
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Workflows are the backbone of many successful LLM applications. They define how language models interact with tools, data, and users—often through a sequence of clearly orchestrated steps. Unlike fully autonomous agents, workflows offer structure and predictability, making them a practical choice for many real-world tasks.
In this guide, we share practical workflows using a variety of agent frameworks, including:
Each section highlights how to use these tools effectively—showing what’s possible, where they shine, and where a simpler solution might serve you better. Whether you're orchestrating deterministic workflows or building dynamic agentic systems, the goal is to help you choose the right tool for your context and build with confidence.
For a deeper dive into the principles behind agentic systems and when to use them, see Anthropic’s “Building Effective Agents”.
Agent Routing is the process of directing a task, query, or request to the most appropriate agent based on context or capabilities. In multi-agent systems, it helps determine which agent is best suited to handle a specific input based on skills, domain expertise, or available tools. This enables more efficient, accurate, and specialized handling of complex tasks.
Prompt Chaining is the technique of breaking a complex task into multiple steps, where the output of one prompt becomes the input for the next. This allows a system to reason more effectively, maintain context across steps, and handle tasks that would be too difficult to solve in a single prompt. It's often used to simulate multi-step thinking or workflows.
Parallelization is the process of dividing a task into smaller, independent parts that can be executed simultaneously to speed up processing. It’s used to handle multiple inputs, computations, or agent responses at the same time rather than sequentially. This improves efficiency and speed, especially for large-scale or time-sensitive tasks.
An orchestrator is a central controller that manages and coordinates multiple components, agents, or processes to ensure they work together smoothly.
It decides what tasks need to be done, who or what should do them, and in what order. An orchestrator can handle things like scheduling, routing, error handling, and result aggregation. It might also manage prompt chains, route tasks to agents, and oversee parallel execution.
An evaluator assesses the quality or correctness of outputs, such as ranking responses, checking for factual accuracy, or scoring performance against a metric. An optimizer uses that evaluation to improve future outputs, either by fine-tuning models, adjusting parameters, or selecting better strategies. Together, they form a feedback loop that helps a system learn what works and refine itself over time.




Self-hosted Phoenix supports multiple user with authentication, roles, and more.
Phoenix Cloud is no longer limited to single-developer use—teams can manage access and share traces easily across their organization.
`The new Phoenix Cloud supports team management and collaboration. You can spin up multiple, customized Phoenix Spaces for different teams and use cases, manage individual user access and permissions for each space, and seamlessly collaborate with additional team members on your projects.
gRPC and HTTP are communication protocols used to transfer data between client and server applications.
HTTP (Hypertext Transfer Protocol) is a stateless protocol primarily used for website and web application requests over the internet.
gRPC (gRemote Procedure Call) is a modern, open-source communication protocol from Google that uses HTTP/2 for transport, protocol buffers as the interface description language, and provides features like bi-directional streaming, multiplexing, and flow control.
gRPC is more efficient in a tracing context than HTTP, but HTTP is more widely supported.
Phoenix can send traces over either HTTP or gRPC.
Phoenix does natively support gRPC for trace collection post 4.0 release. See Configuration for details.
Yes, in fact this is probably the preferred way to interact with OpenAI if your enterprise requires data privacy. Getting the parameters right for Azure can be a bit tricky so check out the models section for details.
We update the Phoenix version used by Phoenix Cloud on a weekly basis.
You can persist data in the notebook by either setting the use_temp_dir flag to false in px.launch_app which will persist your data in SQLite on your disk at the PHOENIX_WORKING_DIR. Alternatively you can deploy a phoenix instance and point to it via PHOENIX_COLLECTOR_ENDPOINT.
Use Phoenix to trace and evaluate AutoGen agents
AutoGen is an open-source framework by Microsoft for building multi-agent workflows. The AutoGen agent framework provides tools to define, manage, and orchestrate agents, including customizable behaviors, roles, and communication protocols.
Phoenix can be used to trace AutoGen agents by instrumenting their workflows, allowing you to visualize agent interactions, message flows, and performance metrics across multi-agent chains.
UserProxyAgent: Acts on behalf of the user to initiate tasks, guide the conversation, and relay feedback between agents. It can operate in auto or human-in-the-loop mode and control the flow of multi-agent interactions.
AssisstantAgent: Performs specialized tasks such as code generation, review, or analysis. It supports role-specific prompts, memory of prior turns, and can be equipped with tools to enhance its capabilities.
GroupChat: Coordinates structured, turn-based conversations among multiple agents. It maintains shared context, controls agent turn-taking, and stops the chat when completion criteria are met.
GroupChatManager: Manages the flow and logic of the GroupChat, including termination rules, turn assignment, and optional message routing customization.
Tool Integration: Agents can use external tools (e.g. Python, web search, RAG retrievers) to perform actions beyond text generation, enabling more grounded or executable outputs.
Memory and Context Tracking: Agents retain and access conversation history, enabling coherent and stateful dialogue over multiple turns.
Agent Roles
Poorly defined responsibilities can cause overlap or miscommunication, especially between multi-agent workflows.
Termination Conditions
GroupChat may continue even after a logical end, as UserProxyAgent can exhaust all allowed turns before stopping unless termination is explicitly triggered.
Human-in-the-Loop
Fully autonomous mode may miss important judgment calls without user oversight.
State Management
Excessive context can exceed token limits, while insufficient context breaks coherence.
Prompt chaining is a method where a complex task is broken into smaller, linked subtasks, with the output of one step feeding into the next. This workflow is ideal when a task can be cleanly decomposed into fixed subtasks, making each LLM call simpler and more accurate — trading off latency for better overall performance.
AutoGen makes it easy to build these chains by coordinating multiple agents. Each AssistantAgent focuses on a specialized task, while a UserProxyAgent manages the conversation flow and passes key outputs between steps. With Phoenix tracing, we can visualize the entire sequence, monitor individual agent calls, and debug the chain easily.
Notebook: Market Analysis Prompt Chaining Agent The agent conducts a multi-step market analysis workflow, starting with identifying general trends and culminating in an evaluation of company strengths.
How to evaluate: Ensure outputs are moved into inputs for the next step and logically build across steps (e.g., do identified trends inform the company evaluation?)
Confirm that each prompt step produces relevant and distinct outputs that contribute to the final analysis
Track total latency and token counts to see which steps cause inefficiencies
Ensure there are no redundant outputs or hallucinations in multi-step reasoning
Routing is a pattern designed to handle incoming requests by classifying them and directing them to the single most appropriate specialized agent or workflow.
AutoGen simplifies implementing this pattern by enabling a dedicated 'Router Agent' to analyze incoming messages and signal its classification decision. Based on this classification, the workflow explicitly directs the query to the appropriate specialist agent for a focused, separate interaction. The specialist agent is equipped with tools to carry out the request.
Notebook: Customer Service Routing Agent
We will build an intelligent customer service system, designed to efficiently handle diverse user queries directing them to a specialized AssistantAgent .
How to evaluate: Ensure the Router Agent consistently classifies incoming queries into the correct category (e.g., billing, technical support, product info)
Confirm that each query is routed to the appropriate specialized AssistantAgent without ambiguity or misdirection
Test with edge cases and overlapping intents to assess the router’s ability to disambiguate accurately
Watch for routing failures, incorrect classifications, or dropped queries during handoff between agents
The Evaluator-Optimizer pattern employs a loop where one agent acts as a generator, creating an initial output (like text or code), while a second agent serves as an evaluator, providing critical feedback against criteria. This feedback guides the generator through successive revisions, enabling iterative refinement. This approach trades increased interactions for a more polished & accurate final result.
AutoGen's GroupChat architecture is good for implementing this pattern because it can manage the conversational turns between the generator and evaluator agents. The GroupChatManager facilitates the dialogue, allowing the agents to exchange the evolving outputs and feedback.
Notebook: Code Generator with Evaluation Loop
We'll use a Code_Generator agent to write Python code from requirements, and a Code_Reviewer agent to assess it for correctness, style, and documentation. This iterative GroupChat process improves code quality through a generation and review loop.
How to evaluate: Ensure the evaluator provides specific, actionable feedback aligned with criteria (e.g., correctness, style, documentation)
Confirm that the generator incorporates feedback into meaningful revisions with each iteration
Track the number of iterations required to reach an acceptable or final version to assess efficiency
Watch for repetitive feedback loops, regressions, or ignored suggestions that signal breakdowns in the refinement process
Orchestration enables collaboration among multiple specialized agents, activating only the most relevant one based on the current subtask context. Instead of relying on a fixed sequence, agents dynamically participate depending on the state of the conversation.
Agent orchestrator workflows simplifies this routing pattern through a central orchestrator (GroupChatManager) that selectively delegates tasks to the appropriate agents. Each agent monitors the conversation but only contributes when their specific expertise is required.
Notebook: Trip Planner Orchestrator Agent
We will build a dynamic travel planning assistant. A GroupChatManager coordinates specialized agents to adapt to the user's evolving travel needs.
How to evaluate: Ensure the orchestrator activates only relevant agents based on the current context or user need.
(e.g., flights, hotels, local activities)
Confirm that agents contribute meaningfully and only when their domain expertise is required
Track the conversation flow to verify smooth handoffs and minimal overlap or redundancy among agents
Test with evolving and multi-intent queries to assess the orchestrator’s ability to adapt and reassign tasks dynamically
Parallelization is a powerful agent pattern where multiple tasks are run concurrently, significantly speeding up the overall process. Unlike purely sequential workflows, this approach is suitable when tasks are independent and can be processed simultaneously.
AutoGen doesn't have a built-in parallel execution manager, but its core agent capabilities integrate seamlessly with standard Python concurrency libraries. We can use these libraries to launch multiple agent interactions concurrently.
Notebook: Product Description Parallelization Agent We'll generate different components of a product description for a smartwatch (features, value proposition, target customer, tagline) by calling a marketing agent. At the end, results are synthesized together.
How to evaluate: Ensure each parallel agent call produces a distinct and relevant component (e.g., features, value proposition, target customer, tagline)
Confirm that all outputs are successfully collected and synthesized into a cohesive final product description
Track per-task runtime and total execution time to measure parallel speedup vs. sequential execution
Test with varying product types to assess generality and stability of the parallel workflow
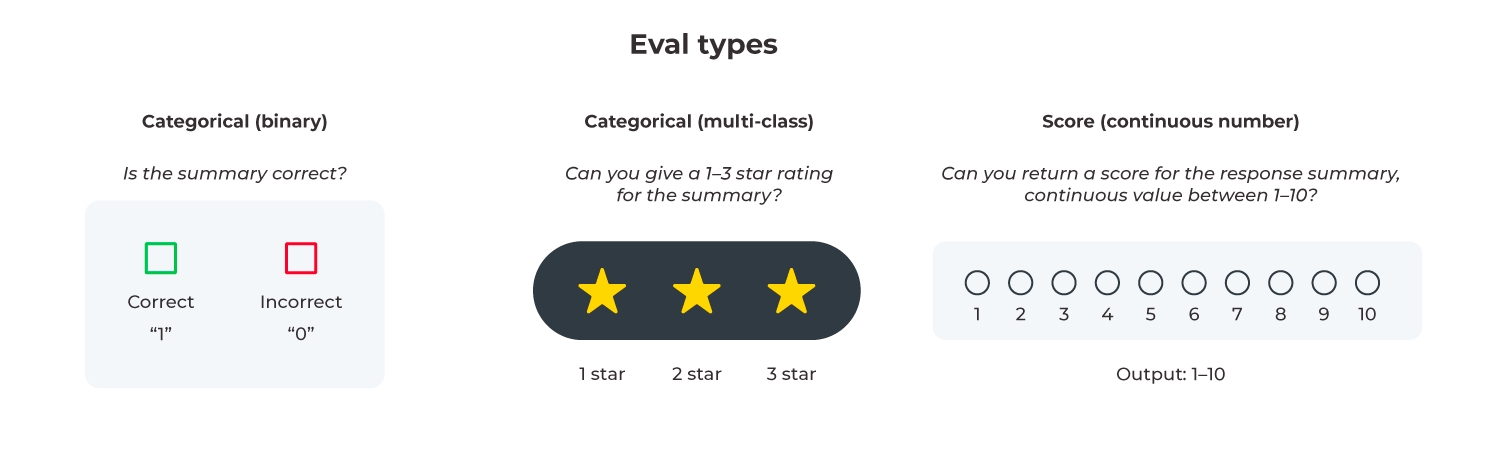
There are a multiple types of evaluations supported by the Phoenix Library. Each category of evaluation is categorized by its output type.
Categorical (binary) - The evaluation results in a binary output, such as true/false or yes/no, which can be easily represented as 1/0. This simplicity makes it straightforward for decision-making processes but lacks the ability to capture nuanced judgements.
Categorical (Multi-class) - The evaluation results in one of several predefined categories or classes, which could be text labels or distinct numbers representing different states or types.
Score - The evaluation results is a numeric value within a set range (e.g. 1-10), offering a scale of measurement.
Although score evals are an option in Phoenix, we recommend using categorical evaluations in production environments. LLMs often struggle with the subtleties of continuous scales, leading to inconsistent results even with slight prompt modifications or across different models. Repeated tests have shown that scores can fluctuate significantly, which is problematic when evaluating at scale.
Categorical evals, especially multi-class, strike a balance between simplicity and the ability to convey distinct evaluative outcomes, making them more suitable for applications where precise and consistent decision-making is important.
To explore the full analysis behind our recommendation and understand the limitations of score-based evaluations, check out our research on LLM eval data types.
