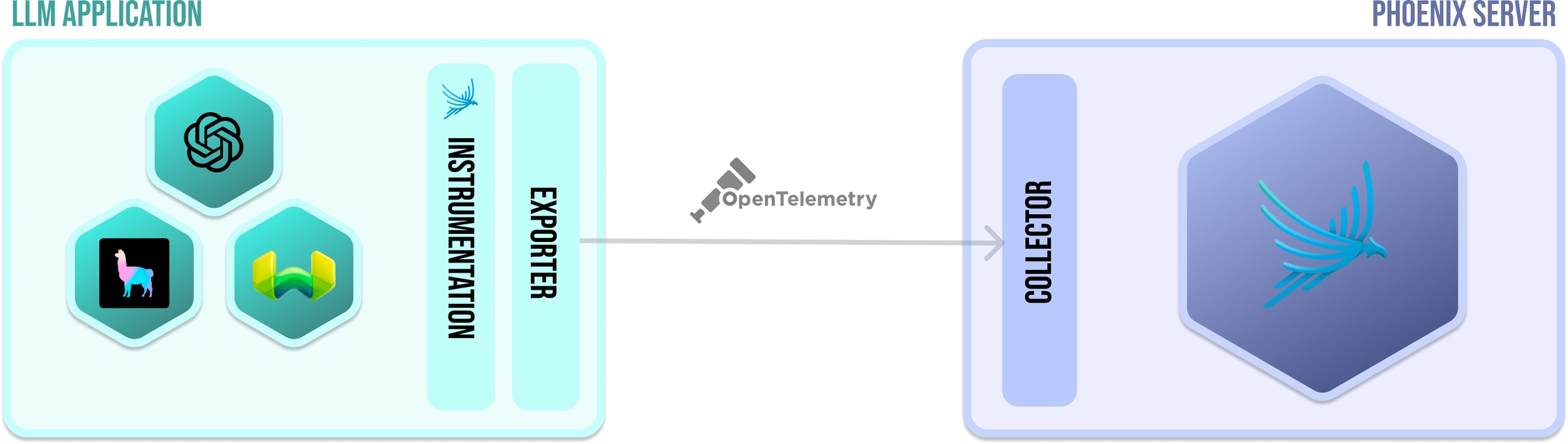
In order for an application to emit traces for analysis, the application must be instrumented. Your application can be manually instrumented or be automatically instrumented. With phoenix, there a set of plugins (instrumentors) that can be added to your application's startup process that perform auto-instrumentation. These plugins collect spans for your application and export them for collection and visualization. For phoenix, all the instrumentors are managed via a single repository called OpenInference. The comprehensive list of instrumentors can be found in the how-to guide.
An exporter takes the spans created via instrumentation and exports them to a collector. In simple terms, it just sends the data to the Phoenix. When using Phoenix, most of this is completely done under the hood when you call instrument on an instrumentor.
The Phoenix server is a collector and a UI that helps you troubleshoot your application in real time. When you run or run phoenix (e.x. px.launch_app(), container), Phoenix starts receiving spans from any application(s) that is exporting spans to it.
OpenTelemetetry Protocol (or OTLP for short) is the means by which traces arrive from your application to the Phoenix collector. Phoenix currently supports OTLP over HTTP.
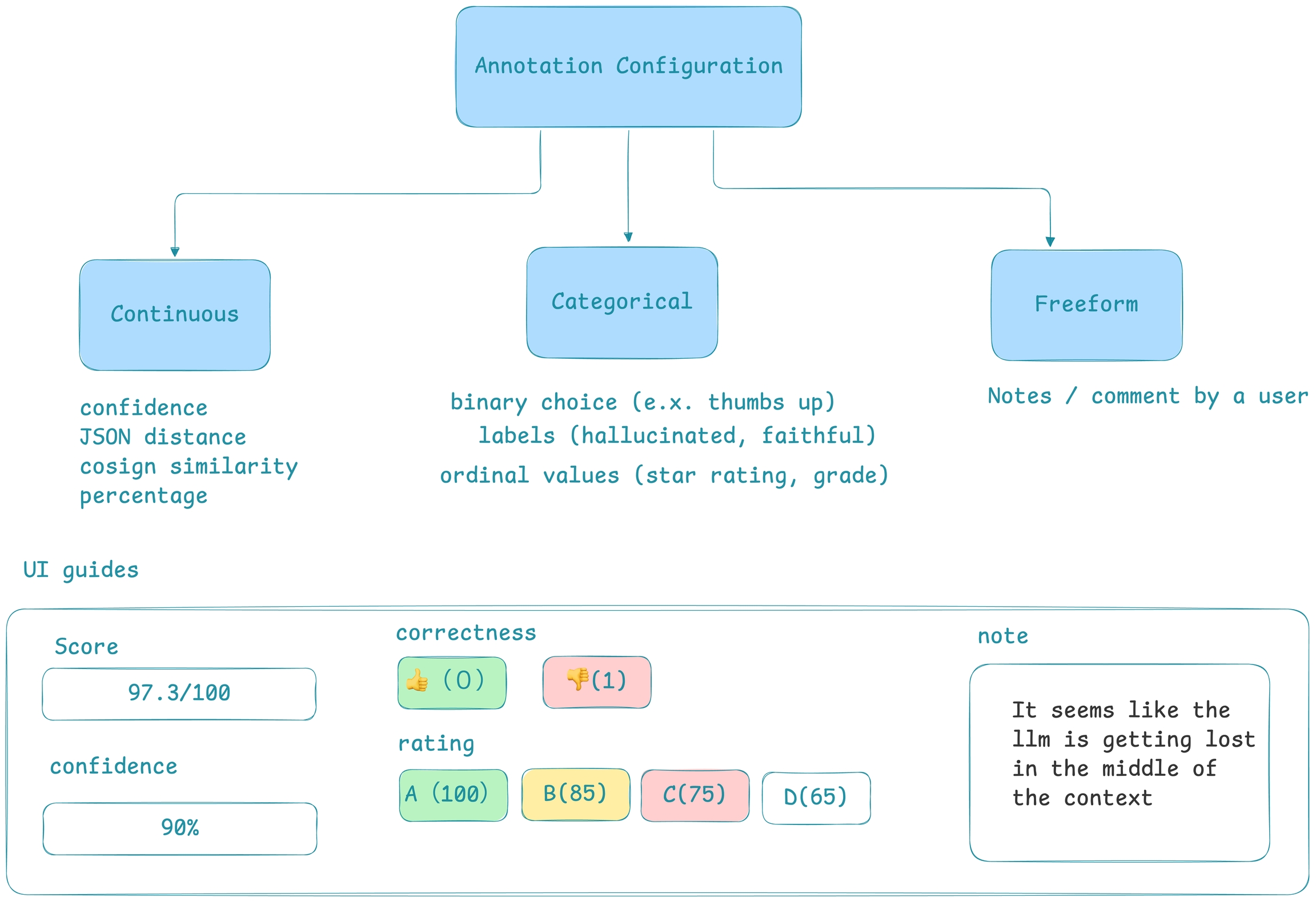
Depending on what you want to do with your annotations, you may want to configure a rubric for what your annotation represents - e.g. is it a category, number with a range (continuous), or freeform.
Annotation type: - Categorical: Predefined labels for selection. (e.x. 👍 or 👎) - Continuous: a score across a specified range. (e.g. confidence score 0-100) - Freeform: Open-ended text comments. (e.g. "correct")
Optimize the direction based on your goal: - Maximize: higher scores are better. (e.g. confidence) - Minimize: lower scores are better. (e.g. hallucinations) - None: direction optimization does not apply. (e.g. tone)
See for more details.
Phoenix supports annotating different annotation targets to capture different levels of LLM application performance. The core annotation types include:
