its own trace, but these traces are linked together by being part of the same session.
To associate traces together, you need to pass in a special metadata key where the value is the unique identifier for that thread.
OpenAI tracing with Sessions
Python
LlamaIndex tracing with Sessions
Python
OpenAI tracing with Sessions
TS/JS
Below is an example of logging conversations:
First make sure you have the required dependancies installed
pip install openinference-instrumentationBelow is an example of how to use openinference.instrumentation to the traces created.
import uuid
import openai
from openinference.instrumentation import using_session
from openinference.semconv.trace import SpanAttributes
from opentelemetry import trace
client = openai.Client()
session_id = str(uuid.uuid4())
tracer = trace.get_tracer(__name__)
@tracer.start_as_current_span(name="agent", attributes={SpanAttributes.OPENINFERENCE_SPAN_KIND: "agent"})
def assistant(
messages: list[dict],
session_id: str = str,
):
current_span = trace.get_current_span()
current_span.set_attribute(SpanAttributes.SESSION_ID, session_id)
current_span.set_attribute(SpanAttributes.INPUT_VALUE, messages[-1].get('content'))
# Propagate the session_id down to spans crated by the OpenAI instrumentation
# This is not strictly necessary, but it helps to correlate the spans to the same session
with using_session(session_id):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "system", "content": "You are a helpful assistant."}] + messages,
).choices[0].message
current_span.set_attribute(SpanAttributes.OUTPUT_VALUE, response.content)
return response
messages = [
{"role": "user", "content": "hi! im bob"}
]
response = assistant(
messages,
session_id=session_id,
)
messages = messages + [
response,
{"role": "user", "content": "what's my name?"}
]
response = assistant(
messages,
session_id=session_id,
)The easiest way to add sessions to your application is to install @arizeai/openinfernce-core
npm install @arizeai/openinference-core --saveYou now can use either the session.id semantic attribute or the setSession utility function from openinference-core to associate traces with a particular session:
import { trace } from "@opentelemetry/api";
import { SemanticConventions } from "@arizeai/openinference-semantic-conventions";
import { context } from "@opentelemetry/api";
import { setSession } from "@arizeai/openinference-core";
const tracer = trace.getTracer("agent");
const client = new OpenAI({
apiKey: process.env["OPENAI_API_KEY"], // This is the default and can be omitted
});
async function assistant(params: {
messages: { role: string; content: string }[];
sessionId: string;
}) {
return tracer.startActiveSpan("agent", async (span: Span) => {
span.setAttribute(SemanticConventions.OPENINFERENCE_SPAN_KIND, "agent");
span.setAttribute(SemanticConventions.SESSION_ID, params.sessionId);
span.setAttribute(
SemanticConventions.INPUT_VALUE,
messages[messages.length - 1].content,
);
try {
// This is not strictly necessary but it helps propagate the session ID
// to all child spans
return context.with(
setSession(context.active(), { sessionId: params.sessionId }),
async () => {
// Calls within this block will generate spans with the session ID set
const chatCompletion = await client.chat.completions.create({
messages: params.messages,
model: "gpt-3.5-turbo",
});
const response = chatCompletion.choices[0].message;
span.setAttribute(SemanticConventions.OUTPUT_VALUE, response.content);
span.end();
return response;
},
);
} catch (e) {
span.error(e);
}
});
}
const sessionId = crypto.randomUUID();
let messages = [{ role: "user", content: "hi! im Tim" }];
const res = await assistant({
messages,
sessionId: sessionId,
});
messages = [res, { role: "assistant", content: "What is my name?" }];
await assistant({
messages,
sessionId: sessionId,
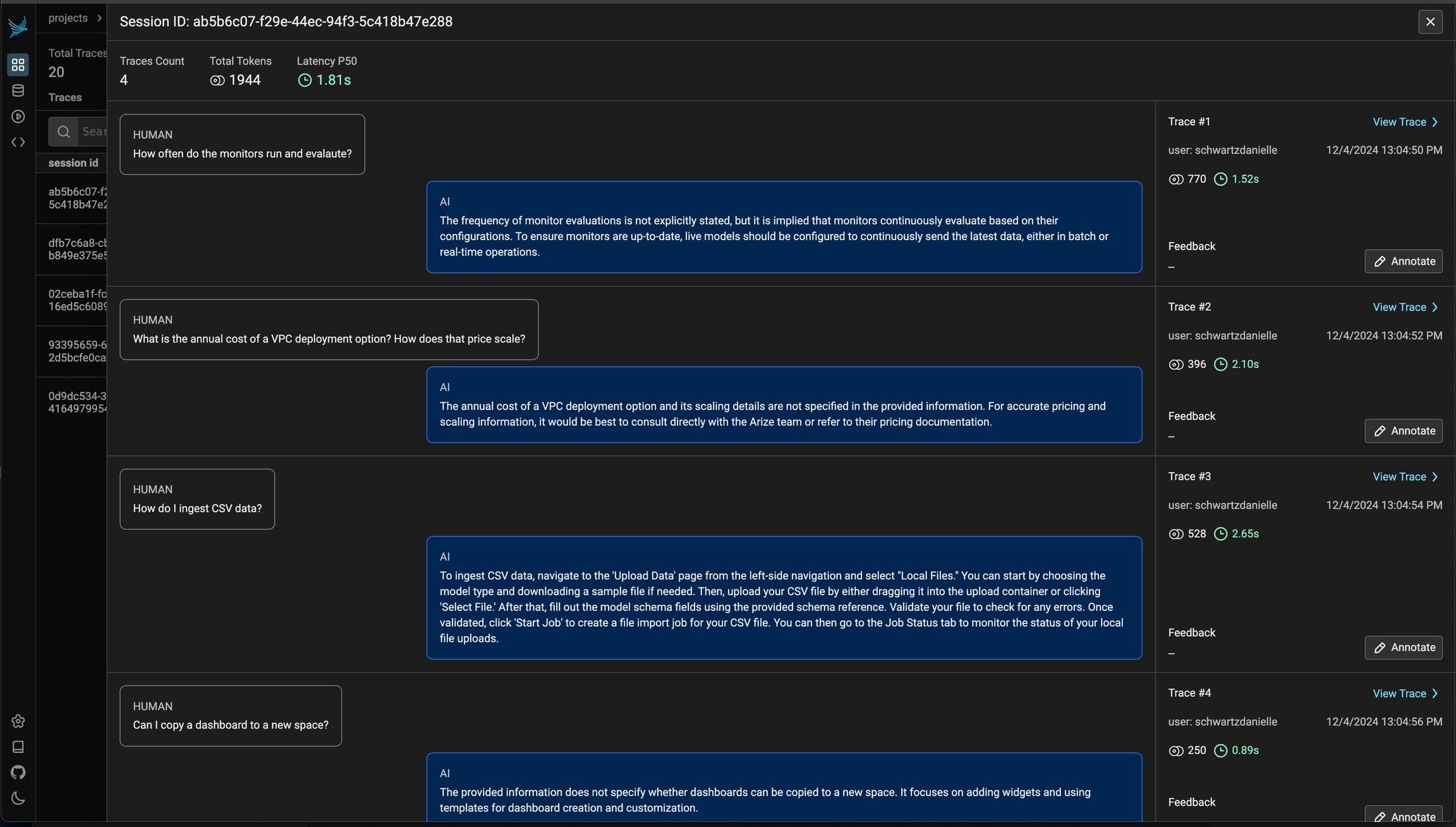
});You can view the sessions for a given project by clicking on the "Sessions" tab in the project. You will see a list of all the recent sessions as well as some analytics. You can search the content of the messages to narrow down the list.
You can then click into a given session. This will open the history of a particular session. If the sessions contain input / output, you will see a chatbot-like UI where you can see the a history of inputs and outputs.
For LangChain, in order to log runs as part of the same thread you need to pass a special metadata key to the run. The key value is the unique identifier for that conversation. The key name should be one of:
session_id
thread_id
conversation_id.
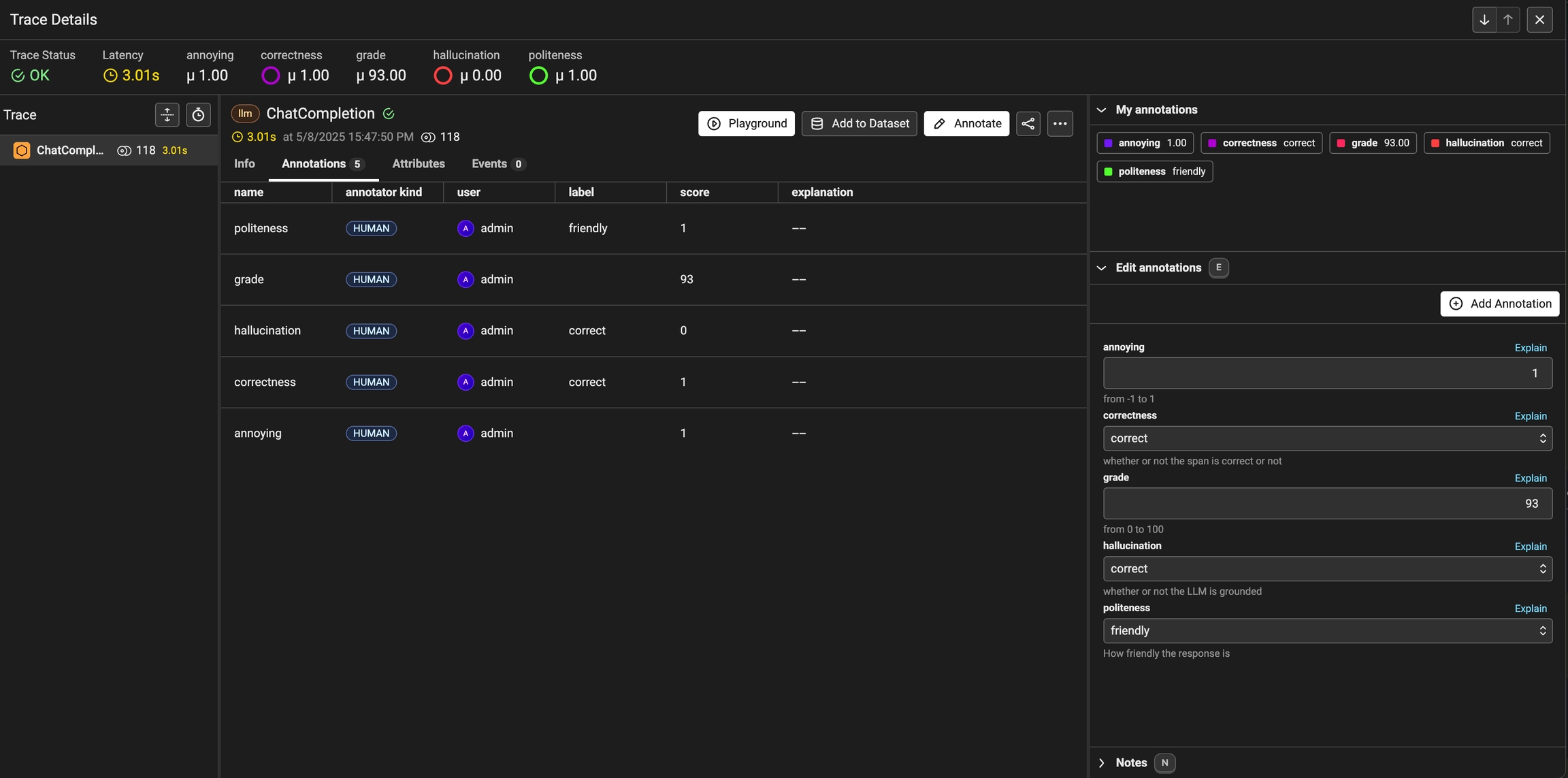
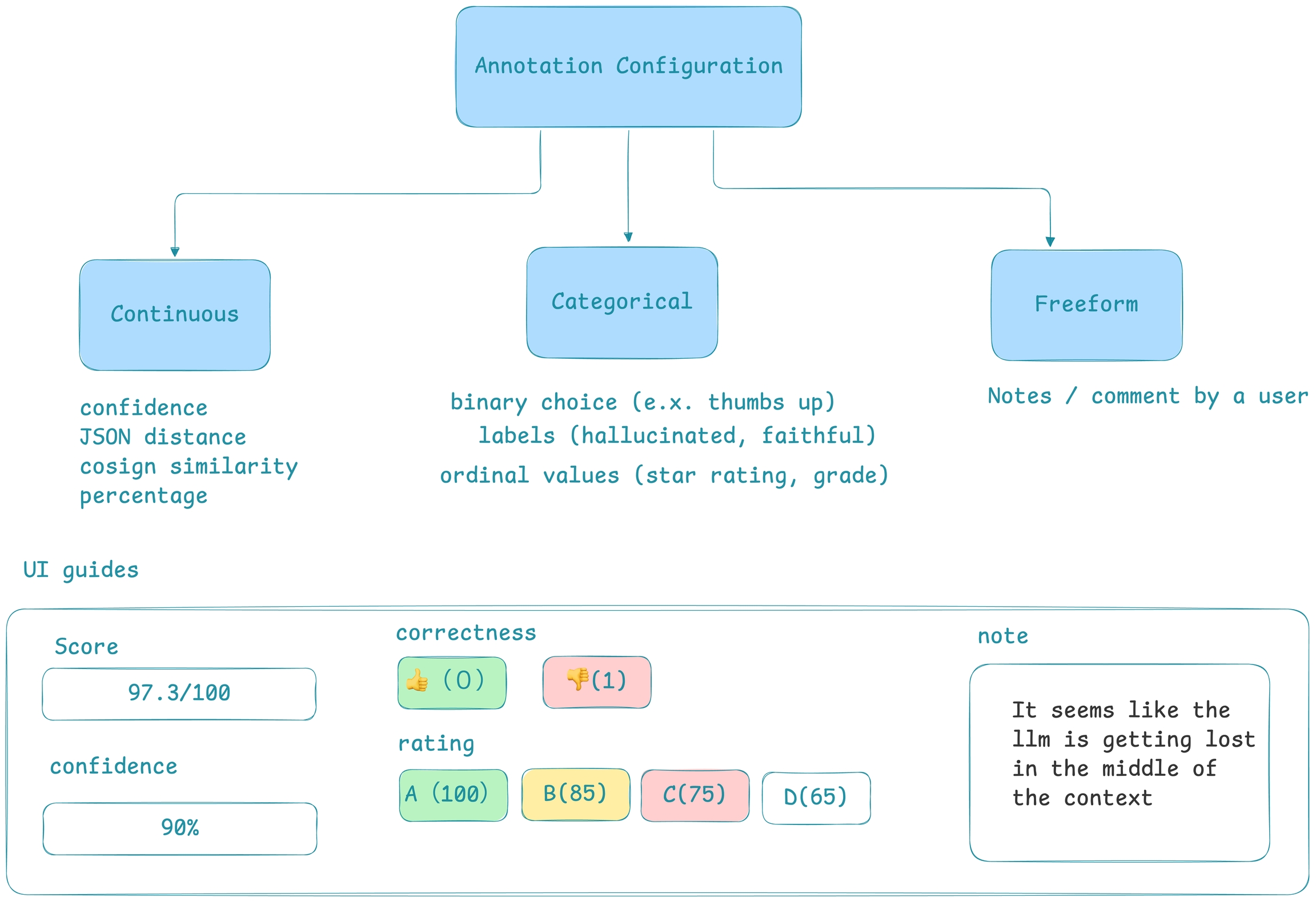
How to annotate traces in the UI for analysis and dataset curation
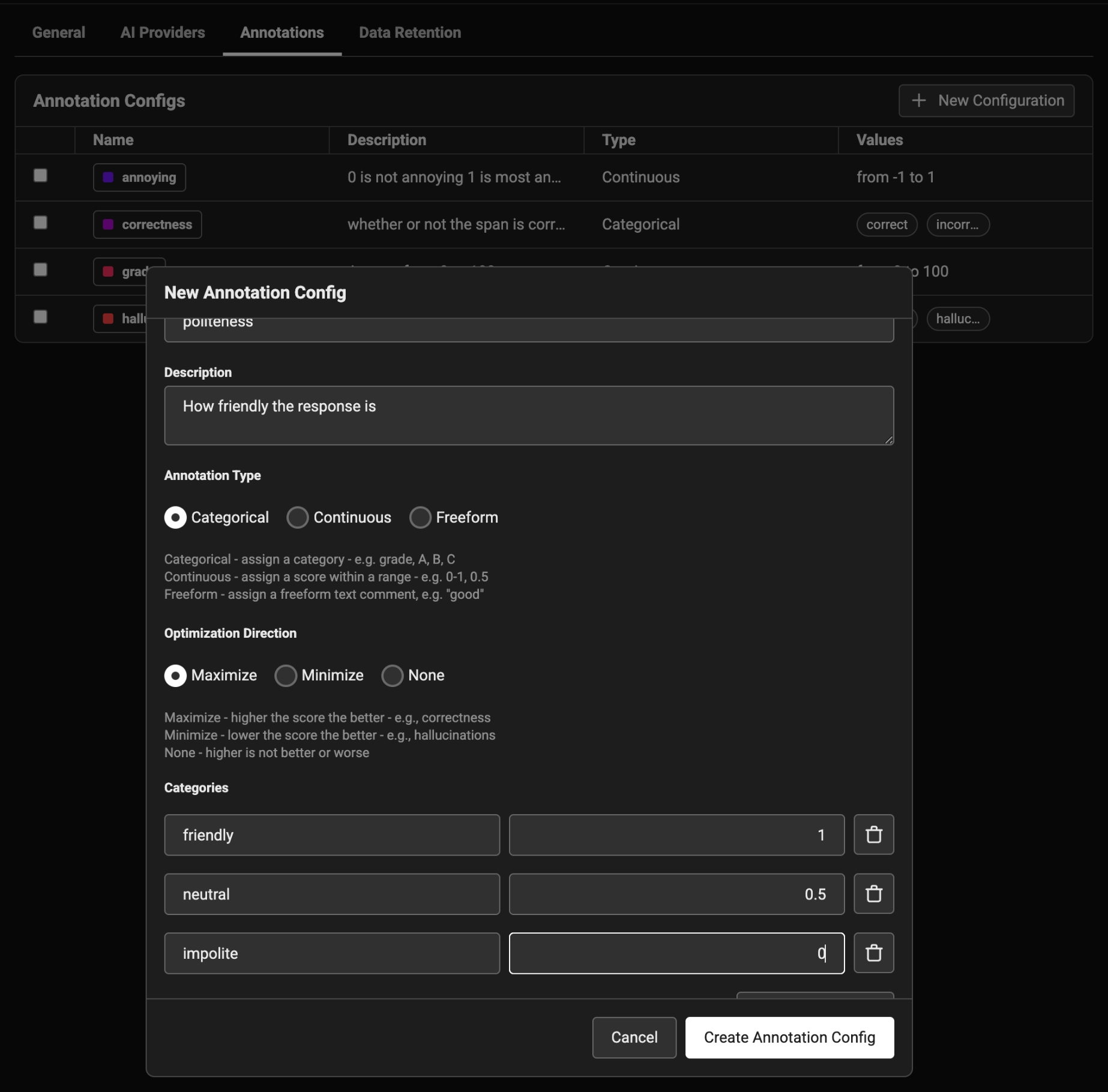
To annotate data in the UI, you first will want to setup a rubric for how to annotate. Navigate to Settings and create annotation configs (e.g. a rubric) for your data. You can create various different types of annotations: Categorical, Continuous, and Freeform.