It can be hard to understand in many cases why an LLM responds in a specific way. The explanation feature of Phoneix allows you to get a Eval output and an explanation from the LLM at the same time. We have found this incredibly useful for debugging LLM Evals.
from phoenix.evals import (
RAG_RELEVANCY_PROMPT_RAILS_MAP,
RAG_RELEVANCY_PROMPT_TEMPLATE,
OpenAIModel,
download_benchmark_dataset,
llm_classify,
)
model = OpenAIModel(
model_name="gpt-4",
temperature=0.0,
)
#The rails are used to hold the output to specific values based on the template
#It will remove text such as ",,," or "..."
#Will ensure the binary value expected from the template is returned
rails = list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values())
relevance_classifications = llm_classify(
dataframe=df,
template=RAG_RELEVANCY_PROMPT_TEMPLATE,
model=model,
rails=rails,
)
#relevance_classifications is a Dataframe with columns 'label' and 'explanation'The flag above can be set with any of the templates or your own custom templates. The example below is from a relevance Evaluation.
Retrieval Evals are designed to evaluate the effectiveness of retrieval systems. The retrieval systems typically return list of chunks of length k ordered by relevancy. The most common retrieval systems in the LLM ecosystem are vector DBs.
The retrieval Eval is designed to assess the relevance of each chunk and its ability to answer the question. More information on the Retrieval Eval can be found here
The picture above shows a single query returning chunks as a list. The retrieval Eval runs across each chunk returning a value of relevance in a list highlighting its relevance for the specific chunk. Phoenix provides helper functions that take in a dataframe, with query column that has lists of chunks and produces a column that is a list of equal length with an Eval for each chunk.
Use Phoenix to trace and evaluate different CrewAI agent patterns
is an open-source framework for building and orchestrating collaborative AI agents that act like a team of specialized virtual employees. Built on LangChain, it enables users to define roles, goals, and workflows for each agent, allowing them to work together autonomously on complex tasks with minimal setup.
Agents are autonomous, role-driven entities designed to perform specific functions—like a Researcher, Writer, or Support Rep. They can be richly customized with goals, backstories, verbosity settings, delegation permissions, and access to tools. This flexibility makes agents expressive and task-aware, helping model real-world team dynamics.
Tasks are the atomic units of work in CrewAI. Each task includes a description, expected output, responsible agent, and optional tools. Tasks can be executed solo or collaboratively, and they serve as the bridge between high-level goals and actionable steps.
Tools give agents capabilities beyond language generation—such as browsing the web, fetching documents, or performing calculations. Tools can be native or developer-defined using the BaseTool class, and each must have a clear name and purpose so agents can invoke them appropriately.Tools must include clear descriptions to help agents use them effectively.
CrewAI supports multiple orchestration strategies:
Sequential: Tasks run in a fixed order—simple and predictable.
Hierarchical: A manager agent or LLM delegates tasks dynamically, enabling top-down workflows.
Consensual (planned): Future support for democratic, collaborative task routing. Each process type shapes how coordination and delegation unfold within a crew.
A crew is a collection of agents and tasks governed by a defined process. It represents a fully operational unit with an execution strategy, internal collaboration logic, and control settings for verbosity and output formatting. Think of it as the operating system for multi-agent workflows.
Pipelines chain multiple crews together, enabling multi-phase workflows where the output of one crew becomes the input to the next. This allows developers to modularize complex applications into reusable, composable segments of logic.
With planning enabled, CrewAI generates a task-by-task strategy before execution using an AgentPlanner. This enriches each task with context and sequencing logic, improving coordination—especially in multi-step or loosely defined workflows.
Prompt chaining decomposes a complex task into a sequence of smaller steps, where each LLM call operates on the output of the previous one. This workflow introduces the ability to add programmatic checks (such as “gates”) between steps, validating intermediate outputs before continuing. The result is higher control, accuracy, and debuggability—at the cost of increased latency.
CrewAI makes it straightforward to build prompt chaining workflows using a sequential process. Each step is modeled as a Task, assigned to a specialized Agent, and executed in order using Process.sequential. You can insert validation logic between tasks or configure agents to flag issues before passing outputs forward.
Notebook: Research-to-Content Prompt Chaining Workflow
Routing is a pattern designed to classify incoming requests and dispatch them to the single most appropriate specialist agent or workflow, ensuring each input is handled by a focused, expert-driven routine.
In CrewAI, you implement routing by defining a Router Agent that inspects each input, emits a category label, and then dynamically delegates to downstream agents (or crews) tailored for that category—each equipped with its own tools and prompts. This separation of concerns delivers more accurate, maintainable pipelines.
Notebook: Research-Content Routing Workflow
Parallelization is a powerful agent workflow where multiple tasks are executed simultaneously, enabling faster and more scalable LLM pipelines. This pattern is particularly effective when tasks are independent and don’t depend on each other’s outputs.
While CrewAI does not enforce true multithreaded execution, it provides a clean and intuitive structure for defining parallel logic through multiple agents and tasks. These can be executed concurrently in terms of logic, and then gathered or synthesized by a downstream agent.
Notebook: Parallel Research Agent
The Orchestrator-Workers workflow centers around a primary agent—the orchestrator—that dynamically decomposes a complex task into smaller, more manageable subtasks. Rather than relying on a fixed structure or pre-defined subtasks, the orchestrator decides what needs to be done based on the input itself. It then delegates each piece to the most relevant worker agent, often specialized in a particular domain like research, content synthesis, or evaluation.
CrewAI supports this pattern using the Process.hierarchical setup, where the orchestrator (as the manager agent) generates follow-up task specifications at runtime. This enables dynamic delegation and coordination without requiring the workflow to be rigidly structured up front. It's especially useful for use cases like multi-step research, document generation, or problem-solving workflows where the best structure only emerges after understanding the initial query.
Notebook: Research & Writing Delegation Agents
The components behind tracing
In order for an application to emit traces for analysis, the application must be instrumented. Your application can be manually instrumented or be automatically instrumented. With phoenix, there a set of plugins (instrumentors) that can be added to your application's startup process that perform auto-instrumentation. These plugins collect spans for your application and export them for collection and visualization. For phoenix, all the instrumentors are managed via a single repository called . The comprehensive list of instrumentors can be found in the how-to guide.
An exporter takes the spans created via instrumentation and exports them to a collector. In simple terms, it just sends the data to the Phoenix. When using Phoenix, most of this is completely done under the hood when you call instrument on an instrumentor.
The Phoenix server is a collector and a UI that helps you troubleshoot your application in real time. When you run or run phoenix (e.x. px.launch_app(), container), Phoenix starts receiving spans from any application(s) that is exporting spans to it.
OpenTelemetry Protocol (or OTLP for short) is the means by which traces arrive from your application to the Phoenix collector. Phoenix currently supports OTLP over HTTP.
Evaluating tasks performed by LLMs can be difficult due to their complexity and the diverse criteria involved. Traditional methods like rule-based assessment or similarity metrics (e.g., ROUGE, BLEU) often fall short when applied to the nuanced and varied outputs of LLMs.
For instance, an AI assistant’s answer to a question can be:
not grounded in context
repetitive, repetitive, repetitive
grammatically incorrect
excessively lengthy and characterized by an overabundance of words
incoherent
The list of criteria goes on. And even if we had a limited list, each of these would be hard to measure
To overcome this challenge, the concept of "LLM as a Judge" employs an LLM to evaluate another's output, combining human-like assessment with machine efficiency.
Here’s the step-by-step process for using an LLM as a judge:
Identify Evaluation Criteria - First, determine what you want to evaluate, be it hallucination, toxicity, accuracy, or another characteristic. See our for examples of what can be assessed.
Craft Your Evaluation Prompt - Write a prompt template that will guide the evaluation. This template should clearly define what variables are needed from both the initial prompt and the LLM's response to effectively assess the output.
Select an Evaluation LLM - Choose the most suitable LLM from our available options for conducting your specific evaluations.
Generate Evaluations and View Results - Execute the evaluations across your data. This process allows for comprehensive testing without the need for manual annotation, enabling you to iterate quickly and refine your LLM's prompts.
Using an LLM as a judge significantly enhances the scalability and efficiency of the evaluation process. By employing this method, you can run thousands of evaluations across curated data without the need for human annotation.
This capability will not only speed up the iteration process for refining your LLM's prompts but will also ensure that you can deploy your models to production with confidence.
Arize is the company that makes Phoenix. Phoenix is an open source LLM observability tool offered by Arize. It can be access in its Cloud form online, or self-hosted and run on your own machine or server.
"Arize" can also refer to Arize's enterprise platform, often called Arize AX, available on arize.com. Arize AX is the enterprise SaaS version of Phoenix that comes with additional features like Copilot, ML and CV support, HIPAA compliance, Security Reviews, a customer success team, and more. See of the two tools.
With SageMaker notebooks, phoenix leverages the to host the server under proxy/6006.Note, that phoenix will automatically try to detect that you are running in SageMaker but you can declare the notebook runtime via a parameter to launch_app or an environment variable
Learn about options to migrate your legacy Phoenix Cloud instance to the latest version
To move to the new Phoenix Cloud, simply with a different email address. From there, you can start using a new Phoenix instance immediately. Your existing projects in your old (legacy) account will remain intact and independent, ensuring a clean transition.
Since most users don’t use Phoenix Cloud for data storage, this straightforward approach works seamlessly for migrating to the latest version.
If you need to migrate data from the legacy version to the latest version, .
The easiest way to determine which version of Phoenix Cloud you’re using is by checking the URL in your browser:
The new Phoenix Cloud version will have a hostname structure like: app.arize.phoenix.com/s/[your-space-name]
If your Phoenix Cloud URL does not include /s/ followed by your space name, you are on the legacy version.
import os
os.environ["PHOENIX_NOTEBOOK_ENV"] = "sagemaker"If you are working on an API whose endpoints perform RAG, but would like the phoenix server not to be launched as another thread.
You can do this by configuring the following the environment variable PHOENIX_COLLECTOR_ENDPOINT to point to the server running in a different process or container.
LlamaTrace and Phoenix Cloud are the same tool. They are the hosted version of Phoenix provided on app.phoenix.arize.com.
NOT_PARSABLE errors often occur when LLM responses exceed the max_tokens limit or produce incomplete JSON. Here's how to fix it:
Increase max_tokens: Update the model configuration as follows:
pythonCopy codellm_judge_model = OpenAIModel(
api_key=getpass("Enter your OpenAI API key..."),
model="gpt-4o-2024-08-06",
temperature=0.2,
max_tokens=1000, # Increase token limit
)Update Phoenix: Use version ≥0.17.4, which removes token limits for OpenAI and increases defaults for other APIs.
Check Logs: Look for finish_reason="length" to confirm token limits caused the issue.
If the above doesn't work, it's possible the llm-as-a-judge output might not fit into the defined rails for that particular custom Phoenix eval. Double check the prompt output matches the rail expectations.
If you want to contribute to the cutting edge of LLM and ML Observability, you've come to the right place!
To get started, please check out the following:
We encourage you to start with an issue labeled with the tag good first issue on theGitHub issue board, to get familiar with our codebase as a first-time contributor.
To submit your code, fork the Phoenix repository, create a new branch on your fork, and open a Pull Request (PR) once your work is ready for review.
In the PR template, please describe the change, including the motivation/context, test coverage, and any other relevant information. Please note if the PR is a breaking change or if it is related to an open GitHub issue.
A Core reviewer will review your PR in around one business day and provide feedback on any changes it requires to be approved. Once approved and all the tests pass, the reviewer will click the Squash and merge button in Github 🥳.
Your PR is now merged into Phoenix! We’ll shout out your contribution in the release notes.
Agent Roles
Explicit role configuration gives flexibility, but poor design can cause overlap or miscommunication
State Management
Stateless by default. Developers must implement external state or context passing for continuity across tasks
Task Planning
Supports sequential and branching workflows, but all logic must be manually defined—no built-in planning
Tool Usage
Agents support tools via config. No automatic selection; all tool-to-agent mappings are manual
Termination Logic
No auto-termination handling. Developers must define explicit conditions to break recursive or looping behavior
Memory
No built-in memory layer. Integration with vector stores or databases must be handled externally





Benchmarking Chunk Size, K and Retrieval Approach
The advent of LLMs is causing a rethinking of the possible architectures of retrieval systems that have been around for decades.
The core use case for RAG (Retrieval Augmented Generation) is the connecting of an LLM to private data, empower an LLM to know your data and respond based on the private data you fit into the context window.
As teams are setting up their retrieval systems understanding performance and configuring the parameters around RAG (type of retrieval, chunk size, and K) is currently a guessing game for most teams.
The above picture shows the a typical retrieval architecture designed for RAG, where there is a vector DB, LLM and an optional Framework.
This section will go through a script that iterates through all possible parameterizations of setting up a retrieval system and use Evals to understand the trade offs.
This overview will run through the scripts in Phoenix for performance analysis of RAG setup:
The scripts above power the included notebook.
The typical flow of retrieval is a user query is embedded and used to search a vector store for chunks of relevant data.
The core issue of retrieval performance: The chunks returned might or might not be able to answer your main question. They might be semantically similar but not usable to create an answer the question!
The eval template is used to evaluate the relevance of each chunk of data. The Eval asks the main question of "Does the chunk of data contain relevant information to answer the question"?
The Retrieval Eval is used to analyze the performance of each chunk within the ordered list retrieved.
The Evals generated on each chunk can then be used to generate more traditional search and retreival metrics for the retrieval system. We highly recommend that teams at least look at traditional search and retrieval metrics such as:
MRR
Precision @ K
NDCG
These metrics have been used for years to help judge how well your search and retrieval system is returning the right documents to your context window.