Span Annotations: Applied to individual spans within a trace, providing granular feedback about specific components
Document Annotations: Specifically for retrieval systems, evaluating individual documents with metrics like relevance and precision
Each annotation can include:
Labels: Text-based classifications (e.g., "helpful" or "not helpful")
Scores: Numeric evaluations (e.g., 0-1 scale for relevance)
Explanations: Detailed justifications for the annotation
These annotations can come from different sources:
Human feedback (e.g., thumbs up/down from end-users)
LLM-as-a-judge evaluations (automated assessments)
Code-based evaluations (programmatic metrics)
Phoenix also supports specialized evaluation metrics for retrieval systems, including NDCG, Precision@K, and Hit Rate, making it particularly useful for evaluating search and retrieval components of LLM applications.
Human feedback allows you to understand how your users are experiencing your application and helps draw attention to problematic traces. Phoenix makes it easy to collect feedback for traces and view it in the context of the trace, as well as filter all your traces based on the feedback annotations you send. Before anything else, you want to know if your users or customers are happy with your product. This can be as straightforward as adding 👍 👎 buttons to your application, and logging the result as annotations.
For more information on how to wire up your application to collect feedback from your users, see .
When you have large amounts of data it can be immensely efficient and valuable to leverage LLM judges via evals to produce labels and scores to annotate your traces with. Phoenix's evals library as well as other third-party eval libraries can be leveraged to annotate your spans with evaluations. For details see to:
Generate evaluation results
Add evaluation results to spans
Sometimes you need to rely on human annotators to attach feedback to specific traces of your application. Human annotations through the UI can be thought of as manual quality assurance. While it can be a bit more labor intensive, it can help in sharing insights within a team, curating datasets of good/bad examples, and even in training an LLM judge.