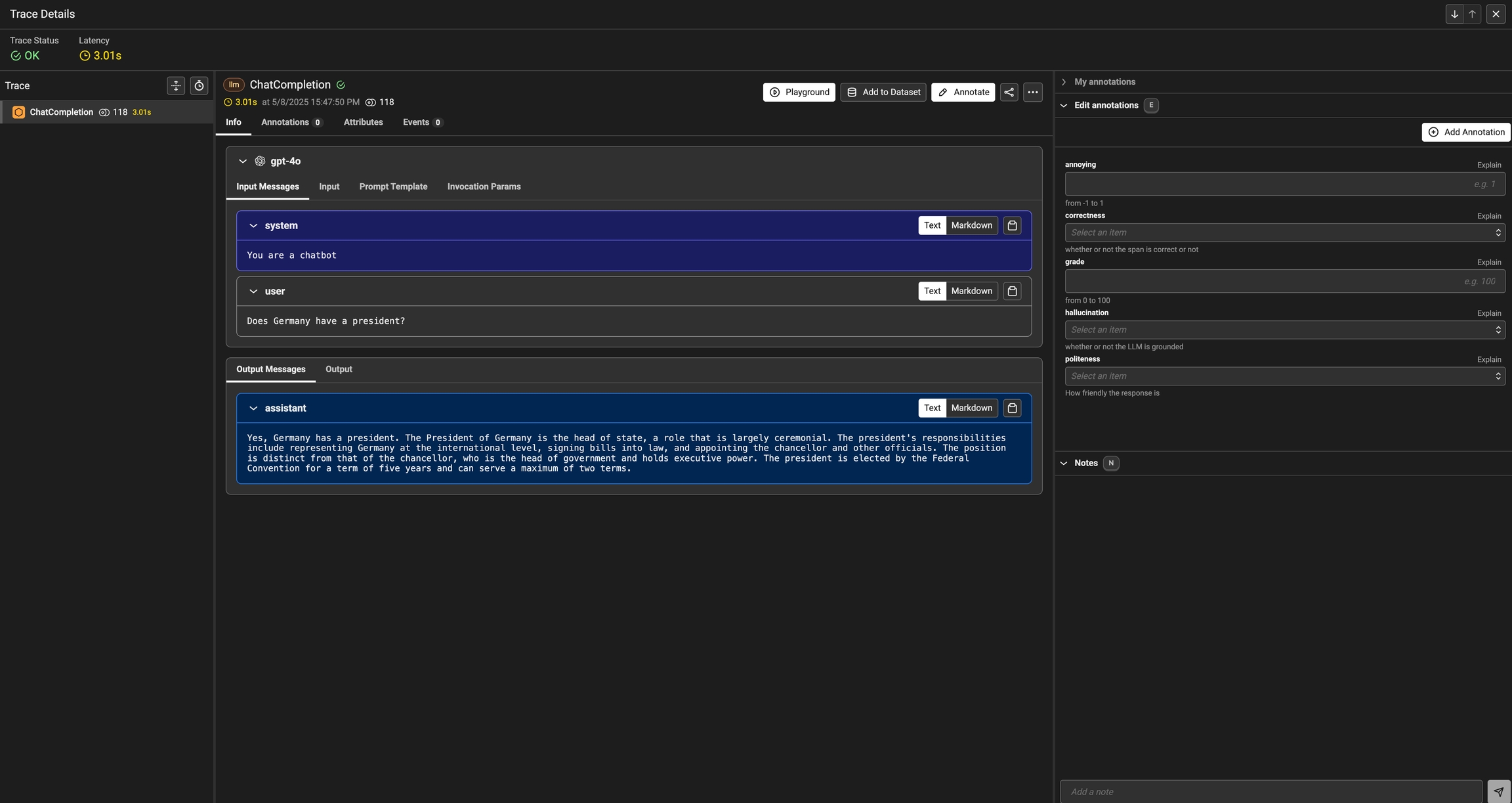
Once you have annotations configured, you can associate annotations to the data that you have traced. Click on the Annotate button and fill out the form to rate different steps in your AI application.
You can also take notes as you go by either clicking on the explain link or by adding your notes to the bottom messages UI.
You can always come back and edit / and delete your annotations. Annotations can be deleted from the table view under the Annotations tab.
Once an annotation has been provided, you can also add a reason to explain why this particular label or score was provided. This is useful to add additional context to the annotation.
As annotations come in from various sources (annotators, evals), the entire list of annotations can be found under the Annotations tab. Here you can see the author, the annotator kind (e.g. was the annotation performed by a human, llm, or code), and so on. This can be particularly useful if you want to see if different annotators disagree.
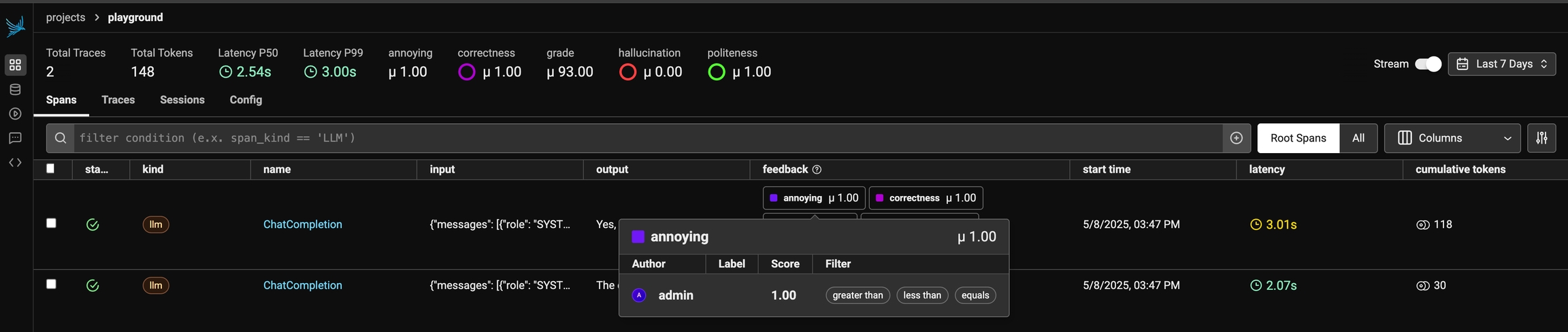
Once you have collected feedback in the form of annotations, you can filter your traces by the annotation values to narrow down to interesting samples (e.x. llm spans that are incorrect). Once filtered down to a sample of spans, you can export your selection to a dataset, which in turn can be used for things like experimentation, fine-tuning, or building a human-aligned eval.
Sometimes while instrumenting your application, you may want to filter out or modify certain spans from being sent to Phoenix. For example, you may want to filter out spans that are that contain sensitive information or contain redundant information.
To do this, you can use a custom SpanProcessor and attach it to the OpenTelemetry TracerProvider.
In this example, we're filtering out any spans that have the name "secret_span" by bypassing the on_start and on_end hooks of the inherited BatchSpanProcessor.
Notice that this logic can be extended to modify a span and redact sensitive information if preserving the span is preferred.
phoenix.otel is a lightweight wrapper around OpenTelemetry primitives with Phoenix-aware defaults.
These defaults are aware of environment variables you may have set to configure Phoenix:
PHOENIX_COLLECTOR_ENDPOINT
PHOENIX_PROJECT_NAME
PHOENIX_CLIENT_HEADERS
PHOENIX_API_KEY
PHOENIX_GRPC_PORT
phoenix.otel.registerThe phoenix.otel module provides a high-level register function to configure OpenTelemetry tracing by setting a global TracerProvider. The register function can also configure headers and whether or not to process spans one by one or by batch.
If the PHOENIX_API_KEY environment variable is set, register will automatically add an authorization header to each span payload.
There are two ways to configure the collector endpoint:
Using environment variables
Using the endpoint keyword argument
If you're setting the PHOENIX_COLLECTOR_ENDPOINT environment variable, register will
automatically try to send spans to your Phoenix server using gRPC.
endpoint directlyWhen passing in the endpoint argument, you must specify the fully qualified endpoint. If the PHOENIX_GRPC_PORT environment variable is set, it will override the default gRPC port.
The HTTP transport protocol is inferred from the endpoint
The GRPC transport protocol is inferred from the endpoint
Additionally, the protocol argument can be used to enforce the OTLP transport protocol regardless of the endpoint. This might be useful in cases such as when the GRPC endpoint is bound to a different port than the default (4317). The valid protocols are: "http/protobuf", and "grpc".
register can be configured with different keyword arguments:
project_name: The Phoenix project name
or use PHOENIX_PROJECT_NAME env. var
headers: Headers to send along with each span payload
or use PHOENIX_CLIENT_HEADERS env. var
batch: Whether or not to process spans in batch
Once you've connected your application to your Phoenix instance using phoenix.otel.register, you need to instrument your application. You have a few options to do this:
Using OpenInference auto-instrumentors. If you've used the auto_instrument flag above, then any instrumentor packages in your environment will be called automatically. For a full list of OpenInference packages, see
Using .
Using .
Instrumenting prompt templates and variables allows you to track and visualize prompt changes. These can also be combined with to measure the performance changes driven by each of your prompts.
We provide a using_prompt_template context manager to add a prompt template (including its version and variables) to the current OpenTelemetry Context. OpenInference will read this Context and pass the prompt template fields as span attributes, following the OpenInference . Its inputs must be of the following type:
Template: non-empty string.
Version: non-empty string.
Variables: a dictionary with string keys. This dictionary will be serialized to JSON when saved to the OTEL Context and remain a JSON string when sent as a span attribute.
It can also be used as a decorator:
We provide a setPromptTemplate function which allows you to set a template, version, and variables on context. You can use this utility in conjunction with to set the active context. OpenInference will then pick up these attributes and add them to any spans created within the context.with callback. The components of a prompt template are:
template - a string with templated variables ex. "hello {{name}}"
variables - an object with variable names and their values ex. {name: "world"}
version - a string version of the template ex. v1.0
All of these are optional. Application of variables to a template will typically happen before the call to an llm and may not be picked up by auto instrumentation. So, this can be helpful to add to ensure you can see the templates and variables while troubleshooting.
pip install arize-phoenix-otelfrom phoenix.otel import register
tracer_provider = register(
project_name="default", # sets a project name for spans
batch=True, # uses a batch span processor
auto_instrument=True, # uses all installed OpenInference instrumentors
)# export PHOENIX_COLLECTOR_ENDPOINT=https://your-phoenix.com:6006
from phoenix.otel import register
# sends traces to https://your-phoenix.com:4317
tracer_provider = register()# export PHOENIX_COLLECTOR_ENDPOINT=https://your-phoenix.com:6006
from phoenix.otel import register
# sends traces to https://your-phoenix.com/v1/traces
tracer_provider = register(
protocol="http/protobuf",
)from phoenix.otel import register
tracer_provider = register(endpoint="http://localhost:6006/v1/traces")from phoenix.otel import register
tracer_provider = register(endpoint="http://localhost:4317")from phoenix.otel import register
tracer_provider = register(
endpoint="http://localhost:9999",
protocol="grpc", # use "http/protobuf" for http transport
)from phoenix.otel import register
tracer_provider = register(
project_name="otel-test",
headers={"Authorization": "Bearer TOKEN"},
batch=True,
)pip install -q "arize-phoenix>=4.29.0" openinference-instrumentation-openai openai# Check if PHOENIX_API_KEY is present in the environment variables.
# If it is, we'll use the cloud instance of Phoenix. If it's not, we'll start a local instance.
# A third option is to connect to a docker or locally hosted instance.
# See https://arize.com/docs/phoenix/setup/environments for more information.
# Launch Phoenix
import os
if "PHOENIX_API_KEY" in os.environ:
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={os.environ['PHOENIX_API_KEY']}"
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com"
else:
import phoenix as px
px.launch_app().view()
# Connect to Phoenix
from phoenix.otel import register
tracer_provider = register()
# Instrument OpenAI calls in your application
from openinference.instrumentation.openai import OpenAIInstrumentor
OpenAIInstrumentor().instrument(tracer_provider=tracer_provider, skip_dep_check=True)
# Make a call to OpenAI with an image provided
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)@using_prompt_template(
template=prompt_template,
variables=prompt_template_variables,
version="v1.0",
)
def call_fn(*args, **kwargs):
# Calls within this function will generate spans with the attributes:
# "llm.prompt_template.template" = "Please describe the weather forecast for {city} on {date}"
# "llm.prompt_template.version" = "v1.0"
# "llm.prompt_template.variables" = "{\"city\": \"Johannesburg\", \"date\": \"July 11\"}" # JSON serialized
...import { context } from "@opentelemetry/api"
import { setPromptTemplate } from "@openinference-core"
context.with(
setPromptTemplate(
context.active(),
{
template: "hello {{name}}",
variables: { name: "world" },
version: "v1.0"
}
),
() => {
// Calls within this block will generate spans with the attributes:
// "llm.prompt_template.template" = "hello {{name}}"
// "llm.prompt_template.version" = "v1.0"
// "llm.prompt_template.variables" = '{ "name": "world" }'
}
)Guides on how to use traces
Setup Tracing in Python or Typescript
Add Integrations via Auto Instrumentation
Manually Instrument your application
How to set custom attributes and semantic attributes to child spans and spans created by auto-instrumentors.