These metrics can be used overall, by cluster (UMAP), or on individual decisions, making them very powerful to track down problems from the simplest to the most complex.
Retrieval Evals just gives an idea of what and how much of the "right" data is fed into the context window of your RAG, it does not give an indication if the final answer was correct.
The Q&A Evals work to give a user an idea of whether the overall system answer was correct. This is typically what the system designer cares the most about and is one of the most important metrics.
The above Eval shows how the query, chunks and answer are used to create an overall assessment of the entire system.
The above Q&A Eval shows how the Query, Chunk and Answer are used to generate a % incorrect for production evaluations.
The results from the runs will be available in the directory.
Underneath experiment_data there are two sets of metrics:
The first set of results removes the cases where there are 0 retrieved relevant documents. There are cases where some clients test sets have a large number of questions where the documents can not answer. This can skew the metrics a lot.
The second set of results is unfiltered and shows the raw metrics for every retrieval.
The above picture shows the results of benchmark sweeps across your retrieval system setup. The lower the percent the better the results. This is the Q&A Eval.
The LLM Evals library is designed to support the building of any custom Eval templates.
Follow the following steps to easily build your own Eval with Phoenix
To do that, you must identify what is the metric best suited for your use case. Can you use a pre-existing template or do you need to evaluate something unique to your use case?
Then, you need the golden dataset. This should be representative of the type of data you expect the LLM eval to see. The golden dataset should have the “ground truth” label so that we can measure performance of the LLM eval template. Often such labels come from human feedback.
Building such a dataset is laborious, but you can often find a standardized one for the most common use cases (as we did in the code above)
The Eval inferences are designed or easy benchmarking and pre-set downloadable test inferences. The inferences are pre-tested, many are hand crafted and designed for testing specific Eval tasks.
Then you need to decide which LLM you want to use for evaluation. This could be a different LLM from the one you are using for your application. For example, you may be using Llama for your application and GPT-4 for your eval. Often this choice is influenced by questions of cost and accuracy.
Now comes the core component that we are trying to benchmark and improve: the eval template.
You can adjust an existing template or build your own from scratch.
Be explicit about the following:
What is the input? In our example, it is the documents/context that was retrieved and the query from the user.
What are we asking? In our example, we’re asking the LLM to tell us if the document was relevant to the query
What are the possible output formats? In our example, it is binary relevant/irrelevant, but it can also be multi-class (e.g., fully relevant, partially relevant, not relevant).
In order to create a new template all that is needed is the setting of the input string to the Eval function.
The above template shows an example creation of an easy to use string template. The Phoenix Eval templates support both strings and objects.
The above example shows a use of the custom created template on the df dataframe.
You now need to run the eval across your golden dataset. Then you can generate metrics (overall accuracy, precision, recall, F1, etc.) to determine the benchmark. It is important to look at more than just overall accuracy. We’ll discuss that below in more detail.
Yes, you can use either of the two methods below.
Install pyngrok on the remote machine using the command pip install pyngrok.
on ngrok and verify your email. Find 'Your Authtoken' on the .
In jupyter notebook, after launching phoenix set its port number as the port parameter in the code below. Preferably use a default port for phoenix so that you won't have to set up ngrok tunnel every time for a new port, simply restarting phoenix will work on the same ngrok URL.
"Visit Site" using the newly printed public_url and ignore warnings, if any.
Ngrok free account does not allow more than 3 tunnels over a single ngrok agent session. Tackle this error by checking active URL tunnels using ngrok.get_tunnels() and close the required URL tunnel using ngrok.disconnect(public_url).
This assumes you have already set up ssh on both the local machine and the remote server.
If you are accessing a remote jupyter notebook from a local machine, you can also access the phoenix app by forwarding a local port to the remote server via ssh. In this particular case of using phoenix on a remote server, it is recommended that you use a default port for launching phoenix, say DEFAULT_PHOENIX_PORT.
Launch the phoenix app from jupyter notebook.
In a new terminal or command prompt, forward a local port of your choice from 49152 to 65535 (say 52362) using the command below. Remote user of the remote host must have sufficient port-forwarding/admin privileges.
If successful, visit to access phoenix locally.
If you are abruptly unable to access phoenix, check whether the ssh connection is still alive by inspecting the terminal. You can also try increasing the ssh timeout settings.
Simply run exit in the terminal/command prompt where you ran the port forwarding command.
There are two endpoints that matter in Phoenix:
Application Endpoint: The endpoint your Phoenix instance is running on
OTEL Tracing Endpoint: The endpoint through which your Phoenix instance receives OpenTelemetry traces
If you're accessing a Phoenix Cloud instance through our website, then your endpoint is available under the Hostname field of your Settings page.
If you're self-hosting Phoenix, then you choose the endpoint when you set up the app. The default value is http://localhost:6006
To set this endpoint, use the PHOENIX_COLLECTOR_ENDPOINT environment variable. This is used by the Phoenix client package to query traces, log annotations, and retrieve prompts.
If you're accessing a Phoenix Cloud instance through our website, then your endpoint is available under the Hostname field of your Settings page.
If you're self-hosting Phoenix, then you choose the endpoint when you set up the app. The default values are:
Using the GRPC protocol: http://localhost:6006/v1/traces
Using the HTTP protocol: http://localhost:4317
To set this endpoint, use the register(endpoint=YOUR ENDPOINT) function. This endpoint can also be set using environment variables. For more on the register function and other configuration options, .
import getpass
from pyngrok import ngrok, conf
print("Enter your authtoken, which can be copied from https://dashboard.ngrok.com/auth")
conf.get_default().auth_token = getpass.getpass()
port = 37689
# Open a ngrok tunnel to the HTTP server
public_url = ngrok.connect(port).public_url
print(" * ngrok tunnel \"{}\" -> \"http://127.0.0.1:{}\"".format(public_url, port))ssh -L 52362:localhost:<DEFAULT_PHOENIX_PORT> <REMOTE_USER>@<REMOTE_HOST>Evaluating multi-agent systems involves unique challenges compared to single-agent evaluations. This guide provides clear explanations of various architectures, strategies for effective evaluation, and additional considerations.
A multi-agent system consists of multiple agents, each using an LLM (Large Language Model) to control application flows. As systems grow, you may encounter challenges such as agents struggling with too many tools, overly complex contexts, or the need for specialized domain knowledge (e.g., planning, research, mathematics). Breaking down applications into multiple smaller, specialized agents often resolves these issues.
Modularity: Easier to develop, test, and maintain.
Specialization: Expert agents handle specific domains.
Control: Explicit control over agent communication.
Multi-agent systems can connect agents in several ways:
Network
Agents can communicate freely with each other, each deciding independently whom to contact next.
Assess communication efficiency, decision quality on agent selection, and coordination complexity.
Supervisor
Agents communicate exclusively with a single supervisor that makes all routing decisions.
Evaluate supervisor decision accuracy, efficiency of routing, and effectiveness in task management.
Supervisor (Tool-calling)
Supervisor uses an LLM to invoke agents represented as tools, making explicit tool calls with arguments.
Evaluate tool-calling accuracy, appropriateness of arguments passed, and supervisor decision quality.
Hierarchical
Systems with supervisors of supervisors, allowing complex, structured flows.
Evaluate communication efficiency, decision-making at each hierarchical level, and overall system coherence.
Custom Workflow
Agents communicate within predetermined subsets, combining deterministic and agent-driven decisions.
Evaluate workflow efficiency, clarity of communication paths, and effectiveness of the predetermined control flow.
There are a few different strategies for evaluating multi agent applications.
1. Agent Handoff Evaluation
When tasks transfer between agents, evaluate:
Appropriateness: Is the timing logical?
Information Transfer: Was context transferred effectively?
Timing: Optimal handoff moment.
2. System-Level Evaluation
Measure holistic performance:
End-to-End Task Completion
Efficiency: Number of interactions, processing speed
User Experience
3. Coordination Evaluation
Evaluate cooperative effectiveness:
Communication Quality
Conflict Resolution
Resource Management
Multi-agent systems introduce added complexity:
Complexity Management: Evaluate agents individually, in pairs, and system-wide.
Emergent Behaviors: Monitor for collective intelligence and unexpected interactions.
Evaluation Granularity:
Agent-level: Individual performance
Interaction-level: Agent interactions
System-level: Overall performance
User-level: End-user experience
Performance Metrics: Latency, throughput, scalability, reliability, operational cost
Adapt single-agent evaluation methods like tool-calling evaluations and planning assessments.
See our guide on agent evals and use our pre-built evals that you can leverage in Phoenix.
Focus evaluations on coordination efficiency, overall system efficiency, and emergent behaviors.
See our docs for creating your own custom evals in Phoenix.
Structure evaluations to match architecture:
Bottom-Up: From individual agents upward.
Top-Down: From system goals downward.
Hybrid: Combination for comprehensive coverage.
from phoenix.evals import download_benchmark_dataset
df = download_benchmark_dataset(
task="binary-hallucination-classification", dataset_name="halueval_qa_data"
)
df.head()MY_CUSTOM_TEMPLATE = '''
You are evaluating the positivity or negativity of the responses to questions.
[BEGIN DATA]
************
[Question]: {question}
************
[Response]: {response}
[END DATA]
Please focus on the tone of the response.
Your answer must be single word, either "positive" or "negative"
'''model = OpenAIModel(model_name="gpt-4",temperature=0.6)
positive_eval = llm_classify(
dataframe=df,
template= MY_CUSTOM_TEMPLATE,
model=model
)#Phoenix Evals support using either strings or objects as templates
MY_CUSTOM_TEMPLATE = " ..."
MY_CUSTOM_TEMPLATE = PromptTemplate("This is a test {prompt}")Prompts often times refer to the content of how you "prompt" a LLM, e.g. the "text" that you send to a model like OpenAI's gpt-4. Within Phoenix we expand this definition to be everything that's needed to prompt:
The prompt template of the messages to send to a completion endpoint
The invocation parameters (temperature, frequency penalty, etc.)
The tools made accessible to the LLM (e.g. weather API)
The response format (sometimes called the output schema) used for when you have JSON mode enabled.
This expanded definition of a prompt lets you more deterministically invoke LLMs with confidence as everything is snapshotted for you to use within your application.
Although the terms prompt and prompt template get used interchangeably, it's important to know the difference.
Prompts refer to the message(s) that are passed into the language model.
Prompt Templates refer to a way of formatting information to get the prompt to hold the information you want (such as context and examples). Prompt templates can include placeholders (variables) for things such as examples (e.g. few-shot), outside context (RAG), or any other external data that is needed.
Every time you save a prompt within Phoenix, a snapshot of the prompt is saved as a prompt version. Phoenix does this so that you not only can view the changes to a prompt over time but also so that you can build confidence about a specific prompt version before using it within your application. With every prompt version phoenix tracks the author of the prompt and the date at which the version was saved.
Similar to the way in which you can track changes to your code via git shas, Phoenix tracks each change to your prompt with a prompt_id.
Imagine you’re working on a AI project, and you want to label specific versions of your prompts so you can control when and where they get deployed. This is where prompt version tags come in.
A prompt version tag is like a sticky note you put on a specific version of your prompt to mark it as important. Once tagged, that version won’t change, making it easy to reference later.
When building applications, different environments are often used for different stages of readiness before going live, for example:
Development – Where new features are built.
Staging – Where testing happens.
Production – The live system that users interact with.
Tagging prompt versions with environment tags can enable building, testing, and deploying prompts in the same way as an application—ensuring that prompt changes can be systematically tested and deployed.
In addition to environment tags, custom Git tags allow teams to label code versions in a way that fits their specific workflow (`v0.0.1`). These tags can be used to signal different stages of deployment, feature readiness, or any other meaningful status.
Prompt version tags work exactly the same way as git tags.
Prompts can be formatted to include any attributes from spans or datasets. These attributes can be added as F-Strings or using Mustache formatting.
F-strings should be formatted with single {s:
{question}{% hint style="info" %} To escape a { when using F-string, add a second { in front of it, e.g., {{escaped}} {not-escaped}. Escaping variables will remove them from inputs in the Playground. {% endhint %}
Mustache should be formatted with double {{s:
{{question}}{% hint style="info" %} We recommend using Mustache where possible, since it supports nested attributes, e.g. attributes.input.value, more seamlessly {% endhint %}
Tools allow LLMs to interact with the external environment. This can allow LLMs to interface with your application in more controlled ways. Given a prompt and some tools to choose from an LLM may choose to use some (or one) tools or not. Many LLM API's also expose a tool choice parameter which allow you to constrain how and which tools are selected.
Here is an example of what a tool would look like for the weather API using OpenAI.
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
},
"required": ["location"],
}
}
}Some LLMs support structured responses, known as response format or output schema, allowing you to specify an exact schema for the model’s output.
Structured Outputs ensure the model consistently generates responses that adhere to a defined JSON Schema, preventing issues like missing keys or invalid values.
Reliable type-safety: Eliminates the need to validate or retry incorrectly formatted responses.
Explicit refusals: Enables programmatic detection of safety-based refusals.
Simpler prompting: Reduces reliance on strongly worded prompts for consistent formatting.
For more details, check out this OpenAI guide.
Use Phoenix to trace and evaluate agent frameworks built using Langgraph
This guide explains key LangGraph concepts, discusses design considerations, and walks through common architectural patterns like orchestrator-worker, evaluators, and routing. Each pattern includes a brief explanation and links to runnable Python notebooks.