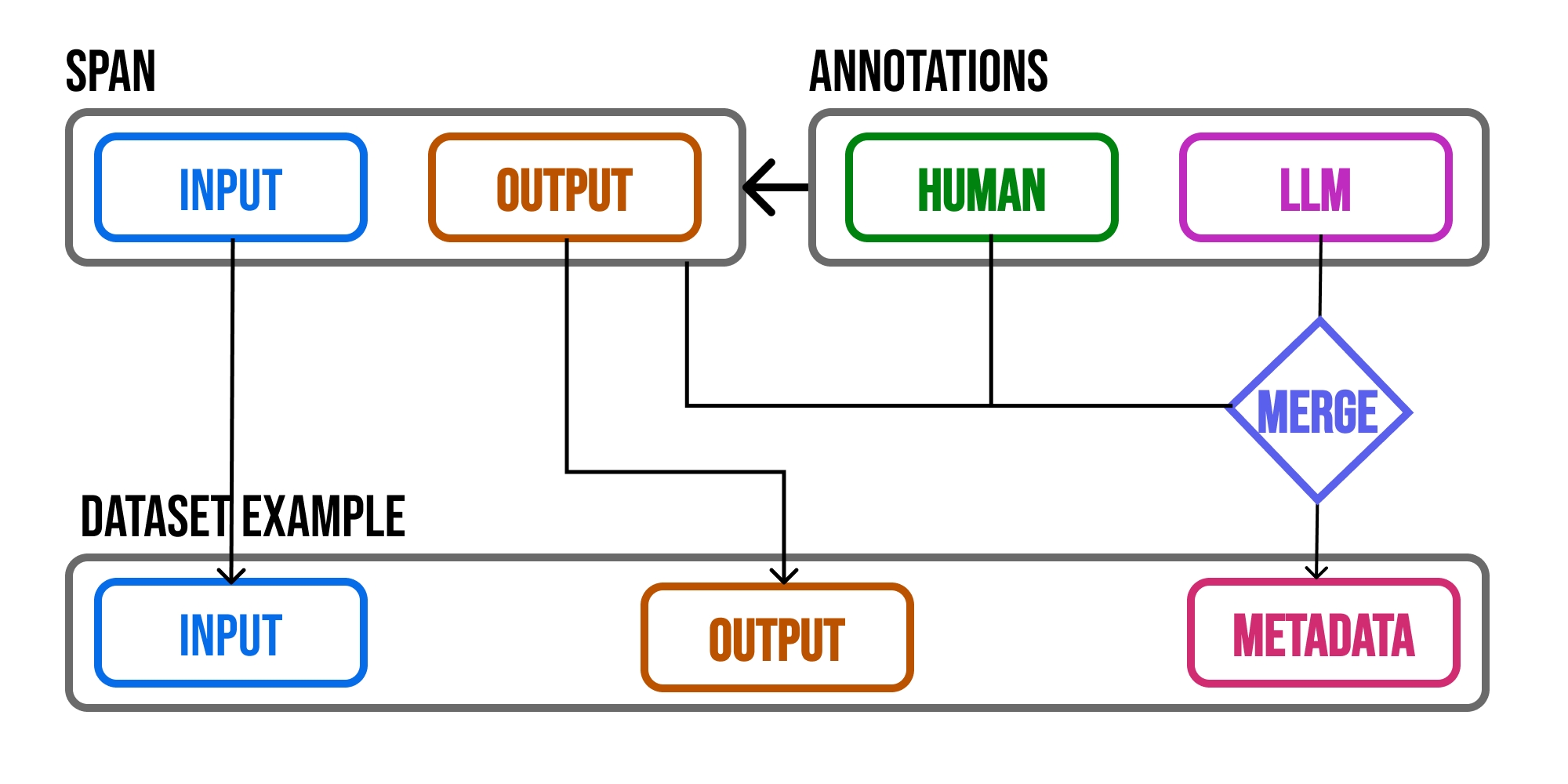
Annotations can help you share valuable insight about how your application is performing. However making these insights actionable can be difficult. With Phoenix, the annotations you add to your trace data is propagated to datasets so that you can use the annotations during experimentation.
Since Phoenix datasets preserve the annotations, you can track whether or not changes to your application (e.g. experimentation) produce better results (e.g. better scores / labels). Phoenix evaluators have access to the example metadata at evaluation time, making it possible to track improvements / regressions over previous generations (e.g. the previous annotations).
AI development currently faces challenges when evaluating LLM application outputs at scale:
Human annotation is precise but time-consuming and impossible to scale efficiently.
Existing automated methods using LLM judges require careful prompt engineering and often fall short of capturing human evaluation nuances.
Solutions requiring extensive human resources are difficult to scale and manage.
These challenges create a bottleneck in the rapid development and improvement of high-quality LLM applications.
Since Phoenix datasets preserve the annotations in the example metadata, you can use datasets to build human-preference calibrated judges using libraries and tools such as DSPy and Zenbase.
Phoenix supports three types of annotators: Human, LLM, and Code.
Phoenix provides two interfaces for annotations: API and APP. The API interface via the REST clients enables automated feedback collection at scale, such as collecting thumbs up/down from end-users in production, providing real-time insights into LLM system performance. The APP interface via the UI offers an efficient workflow for human annotators with hotkey support and structured configurations, making it practical to create high-quality training sets for LLMs.
The combination of these interfaces creates a powerful feedback loop: human annotations through the APP interface help train and calibrate LLM evaluators, which can then be deployed at scale via the API. This cycle of human oversight and automated evaluation helps identify the most valuable examples for review while maintaining quality at scale.