Phoenix natively works with a variety of frameworks and SDKs across Python and JavaScript via OpenTelemetry auto-instrumentation. Phoenix can also be natively integrated with AI platforms such as LangFlow and LiteLLM proxy.
Create and customize spans for your use-case
How to query spans to construct DataFrames to use for evaluation
How to log evaluation results to annotate traces with evals
How to track token-based costs for your LLM applications
import os
os.environ['PHOENIX_PROJECT_NAME'] = "<your-project-name>"from phoenix.otel import register
tracer_provider = register(
project_name="my-project-name",
....
)from openinference.semconv.resource import ResourceAttributes
from openinference.instrumentation.llama_index import LlamaIndexInstrumentor
from opentelemetry import trace as trace_api
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk import trace as trace_sdk
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
resource = Resource(attributes={
ResourceAttributes.PROJECT_NAME: '<your-project-name>'
})
tracer_provider = trace_sdk.TracerProvider(resource=resource)
span_exporter = OTLPSpanExporter(endpoint="http://phoenix:6006/v1/traces")
span_processor = SimpleSpanProcessor(span_exporter=span_exporter)
tracer_provider.add_span_processor(span_processor=span_processor)
trace_api.set_tracer_provider(tracer_provider=tracer_provider)
# Add any auto-instrumentation you want
LlamaIndexInstrumentor().instrument()from phoenix.otel import register
from phoenix.otel import BatchSpanProcessor
from opentelemetry.context import Context
from opentelemetry.sdk.trace import ReadableSpan, Span
class FilteringSpanProcessor(BatchSpanProcessor):
def _filter_condition(self, span: Span) -> bool:
# returns True if the span should be filtered out
return span.name == "secret_span"
def on_start(self, span: Span, parent_context: Context) -> None:
if self._filter_condition(span):
return
super().on_start(span, parent_context)
def on_end(self, span: ReadableSpan) -> None:
if self._filter_condition(span):
logger.info("Filtering span: %s", span.name)
return
super().on_end(span)
tracer_provider = register()
tracer_provider.add_span_processor(
FilteringSpanProcessor(
endpoint="http://localhost:6006/v1/traces",
protocol="http/protobuf",
)
)from openinference.instrumentation import using_prompt_template
prompt_template = "Please describe the weather forecast for {city} on {date}"
prompt_template_variables = {"city": "Johannesburg", "date":"July 11"}
with using_prompt_template(
template=prompt_template,
variables=prompt_template_variables,
version="v1.0",
):
# Commonly preceeds a chat completion to append templates to auto instrumentation
# response = client.chat.completions.create()
# Calls within this block will generate spans with the attributes:
# "llm.prompt_template.template" = "Please describe the weather forecast for {city} on {date}"
# "llm.prompt_template.version" = "v1.0"
# "llm.prompt_template.variables" = "{\"city\": \"Johannesburg\", \"date\": \"July 11\"}" # JSON serialized
...Use the phoenix client to capture end-user feedback
When building LLM applications, it is important to collect feedback to understand how your app is performing in production. Phoenix lets you attach feedback to spans and traces in the form of annotations.
Annotations come from a few different sources:
Human Annotators
End users of your application
LLMs-as-Judges
Basic code checks
You can use the Phoenix SDK and API to attach feedback to a span.
Phoenix expects feedback to be in the form of an annotation. Annotations consist of these fields:
{
"span_id": "67f6740bbe1ddc3f", // the id of the span to annotate
"name": "correctness", // the name of your annotation
"annotator_kind": "HUMAN", // HUMAN, LLM, or CODE
"result": {
"label": "correct", // A human-readable category for the feedback
"score": 0.85, // a numeric score, can be 0 or 1, or a range like 0 to 100
"explanation": "The response answered the question I asked"
},
"metadata": {
"model": "gpt-4",
"threshold_ms": 500,
"confidence": "high"
},
"identifier": "user-123" // optional, identifies the annotation and enables upserts
}Note that you can provide a label, score, or explanation. With Phoenix an annotation has a name (like correctness), is associated with an annotator (LLM, HUMAN, or CODE), and can be attached to the spans you have logged to Phoenix.
Phoenix allows you to log multiple annotations of the same name to the same span. For example, a single span could have 5 different "correctness" annotations. This can be useful when collecting end user feedback.
Note: The API will overwrite span annotations of the same name, unless they have different "identifier" values.
If you want to track multiple annotations of the same name on the same span, make sure to include different "identifier" values on each.
Once you construct the annotation, you can send this to Phoenix via it's REST API. You can POST an annotation from your application to /v1/span_annotations like so:
If you're self-hosting Phoenix, be sure to change the endpoint in the code below to <your phoenix endpoint>/v1/span_annotations?sync=false
Retrieve the current span_id
If you'd like to collect feedback on currently instrumented code, you can get the current span using the opentelemetry SDK.
from opentelemetry.trace import format_span_id, get_current_span
span = get_current_span()
span_id = format_span_id(span.get_span_context().span_id)You can use the span_id to send an annotation associated with that span.
from phoenix.client import Client
client = Client()
annotation = client.annotations.add_span_annotation(
annotation_name="user feedback",
annotator_kind="HUMAN",
span_id=span_id,
label="thumbs-up",
score=1,
)Retrieve the current spanId
import { trace } from "@opentelemetry/api";
async function chat(req, res) {
// ...
const spanId = trace.getActiveSpan()?.spanContext().spanId;
}You can use the spanId to send an annotation associated with that span.
import { createClient } from '@arizeai/phoenix-client';
const PHOENIX_API_KEY = 'your_api_key';
const px = createClient({
options: {
// change to self-hosted base url if applicable
baseUrl: 'https://app.phoenix.arize.com',
headers: {
api_key: PHOENIX_API_KEY,
Authorization: `Bearer ${PHOENIX_API_KEY}`,
},
},
});
export async function postFeedback(
spanId: string,
name: string,
label: string,
score: number,
explanation?: string,
metadata?: Record<string, unknown>
) {
const response = await px.POST('/v1/span_annotations', {
params: { query: { sync: true } },
body: {
data: [
{
span_id: spanId,
name: name,
annotator_kind: 'HUMAN',
result: {
label: label,
score: score,
explanation: explanation || null,
},
metadata: metadata || {},
},
],
},
});
if (!response || !response.data) {
throw new Error('Annotation failed');
}
return response.data.data;
}curl -X 'POST' \
'https://app.phoenix.arize.com/v1/span_annotations?sync=false' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'api_key: <your phoenix api key> \
-d '{
"data": [
{
"span_id": "67f6740bbe1ddc3f",
"name": "correctness",
"annotator_kind": "HUMAN",
"result": {
"label": "correct",
"score": 0.85,
"explanation": "The response answered the question I asked"
},
"metadata": {
"model": "gpt-4",
"threshold_ms": 500,
"confidence": "high"
}
}
]
}'This guide shows how LLM evaluation results in dataframes can be sent to Phoenix.
An evaluation must have a name (e.g. "Q&A Correctness") and its DataFrame must contain identifiers for the subject of evaluation, e.g. a span or a document (more on that below), and values under either the score, label, or explanation columns. See for more information.
Before accessing px.Client(), be sure you've set the following environment variables:
A dataframe of span evaluations would look similar like the table below. It must contain span_id as an index or as a column. Once ingested, Phoenix uses the span_id to associate the evaluation with its target span.
The evaluations dataframe can be sent to Phoenix as follows. Note that the name of the evaluation must be supplied through the eval_name= parameter. In this case we name it "Q&A Correctness".
A dataframe of document evaluations would look something like the table below. It must contain span_id and document_position as either indices or columns. document_position is the document's (zero-based) index in the span's list of retrieved documents. Once ingested, Phoenix uses the span_id and document_position to associate the evaluation with its target span and document.
The evaluations dataframe can be sent to Phoenix as follows. Note that the name of the evaluation must be supplied through the eval_name= parameter. In this case we name it "Relevance".
Multiple sets of Evaluations can be logged by the same px.Client().log_evaluations() function call.
By default the client will push traces to the project specified in the PHOENIX_PROJECT_NAME environment variable or to the default project. If you want to specify the destination project explicitly, you can pass the project name as a parameter.
Use the capture_span_context context manager to annotate auto-instrumented spans
When working with spans that are automatically instrumented via in your LLM applications, you often need to capture span contexts to apply feedback or annotations. The capture_span_context context manager provides a convenient way to capture all OpenInference spans within its scope, making it easier to apply feedback to specific spans in downstream operations.
The capture_span_context context manager allows you to:
Capture all spans created within a specific code block
Retrieve span contexts for later use in feedback systems
Maintain a clean separation between span creation and annotation logic
Apply feedback to spans without needing to track span IDs manually
Access both the first and last spans in a trace topology for targeted feedback
When your LLM application executes, it creates a hierarchy of spans representing different operations. For example, when using a framework, you might have:
The capture_span_context context manager helps you easily access:
First span: The root span of your operation (useful for high-level feedback and evaluations)
Last span: The most recent span created (often the final LLM call, useful for LLM-specific feedback)
All spans: A complete list of all spans created within the context (useful for comprehensive analysis)
Use the first span (get_first_span_id()) when:
Adding user feedback about the overall experience
Recording evaluation scores for the entire request/response cycle
Use the last span (get_last_span_id()) when:
The last span represents an LLM invocation
You want to annotate the final output or generation step
Applying feedback specifically to the model's response quality
Recording model-specific metrics or evaluations
You can also access all spans for more complex annotation scenarios:
You can filter spans based on their attributes:
In some situations, you may need to modify the observability level of your tracing. For instance, you may want to keep sensitive information from being logged for security reasons, or you may want to limit the size of the base64 encoded images logged to reduced payload size.
The OpenInference Specification defines a set of environment variables you can configure to suit your observability needs. In addition, the OpenInference auto-instrumentors accept a trace config which allows you to set these value in code without having to set environment variables, if that's what you prefer
The possible settings are:
To set up this configuration you can either:
Set environment variables as specified above
Define the configuration in code as shown below
Do nothing and fall back to the default values
Use a combination of the three, the order of precedence is:
Values set in the TraceConfig in code
Environment variables
default values
Below is an example of how to set these values in code using our OpenAI Python and JavaScript instrumentors, however, the config is respected by all of our auto-instrumentors.
How to use an LLM judge to label and score your application
This guide will walk you through the process of evaluating traces captured in Phoenix, and exporting the results to the Phoenix UI.
This process is similar to the , but instead of creating your own dataset or using an existing external one, you'll export a trace dataset from Phoenix and log the evaluation results to Phoenix.
Note: if you're self-hosting Phoenix, swap your collector endpoint variable in the snippet below, and remove the Phoenix Client Headers variable.
Now that we have Phoenix configured, we can register that instance with OpenTelemetry, which will allow us to collect traces from our application here.
For the sake of making this guide fully runnable, we'll briefly generate some traces and track them in Phoenix. Typically, you would have already captured traces in Phoenix and would skip to "Download trace dataset from Phoenix"
Now that we have our trace dataset, we can generate evaluations for each trace. Evaluations can be generated in many different ways. Ultimately, we want to end up with a set of labels and/or scores for our traces.
You can generate evaluations using:
Plain code
Phoenix's
Your own
Other evaluation packages
As long as you format your evaluation results properly, you can upload them to Phoenix and visualize them in the UI.
Let's start with a simple example of generating evaluations using plain code. OpenAI has a habit of repeating jokes, so we'll generate evaluations to label whether a joke is a repeat of a previous joke.
We now have a DataFrame with a column for whether each joke is a repeat of a previous joke. Let's upload this to Phoenix.
Our evals_df has a column for the span_id and a column for the evaluation result. The span_id is what allows us to connect the evaluation to the correct trace in Phoenix. Phoenix will also automatically look for columns named "label" and "score" to display in the UI.
You should now see evaluations in the Phoenix UI!
From here you can continue collecting and evaluating traces, or move on to one of these other guides:
If you're interested in more complex evaluation and evaluators, start with
If you're ready to start testing your application in a more rigorous manner, check out
OPENINFERENCE_HIDE_INPUTS
Hides input value, all input messages & embedding input text
bool
False
OPENINFERENCE_HIDE_OUTPUTS
Hides output value & all output messages
bool
False
OPENINFERENCE_HIDE_INPUT_MESSAGES
Hides all input messages & embedding input text
bool
False
OPENINFERENCE_HIDE_OUTPUT_MESSAGES
Hides all output messages
bool
False
PENINFERENCE_HIDE_INPUT_IMAGES
Hides images from input messages
bool
False
OPENINFERENCE_HIDE_INPUT_TEXT
Hides text from input messages & input embeddings
bool
False
OPENINFERENCE_HIDE_OUTPUT_TEXT
Hides text from output messages
bool
False
OPENINFERENCE_HIDE_EMBEDDING_VECTORS
Hides returned embedding vectors
bool
False
OPENINFERENCE_HIDE_LLM_INVOCATION_PARAMETERS
Hides LLM invocation parameters
bool
False
OPENINFERENCE_HIDE_LLM_PROMPTS
Hides LLM prompts span attributes
bool
False
OPENINFERENCE_BASE64_IMAGE_MAX_LENGTH
Limits characters of a base64 encoding of an image
int
32,000
from openinference.instrumentation import TraceConfig
config = TraceConfig(
hide_inputs=...,
hide_outputs=...,
hide_input_messages=...,
hide_output_messages=...,
hide_input_images=...,
hide_input_text=...,
hide_output_text=...,
hide_embedding_vectors=...,
hide_llm_invocation_parameters=...,
hide_llm_prompts=...,
base64_image_max_length=...,
)
from openinference.instrumentation.openai import OpenAIInstrumentor
OpenAIInstrumentor().instrument(
tracer_provider=tracer_provider,
config=config,
)/**
* Everything left out of here will fallback to
* environment variables then defaults
*/
const traceConfig = { hideInputs: true }
const instrumentation = new OpenAIInstrumentation({ traceConfig })import os
# Used by local phoenix deployments with auth:
os.environ["PHOENIX_API_KEY"] = "..."
# Used by Phoenix Cloud deployments:
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key=..."
# Be sure to modify this if you're self-hosting Phoenix:
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com"5B8EF798A381
correct
"this is correct ..."
E19B7EC3GG02
incorrect
"this is incorrect ..."
from phoenix.trace import SpanEvaluations
import os
px.Client().log_evaluations(
SpanEvaluations(
dataframe=qa_correctness_eval_df,
eval_name="Q&A Correctness",
),
)5B8EF798A381
relevant
"this is ..."
5B8EF798A381
irrelevant
"this is ..."