LangGraph allows you to build LLM-powered applications using a graph of steps (called "nodes") and data (called "state"). Here's what you need to know to understand and customize LangGraph workflows:
A TypedDict that stores all information passed between nodes. Think of it as the memory of your workflow. Each node can read from and write to the state.
Nodes are units of computation. Most often these are functions that accept a State input and return a partial update to it. Nodes can do anything: call LLMs, trigger tools, perform calculations, or prompt users.
Directed connections that define the order in which nodes are called. LangGraph supports linear, conditional, and cyclical edges, which allows for building loops, branches, and recovery flows.
A Python function that examines the current state and returns the name of the next node to call. This allows your application to respond dynamically to LLM outputs, tool results, or even human input.
A way to dynamically launch multiple workers (nodes or subgraphs) in parallel, each with their own state. Often used in orchestrator-worker patterns where the orchestrator doesn't know how many tasks there will be ahead of time.
LangGraph enables complex multi-agent orchestration using a Supervisor node that decides how to delegate tasks among a team of agents. Each agent can have its own tools, prompt structure, and output format. The Supervisor coordinates routing, manages retries, and ensures loop control.
LangGraph supports built-in persistence using checkpointing. Each execution step saves state to a database (in-memory, SQLite, or Postgres). This allows for:
Multi-turn conversations (memory)
Rewinding to past checkpoints (time travel)
Human-in-the-loop workflows (pause + resume)
LangGraph improves on LangChain by supporting more flexible and complex workflows. Here’s what to keep in mind when designing:
A linear sequence of prompt steps, where the output of one becomes the input to the next. This workflow is optimal when the task can be simply broken down into concrete subtasks.
Use case: Multistep reasoning, query rewriting, or building up answers gradually.
📓
Runs multiple LLMs in parallel — either by splitting tasks (sectioning) or getting multiple opinions (voting).
Use case: Combining diverse outputs, evaluating models from different angles, or running safety checks.
With the Send API, LangGraph lets you:
Launch multiple safety evaluators in parallel
Compare multiple generated hypotheses side-by-side
Run multi-agent voting workflows
This improves reliability and reduces bottlenecks in linear pipelines.
📓
Routes an input to the most appropriate follow-up node based on its type or intent.
Use case: Customer support bots, intent classification, or model selection.
LangGraph routers enable domain-specific delegation — e.g., classify an incoming query as "billing", "technical support", or "FAQ", and send it to a specialized sub-agent. Each route can have its own tools, memory, and context. Use structured output with a routing schema to make classification more reliable.
📓
One LLM generates content, another LLM evaluates it, and the loop repeats until the evaluation passes. LangGraph allows feedback to modify the state, making each round better than the last.
Use case: Improving code, jokes, summaries, or any generative output with measurable quality.
📓
An orchestrator node dynamically plans subtasks and delegates each to a worker LLM. Results are then combined into a final output.
Use case: Writing research papers, refactoring code, or composing modular documents.
LangGraph’s Send API lets the orchestrator fork off tasks (e.g., subsections of a paper) and gather them into completed_sections. This is especially useful when the number of subtasks isn’t known in advance.
You can also incorporate agents like PDF_Reader or a WebSearcher, and the orchestrator can choose when to route to these workers.
⚠️ Caution: Feedback loops or improper edge handling can cause workers to echo each other or create infinite loops. Use strict conditional routing to avoid this.
📓
SmolAgents is a lightweight Python library for composing tool-using, task-oriented agents. This guide outlines common agent workflows we've implemented—covering routing, evaluation loops, task orchestration, and parallel execution. For each pattern, we include an overview, a reference notebook, and guidance on how to evaluate agent quality.
While the API is minimal—centered on Agent, Task, and Tool—there are important tradeoffs and design constraints to be aware of.
This workflow breaks a task into smaller steps, where the output of one agent becomes the input to another. It’s useful when a single prompt can’t reliably handle the full complexity or when you want clarity in intermediate reasoning.
Notebook: The agent first extracts keywords from a resume, then summarizes what those keywords suggest.
How to evaluate: Check whether each step performs its function correctly and whether the final result meaningfully depends on the intermediate output (e.g., do summaries reflect the extracted keywords?)
Check if the intermediate step (e.g. keyword extraction) is meaningful and accurate
Ensure the final output reflects or builds on the intermediate output
Compare chained vs. single-step prompting to see if chaining improves quality or structure
Routing is used to send inputs to the appropriate downstream agent or workflow based on their content. The routing logic is handled by a dedicated agent, often using lightweight classification.
Notebook: The agent classifies candidate profiles into Software, Product, or Design categories, then hands them off to the appropriate evaluation pipeline.
How to evaluate: Compare the routing decision to human judgment or labeled examples (e.g., did the router choose the right department for a given candidate?)
Compare routing decisions to human-labeled ground truth or expectations
Track precision/recall if framed as a classification task
Monitor for edge cases and routing errors (e.g., ambiguous or mixed-signal profiles)
This pattern uses two agents in a loop: one generates a solution, the other critiques it. The generator revises until the evaluator accepts the result or a retry limit is reached. It’s useful when quality varies across generations.
Notebook: An agent writes a candidate rejection email. If the evaluator agent finds the tone or feedback lacking, it asks for a revision.
How to evaluate: Track how many iterations are needed to converge and whether final outputs meet predefined criteria (e.g., is the message respectful, clear, and specific?)
Measure how many iterations are needed to reach an acceptable result
Evaluate final output quality against criteria like tone, clarity, and specificity
Compare the evaluator’s judgment to human reviewers to calibrate reliability
In this approach, a central agent coordinates multiple agents, each with a specialized role. It’s helpful when tasks can be broken down and assigned to domain-specific workers.
Notebook: The orchestrator delegates resume review, culture fit assessment, and decision-making to different agents, then composes a final recommendation.
How to evaluate: Assess consistency between subtasks and whether the final output reflects the combined evaluations (e.g., does the final recommendation align with the inputs from each worker agent?)
Ensure each worker agent completes its role accurately and in isolation
Check if the orchestrator integrates worker outputs into a consistent final result
Look for agreement or contradictions between components (e.g., technical fit vs. recommendation)
When you need to process many inputs using the same logic, parallel execution improves speed and resource efficiency. Agents can be launched concurrently without changing their individual behavior.
Notebook:
Candidate reviews are distributed using asyncio, enabling faster batch processing without compromising output quality.
How to evaluate: Ensure results remain consistent with sequential runs and monitor for improvements in latency and throughput (e.g., are profiles processed correctly and faster when run in parallel?)
Confirm that outputs are consistent with those from a sequential execution
Track total latency and per-task runtime to assess parallel speedup
Watch for race conditions, dropped inputs, or silent failures in concurrency
To log traces, you must instrument your application either manually or automatically. To log to a remote instance of Phoenix, you must also configure the host and port where your traces will be sent.
When running Phoenix locally on the default port of 6006, no additional configuration is necessary.
If you are running a remote instance of Phoenix, you can configure your instrumentation to log to that instance using the PHOENIX_HOST and PHOENIX_PORT environment variables.
Alternatively, you can use the PHOENIX_COLLECTOR_ENDPOINT environment variable.
Tracing can be paused temporarily or disabled permanently.
Pause tracing using context manager
If there is a section of your code for which tracing is not desired, e.g. the document chunking process, it can be put inside the suppress_tracing context manager as shown below.
Uninstrument the auto-instrumentors permanently
Calling .uninstrument() on the auto-instrumentors will remove tracing permanently. Below is the examples for LangChain, LlamaIndex and OpenAI, respectively.
To get token counts when streaming, install openai>=1.26 and set stream_options={"include_usage": True} when calling create. Below is an example Python code snippet. For more info, see .
If you have customized a LangChain component (say a retriever), you might not get tracing for that component without some additional steps. Internally, instrumentation relies on components to inherit from LangChain base classes for the traces to show up. Below is an example of how to inherit from LanChain base classes to make a and to make traces show up.
Phoenix offers key modules to measure the quality of generated results as well as modules to measure retrieval quality.
Response Evaluation: Does the response match the retrieved context? Does it also match the query?
Retrieval Evaluation: Are the retrieved sources relevant to the query?
Evaluation of generated results can be challenging. Unlike traditional ML, the predicted results are not numeric or categorical, making it hard to define quantitative metrics for this problem.
Phoenix offers , a module designed to measure the quality of results. This module uses a "gold" LLM (e.g. GPT-4) to decide whether the generated answer is correct in a variety of ways. Note that many of these evaluation criteria DO NOT require ground-truth labels. Evaluation can be done simply with a combination of the input (query), output (response), and context.
LLM Evals supports the following response evaluation criteria:
QA Correctness - Whether a question was correctly answered by the system based on the retrieved data. In contrast to retrieval Evals that are checks on chunks of data returned, this check is a system level check of a correct Q&A.
Hallucinations - Designed to detect LLM hallucinations relative to retrieved context
Toxicity - Identify if the AI response is racist, biased, or toxic
Response evaluations are a critical first step to figuring out whether your LLM App is running correctly. Response evaluations can pinpoint specific executions (a.k.a. traces) that are performing badly and can be aggregated up so that you can track how your application is running as a whole.
Phoenix also provides evaluation of retrieval independently.
The concept of retrieval evaluation is not new; given a set of relevance scores for a set of retrieved documents, we can evaluate retrievers using retrieval metrics like precision, NDCG, hit rate and more.
LLM Evals supports the following retrieval evaluation criteria:
Relevance - Evaluates whether a retrieved document chunk contains an answer to the query.
Retrieval is possibly the most important step in any LLM application as poor and/or incorrect retrieval can be the cause of bad response generation. If your application uses RAG to power an LLM, retrieval evals can help you identify the cause of hallucinations and incorrect answers.
With Phoenix's LLM Evals, evaluation results (or just Evaluations for short) is data consisting of 3 main columns:
label: str [optional] - a classification label for the evaluation (e.g. "hallucinated" vs "factual"). Can be used to calculate percentages (e.g. percent hallucinated) and can be used to filter down your data (e.g. Evals["Hallucinations"].label == "hallucinated")
score: number [optional] - a numeric score for the evaluation (e.g. 1 for good, 0 for bad). Scores are great way to sort your data to surface poorly performing examples and can be used to filter your data by a threshold.
explanation: str [optional] - the reasoning for why the evaluation label or score was given. In the case of LLM evals, this is the evaluation model's reasoning. While explanations are optional, they can be extremely useful when trying to understand problematic areas of your application.
Let's take a look at an example list of Q&A relevance evaluations:
These three columns combined can drive any type of evaluation you can imagine. label provides a way to classify responses, score provides a way to assign a numeric assessment, and explanation gives you a way to get qualitative feedback.
With Phoenix, evaluations can be "attached" to the spans and documents collected. In order to facilitate this, Phoenix supports the following steps.
Querying and downloading data - query the spans collected by phoenix and materialize them into DataFrames to be used for evaluation (e.g. question and answer data, documents data).
Running Evaluations - the data queried in step 1 can be fed into LLM Evals to produce evaluation results.
Logging Evaluations - the evaluations performed in the above step can be logged back to Phoenix to be attached to spans and documents for evaluating responses and retrieval. See here on how to log evaluations to Phoenix.
Sorting and Filtering by Evaluation - once the evaluations have been logged back to Phoenix, the spans become instantly sortable and filterable by the evaluation values that you attached to the spans. (An example of an evaluation filter would be Eval["hallucination"].label == "hallucinated")
By following the above steps, you will have a full end-to-end flow for troubleshooting, evaluating, and root-causing an LLM application. By using LLM Evals in conjunction with Traces, you will be able to surface up problematic queries, get an explanation as to why the generation is problematic (e.g. hallucinated because ...), and be able to identify which step of your generative app requires improvement (e.g. did the LLM hallucinate or was the LLM fed bad context?).
For a full tutorial on LLM Ops, check out our tutorial below.
Possibly the most common use-case for creating a LLM application is to connect an LLM to proprietary data such as enterprise documents or video transcriptions. Applications such as these often times are built on top of LLM frameworks such as or , which have first-class support for vector store retrievers. Vector Stores enable teams to connect their own data to LLMs. A common application is chatbots looking across a company's knowledge base/context to answer specific questions.
There are varying degrees of how we can evaluate retrieval systems.
Step 1: First we care if the chatbot is correctly answering the user's questions. Are there certain types of questions the chatbot gets wrong more often?
Step 2: Once we know there's an issue, then we need metrics to trace where specifically did it go wrong. Is the issue with retrieval? Are the documents that the system retrieves irrelevant?
Step 3: If retrieval is not the issue, we should check if we even have the right documents to answer the question.
Visualize the chain of the traces and spans for a Q&A chatbot use case. You can click into specific spans.
When clicking into the retrieval span, you can see the relevance score for each document. This can surface irrelevant context.
Phoenix surfaces up clusters of similar queries that have poor feedback.
Phoenix can help uncover when irrelevant context is being retrieved using the LLM Evals for Relevance. You can look at a cluster's aggregate relevance metric with precision @k, NDCG, MRR, etc to identify where to improve. You can also look at a single prompt/response pair and see the relevance of documents.
Phoenix can help you identify if there is context that is missing from your knowledge base. By visualizing query density, you can understand what topics you need to add additional documentation for in order to improve your chatbots responses.
By setting the "primary" dataset as the user queries, and the "corpus" dataset as the context I have in my vector store, I can see if there are clusters of user query embeddings that have no nearby context embeddings, as seen in the example below.
Found a problematic cluster you want to dig into, but don't want to manually sift through all of the prompts and responses? Ask chatGPT to help you understand the make up of the cluster. .