Annotation configurations in Phoenix are designed to maximize efficiency for human annotators. The system allows you to define the structure of annotations (categorical or continuous values, with appropriate bounds and options) and pair these with keyboard shortcuts (hotkeys) to enable rapid annotation.
For example, a categorical annotation might be configured with specific labels that can be quickly assigned using number keys, while a continuous annotation might use arrow keys for fine-grained scoring. This combination of structured configurations and hotkey support allows annotators to provide feedback quickly, significantly reducing the effort required for manual annotation tasks.
The primary goal is to streamline the annotation workflow, enabling human annotators to process large volumes of data efficiently while maintaining quality and consistency in their feedback.
Annotator Kind
Source
Purpose
Strengths
Use Case
Human
Manual review
Expert judgment and quality assurance
High accuracy, nuanced understanding
Manual QA, edge cases, subjective evaluation
LLM
Language model output
Scalable evaluation of application responses
Fast, scalable, consistent across examples
Large-scale output scoring, pattern review
Code
Programmatic evaluators
Automated assessment based on rules/metrics
Objective, repeatable, useful in experiments
Model benchmarking, regression testing
A span represents a unit of work or operation (think a span of time). It tracks specific operations that a request makes, painting a picture of what happened during the time in which that operation was executed.
A span contains name, time-related data, structured log messages, and other metadata (that is, Attributes) to provide information about the operation it tracks. A span for an LLM execution in JSON format is displayed below
{
"name": "llm",
"context": {
"trace_id": "0x6c80880dbeb609e2ed41e06a6397a0dd",
"span_id": "0xd9bdedf0df0b7208",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x7eb5df0046c77cd2",
"start_time": "2024-05-08T21:46:11.480777Z",
"end_time": "2024-05-08T21:46:35.368042Z",
"status": {
"status_code": "OK"
},
"attributes": {
"openinference.span.kind": "LLM",
"llm.input_messages.0.message.role": "system",
"llm.input_messages.0.message.content": "\n The following is a friendly conversation between a user and an AI assistant.\n The assistant is talkative and provides lots of specific details from its context.\n If the assistant does not know the answer to a question, it truthfully says it\n does not know.\n\n Here are the relevant documents for the context:\n\n page_label: 7\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.4Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. No piece may weigh more than 70 pounds.\nb. The combined length and girth of a piece (the length of its longest side plus \nthe distance around its thickest part) may not exceed 108 inches.\nc. Lower size or weight standards apply to mail addressed to certain APOs and \nFPOs, subject to 703.2.0 and 703.4.0 and for Department of State mail, \nsubject to 703.3.0 .\n\npage_label: 6\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.2.10Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. The reply half of a double card must be used for reply only and may not be \nused to convey a message to the original addressee or to send statements \nof account. The reply half may be formatted for response purposes (e.g., contain blocks for completion by the addressee).\nb. A double card must be folded before mailing and prepared so that the \naddress on the reply half is on the inside when the double card is originally \nmailed. The address side of the reply half may be prepared as Business \nReply Mail, Courtesy Reply Mail, meter reply mail, or as a USPS Returns service label.\nc. Plain stickers, seals, or a single wire stitch (staple) may be used to fasten the \nopen edge at the top or bottom once the card is folded if affixed so that the \ninner surfaces of the cards can be readily examined. Fasteners must be \naffixed according to the applicable preparation requirements for the price claimed. Any sealing on the left and right sides of the cards, no matter the \nsealing process used, is not permitted.\nd. The first half of a double card must be detached when the reply half is \nmailed for return. \n6.2.10 Enclosures\nEnclosures in double postcards are prohibited at card prices. \n6.3 Nonmachinable Pieces\n6.3.1 Nonmachinable Letters\nLetter-size pieces (except card-size pieces) that meet one or more of the \nnonmachinable characteristics in 1.2 are subject to the nonmachinable \nsurcharge (see 133.1.7 ). \n6.3.2 Nonmachinable Flats\nFlat-size pieces that do not meet the standards in 2.0 are considered parcels, \nand the mailer must pay the applicable parcel price. \n6.4 Parcels \n[7-9-23] USPS Ground Advantage \u2014 Retail parcels are eligible for USPS \nTracking and Signature Confirmation service. A USPS Ground Advantage \u2014 \nRetail parcel is the following:\na. A mailpiece that exceeds any one of the maximum dimensions for a flat \n(large envelope). See 2.1.