E19B7EC3GG02
relevant
"this is ..."
from phoenix.trace import DocumentEvaluations
px.Client().log_evaluations(
DocumentEvaluations(
dataframe=document_relevance_eval_df,
eval_name="Relevance",
),
)px.Client().log_evaluations(
SpanEvaluations(
dataframe=qa_correctness_eval_df,
eval_name="Q&A Correctness",
),
DocumentEvaluations(
dataframe=document_relevance_eval_df,
eval_name="Relevance",
),
SpanEvaluations(
dataframe=hallucination_eval_df,
eval_name="Hallucination",
),
# ... as many as you like
)from phoenix.trace import SpanEvaluations
px.Client().log_evaluations(
SpanEvaluations(
dataframe=qa_correctness_eval_df,
eval_name="Q&A Correctness",
),
project_name="<my-project>"
)framework (root span)
├── span 1 (query processing)
│ └── span 2 (LLM call)
└── span 3 (response formatting)from openinference.instrumentation import capture_span_context
from phoenix.client import Client
client = Client()
def process_llm_request_with_feedback(prompt: str):
with capture_span_context() as capture:
# This creates multiple spans in a hierarchy when using a framework
response = llm.invoke("Generate a summary")
# Get user feedback (simulated)
user_feedback = get_user_feedback(response)
# Method 1: Get first span ID (root span - good for user feedback)
first_span_id = capture.get_first_span_id()
if first_span_id:
# Apply user feedback to the first span
client.annotations.add_span_annotation(
annotation_name="user_feedback",
annotator_kind="HUMAN",
span_id=first_span_id,
label=user_feedback.label,
score=user_feedback.score,
explanation=user_feedback.explanation
)
# Method 2: Get last span ID (most recent span - often the LLM call)
last_span_id = capture.get_last_span_id()
if last_span_id:
# Apply feedback to the most recent span
client.annotations.add_span_annotation(
annotation_name="llm_response_quality",
annotator_kind="HUMAN",
span_id=last_span_id,
label="helpful",
score=4,
explanation="The LLM provided a helpful and relevant response"
)with capture_span_context() as capture:
# Make LLM call (auto-instrumented)
response = llm.invoke("Generate a summary")
# Get all captured span contexts
span_contexts = capture.get_span_contexts()
# Apply different feedback logic to different spans
for i, span_context in enumerate(span_contexts):
span_id = format_span_id(span_context.span_id)
client.annotations.add_span_annotation(
annotation_name="span_order",
annotator_kind="CODE",
span_id=span_id,
label=f"span_{i}",
metadata={"position": i, "total_spans": len(span_contexts)}
)with capture_span_context() as capture:
# Make LLM call (auto-instrumented)
response = llm.invoke("Generate a summary")
span_contexts = capture.get_span_contexts()
# Filter for specific span types
llm_spans = [
ctx for ctx in span_contexts
if hasattr(ctx, 'attributes')
]
# Apply different feedback logic to different span types
for span_context in llm_spans:
apply_llm_feedback(span_context)pip install -q "arize-phoenix>=4.29.0"
pip install -q openai 'httpx<0.28'import os
from getpass import getpass
import dotenv
dotenv.load_dotenv()
if not (openai_api_key := os.getenv("OPENAI_API_KEY")):
openai_api_key = getpass("🔑 Enter your OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = openai_api_keyimport os
PHOENIX_API_KEY = "ADD YOUR API KEY"
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com"from phoenix.otel import register
tracer_provider = register(project_name="evaluating_traces_quickstart")%%bash
pip install -q openinference-instrumentation-openaifrom openinference.instrumentation.openai import OpenAIInstrumentor
OpenAIInstrumentor().instrument(tracer_provider=tracer_provider)from openai import OpenAI
# Initialize OpenAI client
client = OpenAI()
# Function to generate a joke
def generate_joke():
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant that generates jokes."},
{"role": "user", "content": "Tell me a joke."},
],
)
joke = response.choices[0].message.content
return joke
# Generate 5 different jokes
jokes = []
for _ in range(5):
joke = generate_joke()
jokes.append(joke)
print(f"Joke {len(jokes)}:\n{joke}\n")
print(f"Generated {len(jokes)} jokes and tracked them in Phoenix.")import phoenix as px
spans_df = px.Client().get_spans_dataframe(project_name="evaluating_traces_quickstart")
spans_df.head()# Create a new DataFrame with selected columns
eval_df = spans_df[["context.span_id", "attributes.llm.output_messages"]].copy()
eval_df.set_index("context.span_id", inplace=True)
# Create a list to store unique jokes
unique_jokes = set()
# Function to check if a joke is a duplicate
def is_duplicate(joke_data):
joke = joke_data[0]["message.content"]
if joke in unique_jokes:
return True
else:
unique_jokes.add(joke)
return False
# Apply the is_duplicate function to create the new column
eval_df["label"] = eval_df["attributes.llm.output_messages"].apply(is_duplicate)
# Convert boolean to integer (0 for False, 1 for True)
eval_df["label"] = eval_df["label"]
# Reset unique_jokes list to ensure correct results if the cell is run multiple times
unique_jokes.clear()eval_df["score"] = eval_df["score"].astype(int)
eval_df["label"] = eval_df["label"].astype(str)from phoenix.trace import SpanEvaluations
px.Client().log_evaluations(SpanEvaluations(eval_name="Duplicate", dataframe=eval_df))
In order to customize spans that are created via auto-instrumentation, The Otel Context can be used to set span attributes created during a block of code (think child spans or spans under that block of code). Our openinference packages offer convenient tools to write and read from the OTel Context. The benefit of this approach is that OpenInference auto instrumentors will pass (e.g. inherit) these attributes to all spans underneath a parent trace.
Supported Context Attributes include:
Session ID* Unique identifier for a session
User ID* Unique identifier for a user.
Metadata Metadata associated with a span.
Tags* List of tags to give the span a category.
Prompt Template
Template Used to generate prompts as Python f-strings.
Version The version of the prompt template.
Variables key-value pairs applied to the prompt template.
Install the core instrumentation package:
pip install openinference-instrumentationnpm install --save @arizeai/openinference-core @opentelemetry/apiWe provide a using_session context manager to add session a ID to the current OpenTelemetry Context. OpenInference auto instrumentators will read this Context and pass the session ID as a span attribute, following the OpenInference semantic conventions. Its input, the session ID, must be a non-empty string.
from openinference.instrumentation import using_session
with using_session(session_id="my-session-id"):
# Calls within this block will generate spans with the attributes:
# "session.id" = "my-session-id"
...It can also be used as a decorator:
@using_session(session_id="my-session-id")
def call_fn(*args, **kwargs):
# Calls within this function will generate spans with the attributes:
# "session.id" = "my-session-id"
...We provide a setSession function which allows you to set a sessionId on context. You can use this utility in conjunction with context.with to set the active context. OpenInference auto instrumentations will then pick up these attributes and add them to any spans created within the context.with callback.
import { context } from "@opentelemetry/api"
import { setSession } from "@openinference-core"
context.with(
setSession(context.active(), { sessionId: "session-id" }),
() => {
// Calls within this block will generate spans with the attributes:
// "session.id" = "session-id"
}
)We provide a using_user context manager to add user ID to the current OpenTelemetry Context. OpenInference auto instrumentators will read this Context and pass the user ID as a span attribute, following the OpenInference semantic conventions. Its input, the user ID, must be a non-empty string.
from openinference.instrumentation import using_user
with using_user("my-user-id"):
# Calls within this block will generate spans with the attributes:
# "user.id" = "my-user-id"
...It can also be used as a decorator:
@using_user("my-user-id")
def call_fn(*args, **kwargs):
# Calls within this function will generate spans with the attributes:
# "user.id" = "my-user-id"
...We provide a setUser function which allows you to set a userId on context. You can use this utility in conjunction with context.with to set the active context. OpenInference auto instrumentations will then pick up these attributes and add them to any spans created within the context.with callback.
import { context } from "@opentelemetry/api"
import { setUser } from "@openinference-core"
context.with(
setUser(context.active(), { userId: "user-id" }),
() => {
// Calls within this block will generate spans with the attributes:
// "user.id" = "user-id"
}
)We provide a using_metadata context manager to add metadata to the current OpenTelemetry Context. OpenInference auto instrumentators will read this Context and pass the metadata as a span attribute, following the OpenInference semantic conventions. Its input, the metadata, must be a dictionary with string keys. This dictionary will be serialized to JSON when saved to the OTEL Context and remain a JSON string when sent as a span attribute.
from openinference.instrumentation import using_metadata
metadata = {
"key-1": value_1,
"key-2": value_2,
...
}
with using_metadata(metadata):
# Calls within this block will generate spans with the attributes:
# "metadata" = "{\"key-1\": value_1, \"key-2\": value_2, ... }" # JSON serialized
...It can also be used as a decorator:
@using_metadata(metadata)
def call_fn(*args, **kwargs):
# Calls within this function will generate spans with the attributes:
# "metadata" = "{\"key-1\": value_1, \"key-2\": value_2, ... }" # JSON serialized
...We provide a setMetadata function which allows you to set a metadata attributes on context. You can use this utility in conjunction with context.with to set the active context. OpenInference auto instrumentations will then pick up these attributes and add them to any spans created within the context.with callback. Metadata attributes will be serialized to a JSON string when stored on context and will be propagated to spans in the same way.
import { context } from "@opentelemetry/api"
import { setMetadata } from "@openinference-core"
context.with(
setMetadata(context.active(), { key1: "value1", key2: "value2" }),
() => {
// Calls within this block will generate spans with the attributes:
// "metadata" = '{"key1": "value1", "key2": "value2"}'
}
)We provide a using_tags context manager to add tags to the current OpenTelemetry Context. OpenInference auto instrumentators will read this Context and pass the tags as a span attribute, following the OpenInference semantic conventions. The input, the tag list, must be a list of strings.
from openinference.instrumentation import using_tags
tags = ["tag_1", "tag_2", ...]
with using_tags(tags):
# Calls within this block will generate spans with the attributes:
# "tag.tags" = "["tag_1","tag_2",...]"
...It can also be used as a decorator:
@using_tags(tags)
def call_fn(*args, **kwargs):
# Calls within this function will generate spans with the attributes:
# "tag.tags" = "["tag_1","tag_2",...]"
...We provide a setTags function which allows you to set a list of string tags on context. You can use this utility in conjunction with context.with to set the active context. OpenInference auto instrumentations will then pick up these attributes and add them to any spans created within the context.with callback. Tags, like metadata, will be serialized to a JSON string when stored on context and will be propagated to spans in the same way.
import { context } from "@opentelemetry/api"
import { setTags } from "@openinference-core"
context.with(
setTags(context.active(), ["value1", "value2"]),
() => {
// Calls within this block will generate spans with the attributes:
// "tag.tags" = '["value1", "value2"]'
}
)We provide a using_attributes context manager to add attributes to the current OpenTelemetry Context. OpenInference auto instrumentators will read this Context and pass the attributes fields as span attributes, following the OpenInference semantic conventions. This is a convenient context manager to use if you find yourself using many of the previous ones in conjunction.
from openinference.instrumentation import using_attributes
tags = ["tag_1", "tag_2", ...]
metadata = {
"key-1": value_1,
"key-2": value_2,
...
}
prompt_template = "Please describe the weather forecast for {city} on {date}"
prompt_template_variables = {"city": "Johannesburg", "date":"July 11"}
prompt_template_version = "v1.0"
with using_attributes(
session_id="my-session-id",
user_id="my-user-id",
metadata=metadata,
tags=tags,
prompt_template=prompt_template,
prompt_template_version=prompt_template_version,
prompt_template_variables=prompt_template_variables,
):
# Calls within this block will generate spans with the attributes:
# "session.id" = "my-session-id"
# "user.id" = "my-user-id"
# "metadata" = "{\"key-1\": value_1, \"key-2\": value_2, ... }" # JSON serialized
# "tag.tags" = "["tag_1","tag_2",...]"
# "llm.prompt_template.template" = "Please describe the weather forecast for {city} on {date}"
# "llm.prompt_template.variables" = "{\"city\": \"Johannesburg\", \"date\": \"July 11\"}" # JSON serialized
# "llm.prompt_template.version " = "v1.0"
...The previous example is equivalent to doing the following, making using_attributes a very convenient tool for the more complex settings.
with (
using_session("my-session-id"),
using_user("my-user-id"),
using_metadata(metadata),
using_tags(tags),
using_prompt_template(
template=prompt_template,
version=prompt_template_version,
variables=prompt_template_variables,
),
):
# Calls within this block will generate spans with the attributes:
# "session.id" = "my-session-id"
# "user.id" = "my-user-id"
# "metadata" = "{\"key-1\": value_1, \"key-2\": value_2, ... }" # JSON serialized
# "tag.tags" = "["tag_1","tag_2",...]"
# "llm.prompt_template.template" = "Please describe the weather forecast for {city} on {date}"
# "llm.prompt_template.variables" = "{\"city\": \"Johannesburg\", \"date\": \"July 11\"}" # JSON serialized
# "llm.prompt_template.version " = "v1.0"
...It can also be used as a decorator:
@using_attributes(
session_id="my-session-id",
user_id="my-user-id",
metadata=metadata,
tags=tags,
prompt_template=prompt_template,
prompt_template_version=prompt_template_version,
prompt_template_variables=prompt_template_variables,
)
def call_fn(*args, **kwargs):
# Calls within this function will generate spans with the attributes:
# "session.id" = "my-session-id"
# "user.id" = "my-user-id"
# "metadata" = "{\"key-1\": value_1, \"key-2\": value_2, ... }" # JSON serialized
# "tag.tags" = "["tag_1","tag_2",...]"
# "llm.prompt_template.template" = "Please describe the weather forecast for {city} on {date}"
# "llm.prompt_template.variables" = "{\"city\": \"Johannesburg\", \"date\": \"July 11\"}" # JSON serialized
# "llm.prompt_template.version " = "v1.0"
...We provide a setAttributes function which allows you to add a set of attributes to context. You can use this utility in conjunction with context.with to set the active context. OpenInference auto instrumentations will then pick up these attributes and add them to any spans created within the context.with callback. Attributes set on context using setAttributes must be valid span attribute values.
import { context } from "@opentelemetry/api"
import { setAttributes } from "@openinference-core"
context.with(
setAttributes(context.active(), { myAttribute: "test" }),
() => {
// Calls within this block will generate spans with the attributes:
// "myAttribute" = "test"
}
)You can also use multiple setters at the same time to propagate multiple attributes to the span below. Since each setter function returns a new context, they can be used together as follows.
import { context } from "@opentelemetry/api"
import { setAttributes } from "@openinference-core"
context.with(
setAttributes(
setSession(context.active(), { sessionId: "session-id"}),
{ myAttribute: "test" }
),
() => {
// Calls within this block will generate spans with the attributes:
// "myAttribute" = "test"
// "session.id" = "session-id"
}
)You can also use setAttributes in conjunction with the OpenInference Semantic Conventions to set OpenInference attributes manually.
import { context } from "@opentelemetry/api"
import { setAttributes } from "@openinference-core"
import { SemanticConventions } from "@arizeai/openinference-semantic-conventions";
context.with(
setAttributes(
{ [SemanticConventions.SESSION_ID: "session-id" }
),
() => {
// Calls within this block will generate spans with the attributes:
// "session.id" = "session-id"
}
)The tutorials and code snippets in these docs default to the SimpleSpanProcessor. A SimpleSpanProcessor processes and exports spans as they are created. This means that if you create 5 spans, each will be processed and exported before the next span is created in code. This can be helpful in scenarios where you do not want to risk losing a batch, or if you’re experimenting with OpenTelemetry in development. However, it also comes with potentially significant overhead, especially if spans are being exported over a network - each time a call to create a span is made, it would be processed and sent over a network before your app’s execution could continue.
The BatchSpanProcessor processes spans in batches before they are exported. This is usually the right processor to use for an application in production but it does mean spans may take some time to show up in Phoenix.
In production we recommend the BatchSpanProcessor over SimpleSpanProcessor
when deployed and the SimpleSpanProcessor when developing.
from phoenix.otel import register
# configure the Phoenix tracer for batch processing
tracer_provider = register(
project_name="my-llm-app", # Default is 'default'
batch=True, # Default is 'False'
)from opentelemetry.sdk.trace.export import SimpleSpanProcessor, BatchSpanProcessor
tracer_provider.add_span_processor(BatchSpanProcessor(OTLPSpanExporter(endpoint)))
Phoenix allows you to track token-based costs for LLM runs automatically. The costs are calculated from token counts and model pricing data, then rolled up to the trace and project level for comprehensive cost analysis.