Looking for code to get started? Go to our Quickstart guide for Search and Retrieval.
Cyclic workflows: LangGraph supports loops, retries, and iterative workflows that would be cumbersome in LangChain.
Debugging complexity: Deep graphs and multi-agent networks can be difficult to trace. Use Arize AX or Phoenix!
Fine-grained control: Customize prompts, tools, state updates, and edge logic for each node.
Token bloat: Cycles and retries can accumulate state and inflate token usage.
Visualize: Graph visualization makes it easier to follow logic flows and complex routing.
Requires upfront design: Graphs must be statically defined before execution. No dynamic graph construction mid-run.
Supports multi-agent coordination: Easily create agent networks with Supervisor and worker roles.
Supervisor misrouting: If not carefully designed, supervisors may loop unnecessarily or reroute outputs to the wrong agent.





from phoenix.trace import suppress_tracing
with suppress_tracing():
# Code running inside this block doesn't generate traces.
# For example, running LLM evals here won't generate additional traces.
...
# Tracing will resume outside the block.
...LangChainInstrumentor().uninstrument()
LlamaIndexInstrumentor().uninstrument()
OpenAIInstrumentor().uninstrument()
# etc.response = openai.OpenAI().chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Write a haiku."}],
max_tokens=20,
stream=True,
stream_options={"include_usage": True},
)from typing import List
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.retrievers import BaseRetriever, Document
from openinference.instrumentation.langchain import LangChainInstrumentor
from opentelemetry import trace as trace_api
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk import trace as trace_sdk
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
PHOENIX_COLLECTOR_ENDPOINT = "http://127.0.0.1:6006/v1/traces"
tracer_provider = trace_sdk.TracerProvider()
trace_api.set_tracer_provider(tracer_provider)
tracer_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter(endpoint)))
LangChainInstrumentor().instrument()
class CustomRetriever(BaseRetriever):
"""
This example is taken from langchain docs.
https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/custom_retriever/
A custom retriever that contains the top k documents that contain the user query.
This retriever only implements the sync method _get_relevant_documents.
If the retriever were to involve file access or network access, it could benefit
from a native async implementation of `_aget_relevant_documents`.
As usual, with Runnables, there's a default async implementation that's provided
that delegates to the sync implementation running on another thread.
"""
k: int
"""Number of top results to return"""
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
"""Sync implementations for retriever."""
matching_documents: List[Document] = []
# Custom logic to find the top k documents that contain the query
for index in range(self.k):
matching_documents.append(Document(page_content=f"dummy content at {index}", score=1.0))
return matching_documents
retriever = CustomRetriever(k=3)
if __name__ == "__main__":
documents = retriever.invoke("what is the meaning of life?")import phoenix as px
from phoenix.trace import LangChainInstrumentor
px.launch_app()
LangChainInstrumentor().instrument()
# run your LangChain applicationimport os
from phoenix.trace import LangChainInstrumentor
# assume phoenix is running at 162.159.135.42:6007
os.environ["PHOENIX_HOST"] = "162.159.135.42"
os.environ["PHOENIX_PORT"] = "6007"
LangChainInstrumentor().instrument() # logs to http://162.159.135.42:6007
# run your LangChain applicationimport os
from phoenix.trace import LangChainInstrumentor
# assume phoenix is running at 162.159.135.42:6007
os.environ["PHOENIX_COLLECTOR_ENDPOINT"] = "162.159.135.42:6007"
LangChainInstrumentor().instrument() # logs to http://162.159.135.42:6007
# run your LangChain applicationDatasets are integral to evaluation and experimentation. They are collections of examples that provide the inputs and, optionally, expected reference outputs for assessing your application. Each example within a dataset represents a single data point, consisting of an inputs dictionary, an optional output dictionary, and an optional metadata dictionary. The optional output dictionary often contains the the expected LLM application output for the given input.
Datasets allow you to collect data from production, staging, evaluations, and even manually. The examples collected are then used to run experiments and evaluations to track improvements.
Use datasets to:
Store evaluation test cases for your eval script instead of managing large JSONL or CSV files
Capture generations to assess quality manually or using LLM-graded evals
Store user reviewed generations to find new test cases
With Phoenix, datasets are:
Integrated. Datasets are integrated with the platform, so you can add production spans to datasets, use datasets to run experiments, and use metadata to track different segments and use-cases.
Versioned. Every insert, update, and delete is versioned, so you can pin experiments and evaluations to a specific version of a dataset and track changes over time.
There are various ways to get started with datasets:
Manually Curated Examples
This is how we recommend you start. From building your application, you probably have an idea of what types of inputs you expect your application to be able to handle, and what "good" responses look like. You probably want to cover a few different common edge cases or situations you can imagine. Even 20 high quality, manually curated examples can go a long way.
Historical Logs
Once you ship an application, you start gleaning valuable information: how users are actually using it. This information can be valuable to capture and store in datasets. This allows you to test against specific use cases as you iterate on your application.
If your application is going well, you will likely get a lot of usage. How can you determine which datapoints are valuable to add? There are a few heuristics you can follow. If possible, try to collect end user feedback. You can then see which datapoints got negative feedback. That is super valuable! These are spots where your application did not perform well. You should add these to your dataset to test against in the future. You can also use other heuristics to identify interesting datapoints - for example, runs that took a long time to complete could be interesting to analyze and add to a dataset.
Synthetic Data
Once you have a few examples, you can try to artificially generate examples to get a lot of datapoints quickly. It's generally advised to have a few good handcrafted examples before this step, as the synthetic data will often resemble the source examples in some way.
While Phoenix doesn't have dataset types, conceptually you can contain:
Key-Value Pairs:
Inputs and outputs are arbitrary key-value pairs.
This dataset type is ideal for evaluating prompts, functions, and agents that require multiple inputs or generate multiple outputs.
If you have a RAG prompt template such as:
Given the context information and not prior knowledge, answer the query.
---------------------
{context}
---------------------
Query: {query}
Answer: Your dataset might look like:
{
"query": "What is Paul Graham known for?",
"context": "Paul Graham is an investor, entrepreneur, and computer scientist known for..."
}
{
"answer": "Paul Graham is known for co-founding Y Combinator, for his writing, and for his work on the Lisp programming language." }
LLM inputs and outputs:
Simply capture the input and output as a single string to test the completion of an LLM.
The "inputs" dictionary contains a single "input" key mapped to the prompt string.
The "outputs" dictionary contains a single "output" key mapped to the corresponding response string.
{
"input": "do you have to have two license plates in ontario" }
{
"output": "true"
}
{
"input": "are black beans the same as turtle beans" }
{ "output": "true" }
Messages or chat:
This type of dataset is designed for evaluating LLM structured messages as inputs and outputs.
The "inputs" dictionary contains a "messages" key mapped to a list of serialized chat messages.
The "outputs" dictionary contains a "messages" key mapped to a list of serialized chat messages.
This type of data is useful for evaluating conversational AI systems or chatbots.
{ "messages": [{ "role": "system", "content": "You are an expert SQL..."}] }
{ "messages": [{ "role": "assistant", "content": "select * from users"}] }
{ "messages": [{ "role": "system", "content": "You are a helpful..."}] }
{ "messages": [{ "role": "assistant", "content": "I don't know the answer to that"}] }
Depending on the type of contents of a given dataset, you might consider the dataset be a certain type.
A dataset that contains the inputs and the ideal "golden" output is often times is referred to as a Golden Dataset. These datasets are hand-labeled dataset and are used in evaluating the performance of LLMs or prompt templates. T.A golden dataset could look something like
Paris is the capital of France
True
Canada borders the United States
True
The native language of Japan is English
False
API centered on Agent, Task, and Tool
Tools are just Python functions decorated with @tool. There’s no centralized registry or schema enforcement, so developers must define conventions and structure on their own.
Provides flexibility for orchestration
No retry mechanism or built-in workflow engine
Supports evaluator-optimizer loops, routing, and fan-out/fan-in
Agents are composed, not built-in abstractions
Must implement orchestration logic
Multi-Agent support
No built-in support for collaboration structures like voting, planning, or debate.
Token-level streaming is not supported
No state or memory management out of the box. Applications that require persistent state—such as conversations or multi-turn workflows—will need to integrate external storage (e.g., a vector database or key-value store).
There’s no native memory or “trajectory” tracking between agents. Handoffs between tasks are manual. This is workable in small systems, but may require structure in more complex workflows.
correct
The reference text explains that YC was not or...
1
correct
To determine if the answer is correct, we need...
1
incorrect
To determine if the answer is correct, we must...
0
correct
To determine if the answer is correct, we need...
1
Is this a bad response to the answer?
User feedback or LLM Eval for Q&A
Most relevant way to measure application
Hard to trace down specifically what to fix
Is the retrieved context relevant?
LLM Eval for Relevance
Directly measures effectiveness of retrieval
Requires additional LLMs calls
Is the knowledge base missing areas of user queries?
Query density (drift) - Phoenix generated
Highlights groups of queries with large distance from context
Identifies broad topics missing from knowledge base, but not small gaps
Depending on what you want to do with your annotations, you may want to configure a rubric for what your annotation represents - e.g. is it a category, number with a range (continuous), or freeform.
Annotation type: - Categorical: Predefined labels for selection. (e.g. 👍 or 👎) - Continuous: a score across a specified range. (e.g. confidence score 0-100) - Freeform: Open-ended text comments. (e.g. "correct")
Optimize the direction based on your goal: - Maximize: higher scores are better. (e.g. confidence) - Minimize: lower scores are better. (e.g. hallucinations) - None: direction optimization does not apply. (e.g. tone)
See for more details.
Phoenix supports annotating different annotation targets to capture different levels of LLM application performance. The core annotation types include:
Span Annotations: Applied to individual spans within a trace, providing granular feedback about specific components
Document Annotations: Specifically for retrieval systems, evaluating individual documents with metrics like relevance and precision
Each annotation can include:
Labels: Text-based classifications (e.g., "helpful" or "not helpful")
Scores: Numeric evaluations (e.g., 0-1 scale for relevance)
Explanations: Detailed justifications for the annotation
These annotations can come from different sources:
Human feedback (e.g., thumbs up/down from end-users)
LLM-as-a-judge evaluations (automated assessments)
Code-based evaluations (programmatic metrics)
Phoenix also supports specialized evaluation metrics for retrieval systems, including NDCG, Precision@K, and Hit Rate, making it particularly useful for evaluating search and retrieval components of LLM applications.
Human feedback allows you to understand how your users are experiencing your application and helps draw attention to problematic traces. Phoenix makes it easy to collect feedback for traces and view it in the context of the trace, as well as filter all your traces based on the feedback annotations you send. Before anything else, you want to know if your users or customers are happy with your product. This can be as straightforward as adding 👍 👎 buttons to your application, and logging the result as annotations.
For more information on how to wire up your application to collect feedback from your users, see .
When you have large amounts of data it can be immensely efficient and valuable to leverage LLM judges via evals to produce labels and scores to annotate your traces with. Phoenix's evals library as well as other third-party eval libraries can be leveraged to annotate your spans with evaluations. For details see to:
Generate evaluation results
Add evaluation results to spans
Sometimes you need to rely on human annotators to attach feedback to specific traces of your application. Human annotations through the UI can be thought of as manual quality assurance. While it can be a bit more labor intensive, it can help in sharing insights within a team, curating datasets of good/bad examples, and even in training an LLM judge.
Annotations can help you share valuable insight about how your application is performing. However making these insights actionable can be difficult. With Phoenix, the annotations you add to your trace data is propagated to datasets so that you can use the annotations during experimentation.
Since Phoenix datasets preserve the annotations, you can track whether or not changes to your application (e.g. experimentation) produce better results (e.g. better scores / labels). Phoenix evaluators have access to the example metadata at evaluation time, making it possible to track improvements / regressions over previous generations (e.g. the previous annotations).
AI development currently faces challenges when evaluating LLM application outputs at scale:
Human annotation is precise but time-consuming and impossible to scale efficiently.
Existing automated methods using LLM judges require careful prompt engineering and often fall short of capturing human evaluation nuances.
Solutions requiring extensive human resources are difficult to scale and manage.
These challenges create a bottleneck in the rapid development and improvement of high-quality LLM applications.
Since Phoenix datasets preserve the annotations in the example metadata, you can use datasets to build human-preference calibrated judges using libraries and tools such as DSPy and Zenbase.
Phoenix supports three types of annotators: Human, LLM, and Code.
Annotator Kind
Source
Purpose
Strengths
Use Case
Human
Manual review
Expert judgment and quality assurance
High accuracy, nuanced understanding
Manual QA, edge cases, subjective evaluation
LLM
Language model output
Scalable evaluation of application responses
Fast, scalable, consistent across examples
Large-scale output scoring, pattern review
Code
Programmatic evaluators
Automated assessment based on rules/metrics
Objective, repeatable, useful in experiments
Model benchmarking, regression testing
Phoenix provides two interfaces for annotations: API and APP. The API interface via the REST clients enables automated feedback collection at scale, such as collecting thumbs up/down from end-users in production, providing real-time insights into LLM system performance. The APP interface via the UI offers an efficient workflow for human annotators with hotkey support and structured configurations, making it practical to create high-quality training sets for LLMs.
The combination of these interfaces creates a powerful feedback loop: human annotations through the APP interface help train and calibrate LLM evaluators, which can then be deployed at scale via the API. This cycle of human oversight and automated evaluation helps identify the most valuable examples for review while maintaining quality at scale.