\nb. A flat-size mailpiece, regardless of thickness, that is rigid or nonrectangular. \nc. A flat-size mailpiece that is not uniformly thick under 2.4. \nd.[7-9-23] A mailpiece that does not exceed 130 inches in combined length \nand girth.\n7.0 Additional Physical Standards for Media Mail and Library \nMail\nThese standards apply to Media Mail and Library Mail:\n\npage_label: 4\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.1Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\n4.0 Additional Physical Standa rds for Priority Mail Express\nEach piece of Priority Mail Express may not weigh more than 70 pounds. The \ncombined length and girth of a piece (the length of its longest side plus the \ndistance around its thickest part) may not exceed 108 inches. Lower size or weight standards apply to Priority Mail Express addressed to certain APO/FPO \nand DPOs. Priority Mail Express items must be large enough to hold the required \nmailing labels and indicia on a single optical plane without bending or folding.\n5.0 Additional Physical St andards for Priority Mail\nThe maximum weight is 70 pounds. The combined length and girth of a piece \n(the length of its longest side plus the distance around its thickest part) may not \nexceed 108 inches. Lower size and weight standards apply for some APO/FPO \nand DPO mail subject to 703.2.0 , and 703.4.0 , and for Department of State mail \nsubject to 703.3.0 . \n[7-9-23] \n6.0 Additional Physical Standa rds for First-Class Mail and \nUSPS Ground Advantage \u2014 Retail\n[7-9-23]\n6.1 Maximum Weight\n6.1.1 First-Class Mail\nFirst-Class Mail (letters and flats) must not exceed 13 ounces. \n6.1.2 USPS Ground Advantage \u2014 Retail\nUSPS Ground Advantage \u2014 Retail mail must not exceed 70 pounds.\n6.2 Cards Claimed at Card Prices\n6.2.1 Card Price\nA card may be a single or double (reply) stamped card or a single or double postcard. Stamped cards are available from USPS with postage imprinted on \nthem. Postcards are commercially available or privately printed mailing cards. To \nbe eligible for card pricing, a card and each half of a double card must meet the physical standards in 6.2 and the applicable eligibility for the price claimed. \nIneligible cards are subject to letter-size pricing. \n6.2.2 Postcard Dimensions\nEach card and part of a double card claimed at card pricing must be the following: \na. Rectangular.b. Not less than 3-1/2 inches high, 5 inches long, and 0.007 inch thick.\nc. Not more than 4-1/4 inches high, or more than 6 inches long, or greater than \n0.016 inch thick.\nd. Not more than 3.5 ounces (Charge flat-size prices for First-Class Mail \ncard-type pieces over 3.5 ounces.)\n\n Instruction: Based on the above documents, provide a detailed answer for the user question below.\n Answer \"don't know\" if not present in the document.\n ",
"llm.input_messages.1.message.role": "user",
"llm.input_messages.1.message.content": "Hello",
"llm.model_name": "gpt-4-turbo-preview",
"llm.invocation_parameters": "{\"temperature\": 0.1, \"model\": \"gpt-4-turbo-preview\"}",
"output.value": "How are you?" },
"events": [],
"links": [],
"resource": {
"attributes": {},
"schema_url": ""
}
}Spans can be nested, as is implied by the presence of a parent span ID: child spans represent sub-operations. This allows spans to more accurately capture the work done in an application.
A trace records the paths taken by requests (made by an application or end-user) as they propagate through multiple steps.
Without tracing, it is challenging to pinpoint the cause of performance problems in a system.
It improves the visibility of our application or system’s health and lets us debug behavior that is difficult to reproduce locally. Tracing is essential for LLM applications, which commonly have nondeterministic problems or are too complicated to reproduce locally.
Tracing makes debugging and understanding LLM applications less daunting by breaking down what happens within a request as it flows through a system.
A trace is made of one or more spans. The first span represents the root span. Each root span represents a request from start to finish. The spans underneath the parent provide a more in-depth context of what occurs during a request (or what steps make up a request).
A project is a collection of traces. You can think of a project as a container for all the traces that are related to a single application or service. You can have multiple projects, and each project can have multiple traces. Projects can be useful for various use-cases such as separating out environments, logging traces for evaluation runs, etc. To learn more about how to setup projects, see the how-to guide
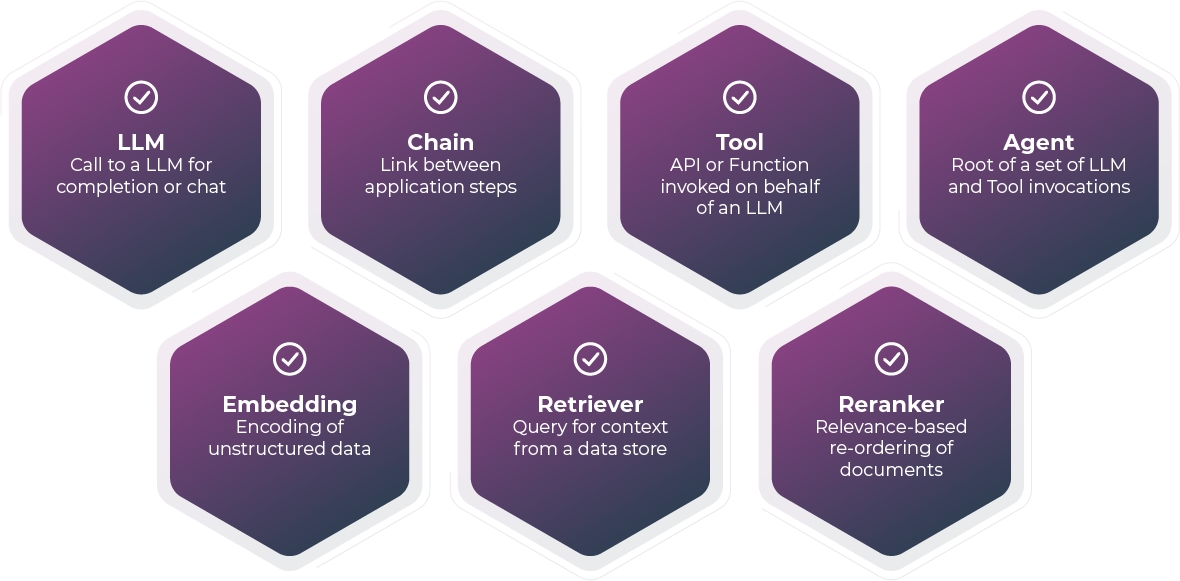
When a span is created, it is created as one of the following: Chain, Retriever, Reranker, LLM, Embedding, Agent, or Tool.