In most cases it is simplest to let Phoenix handle cost calculation using its built-in model pricing table. When custom pricing is required, you can create custom cost configurations in Settings > Models.
For Phoenix to accurately derive costs for LLM spans, you need to provide token counts in your traces:
If you are using OpenInference auto-instrumentation with OpenAI, Anthropic, or other supported instrumentation, token counts and model information are automatically captured.
If you are manually instrumenting your code, you should include the appropriate token count attributes in your spans.
If you are using OpenTelemetry directly, ensure that your LLM spans include the OpenInference semantic conventions for token counts.
Phoenix uses the OpenInference semantic conventions for cost tracking. The following attributes are required:
llm.token_count.prompt
Integer
The number of tokens in the prompt
llm.token_count.completion
Integer
The number of tokens in the completion
llm.token_count.total
Integer
Total number of tokens, including prompt and completion
llm.model_name
String
The name of the language model being utilized
llm.provider
String
The hosting provider of the llm (e.g., openai, anthropic, azure)
For more granular cost tracking, you can provide detailed token counts:
llm.token_count.prompt_details.cache_read
Integer
The number of tokens read from previously cached prompts
llm.token_count.prompt_details.cache_write
Integer
The number of tokens written to cache
llm.token_count.prompt_details.audio
Integer
The number of audio input tokens presented in the prompt
llm.token_count.completion_details.reasoning
Integer
The number of tokens used for model reasoning
llm.token_count.completion_details.audio
Integer
The number of audio input tokens generated by the model
Phoenix includes a comprehensive model pricing table with built-in support for popular models from:
OpenAI: GPT-3.5, GPT-4, GPT-4 Turbo, GPT-4o, and newer models
Anthropic: Claude 1.x, Claude 2.x, Claude 3.x, Claude 3.5 models
Google: Gemini 1.0, Gemini 1.5, Gemini 2.0 models
Other providers: Additional models as they become available
You can view and manage model pricing through the Phoenix UI:
Navigate to Settings → Models in the Phoenix interface
View existing models and their pricing information
Add custom models or override pricing for existing models
Set different prices for prompt (input) and completion (output) tokens
To add pricing for a model not in the built-in table:
Click Add new model in the Models settings page
Fill in the model details:
Model Name: Human-readable name for the model
Name Pattern: Regex pattern to match the model name in traces
Provider: Model provider (optional)
Prompt (Input) Cost: Cost per 1M input tokens
Completion (Output) Cost: Cost per 1M output tokens
Start Date: When this pricing becomes effective (optional)
For models with complex pricing structures, you can configure detailed token pricing:
Prompt Price Breakdown: Different rates for cache_read, cache_write, audio, image, video tokens
Completion Price Breakdown: Different rates for reasoning, audio, image tokens
Provider Matching: Match models by provider to avoid naming conflicts
Once configured, Phoenix automatically displays cost information throughout the interface:
Total cost for the entire trace
Breakdown by prompt vs completion costs
Individual span costs with detailed breakdowns
Token type-specific cost details
Aggregated costs across all traces within a session
Session-based cost analysis for multi-turn conversations
Cost tracking for extended user interactions
Phoenix automatically tracks costs for traced experiments, providing detailed cost analysis across experiment runs:
Total experiment cost: Sum of all LLM costs across all experiment runs
Cost per experiment run: Individual cost for each dataset example run through an experiment Experiment costs are automatically calculated when you:
Run experiments on datasets through Phoenix
Include proper token count and model information in your traced LLM calls
Have model pricing configured for the models used in experiments
Total costs across all traces in a project
Cost trends over time (coming-soon)
Most expensive models (coming-soon)
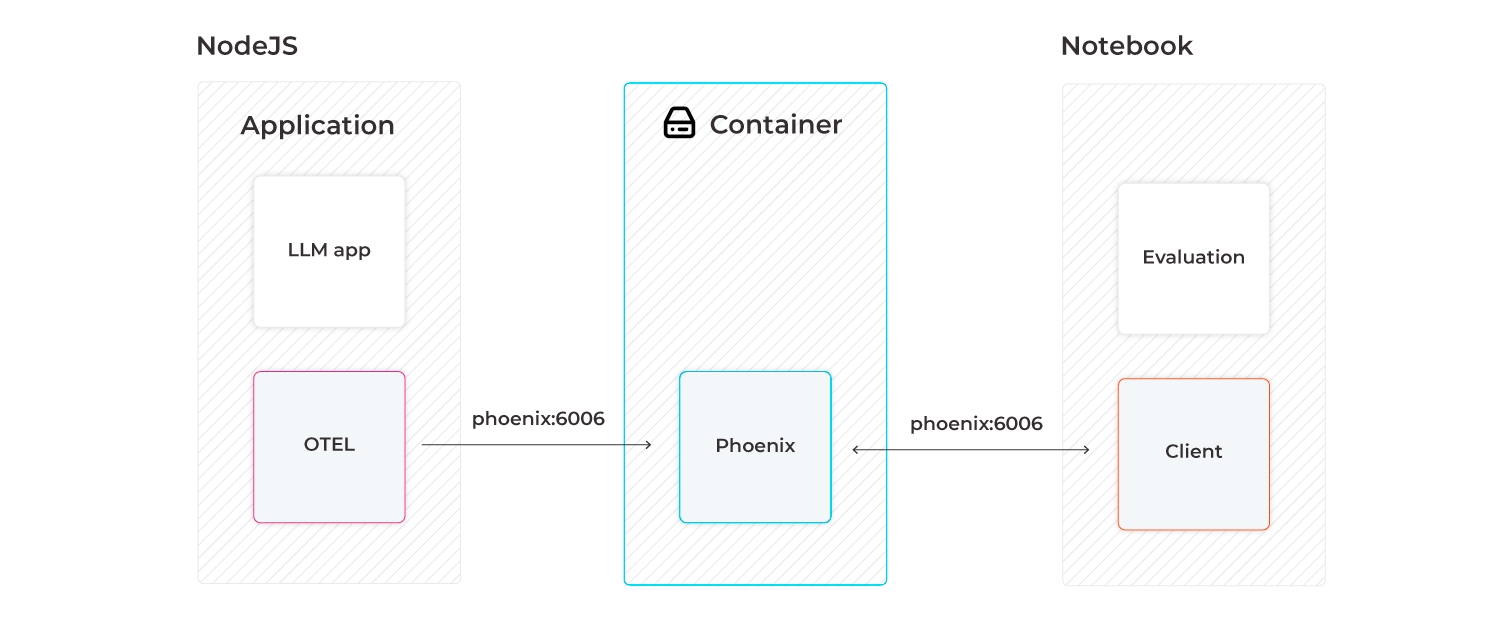
Phoenix is written and maintained in Python to make it natively runnable in Python notebooks. However, it can be stood up as a trace collector so that your LLM traces from your NodeJS application (e.g., LlamaIndex.TS, Langchain.js) can be collected. The traces collected by Phoenix can then be downloaded to a Jupyter notebook and used to run evaluations (e.g., LLM Evals, Ragas).
Instrumentation is the act of adding observability code to an app yourself.
If you’re instrumenting an app, you need to use the OpenTelemetry SDK for your language. You’ll then use the SDK to initialize OpenTelemetry and the API to instrument your code. This will emit telemetry from your app, and any library you installed that also comes with instrumentation.
Phoenix natively supports automatic instrumentation provided by OpenInference. For more details on OpenInference, checkout the project on GitHub.
Now lets walk through instrumenting, and then tracing, a sample express application.
Install OpenTelemetry API packages:
# npm, pnpm, yarn, etc
npm install @opentelemetry/semantic-conventions @opentelemetry/api @opentelemetry/instrumentation @opentelemetry/resources @opentelemetry/sdk-trace-base @opentelemetry/sdk-trace-node @opentelemetry/exporter-trace-otlp-protoInstall OpenInference instrumentation packages. Below is an example of adding instrumentation for OpenAI as well as the semantic conventions for OpenInference.
# npm, pnpm, yarn, etc
npm install openai @arizeai/openinference-instrumentation-openai @arizeai/openinference-semantic-conventionsTo enable tracing in your app, you’ll need to have an initialized TracerProvider.
If a TracerProvider is not created, the OpenTelemetry APIs for tracing will use a no-op implementation and fail to generate data. As explained next, create an instrumentation.ts (or instrumentation.js) file to include all of the provider initialization code in Node.
Node.js
Create instrumentation.ts (or instrumentation.js) to contain all the provider initialization code:
// instrumentation.ts
import { registerInstrumentations } from "@opentelemetry/instrumentation";
import { OpenAIInstrumentation } from "@arizeai/openinference-instrumentation-openai";
import { diag, DiagConsoleLogger, DiagLogLevel } from "@opentelemetry/api";
import { OTLPTraceExporter } from "@opentelemetry/exporter-trace-otlp-proto";
import { resourceFromAttributes } from "@opentelemetry/resources";
import { BatchSpanProcessor } from "@opentelemetry/sdk-trace-base";
import { NodeTracerProvider } from "@opentelemetry/sdk-trace-node";
import { ATTR_SERVICE_NAME } from "@opentelemetry/semantic-conventions";
import { SEMRESATTRS_PROJECT_NAME } from "@arizeai/openinference-semantic-conventions";
import OpenAI from "openai";
// For troubleshooting, set the log level to DiagLogLevel.DEBUG
diag.setLogger(new DiagConsoleLogger(), DiagLogLevel.DEBUG);
const tracerProvider = new NodeTracerProvider({
resource: resourceFromAttributes({
[ATTR_SERVICE_NAME]: "openai-service",
// Project name in Phoenix, defaults to "default"
[SEMRESATTRS_PROJECT_NAME]: "openai-service",
}),
spanProcessors: [
// BatchSpanProcessor will flush spans in batches after some time,
// this is recommended in production. For development or testing purposes
// you may try SimpleSpanProcessor for instant span flushing to the Phoenix UI.
new BatchSpanProcessor(
new OTLPTraceExporter({
url: `http://localhost:6006/v1/traces`,
// (optional) if connecting to Phoenix Cloud
// headers: { "api_key": process.env.PHOENIX_API_KEY },
// (optional) if connecting to self-hosted Phoenix with Authentication enabled
// headers: { "Authorization": `Bearer ${process.env.PHOENIX_API_KEY}` }
})
),
],
});
tracerProvider.register();
const instrumentation = new OpenAIInstrumentation();
instrumentation.manuallyInstrument(OpenAI);
registerInstrumentations({
instrumentations: [instrumentation],
});
console.log("👀 OpenInference initialized");This basic setup has will instrument chat completions via native calls to the OpenAI client.
As shown above with OpenAI, you can register additional instrumentation libraries with the OpenTelemetry provider in order to generate telemetry data for your dependencies. For more information, see Integrations.
Picking the right span processor
In our instrumentation.ts file above, we use the BatchSpanProcessor. The BatchSpanProcessor processes spans in batches before they are exported. This is usually the right processor to use for an application.
In contrast, the SimpleSpanProcessor processes spans as they are created. This means that if you create 5 spans, each will be processed and exported before the next span is created in code. This can be helpful in scenarios where you do not want to risk losing a batch, or if you’re experimenting with OpenTelemetry in development. However, it also comes with potentially significant overhead, especially if spans are being exported over a network - each time a call to create a span is made, it would be processed and sent over a network before your app’s execution could continue.
In most cases, stick with BatchSpanProcessor over SimpleSpanProcessor.
Tracing instrumented libraries
Now that you have configured a tracer provider, and instrumented the openai package, lets see how we can generate traces for a sample application.
First, install the dependencies required for our sample app.
# npm, pnpm, yarn, etc
npm install expressNext, create an app.ts (or app.js ) file, that hosts a simple express server for executing OpenAI chat completions.
// app.ts
import express from "express";
import OpenAI from "openai";
const PORT: number = parseInt(process.env.PORT || "8080");
const app = express();
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
app.get("/chat", async (req, res) => {
const message = req.query.message;
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: "user", content: message }],
model: "gpt-4o",
});
res.send(chatCompletion.choices[0].message.content);
});
app.listen(PORT, () => {
console.log(`Listening for requests on http://localhost:${PORT}`);
});Then, we will start our application, loading the instrumentation.ts file before app.ts so that our instrumentation code can instrument openai .
# node v23
node --require ./instrumentation.ts app.tsFinally, we can execute a request against our server
curl "http://localhost:8080/chat?message=write%20me%20a%20haiku"After a few moments, a new project openai-service will appear in the Phoenix UI, along with the trace generated by our OpenAI chat completion!
Anywhere in your application where you write manual tracing code should call getTracer to acquire a tracer. For example:
import opentelemetry from '@opentelemetry/api';
//...
const tracer = opentelemetry.trace.getTracer(
'instrumentation-scope-name',
'instrumentation-scope-version',
);
// You can now use a 'tracer' to do tracing!The values of instrumentation-scope-name and instrumentation-scope-version should uniquely identify the Instrumentation Scope, such as the package, module or class name. While the name is required, the version is still recommended despite being optional.
It’s generally recommended to call getTracer in your app when you need it rather than exporting the tracer instance to the rest of your app. This helps avoid trickier application load issues when other required dependencies are involved.
Below is an example of acquiring a tracer within application scope.
// app.ts
import { trace } from '@opentelemetry/api';
import express from 'express';
import OpenAI from "openai";
const tracer = trace.getTracer('llm-server', '0.1.0');
const PORT: number = parseInt(process.env.PORT || "8080");
const app = express();
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
app.get("/chat", async (req, res) => {
const message = req.query.message;
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: "user", content: message }],
model: "gpt-4o",
});
res.send(chatCompletion.choices[0].message.content);
});
app.listen(PORT, () => {
console.log(`Listening for requests on http://localhost:${PORT}`);
});Now that you have tracers initialized, you can create spans.
The API of OpenTelemetry JavaScript exposes two methods that allow you to create spans:
tracer.startSpan: Starts a new span without setting it on context.
tracer.startActiveSpan: Starts a new span and calls the given callback function passing it the created span as first argument. The new span gets set in context and this context is activated for the duration of the function call.
In most cases you want to use the latter (tracer.startActiveSpan), as it takes care of setting the span and its context active.
The code below illustrates how to create an active span.
import { trace, Span } from "@opentelemetry/api";
import { SpanKind } from "@opentelemetry/api";
import {
SemanticConventions,
OpenInferenceSpanKind,
} from "@arizeai/openinference-semantic-conventions";
export function chat(message: string) {
// Create a span. A span must be closed.
return tracer.startActiveSpan(
"chat",
(span: Span) => {
span.setAttributes({
[SemanticConventions.OPENINFERENCE_SPAN_KIND]: OpenInferenceSpanKind.chain,
[SemanticConventions.INPUT_VALUE]: message,
});
let chatCompletion = await openai.chat.completions.create({
messages: [{ role: "user", content: message }],
model: "gpt-3.5-turbo",
});
span.setAttributes({
attributes: {
[SemanticConventions.OUTPUT_VALUE]: chatCompletion.choices[0].message,
},
});
// Be sure to end the span!
span.end();
return result;
}
);
}The above instrumented code can now be pasted in the /chat handler. You should now be able to see spans emitted from your app.