Annotation configurations in Phoenix are designed to maximize efficiency for human annotators. The system allows you to define the structure of annotations (categorical or continuous values, with appropriate bounds and options) and pair these with keyboard shortcuts (hotkeys) to enable rapid annotation.
For example, a categorical annotation might be configured with specific labels that can be quickly assigned using number keys, while a continuous annotation might use arrow keys for fine-grained scoring. This combination of structured configurations and hotkey support allows annotators to provide feedback quickly, significantly reducing the effort required for manual annotation tasks.
The primary goal is to streamline the annotation workflow, enabling human annotators to process large volumes of data efficiently while maintaining quality and consistency in their feedback.
An independent deep‑dive into the science of giving language‑model agents the “right mind at the right moment.”
Context engineering is the practice of deciding exactly what information a large language model (LLM)—or a group of LLM agents—should see when doing a task. This includes what data is shown, how it’s organized, and how it’s framed.
We break context into four main parts:
Information (I): Facts, documents, or intermediate results passed into the model.
State (S): What the model needs to know about the current session—like the conversation so far or the structure of a task.
Tools (T): External systems the model can access, like APIs or data sources.
Format (F): How everything is wrapped—prompt templates, instructions, or response formats.
By treating these pieces like we treat code—versioning, testing, measuring, and improving them—we can make LLM outputs more predictable and reliable across use cases.
Large models perform well in single-shot tasks, but real-world systems often use agents that delegate, call APIs, and persist across time. In these long-running setups, common failure modes include:
Context drift: Agents develop conflicting views of the truth.
Bandwidth overload: Passing full histories strains context limits and slows responses.
Tool blindness: Agents get raw data but lack guidance on how to use it.
In practice, stale or inconsistent context is the leading cause of coordination failures. Even basic memory update strategies can significantly alter agent behavior over time—highlighting the need for deliberate memory management.
Prompt engineering and context engineering are related but distinct disciplines. Both shape how language models behave—but they operate at different levels of abstraction.
Prompt engineering focuses on the how: crafting the right wording, tone, and examples to guide the model’s behavior in a single interaction. It’s about writing the best possible "function call" to the model.
Context engineering, by contrast, governs the what, when, and how of the information the model observes. It spans entire workflows, manages memory across turns, and ensures the model has access to relevant tools and schemas. If prompt engineering is writing a clean function call, context engineering is architecting the full service contract—including interfaces, dependencies, and state management.
Context engineering becomes essential when systems move from isolated prompts to persistent agents and long-running applications. It enables scalable coordination, memory, and interaction across tasks—turning a language model from a tool into part of a system.
As systems grow beyond one-off prompts and into long-running workflows, context becomes a key engineering surface. These principles guide how to design and manage context for LLMs and agent-based systems.
Each principle pushes context design toward systems that are leaner, more interpretable, and better aligned with both model behavior and downstream actions.
Systems that rely on long or complex context need well-designed memory. The patterns below offer practical ways to manage context, depending on how much information your system handles and how long it needs to remember it.
Three-tier memory breaks context into three layers: short-term (exact text), mid-term (summaries), and long-term (titles or embeddings). This makes it easier to keep recent details while still remembering important older information. It’s a good fit for chats or agents that run over many turns. Hierarchical Memory Transformers (HMT) follow this design.
Recurrent compression buffers take earlier parts of a stream—like a transcript or log—and compress them into smaller representations that can be brought back later if needed. This saves space while keeping the option to recall details when relevant.
State-space backbones store memory outside the prompt using a hidden state that carries over between turns. This lets the model handle much longer sequences efficiently. It’s especially useful in devices with tight memory or speed limits, like mobile or edge systems. Mamba is one example of this pattern.
Context cache and KV-sharing spread memory across different servers by saving reusable attention patterns. This avoids repeating work and keeps prompts small, making it a strong choice for systems running many requests in parallel. MemServe uses this technique.
Hybrid retrieval combines two steps: first, it filters data using keywords or metadata; then it uses vector search for meaning. This cuts down on irrelevant results, especially in datasets with lots of similar content.
Graph-of-thought memory turns ideas into a graph, where entities and their relationships are nodes and edges. Instead of sending the whole graph to the model, only the relevant part is used. This works well for complex tasks like analysis or knowledge reasoning and is often built with tools like Neo4j or TigerGraph.
Each of these patterns offers a different way to scale memory and context depending on the problem. They help systems stay efficient, accurate, and responsive as context grows.
Log every prompt and context segment. Track exactly what the model sees at each step.
Label each span. Mark whether it was used, ignored, hallucinated, or contributed to the final output.
Measure return on input (ROI).
For each span, calculate: ROI = token cost ÷ impact on accuracy.
Trim low-value spans. Drop spans with low ROI. Keep references (pointers) in case retrieval is needed later.
Train a salience model. Predict which spans should be included in context automatically, based on past usefulness.
Test with adversarial context. Shuffle inputs or omit key details to probe model robustness and dependency on context structure.
Run regression evaluations. Repeatedly test the system across agent roles and tasks to catch context-related drift or failures.
Version and diff context bundles. Treat context like code—snapshot, compare, and review changes before release.
Multi-agent systems are powerful because they divide knowledge and responsibility across roles. But that same structure becomes fragile when context is outdated, overloaded, or misaligned.
Context engineering turns prompting from trial-and-error into system design. It ensures each agent sees the right information, in the right form, at the right time.
To build reliable systems, treat context as a core artifact—not just an input. Observe it. Version it. Optimize it. With that foundation, agents stop behaving like chat interfaces and start acting like collaborators.
Optimises
Wording, tone, in‑context examples
Selection, compression, memory, tool schemas
Timescale
Single request/response
Full session or workflow
Metrics
BLEU, factuality, helpfulness (per turn)
Task success vs. token cost, long-horizon consistency
Salience over size
More tokens don’t mean more value—signal matters more than volume.
Salience scoring + reservoir sampling to retain only statistically “interesting” chunks
Structure first
Models and tools handle structured inputs more reliably than unstructured text.
Use canonical world-state objects; track changes with diff logs
Hierarchies beat flat buffers
Effective recall happens at multiple levels of detail—not in a flat sequence.
Multi-resolution memory via Hierarchical Memory Transformers
Lazy Recall
Don’t pay the context cost until the information is actually needed.
Use pointer IDs and on-demand retrieval (RAG)
Deterministic provenance
You can’t debug what you can’t trace—source tracking is critical.
Apply “git-for-thoughts” commit hashes to memory updates
Context–tool co-design
Information should be shaped for use, not just stored—tools need actionable input.
Embed tool signatures alongside payloads so the model knows how to act
A feature comparison guide for AI engineers looking for developer-friendly LangSmith alternatives.
LangSmith is another LLM Observability and Evaluation platform that serves as an alternative to Arize Phoenix. Both platforms support the baseline tracing, evaluation, prompt management, and experimentation features, but there are a few key differences to be aware of:
LangSmith is closed source, while Phoenix is open source
LangSmith is part of the broader LangChain ecosystem, though it does support applications that don’t use LangChain. Phoenix is fully framework-agnostic.
Self-hosting is a paid feature within LangSmith, vs free for Phoenix.
Phoenix is backed by Arize AI. Phoenix users always have the option to graduate into Arize AX, with additional features, a customer success org, infosec team, and dedicated support. Meanwhile, Phoenix is able to focus entirely on providing the best fully open-source solution in the ecosystem.
The first and most fundamental difference: LangSmith is closed source, while Phoenix is fully open source.
This means Phoenix users have complete control over how the platform is used, modified, and integrated. Whether you're running in a corporate environment with custom compliance requirements or you're building novel agent workflows, open-source tooling allows for a degree of flexibility and transparency that closed platforms simply can’t match.
LangSmith users, on the other hand, are dependent on a vendor roadmap and pricing model, with limited ability to inspect or modify the underlying system.
LangSmith is tightly integrated with the LangChain ecosystem, and while it technically supports non-LangChain applications, the experience is optimized for LangChain-native workflows.
Phoenix is designed from the ground up to be framework-agnostic. It supports popular orchestration tools like LangChain, LlamaIndex, CrewAI, SmolAgents, and custom agents, thanks to its OpenInference instrumentation layer. This makes Phoenix a better choice for teams exploring multiple agent/orchestration frameworks—or who simply want to avoid vendor lock-in.
If self-hosting is a requirement—for reasons ranging from data privacy to performance—Phoenix offers it out-of-the-box, for free. You can launch the entire platform with a single Docker container, no license keys or paywalls required.
LangSmith, by contrast, requires a paid plan to access self-hosting options. This can be a barrier for teams evaluating tools or early in their journey, especially those that want to maintain control over their data from day one.
Phoenix is backed by Arize AI, the leading and best-funded AI Observability provider in the ecosystem.
Arize Phoenix is intended to be a complete LLM observability solution, however for users who do not want to self-host, or who need additional features like Custom Dashboards, Copilot, Dedicated Support, or HIPAA compliance, there is a seamless upgrade path to Arize AX.
The success of Arize means that Phoenix does not need to be heavily commercialized. It can focus entirely on providing the best open-source solution for LLM Observability & Evaluation.
Open Source
✅
Tracing
✅
✅
✅
Auto-Instrumentation
✅
✅
Offline Evals
✅
✅
✅
Online Evals
✅
✅
Experimentation
✅
✅
✅
Prompt Management
✅
✅
✅
Prompt Playground
✅
✅
✅
Run Prompts on Datasets
✅
✅
✅
Built-in Evaluators
✅
✅
✅
Agent Evaluations
✅
✅
✅
Human Annotations
✅
✅
✅
Custom Dashboards
✅
Workspaces
✅
Semantic Querying
✅
Copilot Assistant
✅
LangSmith is a strong option for teams all-in on the LangChain ecosystem and comfortable with a closed-source platform. But for those who value openness, framework flexibility, and low-friction adoption, Arize Phoenix stands out as the more accessible and extensible observability solution.
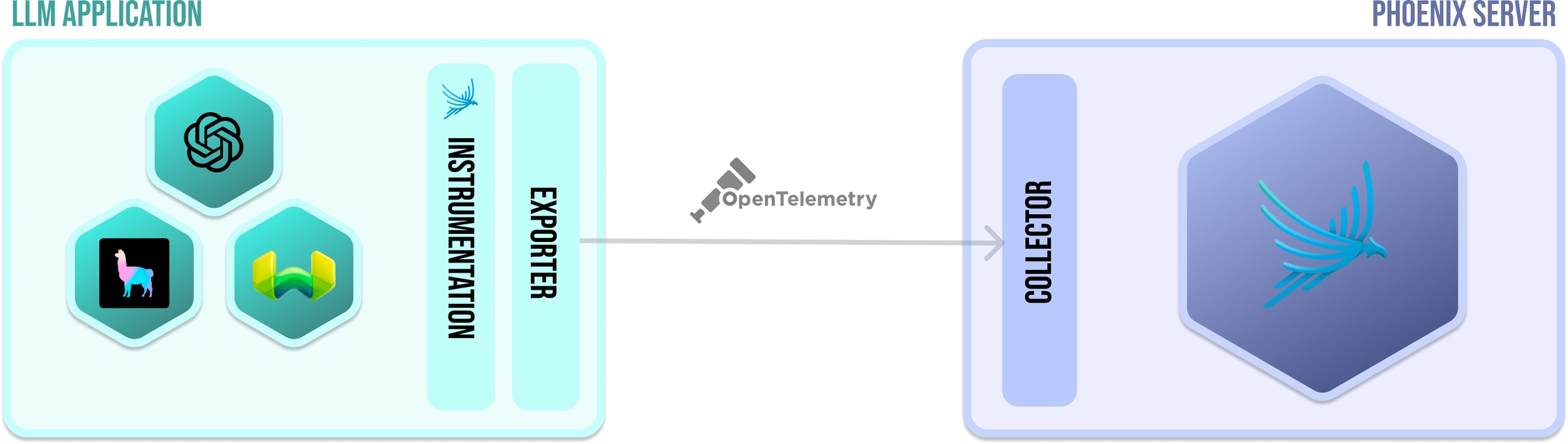
Everything you need to know about Google's GenAI framework
Google's GenAI SDK is a framework designed to help you interact with Gemini models and models run through VertexAI. Out of all the frameworks detailed in this guide, GenAI SDK is the closest to a base model SDK. While it does provide helpful functions and concepts to streamline tool calling, structured output, and passing files, it does not approach the level of abstraction of frameworks like CrewAI or Autogen.
In April 2025, Google launched its ADK framework, which is a more comparable agent orchestration framework to the others on this list.
That said, because of the relative simplicity of the GenAI SDK, this guide serves as a good learning tool to show how some of the common agent patterns can be manually implemented.
GenAI SDK uses contents to represent user messages, files, system messages, function calls, and invocation parameters. That creates relatively simple generation calls:
file = client.files.upload(file='a11.txt')
response = client.models.generate_content(
model='gemini-2.0-flash-001',
contents=['Could you summarize this file?', file]
)
print(response.text)Content objections can also be composed together in a list:
[
types.UserContent(
parts=[
types.Part.from_text('What is this image about?'),
types.Part.from_uri(
file_uri: 'gs://generativeai-downloads/images/scones.jpg',
mime_type: 'image/jpeg',
)
]
)
]Google GenAI does not include built in orchestration patterns.
GenAI has no concept of handoffs natively.
State is handled by maintaining a list of previous messages and other data in a list of content objections. This is similar to how other model SDKs like OpenAI and Anthropic handle the concept of state. This stands in contrast to the more sophisticated measurements of state present in agent orchestration frameworks.