CHAIN
A Chain is a starting point or a link between different LLM application steps. For example, a Chain span could be used to represent the beginning of a request to an LLM application or the glue code that passes context from a retriever to and LLM call.
RETRIEVER
A Retriever is a span that represents a data retrieval step. For example, a Retriever span could be used to represent a call to a vector store or a database.
RERANKER
A Reranker is a span that represents the reranking of a set of input documents. For example, a cross-encoder may be used to compute the input documents' relevance scores with respect to a user query, and the top K documents with the highest scores are then returned by the Reranker.
LLM
An LLM is a span that represents a call to an LLM. For example, an LLM span could be used to represent a call to OpenAI or Llama.
EMBEDDING
An Embedding is a span that represents a call to an LLM for an embedding. For example, an Embedding span could be used to represent a call OpenAI to get an ada-2 embedding for retrieval.
TOOL
A Tool is a span that represents a call to an external tool such as a calculator or a weather API.
AGENT
A span that encompasses calls to LLMs and Tools. An agent describes a reasoning block that acts on tools using the guidance of an LLM.\
Attributes are key-value pairs that contain metadata that you can use to annotate a span to carry information about the operation it is tracking.
For example, if a span invokes an LLM, you can capture the model name, the invocation parameters, the token count, and so on.
Attributes have the following rules:
Keys must be non-null string values
Values must be a non-null string, boolean, floating point value, integer, or an array of these values Additionally, there are Semantic Attributes, which are known naming conventions for metadata that is typically present in common operations. It's helpful to use semantic attribute naming wherever possible so that common kinds of metadata are standardized across systems. See semantic conventions for more information.
Below are example OTEL spans for each OpenInference spanKind to be used as reference when doing manual instrumentation
{
"name": "llm",
"context": {
"trace_id": "0x6c80880dbeb609e2ed41e06a6397a0dd",
"span_id": "0xd9bdedf0df0b7208",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x7eb5df0046c77cd2",
"start_time": "2024-05-08T21:46:11.480777Z",
"end_time": "2024-05-08T21:46:35.368042Z",
"status": {
"status_code": "OK"
},
"attributes": {
"openinference.span.kind": "LLM",
"llm.input_messages.0.message.role": "system",
"llm.input_messages.0.message.content": "\n The following is a friendly conversation between a user and an AI assistant.\n The assistant is talkative and provides lots of specific details from its context.\n If the assistant does not know the answer to a question, it truthfully says it\n does not know.\n\n Here are the relevant documents for the context:\n\n page_label: 7\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.4Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. No piece may weigh more than 70 pounds.\nb. The combined length and girth of a piece (the length of its longest side plus \nthe distance around its thickest part) may not exceed 108 inches.\nc. Lower size or weight standards apply to mail addressed to certain APOs and \nFPOs, subject to 703.2.0 and 703.4.0 and for Department of State mail, \nsubject to 703.3.0 .\n\npage_label: 6\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.2.10Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. The reply half of a double card must be used for reply only and may not be \nused to convey a message to the original addressee or to send statements \nof account. The reply half may be formatted for response purposes (e.g., contain blocks for completion by the addressee).\nb. A double card must be folded before mailing and prepared so that the \naddress on the reply half is on the inside when the double card is originally \nmailed. The address side of the reply half may be prepared as Business \nReply Mail, Courtesy Reply Mail, meter reply mail, or as a USPS Returns service label.\nc. Plain stickers, seals, or a single wire stitch (staple) may be used to fasten the \nopen edge at the top or bottom once the card is folded if affixed so that the \ninner surfaces of the cards can be readily examined. Fasteners must be \naffixed according to the applicable preparation requirements for the price claimed. Any sealing on the left and right sides of the cards, no matter the \nsealing process used, is not permitted.\nd. The first half of a double card must be detached when the reply half is \nmailed for return. \n6.2.10 Enclosures\nEnclosures in double postcards are prohibited at card prices. \n6.3 Nonmachinable Pieces\n6.3.1 Nonmachinable Letters\nLetter-size pieces (except card-size pieces) that meet one or more of the \nnonmachinable characteristics in 1.2 are subject to the nonmachinable \nsurcharge (see 133.1.7 ). \n6.3.2 Nonmachinable Flats\nFlat-size pieces that do not meet the standards in 2.0 are considered parcels, \nand the mailer must pay the applicable parcel price. \n6.4 Parcels \n[7-9-23] USPS Ground Advantage \u2014 Retail parcels are eligible for USPS \nTracking and Signature Confirmation service. A USPS Ground Advantage \u2014 \nRetail parcel is the following:\na. A mailpiece that exceeds any one of the maximum dimensions for a flat \n(large envelope). See 2.1.