Datasets are critical assets for building robust prompts, evals, fine-tuning,
Datasets are critical assets for building robust prompts, evals, fine-tuning, and much more. Phoenix allows you to build datasets manually, programmatically, or from files.
Export datasets for offline analysis, evals, and fine-tuning.
Exporting to CSV - how to quickly download a dataset to use elsewhere
Exporting to OpenAI Ft - want to fine tune an LLM for better accuracy and cost? Export llm examples for fine-tuning.
Exporting to OpenAI Evals - have some good examples to use for benchmarking of llms using OpenAI evals? export to OpenAI evals format.
Want to just use the contents of your dataset in another context? Simply click on the export to CSV button on the dataset page and you are good to go!
Fine-tuning lets you get more out of the models available by providing:
Higher quality results than prompting
Ability to train on more examples than can fit in a prompt
Token savings due to shorter prompts
Lower latency requests
Fine-tuning improves on few-shot learning by training on many more examples than can fit in the prompt, letting you achieve better results on a wide number of tasks. Once a model has been fine-tuned, you won't need to provide as many examples in the prompt. This saves costs and enables lower-latency requests. Phoenix natively exports OpenAI Fine-Tuning JSONL as long as the dataset contains compatible inputs and outputs.
Evals provide a framework for evaluating large language models (LLMs) or systems built using LLMs. OpenAI Evals offer an existing registry of evals to test different dimensions of OpenAI models and the ability to write your own custom evals for use cases you care about. You can also use your data to build private evals. Phoenix can natively export the OpenAI Evals format as JSONL so you can use it with OpenAI Evals. See https://github.com/openai/evals for details.
When manually creating a dataset (let's say collecting hypothetical questions and answers), the easiest way to start is by using a spreadsheet. Once you've collected the information, you can simply upload the CSV of your data to the Phoenix platform using the UI. You can also programmatically upload tabular data using Pandas as seen below.
Sometimes you just want to upload datasets using plain objects as CSVs and DataFrames can be too restrictive about the keys.
from phoenix.client import Client
px_client = Client()
ds = px_client.datasets.create_dataset(
name="my-synthetic-dataset",
inputs=[{ "question": "hello" }, { "question": "good morning" }],
outputs=[{ "answer": "hi" }, { "answer": "good morning" }],
);One of the quickest ways of getting started is to produce synthetic queries using an LLM.
One use case for synthetic data creation is when you want to test your RAG pipeline. You can leverage an LLM to synthesize hypothetical questions about your knowledge base.
In the below example we will use Phoenix's built-in llm_generate, but you can leverage any synthetic dataset creation tool you'd like.
Imagine you have a knowledge-base that contains the following documents:
import pandas as pd
document_chunks = [
"Paul Graham is a VC",
"Paul Graham loves lisp",
"Paul founded YC",
]
document_chunks_df = pd.DataFrame({"text": document_chunks})generate_questions_template = (
"Context information is below.\n\n"
"---------------------\n"
"{text}\n"
"---------------------\n\n"
"Given the context information and not prior knowledge.\n"
"generate only questions based on the below query.\n\n"
"You are a Teacher/ Professor. Your task is to setup "
"one question for an upcoming "
"quiz/examination. The questions should be diverse in nature "
"across the document. Restrict the questions to the "
"context information provided.\n\n"
"Output the questions in JSON format with the key question"
)Once your synthetic data has been created, this data can be uploaded to Phoenix for later re-use.
import json
from phoenix.evals import OpenAIModel, llm_generate
def output_parser(response: str, index: int):
try:
return json.loads(response)
except json.JSONDecodeError as e:
return {"__error__": str(e)}
questions_df = llm_generate(
dataframe=document_chunks_df,
template=generate_questions_template,
model=OpenAIModel(model="gpt-3.5-turbo"),
output_parser=output_parser,
concurrency=20,
)
questions_df["output"] = [None, None, None]Once we've constructed a collection of synthetic questions, we can upload them to a Phoenix dataset.
from phoenix.client import Client
# Note that the below code assumes that phoenix is running and accessible
px_client = Client()
px_client.datasets.create_dataset(
dataframe=questions_df,
name="paul-graham-questions",
input_keys=["question"],
output_keys=["output"],
)If you have an application that is traced using instrumentation, you can quickly add any span or group of spans using the Phoenix UI.