GenAI does include some conveience features around tool calling. The types.GenerateContentConfig method can automatically convert base python functions into signatures. To do this, the SDK will use the function docstring to understand its purpose and arguments.
def get_current_weather(location: str) -> str:
"""Returns the current weather.
Args:
location: The city and state, e.g. San Francisco, CA
"""
return 'sunny'
response = client.models.generate_content(
model='gemini-2.0-flash-001',
contents='What is the weather like in Boston?',
config=types.GenerateContentConfig(tools=[get_current_weather]),
)
print(response.text)GenAI will also automatically call the function and incorporate its return value. This goes a step beyond what similar model SDKs do on other platforms. This behavior can be disabled.
GenAI has no built-in concept of memory.
GenAI has no built-in collaboration strategies. These must be defined manually.
GenAI supports streaming of both text and image responses:
for chunk in client.models.generate_content_stream(
model='gemini-2.0-flash-001', contents='Tell me a story in 300 words.'
):
print(chunk.text, end='')GenAI is the "simplest" framework in this guide, and is closer to a pure model SDK like the OpenAI SDK, rather than an agent framework. It does go a few steps beyond these base SDKs however, notably in tool calling. It is a good option if you're using Gemini models, and want more direct control over your agent system.
Content approach streamlines message management
No built-in orchestration capabilities
Supports automatic tool calling
No state or memory management
Allows for all agent patterns, but each must be manually set up
Primarily designed to work with Gemini models
This workflow breaks a task into smaller steps, where the output of one agent becomes the input to another. It’s useful when a single prompt can’t reliably handle the full complexity or when you want clarity in intermediate reasoning.
Notebook: Research Agent The agent first researches a topic, then provides an executive summary of its results, then finally recommends future focus directions.
How to evaluate: Check whether each step performs its function correctly and whether the final result meaningfully depends on the intermediate output (e.g., do key points reflect the original research?)
Check if the intermediate step (e.g. key point extraction) is meaningful and accurate
Ensure the final output reflects or builds on the intermediate output
Compare chained vs. single-step prompting to see if chaining improves quality or structure
Routing is used to send inputs to the appropriate downstream agent or workflow based on their content. The routing logic is handled by a dedicated call, often using lightweight classification.
Notebook: Simple Tool Router This agent shows a simple example of routing use inputs to different tools.
How to evaluate: Compare the routing decision to human judgment or labeled examples (e.g., did the router choose the right tool for a given input?)
Compare routing decisions to human-labeled ground truth or expectations
Track precision/recall if framed as a classification task
Monitor for edge cases and routing errors
This pattern uses two agents in a loop: one generates a solution, the other critiques it. The generator revises until the evaluator accepts the result or a retry limit is reached. It’s useful when quality varies across generations.
Notebook: Story Writing Agent An agent generates an initial draft of a story, then a critique agent decides whether the quality is high enough. If not, it asks for a revision.
How to evaluate: Track how many iterations are needed to converge and whether final outputs meet predefined criteria (e.g., is the story engaging, clear, and well-written?)
Measure how many iterations are needed to reach an acceptable result
Evaluate final output quality against criteria like tone, clarity, and specificity
Compare the evaluator’s judgment to human reviewers to calibrate reliability
In this approach, a central agent coordinates multiple agents, each with a specialized role. It’s helpful when tasks can be broken down and assigned to domain-specific workers.
Notebook: Travel Planning Agent The orchestrator delegates planning a trip for a user, and incorporates a user proxy to improve its quality. The orchestrator delegates to specific functions to plan flights, hotels, and provide general travel recommendations.
How to evaluate: Assess consistency between subtasks and whether the final output reflects the combined evaluations (e.g., does the final output align with the inputs from each worker agent?)
Ensure each worker agent completes its role accurately and in isolation
Check if the orchestrator integrates worker outputs into a consistent final result
Look for agreement or contradictions between components
When you need to process many inputs using the same logic, parallel execution improves speed and resource efficiency. Agents can be launched concurrently without changing their individual behavior.
Notebook: Parallel Research Agent Multiple research topics are examined simultaneously. Once all are complete, the topics are then synthesized into a final combined report.
How to evaluate: Ensure results remain consistent with sequential runs and monitor for improvements in latency and throughput (e.g., are topics processed correctly and faster when run in parallel?)
Confirm that outputs are consistent with those from a sequential execution
Track total latency and per-task runtime to assess parallel speedup
Watch for race conditions, dropped inputs, or silent failures in concurrency
This section introduces inferences and schemas, the starting concepts needed to use Phoenix with inferences.
Phoenix inferences are an instance of phoenix.Inferences that contains three pieces of information:
The data itself (a pandas dataframe)
A schema (a phoenix.Schema instance) that describes the columns of your dataframe
A name that appears in the UI
For example, if you have a dataframe prod_df that is described by a schema prod_schema, you can define inferences prod_ds with
prod_ds = px.Inferences(prod_df, prod_schema, "production")If you launch Phoenix with these inferences, you will see inferences named "production" in the UI.
You can launch Phoenix with zero, one, or two sets of inferences.
With no inferences, Phoenix runs in the background and collects trace data emitted by your instrumented LLM application. With a single inference set, Phoenix provides insights into model performance and data quality. With two inference sets, Phoenix compares your inferences and gives insights into drift in addition to model performance and data quality, or helps you debug your retrieval-augmented generation applications.
Your reference inferences provides a baseline against which to compare your primary inferences.
To compare two inference sets with Phoenix, you must select one inference set as primary and one to serve as a reference. As the name suggests, your primary inference set contains the data you care about most, perhaps because your model's performance on this data directly affects your customers or users. Your reference inferences, in contrast, is usually of secondary importance and serves as a baseline against which to compare your primary inferences.
Very often, your primary inferences will contain production data and your reference inferences will contain training data. However, that's not always the case; you can imagine a scenario where you want to check your test set for drift relative to your training data, or use your test set as a baseline against which to compare your production data. When choosing primary and reference inference sets, it matters less where your data comes from than how important the data is and what role the data serves relative to your other data.
The only difference for the corpus inferences is that it needs a separate schema because it has a different set of columns compared to the model data. See the schema section for more details.
A Phoenix schema is an instance of phoenix.Schema that maps the columns of your dataframe to fields that Phoenix expects and understands. Use your schema to tell Phoenix what the data in your dataframe means.
For example, if you have a dataframe containing Fisher's Iris data that looks like this:
7.7
3.0
6.1
2.3
virginica
versicolor
5.4
3.9
1.7
0.4
setosa
setosa
6.3
3.3
4.7
1.6
versicolor
versicolor
6.2
3.4
5.4
2.3
virginica
setosa
5.8
2.7
5.1
1.9
virginica
virginica
your schema might look like this:
schema = px.Schema(
feature_column_names=[
"sepal_length",
"sepal_width",
"petal_length",
"petal_width",
],
actual_label_column_name="target",
prediction_label_column_name="prediction",
)Usually one, sometimes two.
Each inference set needs a schema. If your primary and reference inferences have the same format, then you only need one schema. For example, if you have dataframes train_df and prod_df that share an identical format described by a schema named schema, then you can define inference sets train_ds and prod_ds with
train_ds = px.Inferences(train_df, schema, "training")
prod_ds = px.Inferences(prod_df, schema, "production")Sometimes, you'll encounter scenarios where the formats of your primary and reference inference sets differ. For example, you'll need two schemas if:
Your production data has timestamps indicating the time at which an inference was made, but your training data does not.
Your training data has ground truth (what we call actuals in Phoenix nomenclature), but your production data does not.
A new version of your model has a differing set of features from a previous version.
In cases like these, you'll need to define two schemas, one for each inference set. For example, if you have dataframes train_df and prod_df that are described by schemas train_schema and prod_schema, respectively, then you can define inference sets train_ds and prod_ds with
train_ds = px.Inferences(train_df, train_schema, "training")
prod_ds = px.Inferences(prod_df, prod_schema, "production")A corpus inference set, containing documents for information retrieval, typically has a different set of columns than those found in the model data from either production or training, and requires a separate schema. Below is an example schema for a corpus inference set with three columns: the id, text, and embedding for each document in the corpus.
corpus_schema=Schema(
id_column_name="id",
document_column_names=EmbeddingColumnNames(
vector_column_name="embedding",
raw_data_column_name="text",
),
),
corpus_ds = px.Inferences(corpus_df, corpus_schema)A deep dive into the details of a trace
A span represents a unit of work or operation (think a span of time). It tracks specific operations that a request makes, painting a picture of what happened during the time in which that operation was executed.
A span contains name, time-related data, structured log messages, and other metadata (that is, Attributes) to provide information about the operation it tracks. A span for an LLM execution in JSON format is displayed below
Spans can be nested, as is implied by the presence of a parent span ID: child spans represent sub-operations. This allows spans to more accurately capture the work done in an application.
A trace records the paths taken by requests (made by an application or end-user) as they propagate through multiple steps.
Without tracing, it is challenging to pinpoint the cause of performance problems in a system.
It improves the visibility of our application or system’s health and lets us debug behavior that is difficult to reproduce locally. Tracing is essential for LLM applications, which commonly have nondeterministic problems or are too complicated to reproduce locally.
Tracing makes debugging and understanding LLM applications less daunting by breaking down what happens within a request as it flows through a system.
A trace is made of one or more spans. The first span represents the root span. Each root span represents a request from start to finish. The spans underneath the parent provide a more in-depth context of what occurs during a request (or what steps make up a request).
A project is a collection of traces. You can think of a project as a container for all the traces that are related to a single application or service. You can have multiple projects, and each project can have multiple traces. Projects can be useful for various use-cases such as separating out environments, logging traces for evaluation runs, etc. To learn more about how to setup projects, see the how-to guide
When a span is created, it is created as one of the following: Chain, Retriever, Reranker, LLM, Embedding, Agent, or Tool.
CHAIN
A Chain is a starting point or a link between different LLM application steps. For example, a Chain span could be used to represent the beginning of a request to an LLM application or the glue code that passes context from a retriever to and LLM call.
RETRIEVER
A Retriever is a span that represents a data retrieval step. For example, a Retriever span could be used to represent a call to a vector store or a database.
RERANKER
A Reranker is a span that represents the reranking of a set of input documents. For example, a cross-encoder may be used to compute the input documents' relevance scores with respect to a user query, and the top K documents with the highest scores are then returned by the Reranker.
LLM
An LLM is a span that represents a call to an LLM. For example, an LLM span could be used to represent a call to OpenAI or Llama.
EMBEDDING
An Embedding is a span that represents a call to an LLM for an embedding. For example, an Embedding span could be used to represent a call OpenAI to get an ada-2 embedding for retrieval.
TOOL
A Tool is a span that represents a call to an external tool such as a calculator or a weather API.
AGENT
A span that encompasses calls to LLMs and Tools. An agent describes a reasoning block that acts on tools using the guidance of an LLM.\
Attributes are key-value pairs that contain metadata that you can use to annotate a span to carry information about the operation it is tracking.
For example, if a span invokes an LLM, you can capture the model name, the invocation parameters, the token count, and so on.
Attributes have the following rules:
Keys must be non-null string values
Values must be a non-null string, boolean, floating point value, integer, or an array of these values Additionally, there are Semantic Attributes, which are known naming conventions for metadata that is typically present in common operations. It's helpful to use semantic attribute naming wherever possible so that common kinds of metadata are standardized across systems. See for more information.
Below are example OTEL spans for each OpenInference spanKind to be used as reference when doing manual instrumentation
Use Zero Inference sets When:
You want to run Phoenix in the background to collect trace data from your instrumented LLM application.
Use a Single Inference set When:
You have only a single cohort of data, e.g., only training data.
You care about model performance and data quality, but not drift.
Use Two Inference sets When:
You want to compare cohorts of data, e.g., training vs. production.
You care about drift in addition to model performance and data quality.
You have corpus data for information retrieval. See Corpus Data.