Start your app as follows, and then send it requests by visiting http://localhost:8080/chat?message="how long is a pencil" with your browser or curl.
ts-node --require ./instrumentation.ts app.tsAfter a while, you should see the spans printed in the console by the ConsoleSpanExporter, something like this:
{
"traceId": "6cc927a05e7f573e63f806a2e9bb7da8",
"parentId": undefined,
"name": "chat",
"id": "117d98e8add5dc80",
"kind": 0,
"timestamp": 1688386291908349,
"duration": 501,
"attributes": {
"openinference.span.kind": "chain"
"input.value": "how long is a pencil"
},
"status": { "code": 0 },
"events": [],
"links": []
}Sometimes it’s helpful to do something with the current/active span at a particular point in program execution.
const activeSpan = opentelemetry.trace.getActiveSpan();
// do something with the active span, optionally ending it if that is appropriate for your use case.It can also be helpful to get the span from a given context that isn’t necessarily the active span.
const ctx = getContextFromSomewhere();
const span = opentelemetry.trace.getSpan(ctx);
// do something with the acquired span, optionally ending it if that is appropriate for your use case.Attributes let you attach key/value pairs to a Span so it carries more information about the current operation that it’s tracking. For OpenInference related attributes, use the @arizeai/openinference-semantic-conventions keys. However you are free to add any attributes you'd like!
function chat(message: string, user: User) {
return tracer.startActiveSpan(`chat:${i}`, (span: Span) => {
const result = Math.floor(Math.random() * (max - min) + min);
// Add an attribute to the span
span.setAttribute('mycompany.userid', user.id);
span.end();
return result;
});
}You can also add attributes to a span as it’s created:
tracer.startActiveSpan(
'app.new-span',
{ attributes: { attribute1: 'value1' } },
(span) => {
// do some work...
span.end();
},
);function chat(session: Session) {
return tracer.startActiveSpan(
'chat',
{ attributes: { 'mycompany.sessionid': session.id } },
(span: Span) => {
/* ... */
},
);
}Semantic Attributes
There are semantic conventions for spans representing operations in well-known protocols like HTTP or database calls. OpenInference also publishes it's own set of semantic conventions related to LLM applications. Semantic conventions for these spans are defined in the specification under OpenInference. In the simple example of this guide the source code attributes can be used.
First add both semantic conventions as a dependency to your application:
npm install --save @opentelemetry/semantic-conventions @arizeai/openinfernece-semantic-conventionsAdd the following to the top of your application file:
import { SemanticAttributes } from 'arizeai/openinfernece-semantic-conventions';Finally, you can update your file to include semantic attributes:
const doWork = () => {
tracer.startActiveSpan('app.doWork', (span) => {
span.setAttribute(SemanticAttributes.INPUT_VALUE, 'work input');
// Do some work...
span.end();
});
};A Span Event is a human-readable message on an Span that represents a discrete event with no duration that can be tracked by a single timestamp. You can think of it like a primitive log.
span.addEvent('Doing something');
const result = doWork();You can also create Span Events with additional Attributes
While Phoenix captures these, they are currently not displayed in the UI. Contact us if you would like to support!
span.addEvent('some log', {
'log.severity': 'error',
'log.message': 'Data not found',
'request.id': requestId,
});A Status can be set on a Span, typically used to specify that a Span has not completed successfully - Error. By default, all spans are Unset, which means a span completed without error. The Ok status is reserved for when you need to explicitly mark a span as successful rather than stick with the default of Unset (i.e., “without error”).
The status can be set at any time before the span is finished.
import opentelemetry, { SpanStatusCode } from '@opentelemetry/api';
// ...
tracer.startActiveSpan('app.doWork', (span) => {
for (let i = 0; i <= Math.floor(Math.random() * 40000000); i += 1) {
if (i > 10000) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: 'Error',
});
}
}
span.end();
});It can be a good idea to record exceptions when they happen. It’s recommended to do this in conjunction with setting span status.
import opentelemetry, { SpanStatusCode } from '@opentelemetry/api';
// ...
try {
doWork();
} catch (ex) {
span.recordException(ex);
span.setStatus({ code: SpanStatusCode.ERROR });
}sdk-trace-base and manually propagating span contextIn some cases, you may not be able to use either the Node.js SDK nor the Web SDK. The biggest difference, aside from initialization code, is that you’ll have to manually set spans as active in the current context to be able to create nested spans.
Initializing tracing with sdk-trace-base
Initializing tracing is similar to how you’d do it with Node.js or the Web SDK.
import opentelemetry from '@opentelemetry/api';
import {
BasicTracerProvider,
BatchSpanProcessor,
ConsoleSpanExporter,
} from '@opentelemetry/sdk-trace-base';
const provider = new BasicTracerProvider();
// Configure span processor to send spans to the exporter
provider.addSpanProcessor(new BatchSpanProcessor(new ConsoleSpanExporter()));
provider.register();
// This is what we'll access in all instrumentation code
const tracer = opentelemetry.trace.getTracer('example-basic-tracer-node');Like the other examples in this document, this exports a tracer you can use throughout the app.
Creating nested spans with sdk-trace-base
To create nested spans, you need to set whatever the currently-created span is as the active span in the current context. Don’t bother using startActiveSpan because it won’t do this for you.
const mainWork = () => {
const parentSpan = tracer.startSpan('main');
for (let i = 0; i < 3; i += 1) {
doWork(parentSpan, i);
}
// Be sure to end the parent span!
parentSpan.end();
};
const doWork = (parent, i) => {
// To create a child span, we need to mark the current (parent) span as the active span
// in the context, then use the resulting context to create a child span.
const ctx = opentelemetry.trace.setSpan(
opentelemetry.context.active(),
parent,
);
const span = tracer.startSpan(`doWork:${i}`, undefined, ctx);
// simulate some random work.
for (let i = 0; i <= Math.floor(Math.random() * 40000000); i += 1) {
// empty
}
// Make sure to end this child span! If you don't,
// it will continue to track work beyond 'doWork'!
span.end();
};All other APIs behave the same when you use sdk-trace-base compared with the Node.js SDKs.
OpenInference JavaScript instrumentations support specifying a custom tracer provider in multiple ways. This is useful when you need to use a different tracer provider than the default global one, or when you want to have more control over the tracing configuration.
You can pass a custom tracer provider directly to the instrumentation when creating it:
// Create a custom tracer provider
const customTracerProvider = new NodeTracerProvider({
resource: resourceFromAttributes({
[ATTR_SERVICE_NAME]: "custom-service",
[SEMRESATTRS_PROJECT_NAME]: "custom-project",
}),
spanProcessors: [
new BatchSpanProcessor(
new OTLPTraceExporter({
url: `http://localhost:6006/v1/traces`,
})
),
],
});
// Pass the custom tracer provider to the instrumentation
const instrumentation = new OpenAIInstrumentation({
tracerProvider: customTracerProvider,
});
instrumentation.manuallyInstrument(OpenAI);You can set a tracer provider after creating the instrumentation:
const instrumentation = new OpenAIInstrumentation();
instrumentation.setTracerProvider(customTracerProvider);
instrumentation.manuallyInstrument(OpenAI);You can also specify the tracer provider when registering instrumentations:
const instrumentation = new OpenAIInstrumentation();
instrumentation.manuallyInstrument(OpenAI);
registerInstrumentations({
instrumentations: [instrumentation],
tracerProvider: customTracerProvider,
});This functionality is supported across all OpenInference JavaScript instrumentations:
LangChain JS: @arizeai/openinference-instrumentation-langchain
BeeAI: @arizeai/openinference-instrumentation-beeai
OpenAI JS: @arizeai/openinference-instrumentation-openai
For specific examples with each instrumentation, see their respective documentation pages in the Integrations section.
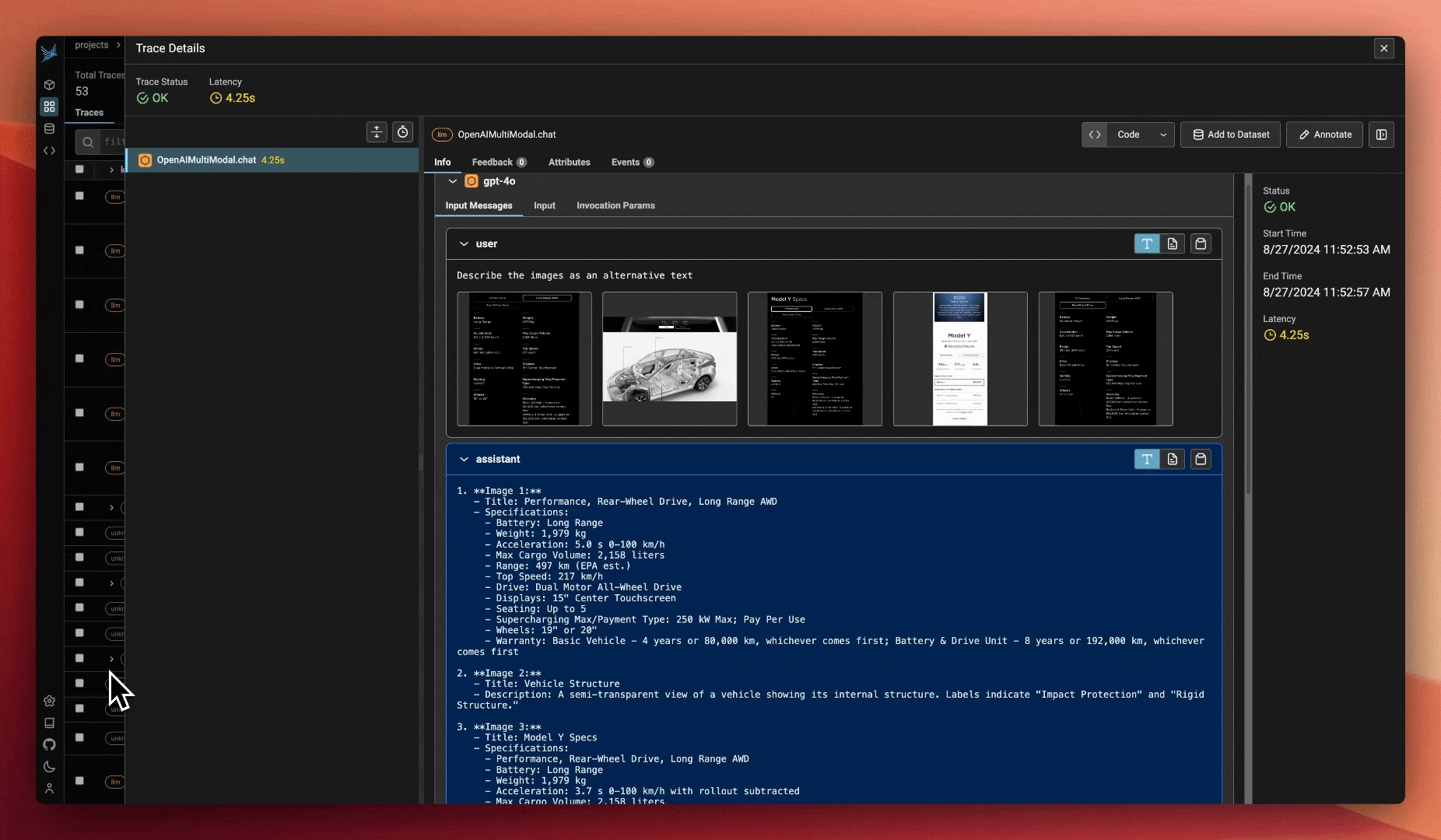
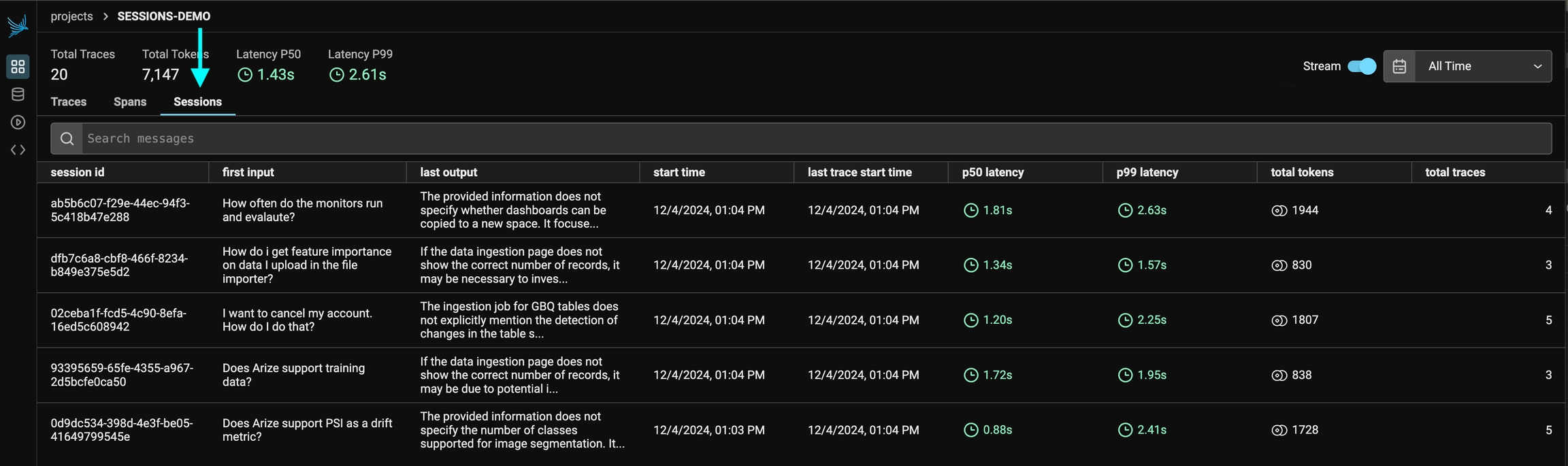
Various options for to help you get data out of Phoenix
Exports all spans in a project as a dataframe
Evaluation - Filtering your spans locally using pandas instead of Phoenix DSL.
Exports specific spans or traces based on filters
Evaluation - Querying spans from Phoenix
Exports specific groups of spans
Agent Evaluation - Easily export tool calls.
RAG Evaluation - Easily exporting retrieved documents or Q&A data from a RAG system.
Saves all traces as a local file
Storing Data - Backing up an entire Phoenix instance.
Before using any of the methods above, make sure you've connected to px.Client() . You'll need to set the following environment variables:
import os
os.environ["PHOENIX_CLIENT_HEADERS"] = f"api_key=..."
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "https://app.phoenix.arize.com"If you're self-hosting Phoenix, ignore the client headers and change the collector endpoint to your endpoint.
If you prefer to handle your filtering locally, you can also download all spans as a dataframe using the get_spans_dataframe() function:
import phoenix as px
# Download all spans from your default project
px.Client().get_spans_dataframe()
# Download all spans from a specific project
px.Client().get_spans_dataframe(project_name='your project name')
# You can query for spans with the same filter conditions as in the UI
px.Client().get_spans_dataframe("span_kind == 'CHAIN'")You can query for data using our query DSL (domain specific language).
This Query DSL is the same as what is used by the filter bar in the dashboard. It can be helpful to form your query string in the Phoenix dashboard for more immediate feedback, before moving it to code.
Below is an example of how to pull all retriever spans and select the input value. The output of this query is a DataFrame that contains the input values for all retriever spans.
import phoenix as px
from phoenix.trace.dsl import SpanQuery
query = SpanQuery().where(
# Filter for the `RETRIEVER` span kind.
# The filter condition is a string of valid Python boolean expression.
"span_kind == 'RETRIEVER'",
).select(
# Extract the span attribute `input.value` which contains the query for the
# retriever. Rename it as the `input` column in the output dataframe.
input="input.value",
)
# The Phoenix Client can take this query and return the dataframe.
px.Client().query_spans(query)By default, all queries will collect all spans that are in your Phoenix instance. If you'd like to focus on most recent spans, you can pull spans based on time frames using start_time and end_time.
import phoenix as px
from phoenix.trace.dsl import SpanQuery
from datetime import datetime, timedelta
# Initiate Phoenix client
px_client = px.Client()
# Get spans from the last 7 days only
start = datetime.now() - timedelta(days=7)
# Get spans to exclude the last 24 hours
end = datetime.now() - timedelta(days=1)
phoenix_df = px_client.query_spans(start_time=start, end_time=end)By default all queries are executed against the default project or the project set via the PHOENIX_PROJECT_NAME environment variable. If you choose to pull from a different project, all methods on the Client have an optional parameter named project_name
import phoenix as px
from phoenix.trace.dsl import SpanQuery
# Get spans from a project
px.Client().get_spans_dataframe(project_name="<my-project>")
# Using the query DSL
query = SpanQuery().where("span_kind == 'CHAIN'").select(input="input.value")
px.Client().query_spans(query, project_name="<my-project>")Let's say we want to extract the retrieved documents into a DataFrame that looks something like the table below, where input denotes the query for the retriever, reference denotes the content of each document, and document_position denotes the (zero-based) index in each span's list of retrieved documents.