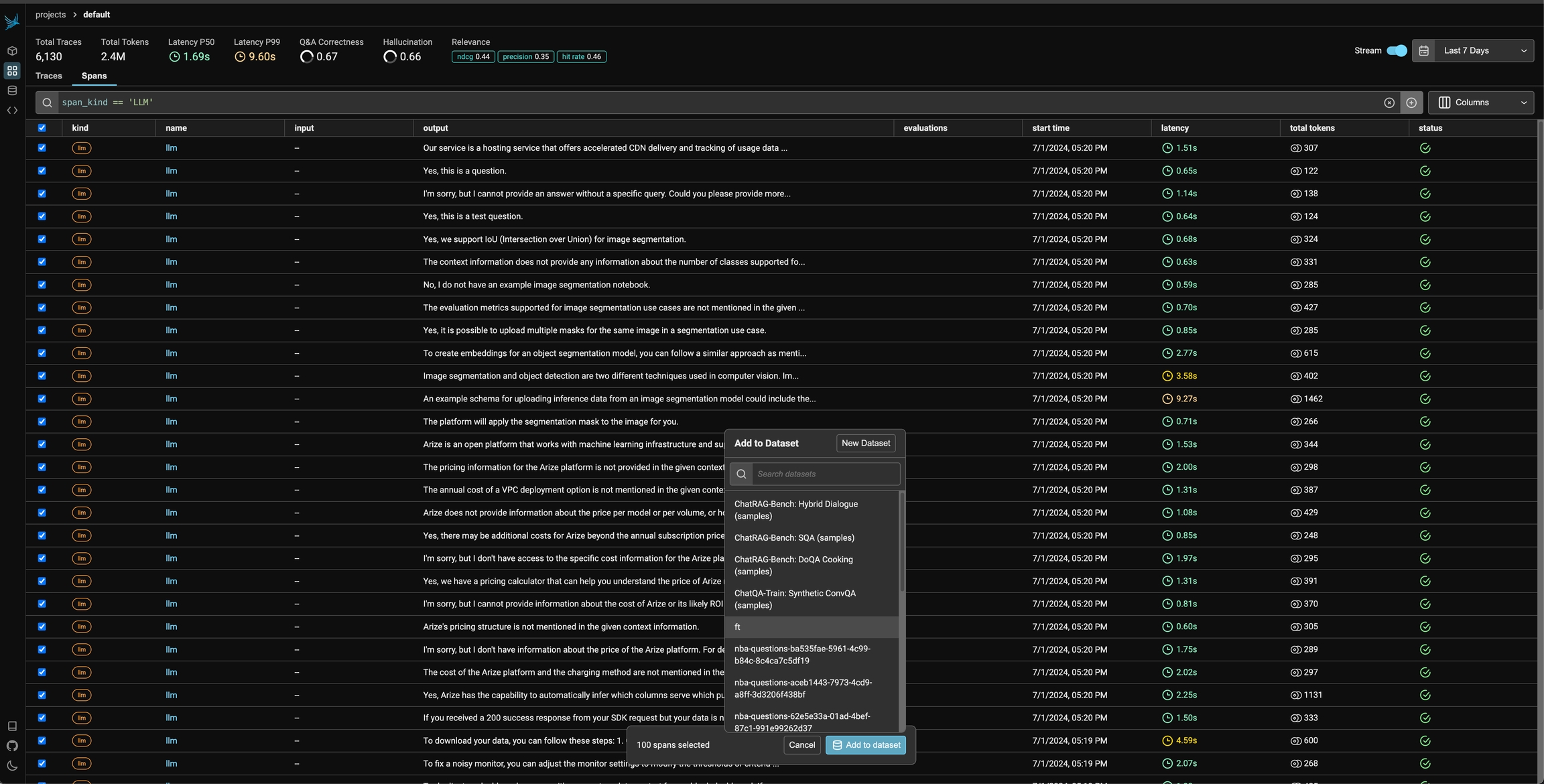
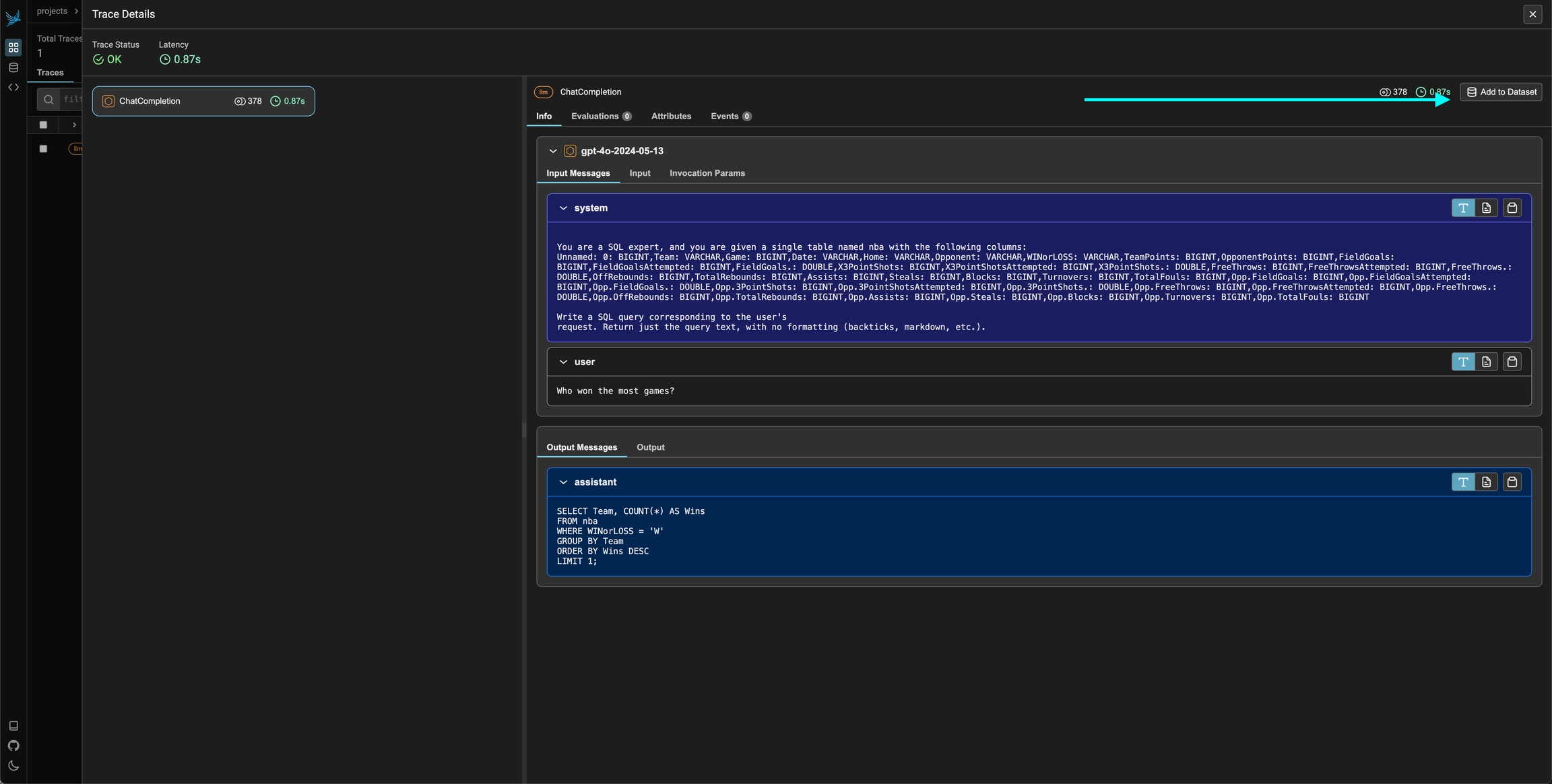
To add a single span to a dataset, simply select the span in the trace details view. You should see an add to dataset button on the top right. From there you can select the dataset you would like to add it to and make any changes you might need to make before saving the example.
You can also use the filters on the spans table and select multiple spans to add to a specific dataset.
import pandas as pd
import phoenix as px
from phoenix.client import Client
queries = [
"What are the 9 planets in the solar system?",
"How many generations of fundamental particles have we observed?",
"Is Aluminum a superconductor?",
]
responses = [
"There are 8 planets in the solar system.",
"We have observed 3 generations of fundamental particles.",
"Yes, Aluminum becomes a superconductor at 1.2 degrees Kelvin.",
]
dataset_df = pd.DataFrame(data={"query": queries, "responses": responses})
px.launch_app()
px_client = Client()
dataset = px_client.datasets.create_dataset(
dataframe=dataset_df,
name="physics-questions",
input_keys=["query"],
output_keys=["responses"],
)