\nb. A flat-size mailpiece, regardless of thickness, that is rigid or nonrectangular. \nc. A flat-size mailpiece that is not uniformly thick under 2.4. \nd.[7-9-23] A mailpiece that does not exceed 130 inches in combined length \nand girth.\n7.0 Additional Physical Standards for Media Mail and Library \nMail\nThese standards apply to Media Mail and Library Mail:\n\npage_label: 4\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.1Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\n4.0 Additional Physical Standa rds for Priority Mail Express\nEach piece of Priority Mail Express may not weigh more than 70 pounds. The \ncombined length and girth of a piece (the length of its longest side plus the \ndistance around its thickest part) may not exceed 108 inches. Lower size or weight standards apply to Priority Mail Express addressed to certain APO/FPO \nand DPOs. Priority Mail Express items must be large enough to hold the required \nmailing labels and indicia on a single optical plane without bending or folding.\n5.0 Additional Physical St andards for Priority Mail\nThe maximum weight is 70 pounds. The combined length and girth of a piece \n(the length of its longest side plus the distance around its thickest part) may not \nexceed 108 inches. Lower size and weight standards apply for some APO/FPO \nand DPO mail subject to 703.2.0 , and 703.4.0 , and for Department of State mail \nsubject to 703.3.0 . \n[7-9-23] \n6.0 Additional Physical Standa rds for First-Class Mail and \nUSPS Ground Advantage \u2014 Retail\n[7-9-23]\n6.1 Maximum Weight\n6.1.1 First-Class Mail\nFirst-Class Mail (letters and flats) must not exceed 13 ounces. \n6.1.2 USPS Ground Advantage \u2014 Retail\nUSPS Ground Advantage \u2014 Retail mail must not exceed 70 pounds.\n6.2 Cards Claimed at Card Prices\n6.2.1 Card Price\nA card may be a single or double (reply) stamped card or a single or double postcard. Stamped cards are available from USPS with postage imprinted on \nthem. Postcards are commercially available or privately printed mailing cards. To \nbe eligible for card pricing, a card and each half of a double card must meet the physical standards in 6.2 and the applicable eligibility for the price claimed. \nIneligible cards are subject to letter-size pricing. \n6.2.2 Postcard Dimensions\nEach card and part of a double card claimed at card pricing must be the following: \na. Rectangular.b. Not less than 3-1/2 inches high, 5 inches long, and 0.007 inch thick.\nc. Not more than 4-1/4 inches high, or more than 6 inches long, or greater than \n0.016 inch thick.\nd. Not more than 3.5 ounces (Charge flat-size prices for First-Class Mail \ncard-type pieces over 3.5 ounces.)\n\n Instruction: Based on the above documents, provide a detailed answer for the user question below.\n Answer \"don't know\" if not present in the document.\n ",
"llm.input_messages.1.message.role": "user",
"llm.input_messages.1.message.content": "Hello",
"llm.model_name": "gpt-4-turbo-preview",
"llm.invocation_parameters": "{\"temperature\": 0.1, \"model\": \"gpt-4-turbo-preview\"}",
"output.value": "How are you?" },
"events": [],
"links": [],
"resource": {
"attributes": {},
"schema_url": ""
}
}{
"name": "retrieve",
"context": {
"trace_id": "0x6c80880dbeb609e2ed41e06a6397a0dd",
"span_id": "0x03f3466720f4bfc7",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x7eb5df0046c77cd2",
"start_time": "2024-05-08T21:46:11.044464Z",
"end_time": "2024-05-08T21:46:11.465803Z",
"status": {
"status_code": "OK"
},
"attributes": {
"openinference.span.kind": "RETRIEVER",
"input.value": "tell me about postal service",
"retrieval.documents.0.document.id": "6d4e27be-1d6d-4084-a619-351a44834f38",
"retrieval.documents.0.document.score": 0.7711453293100421,
"retrieval.documents.0.document.content": "<document-chunk-1>",
"retrieval.documents.0.document.metadata": "{\"page_label\": \"7\", \"file_name\": \"/data/101.pdf\", \"file_path\": \"/data/101.pdf\", \"file_type\": \"application/pdf\", \"file_size\": 47931, \"creation_date\": \"2024-04-12\", \"last_modified_date\": \"2024-04-12\"}",
"retrieval.documents.1.document.id": "869d9f6d-db9a-43c4-842f-74bd8d505147",
"retrieval.documents.1.document.score": 0.7672439175862021,
"retrieval.documents.1.document.content": "<document-chunk-2>",
"retrieval.documents.1.document.metadata": "{\"page_label\": \"6\", \"file_name\": \"/data/101.pdf\", \"file_path\": \"/data/101.pdf\", \"file_type\": \"application/pdf\", \"file_size\": 47931, \"creation_date\": \"2024-04-12\", \"last_modified_date\": \"2024-04-12\"}",
"retrieval.documents.2.document.id": "72b5cb6b-464f-4460-b497-cc7c09d1dbef",
"retrieval.documents.2.document.score": 0.7647611816897794,
"retrieval.documents.2.document.content": "<document-chunk-3>",
"retrieval.documents.2.document.metadata": "{\"page_label\": \"4\", \"file_name\": \"/data/101.pdf\", \"file_path\": \"/data/101.pdf\", \"file_type\": \"application/pdf\", \"file_size\": 47931, \"creation_date\": \"2024-04-12\", \"last_modified_date\": \"2024-04-12\"}"
},
"events": [],
"links": [],
"resource": {
"attributes": {},
"schema_url": ""
}
}
To log traces, you must instrument your application either manually or automatically. To log to a remote instance of Phoenix, you must also configure the host and port where your traces will be sent.