Note that this DataFrame can be used directly as input for the Retrieval (RAG) Relevance evaluations.
5B8EF798A381
0
What was the author's motivation for writing ...
In fact, I decided to write a book about ...
5B8EF798A381
1
What was the author's motivation for writing ...
I started writing essays again, and wrote a bunch of ...
...
...
...
...
E19B7EC3GG02
0
What did the author learn about ...
The good part was that I got paid huge amounts of ...
We can accomplish this with a simple query as follows. Also see Predefined Queries for a helper function executing this query.
from phoenix.trace.dsl import SpanQuery
query = SpanQuery().where(
# Filter for the `RETRIEVER` span kind.
# The filter condition is a string of valid Python boolean expression.
"span_kind == 'RETRIEVER'",
).select(
# Extract the span attribute `input.value` which contains the query for the
# retriever. Rename it as the `input` column in the output dataframe.
input="input.value",
).explode(
# Specify the span attribute `retrieval.documents` which contains a list of
# objects and explode the list. Extract the `document.content` attribute from
# each object and rename it as the `reference` column in the output dataframe.
"retrieval.documents",
reference="document.content",
)
# The Phoenix Client can take this query and return the dataframe.
px.Client().query_spans(query)In addition to the document content, if we also want to explode the document score, we can simply add the document.score attribute to the .explode() method alongside document.content as follows. Keyword arguments are necessary to name the output columns, and in this example we name the output columns as reference and score. (Python's double-asterisk unpacking idiom can be used to specify arbitrary output names containing spaces or symbols. See here for an example.)
query = SpanQuery().explode(
"retrieval.documents",
reference="document.content",
score="document.score",
)The .where() method accepts a string of valid Python boolean expression. The expression can be arbitrarily complex, but restrictions apply, e.g. making function calls are generally disallowed. Below is a conjunction filtering also on whether the input value contains the string 'programming'.
query = SpanQuery().where(
"span_kind == 'RETRIEVER' and 'programming' in input.value"
)Filtering spans by evaluation results, e.g. score or label, can be done via a special syntax. The name of the evaluation is specified as an indexer on the special keyword evals. The example below filters for spans with the incorrect label on their correctness evaluations. (See here for how to compute evaluations for traces, and here for how to ingest those results back to Phoenix.)
query = SpanQuery().where(
"evals['correctness'].label == 'incorrect'"
)metadata is an attribute that is a dictionary and it can be filtered like a dictionary.
query = SpanQuery().where(
"metadata["topic"] == 'programming'"
)Note that Python strings do not have a contain method, and substring search is done with the in operator.
query = SpanQuery().where(
"'programming' in metadata["topic"]"
)Get spans that do not have an evaluation attached yet
query = SpanQuery().where(
"evals['correctness'].label is None"
)
# correctness is whatever you named your evaluation metricYou can also use Python boolean expressions to filter spans in the Phoenix UI. These expressions can be entered directly into the search bar above your experiment runs, allowing you to apply complex conditions involving span attributes. Any expressions that work with the .where() method above can also be used in the UI.
Span attributes can be selected by simply listing them inside .select() method.
query = SpanQuery().select(
"input.value",
"output.value",
)Keyword-argument style can be used to rename the columns in the dataframe. The example below returns two columns named input and output instead of the original names of the attributes.
query = SpanQuery().select(
input="input.value",
output="output.value",
)If arbitrary output names are desired, e.g. names with spaces and symbols, we can leverage Python's double-asterisk idiom for unpacking a dictionary, as shown below.
query = SpanQuery().select(**{
"Value (Input)": "input.value",
"Value (Output)": "output.value",
})The document contents can also be concatenated together. The query below concatenates the list of document.content with (double newlines), which is the default separator. Keyword arguments are necessary to name the output columns, and in this example we name the output column as reference. (Python's double-asterisk unpacking idiom can be used to specify arbitrary output names containing spaces or symbols. See here for an example.)
query = SpanQuery().concat(
"retrieval.documents",
reference="document.content",
)If a different separator is desired, say \n************, it can be specified as follows.
query = SpanQuery().concat(
"retrieval.documents",
reference="document.content",
).with_concat_separator(
separator="\n************\n",
)This is useful for joining a span to its parent span. To do that we would first index the child span by selecting its parent ID and renaming it as span_id. This works because span_id is a special column name: whichever column having that name will become the index of the output DataFrame.
query = SpanQuery().select(
span_id="parent_id",
output="output.value",
)To do this, we would provide two queries to Phoenix which will return two simultaneous dataframes that can be joined together by pandas. The query_for_child_spans uses parent_id as index as shown in Using Parent ID as Index, and px.Client().query_spans() returns a list of dataframes when multiple queries are given.
import pandas as pd
pd.concatenate(
px.Client().query_spans(
query_for_parent_spans,
query_for_child_spans,
),
axis=1, # joining on the row indices
join="inner", # inner-join by the indices of the dataframes
)To learn more about extracting span attributes, see Extracting Span Attributes.
from phoenix.trace.dsl import SpanQuery
query = SpanQuery().where(
"span_kind == 'LLM'",
).select(
input="input.value",
output="output.value,
)
# The Phoenix Client can take this query and return a dataframe.
px.Client().query_spans(query)To extract the dataframe input for Retrieval (RAG) Relevance evaluations, we can apply the query described in the Example, or leverage the helper function implementing the same query.
To extract the dataframe input to the Q&A on Retrieved Data evaluations, we can use a helper function or use the following query (which is what's inside the helper function). This query applies techniques described in the Advanced Usage section.
import pandas as pd
from phoenix.trace.dsl import SpanQuery
query_for_root_span = SpanQuery().where(
"parent_id is None", # Filter for root spans
).select(
input="input.value", # Input contains the user's question
output="output.value", # Output contains the LLM's answer
)
query_for_retrieved_documents = SpanQuery().where(
"span_kind == 'RETRIEVER'", # Filter for RETRIEVER span
).select(
# Rename parent_id as span_id. This turns the parent_id
# values into the index of the output dataframe.
span_id="parent_id",
).concat(
"retrieval.documents",
reference="document.content",
)
# Perform an inner join on the two sets of spans.
pd.concat(
px.Client().query_spans(
query_for_root_span,
query_for_retrieved_documents,
),
axis=1,
join="inner",
)Phoenix also provides helper functions that executes predefined queries for the following use cases.
The query below will automatically export any tool calls selected by LLM calls. The output DataFrame can be easily combined with Agent Function Calling Eval.
from phoenix.trace.dsl.helpers import get_called_tools
tools_df = get_called_tools(client)
tools_dfThe query shown in the example can be done more simply with a helper function as follows. The output DataFrame can be used directly as input for the Retrieval (RAG) Relevance evaluations.
from phoenix.session.evaluation import get_retrieved_documents
retrieved_documents = get_retrieved_documents(px.Client())
retrieved_documentsTo extract the dataframe input to the Q&A on Retrieved Data evaluations, we can use the following helper function.
from phoenix.session.evaluation import get_qa_with_reference
qa_with_reference = get_qa_with_reference(px.Client())
qa_with_referenceThe output DataFrame would look something like the one below. The input contains contains the question, the output column contains the answer, and the reference column contains a concatenation of all the retrieved documents. This helper function assumes that the questions and answers are the input.value and output.value attributes of the root spans, and the list of retrieved documents are contained in a direct child span of the root span. (The helper function applies the techniques described in the Advanced Usage section.)
CDBC4CE34
What was the author's trick for ...
The author's trick for ...
Even then it took me several years to understand ...
...
...
...
...
Sometimes you may want to back up your Phoenix traces to a single file, rather than exporting specific spans to run evaluation.
Use the following command to save all traces from a Phoenix instance to a designated location.
my_traces = px.Client().get_trace_dataset().save()You can specify the directory to save your traces by passing adirectory argument to the save method.
import os
# Specify and Create the Directory for Trace Dataset
directory = '/my_saved_traces'
os.makedirs(directory, exist_ok=True)
# Save the Trace Dataset
trace_id = px.Client().get_trace_dataset().save(directory=directory)This output the trace ID and prints the path of the saved file:
💾 Trace dataset saved to under ID: f7733fda-6ad6-4427-a803-55ad2182b662
📂 Trace dataset path: /my_saved_traces/trace_dataset-f7733fda-6ad6-4427-a803-55ad2182b662.parquet
As part of the OpenInference library, Phoenix provides helpful abstractions to make manual instrumentation easier.
This documentation provides a guide on using OpenInference OTEL tracing decorators and methods for instrumenting functions, chains, agents, and tools using OpenTelemetry.
These tools can be combined with, or used in place of, OpenTelemetry instrumentation code. They are designed to simplify the instrumentation process.
If you'd prefer to use pure OTEL instead, see
Ensure you have OpenInference and OpenTelemetry installed:
You can configure the tracer using either TracerProvider from openinference.instrumentation or using phoenix.otel.register.
Your tracer object can now be used in two primary ways:
This entire function will appear as a Span in Phoenix. Input and output attributes in Phoenix will be set automatically based on my_func's parameters and return. The status attribute will also be set automatically.
The code within this clause will be captured as a Span in Phoenix. Here the input, output, and status must be set manually.
This approach is useful when you need only a portion of a method to be captured as a Span.
OpenInference Span Kinds denote the possible types of spans you might capture, and will be rendered different in the Phoenix UI.
The possible values are:\
Like other span kinds, LLM spans can be instrumented either via a context manager or via a decorator pattern. It's also possible to directly patch client methods.
While this guide uses the OpenAI Python client for illustration, in practice, you should use the OpenInference auto-instrumentors for OpenAI whenever possible and resort to manual instrumentation for LLM spans only as a last resort.
To run the snippets in this section, set your OPENAI_API_KEY environment variable.
This decorator pattern above works for sync functions, async coroutine functions, sync generator functions, and async generator functions. Here's an example with an async generator.
It's also possible to directly patch methods on a client. This is useful if you want to transparently use the client in your application with instrumentation logic localized in one place.
The snippets above produce LLM spans with input and output values, but don't offer rich UI for messages, tools, invocation parameters, etc. In order to manually instrument LLM spans with these features, users can define their own functions to wrangle the input and output of their LLM calls into OpenInference format. The openinference-instrumentation library contains helper functions that produce valid OpenInference attributes for LLM spans:
get_llm_attributes
get_input_attributes
get_output_attributes
For OpenAI, these functions might look like this:
When using a context manager to create LLM spans, these functions can be used to wrangle inputs and outputs.
When using the tracer.llm decorator, these functions are passed via the process_input and process_output parameters and should satisfy the following:
The input signature of process_input should exactly match the input signature of the decorated function.
The input signature of process_output has a single argument, the output of the decorated function. This argument accepts the returned value when the decorated function is a sync or async function, or a list of yielded values when the decorated function is a sync or async generator function.
Both process_input and process_output should output a dictionary mapping attribute names to values.
When decorating a generator function, process_output should accept a single argument, a list of the values yielded by the decorated function.
Then the decoration is the same as before.
As before, it's possible to directly patch the method on the client. Just ensure that the input signatures of process_input and the patched method match.
The OpenInference Tracer shown above respects context Managers for &
OpenInference includes message types that can be useful in composing text and image or other file inputs and outputs:
pip install openinference-semantic-conventions opentelemetry-api opentelemetry-sdk@tracer.chain
def my_func(input: str) -> str:
return "output"with tracer.start_as_current_span(
"my-span-name",
openinference_span_kind="chain",
) as span:
span.set_input("input")
span.set_output("output")
span.set_status(Status(StatusCode.OK))CHAIN
General logic operations, functions, or code blocks
LLM
Making LLM calls
TOOL
Completing tool calls
RETRIEVER
Retrieving documents
EMBEDDING
Generating embeddings
AGENT
Agent invokations - typically a top level or near top level span
RERANKER
Reranking retrieved context
UNKNOWN
Unknown
GUARDRAIL
Guardrail checks
EVALUATOR
Evaluators - typically only use by Phoenix when automatically tracing evaluation and experiment calls
with tracer.start_as_current_span(
"chain-span-with-plain-text-io",
openinference_span_kind="chain",
) as span:
span.set_input("input")
span.set_output("output")
span.set_status(Status(StatusCode.OK))@tracer.chain
def decorated_chain_with_plain_text_output(input: str) -> str:
return "output"
decorated_chain_with_plain_text_output("input")@tracer.chain
def decorated_chain_with_json_output(input: str) -> Dict[str, Any]:
return {"output": "output"}
decorated_chain_with_json_output("input")@tracer.chain(name="decorated-chain-with-overriden-name")
def this_name_should_be_overriden(input: str) -> Dict[str, Any]:
return {"output": "output"}
this_name_should_be_overriden("input")with tracer.start_as_current_span(
"agent-span-with-plain-text-io",
openinference_span_kind="agent",
) as span:
span.set_input("input")
span.set_output("output")
span.set_status(Status(StatusCode.OK))@tracer.agent
def decorated_agent(input: str) -> str:
return "output"
decorated_agent("input")with tracer.start_as_current_span(
"tool-span",
openinference_span_kind="tool",
) as span:
span.set_input("input")
span.set_output("output")
span.set_tool(
name="tool-name",
description="tool-description",
parameters={"input": "input"},
)
span.set_status(Status(StatusCode.OK))@tracer.tool
def decorated_tool(input1: str, input2: int) -> None:
"""
tool-description
"""
decorated_tool("input1", 1)@tracer.tool(
name="decorated-tool-with-overriden-name",
description="overriden-tool-description",
)
def this_tool_name_should_be_overriden(input1: str, input2: int) -> None:
"""
this tool description should be overriden
"""
this_tool_name_should_be_overriden("input1", 1)from openai import OpenAI
from opentelemetry.trace import Status, StatusCode
openai_client = OpenAI()
messages = [{"role": "user", "content": "Hello, world!"}]
with tracer.start_as_current_span("llm_span", openinference_span_kind="llm") as span:
span.set_input(messages)
try:
response = openai_client.chat.completions.create(
model="gpt-4",
messages=messages,
)
except Exception as error:
span.record_exception(error)
span.set_status(Status(StatusCode.ERROR))
else:
span.set_output(response)
span.set_status(Status(StatusCode.OK))from typing import List
from openai import OpenAI
from openai.types.chat import ChatCompletionMessageParam
openai_client = OpenAI()
@tracer.llm
def invoke_llm(
messages: List[ChatCompletionMessageParam],
) -> str:
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=messages,
)
message = response.choices[0].message
return message.content or ""
invoke_llm([{"role": "user", "content": "Hello, world!"}])from typing import AsyncGenerator, List
from openai import AsyncOpenAI
from openai.types.chat import ChatCompletionMessageParam
openai_async_client = AsyncOpenAI()
@tracer.llm
async def stream_llm_responses(
messages: List[ChatCompletionMessageParam],
) -> AsyncGenerator[str, None]:
stream = await openai_async_client.chat.completions.create(
model="gpt-4o",
messages=messages,
stream=True,
)
async for chunk in stream:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
# invoke inside of an async context
async for token in stream_llm_responses([{"role": "user", "content": "Hello, world!"}]):
print(token, end="")
from openai import OpenAI
openai_client = OpenAI()
# patch the create method
wrapper = tracer.llm
openai_client.chat.completions.create = wrapper(openai_client.chat.completions.create)
# invoke the patched method normally
openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hello, world!"}],
)from typing import Any, Dict, List, Optional, Union
from openai.types.chat import (
ChatCompletion,
ChatCompletionMessage,
ChatCompletionMessageParam,
ChatCompletionToolParam,
)
from opentelemetry.util.types import AttributeValue
import openinference.instrumentation as oi
from openinference.instrumentation import (
get_input_attributes,
get_llm_attributes,
get_output_attributes,
)
def process_input(
messages: List[ChatCompletionMessageParam],
model: str,
temperature: Optional[float] = None,
tools: Optional[List[ChatCompletionToolParam]] = None,
**kwargs: Any,
) -> Dict[str, AttributeValue]:
oi_messages = [convert_openai_message_to_oi_message(message) for message in messages]
oi_tools = [convert_openai_tool_param_to_oi_tool(tool) for tool in tools or []]
return {
**get_input_attributes(
{
"messages": messages,
"model": model,
"temperature": temperature,
"tools": tools,
**kwargs,
}
),
**get_llm_attributes(
provider="openai",
system="openai",
model_name=model,
input_messages=oi_messages,
invocation_parameters={"temperature": temperature},
tools=oi_tools,
),
}
def convert_openai_message_to_oi_message(
message_param: Union[ChatCompletionMessageParam, ChatCompletionMessage],
) -> oi.Message:
if isinstance(message_param, ChatCompletionMessage):
role: str = message_param.role
oi_message = oi.Message(role=role)
if isinstance(content := message_param.content, str):
oi_message["content"] = content
if message_param.tool_calls is not None:
oi_tool_calls: List[oi.ToolCall] = []
for tool_call in message_param.tool_calls:
function = tool_call.function
oi_tool_calls.append(
oi.ToolCall(
id=tool_call.id,
function=oi.ToolCallFunction(
name=function.name,
arguments=function.arguments,
),
)
)
oi_message["tool_calls"] = oi_tool_calls
return oi_message
role = message_param["role"]
assert isinstance(message_param["content"], str)
content = message_param["content"]
return oi.Message(role=role, content=content)
def convert_openai_tool_param_to_oi_tool(tool_param: ChatCompletionToolParam) -> oi.Tool:
assert tool_param["type"] == "function"
return oi.Tool(json_schema=dict(tool_param))
def process_output(response: ChatCompletion) -> Dict[str, AttributeValue]:
message = response.choices[0].message
role = message.role
oi_message = oi.Message(role=role)
if isinstance(message.content, str):
oi_message["content"] = message.content
if isinstance(message.tool_calls, list):
oi_tool_calls: List[oi.ToolCall] = []
for tool_call in message.tool_calls:
tool_call_id = tool_call.id
function_name = tool_call.function.name
function_arguments = tool_call.function.arguments
oi_tool_calls.append(
oi.ToolCall(
id=tool_call_id,
function=oi.ToolCallFunction(
name=function_name,
arguments=function_arguments,
),
)
)
oi_message["tool_calls"] = oi_tool_calls
output_messages = [oi_message]
token_usage = response.usage
oi_token_count: Optional[oi.TokenCount] = None
if token_usage is not None:
prompt_tokens = token_usage.prompt_tokens
completion_tokens = token_usage.completion_tokens
oi_token_count = oi.TokenCount(
prompt=prompt_tokens,
completion=completion_tokens,
)
return {
**get_llm_attributes(
output_messages=output_messages,
token_count=oi_token_count,
),
**get_output_attributes(response),
}import json
from openai import OpenAI
from openai.types.chat import (
ChatCompletionMessage,
ChatCompletionMessageParam,
ChatCompletionToolMessageParam,
ChatCompletionToolParam,
ChatCompletionUserMessageParam,
)
from opentelemetry.trace import Status, StatusCode
openai_client = OpenAI()
@tracer.tool
def get_weather(city: str) -> str:
# make an call to a weather API here
return "sunny"
messages: List[Union[ChatCompletionMessage, ChatCompletionMessageParam]] = [
ChatCompletionUserMessageParam(
role="user",
content="What's the weather like in San Francisco?",
)
]
temperature = 0.5
invocation_parameters = {"temperature": temperature}
tools: List[ChatCompletionToolParam] = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "finds the weather for a given city",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city to find the weather for, e.g. 'London'",
}
},
"required": ["city"],
},
},
},
]
with tracer.start_as_current_span(
"llm_tool_call",
attributes=process_input(
messages=messages,
invocation_parameters={"temperature": temperature},
model="gpt-4",
),
openinference_span_kind="llm",
) as span:
try:
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=temperature,
tools=tools,
)
except Exception as error:
span.record_exception(error)
span.set_status(Status(StatusCode.ERROR))
else:
span.set_attributes(process_output(response))
span.set_status(Status(StatusCode.OK))
output_message = response.choices[0].message
tool_calls = output_message.tool_calls
assert tool_calls and len(tool_calls) == 1
tool_call = tool_calls[0]
city = json.loads(tool_call.function.arguments)["city"]
weather = get_weather(city)
messages.append(output_message)
messages.append(
ChatCompletionToolMessageParam(
content=weather,
role="tool",
tool_call_id=tool_call.id,
)
)
with tracer.start_as_current_span(
"tool_call_response",
attributes=process_input(
messages=messages,
invocation_parameters={"temperature": temperature},
model="gpt-4",
),
openinference_span_kind="llm",
) as span:
try:
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=temperature,
)
except Exception as error:
span.record_exception(error)
span.set_status(Status(StatusCode.ERROR))
else:
span.set_attributes(process_output(response))
span.set_status(Status(StatusCode.OK))
from openai import NOT_GIVEN, OpenAI
from openai.types.chat import ChatCompletion
openai_client = OpenAI()
@tracer.llm(
process_input=process_input,
process_output=process_output,
)
def invoke_llm(
messages: List[ChatCompletionMessageParam],
model: str,
temperature: Optional[float] = None,
tools: Optional[List[ChatCompletionToolParam]] = None,
) -> ChatCompletion:
response: ChatCompletion = openai_client.chat.completions.create(
messages=messages,
model=model,
tools=tools or NOT_GIVEN,
temperature=temperature,
)
return response
invoke_llm(
messages=[{"role": "user", "content": "Hello, world!"}],
temperature=0.5,
model="gpt-4",
)from typing import Dict, List, Optional
from openai.types.chat import ChatCompletionChunk
from opentelemetry.util.types import AttributeValue
import openinference.instrumentation as oi
from openinference.instrumentation import (
get_llm_attributes,
get_output_attributes,
)
def process_generator_output(
outputs: List[ChatCompletionChunk],
) -> Dict[str, AttributeValue]:
role: Optional[str] = None
content = ""
oi_token_count = oi.TokenCount()
for chunk in outputs:
if choices := chunk.choices:
assert len(choices) == 1
delta = choices[0].delta
if isinstance(delta.content, str):
content += delta.content
if isinstance(delta.role, str):
role = delta.role
if (usage := chunk.usage) is not None:
if (prompt_tokens := usage.prompt_tokens) is not None:
oi_token_count["prompt"] = prompt_tokens
if (completion_tokens := usage.completion_tokens) is not None:
oi_token_count["completion"] = completion_tokens
oi_messages = []
if role and content:
oi_messages.append(oi.Message(role=role, content=content))
return {
**get_llm_attributes(
output_messages=oi_messages,
token_count=oi_token_count,
),
**get_output_attributes(content),
}
from typing import AsyncGenerator
from openai import AsyncOpenAI
from openai.types.chat import ChatCompletionChunk
openai_async_client = AsyncOpenAI()
@tracer.llm(
process_input=process_input, # same as before
process_output=process_generator_output,
)
async def stream_llm_response(
messages: List[ChatCompletionMessageParam],
model: str,
temperature: Optional[float] = None,
) -> AsyncGenerator[ChatCompletionChunk, None]:
async for chunk in await openai_async_client.chat.completions.create(
messages=messages,
model=model,
temperature=temperature,
stream=True,
):
yield chunk
async for chunk in stream_llm_response(
messages=[{"role": "user", "content": "Hello, world!"}],
temperature=0.5,
model="gpt-4",
):
print(chunk)from openai import OpenAI
from openai.types.chat import ChatCompletionMessageParam
openai_client = OpenAI()
# patch the create method
wrapper = tracer.llm(
process_input=process_input,
process_output=process_output,
)
openai_client.chat.completions.create = wrapper(openai_client.chat.completions.create)
# invoke the patched method normally
openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hello, world!"}],
)with suppress_tracing():
# this trace will not be recorded
with tracer.start_as_current_span(
"THIS-SPAN-SHOULD-NOT-BE-TRACED",
openinference_span_kind="chain",
) as span:
span.set_input("input")
span.set_output("output")
span.set_status(Status(StatusCode.OK))with using_attributes(session_id="123"):
# this trace has session id "123"
with tracer.start_as_current_span(
"chain-span-with-context-attributes",
openinference_span_kind="chain",
) as span:
span.set_input("input")
span.set_output("output")
span.set_status(Status(StatusCode.OK))import openinference.instrumentation as oi
image_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
text = "describe the weather in this image"
content = [
{"type": "text", "text": text},
{
"type": "image_url",
"image_url": {"url": image_url, "detail": "low"},
},
]
image = oi.Image(url=image_url)
contents = [
oi.TextMessageContent(
type="text",
text=text,
),
oi.ImageMessageContent(
type="image",
image=image,
),
]
messages = [
oi.Message(
role="user",
contents=contents,
)
]
with tracer.start_as_current_span(
"my-span-name",
openinference_span_kind="llm",
attributes=oi.get_llm_attributes(input_messages=messages)
) as span:
span.set_input(text)
# Call your LLM here
response = "This is a test response"
span.set_output(response)
print(response.content)from phoenix.otel import register
tracer_provider = register(protocol="http/protobuf", project_name="your project name")
tracer = tracer_provider.get_tracer(__name__)from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace.export import ConsoleSpanExporter, SimpleSpanProcessor
from openinference.instrumentation import TracerProvider
from openinference.semconv.resource import ResourceAttributes
endpoint = "http://127.0.0.1:6006/v1/traces"
resource = Resource(attributes={ResourceAttributes.PROJECT_NAME: "openinference-tracer"})
tracer_provider = TracerProvider(resource=resource)
tracer_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter(endpoint)))
tracer = tracer_provider.get_tracer(__name__)While the spans created via Phoenix and OpenInference create a solid foundation for tracing your application, sometimes you need to create and customize your LLM spans
Phoenix and OpenInference use the OpenTelemetry Trace API to create spans. Because Phoenix supports OpenTelemetry, this means that you can perform manual instrumentation, no LLM framework required! This guide will help you understand how to create and customize spans using the OpenTelemetry Trace API.
First, ensure you have the API and SDK packages:
pip install opentelemetry-api
pip install opentelemetry-sdk
pip install opentelemetry-exporter-otlpLet's next install the OpenInference Semantic Conventions package so that we can construct spans with LLM semantic conventions:
pip install openinference-semantic-conventionsFor full documentation on the OpenInference semantic conventions, please consult the specification
Configuring an OTel tracer involves some boilerplate code that the instrumentors in phoenix.trace take care of for you. If you're manually instrumenting your application, you'll need to implement this boilerplate yourself:
from openinference.semconv.resource import ResourceAttributes
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
from phoenix.config import get_env_host, get_env_port
resource = Resource(attributes={
ResourceAttributes.PROJECT_NAME: '<your-project-name>'
})
tracer_provider = TracerProvider(resource=resource)
trace.set_tracer_provider(tracer_provider)
tracer = trace.get_tracer(__name__)
collector_endpoint = f"http://{get_env_host()}:{get_env_port()}/v1/traces"
span_exporter = OTLPSpanExporter(endpoint=collector_endpoint)
simple_span_processor = SimpleSpanProcessor(span_exporter=span_exporter)
trace.get_tracer_provider().add_span_processor(simple_span_processor)This snippet contains a few OTel concepts:
A resource represents an origin (e.g., a particular service, or in this case, a project) from which your spans are emitted.
Span processors filter, batch, and perform operations on your spans prior to export.
Your tracer provides a handle for you to create spans and add attributes in your application code.
The collector (e.g., Phoenix) receives the spans exported by your application.
If you're using Phoenix Cloud or a local Phoenix with auth enabled:
Modify your span exporter to include your API key:
headers = {"Authorization": f"Bearer {os.environ['PHOENIX_API_KEY']}"}
exporter = OTLPSpanExporter(endpoint=collector_endpoint, headers=headers)To create a span, you'll typically want it to be started as the current span.
def do_work():
with tracer.start_as_current_span("span-name") as span:
# do some work that 'span' will track
print("doing some work...")
# When the 'with' block goes out of scope, 'span' is closed for youYou can also use start_span to create a span without making it the current span. This is usually done to track concurrent or asynchronous operations.
If you have a distinct sub-operation you'd like to track as a part of another one, you can create span to represent the relationship:
def do_work():
with tracer.start_as_current_span("parent") as parent:
# do some work that 'parent' tracks
print("doing some work...")
# Create a nested span to track nested work
with tracer.start_as_current_span("child") as child:
# do some work that 'child' tracks
print("doing some nested work...")
# the nested span is closed when it's out of scope
# This span is also closed when it goes out of scopeWhen you view spans in a trace visualization tool, child will be tracked as a nested span under parent.
It's common to have a single span track the execution of an entire function. In that scenario, there is a decorator you can use to reduce code:
@tracer.start_as_current_span("do_work")
def do_work():
print("doing some work...")Use of the decorator is equivalent to creating the span inside do_work() and ending it when do_work() is finished.
To use the decorator, you must have a tracer instance in scope for your function declaration.
If you need to add attributes or events then it's less convenient to use a decorator.
Sometimes it's helpful to access whatever the current span is at a point in time so that you can enrich it with more information.
from opentelemetry import trace
current_span = trace.get_current_span()
# enrich 'current_span' with some informationAttributes let you attach key/value pairs to a spans so it carries more information about the current operation that it's tracking.
from opentelemetry import trace
current_span = trace.get_current_span()
current_span.set_attribute("operation.value", 1)
current_span.set_attribute("operation.name", "Saying hello!")
current_span.set_attribute("operation.other-stuff", [1, 2, 3])Notice above that the attributes have a specific prefix operation. When adding custom attributes, it's best practice to vendor your attributes (e.x. mycompany.) so that your attributes do not clash with semantic conventions.
Semantic attributes are pre-defined attributes that are well-known naming conventions for common kinds of data. Using semantic attributes lets you normalize this kind of information across your systems. In the case of Phoenix, the OpenInference Semantic Conventions package provides a set of well-known attributes that are used to represent LLM application specific semantic conventions.
To use OpenInference Semantic Attributes in Python, ensure you have the semantic conventions package:
pip install openinference-semantic-conventionsThen you can use it in code:
from opentelemetry import trace
from openinference.semconv.trace import SpanAttributes
# ...
current_span = trace.get_current_span()
current_span.set_attribute(SpanAttributes.INPUT_VALUE, "Hello world!")
current_span.set_attribute(SpanAttributes.LLM_MODEL_NAME, "gpt-3.5-turbo")Events are human-readable messages that represent "something happening" at a particular moment during the lifetime of a span. You can think of it as a primitive log.
from opentelemetry import trace
current_span = trace.get_current_span()
current_span.add_event("Gonna try it!")
# Do the thing
current_span.add_event("Did it!")The span status allows you to signal the success or failure of the code executed within the span.
from opentelemetry import trace
from opentelemetry.trace import Status, StatusCode
current_span = trace.get_current_span()
try:
# something that might fail
except:
current_span.set_status(Status(StatusCode.ERROR))It can be a good idea to record exceptions when they happen. It’s recommended to do this in conjunction with setting span status.
from opentelemetry import trace
from opentelemetry.trace import Status, StatusCode
current_span = trace.get_current_span()
try:
# something that might fail
# Consider catching a more specific exception in your code
except Exception as ex:
current_span.set_status(Status(StatusCode.ERROR))
current_span.record_exception(ex)