When running running Phoenix locally on the default port of 6006, no additional configuration is necessary.
import phoenix as px
from phoenix.trace import LangChainInstrumentor
px.launch_app()
LangChainInstrumentor().instrument()
# run your LangChain applicationIf you are running a remote instance of Phoenix, you can configure your instrumentation to log to that instance using the PHOENIX_HOST and PHOENIX_PORT environment variables.
import os
from phoenix.trace import LangChainInstrumentor
# assume phoenix is running at 162.159.135.42:6007
os.environ["PHOENIX_HOST"] = "162.159.135.42"
os.environ["PHOENIX_PORT"] = "6007"
LangChainInstrumentor().instrument() # logs to http://162.159.135.42:6007
# run your LangChain applicationAlternatively, you can use the PHOENIX_COLLECTOR_ENDPOINT environment variable.
import os
from phoenix.trace import LangChainInstrumentor
# assume phoenix is running at 162.159.135.42:6007
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "162.159.135.42:6007"
LangChainInstrumentor().instrument() # logs to http://162.159.135.42:6007
# run your LangChain applicationTracing can be paused temporarily or disabled permanently.
Pause tracing using context manager
If there is a section of your code for which tracing is not desired, e.g. the document chunking process, it can be put inside the suppress_tracing context manager as shown below.
from phoenix.trace import suppress_tracing
with suppress_tracing():
# Code running inside this block doesn't generate traces.
# For example, running LLM evals here won't generate additional traces.
...
# Tracing will resume outside the block.
...Uninstrument the auto-instrumentors permanently
Calling .uninstrument() on the auto-instrumentors will remove tracing permanently. Below is the examples for LangChain, LlamaIndex and OpenAI, respectively.
LangChainInstrumentor().uninstrument()
LlamaIndexInstrumentor().uninstrument()
OpenAIInstrumentor().uninstrument()
# etc.To get token counts when streaming, install openai>=1.26 and set stream_options={"include_usage": True} when calling create. Below is an example Python code snippet. For more info, see here.
response = openai.OpenAI().chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Write a haiku."}],
max_tokens=20,
stream=True,
stream_options={"include_usage": True},
)If you have customized a LangChain component (say a retriever), you might not get tracing for that component without some additional steps. Internally, instrumentation relies on components to inherit from LangChain base classes for the traces to show up. Below is an example of how to inherit from LanChain base classes to make a custom retriever and to make traces show up.
from typing import List
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.retrievers import BaseRetriever, Document
from openinference.instrumentation.langchain import LangChainInstrumentor
from opentelemetry import trace as trace_api
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk import trace as trace_sdk
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
PHOENIX_COLLECTOR_ENDPOINT = "http://127.0.0.1:6006/v1/traces"
tracer_provider = trace_sdk.TracerProvider()
trace_api.set_tracer_provider(tracer_provider)
tracer_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter(endpoint)))
LangChainInstrumentor().instrument()
class CustomRetriever(BaseRetriever):
"""
This example is taken from langchain docs.
https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/custom_retriever/
A custom retriever that contains the top k documents that contain the user query.
This retriever only implements the sync method _get_relevant_documents.
If the retriever were to involve file access or network access, it could benefit
from a native async implementation of `_aget_relevant_documents`.
As usual, with Runnables, there's a default async implementation that's provided
that delegates to the sync implementation running on another thread.
"""
k: int
"""Number of top results to return"""
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
"""Sync implementations for retriever."""
matching_documents: List[Document] = []
# Custom logic to find the top k documents that contain the query
for index in range(self.k):
matching_documents.append(Document(page_content=f"dummy content at {index}", score=1.0))
return matching_documents
retriever = CustomRetriever(k=3)
if __name__ == "__main__":
documents = retriever.invoke("what is the meaning of life?")