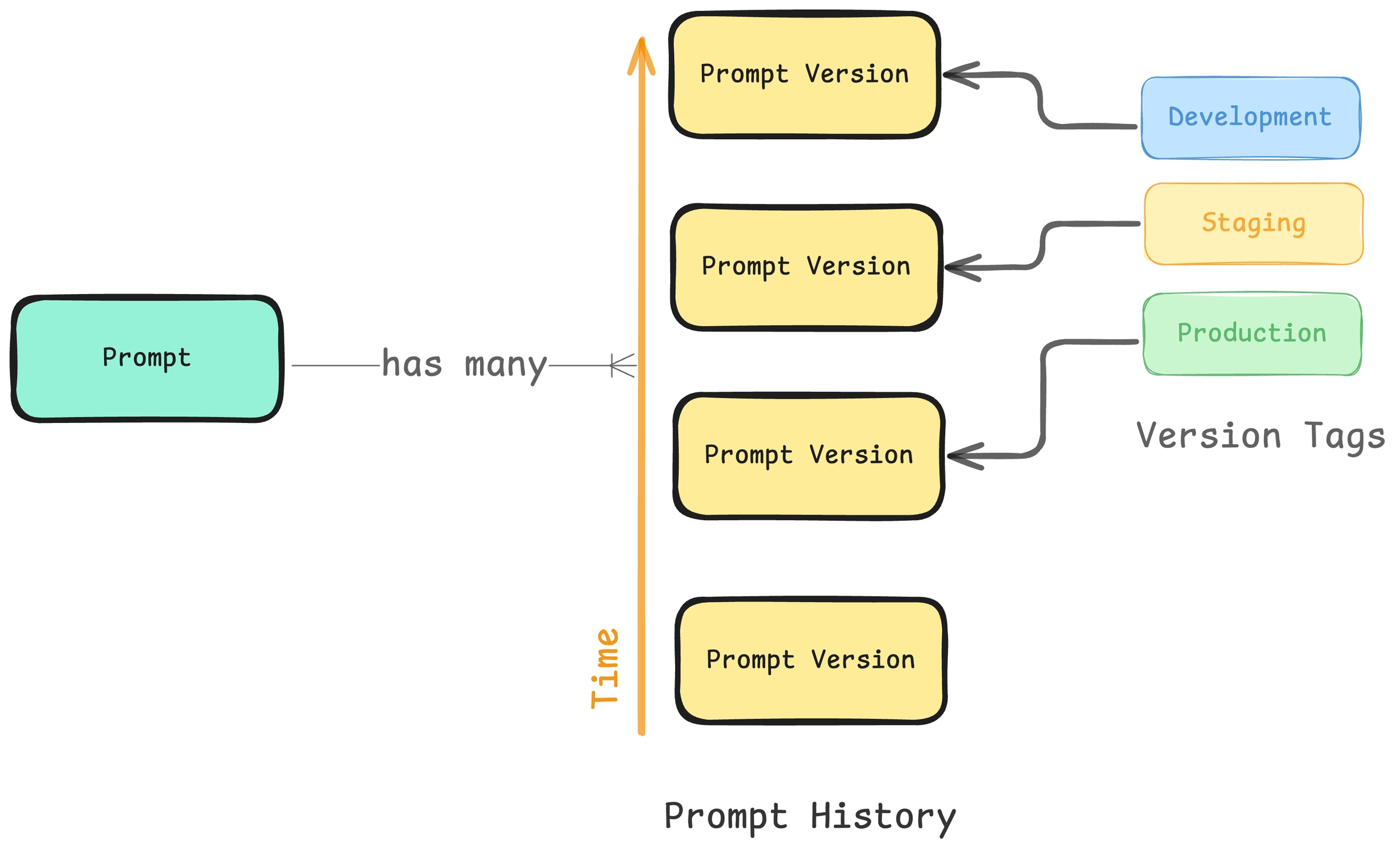
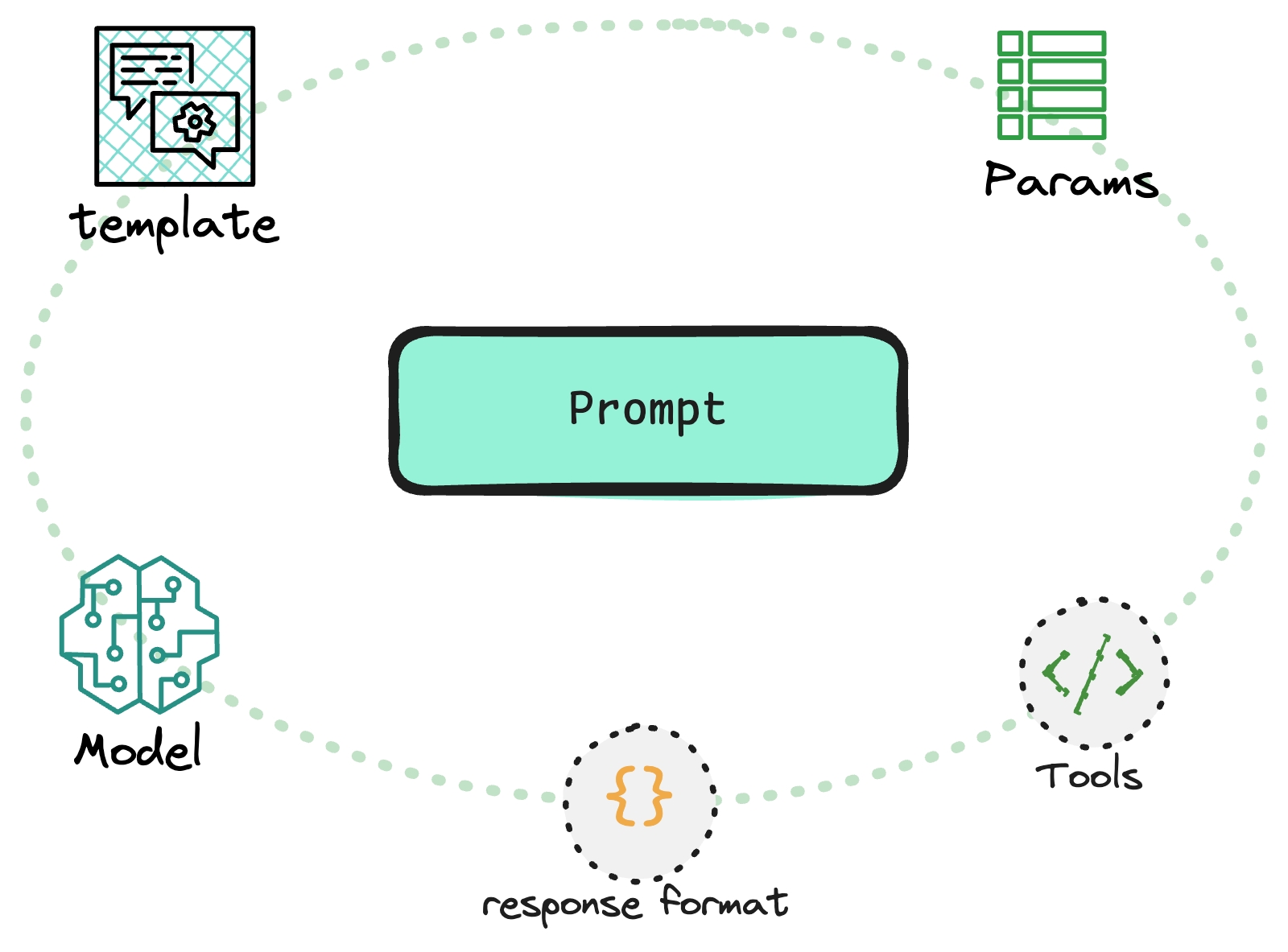

{
"name": "llm",
"context": {
"trace_id": "0x6c80880dbeb609e2ed41e06a6397a0dd",
"span_id": "0xd9bdedf0df0b7208",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x7eb5df0046c77cd2",
"start_time": "2024-05-08T21:46:11.480777Z",
"end_time": "2024-05-08T21:46:35.368042Z",
"status": {
"status_code": "OK"
},
"attributes": {
"openinference.span.kind": "LLM",
"llm.input_messages.0.message.role": "system",
"llm.input_messages.0.message.content": "\n The following is a friendly conversation between a user and an AI assistant.\n The assistant is talkative and provides lots of specific details from its context.\n If the assistant does not know the answer to a question, it truthfully says it\n does not know.\n\n Here are the relevant documents for the context:\n\n page_label: 7\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.4Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. No piece may weigh more than 70 pounds.\nb. The combined length and girth of a piece (the length of its longest side plus \nthe distance around its thickest part) may not exceed 108 inches.\nc. Lower size or weight standards apply to mail addressed to certain APOs and \nFPOs, subject to 703.2.0 and 703.4.0 and for Department of State mail, \nsubject to 703.3.0 .\n\npage_label: 6\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.2.10Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. The reply half of a double card must be used for reply only and may not be \nused to convey a message to the original addressee or to send statements \nof account. The reply half may be formatted for response purposes (e.g., contain blocks for completion by the addressee).\nb. A double card must be folded before mailing and prepared so that the \naddress on the reply half is on the inside when the double card is originally \nmailed. The address side of the reply half may be prepared as Business \nReply Mail, Courtesy Reply Mail, meter reply mail, or as a USPS Returns service label.\nc. Plain stickers, seals, or a single wire stitch (staple) may be used to fasten the \nopen edge at the top or bottom once the card is folded if affixed so that the \ninner surfaces of the cards can be readily examined. Fasteners must be \naffixed according to the applicable preparation requirements for the price claimed. Any sealing on the left and right sides of the cards, no matter the \nsealing process used, is not permitted.\nd. The first half of a double card must be detached when the reply half is \nmailed for return. \n6.2.10 Enclosures\nEnclosures in double postcards are prohibited at card prices. \n6.3 Nonmachinable Pieces\n6.3.1 Nonmachinable Letters\nLetter-size pieces (except card-size pieces) that meet one or more of the \nnonmachinable characteristics in 1.2 are subject to the nonmachinable \nsurcharge (see 133.1.7 ). \n6.3.2 Nonmachinable Flats\nFlat-size pieces that do not meet the standards in 2.0 are considered parcels, \nand the mailer must pay the applicable parcel price. \n6.4 Parcels \n[7-9-23] USPS Ground Advantage \u2014 Retail parcels are eligible for USPS \nTracking and Signature Confirmation service. A USPS Ground Advantage \u2014 \nRetail parcel is the following:\na. A mailpiece that exceeds any one of the maximum dimensions for a flat \n(large envelope). See 2.1.\nb. A flat-size mailpiece, regardless of thickness, that is rigid or nonrectangular. \nc. A flat-size mailpiece that is not uniformly thick under 2.4. \nd.[7-9-23] A mailpiece that does not exceed 130 inches in combined length \nand girth.\n7.0 Additional Physical Standards for Media Mail and Library \nMail\nThese standards apply to Media Mail and Library Mail:\n\npage_label: 4\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.1Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\n4.0 Additional Physical Standa rds for Priority Mail Express\nEach piece of Priority Mail Express may not weigh more than 70 pounds. The \ncombined length and girth of a piece (the length of its longest side plus the \ndistance around its thickest part) may not exceed 108 inches. Lower size or weight standards apply to Priority Mail Express addressed to certain APO/FPO \nand DPOs. Priority Mail Express items must be large enough to hold the required \nmailing labels and indicia on a single optical plane without bending or folding.\n5.0 Additional Physical St andards for Priority Mail\nThe maximum weight is 70 pounds. The combined length and girth of a piece \n(the length of its longest side plus the distance around its thickest part) may not \nexceed 108 inches. Lower size and weight standards apply for some APO/FPO \nand DPO mail subject to 703.2.0 , and 703.4.0 , and for Department of State mail \nsubject to 703.3.0 . \n[7-9-23] \n6.0 Additional Physical Standa rds for First-Class Mail and \nUSPS Ground Advantage \u2014 Retail\n[7-9-23]\n6.1 Maximum Weight\n6.1.1 First-Class Mail\nFirst-Class Mail (letters and flats) must not exceed 13 ounces. \n6.1.2 USPS Ground Advantage \u2014 Retail\nUSPS Ground Advantage \u2014 Retail mail must not exceed 70 pounds.\n6.2 Cards Claimed at Card Prices\n6.2.1 Card Price\nA card may be a single or double (reply) stamped card or a single or double postcard. Stamped cards are available from USPS with postage imprinted on \nthem. Postcards are commercially available or privately printed mailing cards. To \nbe eligible for card pricing, a card and each half of a double card must meet the physical standards in 6.2 and the applicable eligibility for the price claimed. \nIneligible cards are subject to letter-size pricing. \n6.2.2 Postcard Dimensions\nEach card and part of a double card claimed at card pricing must be the following: \na. Rectangular.b. Not less than 3-1/2 inches high, 5 inches long, and 0.007 inch thick.\nc. Not more than 4-1/4 inches high, or more than 6 inches long, or greater than \n0.016 inch thick.\nd. Not more than 3.5 ounces (Charge flat-size prices for First-Class Mail \ncard-type pieces over 3.5 ounces.)\n\n Instruction: Based on the above documents, provide a detailed answer for the user question below.\n Answer \"don't know\" if not present in the document.\n ",
"llm.input_messages.1.message.role": "user",
"llm.input_messages.1.message.content": "Hello",
"llm.model_name": "gpt-4-turbo-preview",
"llm.invocation_parameters": "{\"temperature\": 0.1, \"model\": \"gpt-4-turbo-preview\"}",
"output.value": "How are you?" },
"events": [],
"links": [],
"resource": {
"attributes": {},
"schema_url": ""
}
}{
"name": "llm",
"context": {
"trace_id": "0x6c80880dbeb609e2ed41e06a6397a0dd",
"span_id": "0xd9bdedf0df0b7208",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x7eb5df0046c77cd2",
"start_time": "2024-05-08T21:46:11.480777Z",
"end_time": "2024-05-08T21:46:35.368042Z",
"status": {
"status_code": "OK"
},
"attributes": {
"openinference.span.kind": "LLM",
"llm.input_messages.0.message.role": "system",
"llm.input_messages.0.message.content": "\n The following is a friendly conversation between a user and an AI assistant.\n The assistant is talkative and provides lots of specific details from its context.\n If the assistant does not know the answer to a question, it truthfully says it\n does not know.\n\n Here are the relevant documents for the context:\n\n page_label: 7\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.4Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. No piece may weigh more than 70 pounds.\nb. The combined length and girth of a piece (the length of its longest side plus \nthe distance around its thickest part) may not exceed 108 inches.\nc. Lower size or weight standards apply to mail addressed to certain APOs and \nFPOs, subject to 703.2.0 and 703.4.0 and for Department of State mail, \nsubject to 703.3.0 .\n\npage_label: 6\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.2.10Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\na. The reply half of a double card must be used for reply only and may not be \nused to convey a message to the original addressee or to send statements \nof account. The reply half may be formatted for response purposes (e.g., contain blocks for completion by the addressee).\nb. A double card must be folded before mailing and prepared so that the \naddress on the reply half is on the inside when the double card is originally \nmailed. The address side of the reply half may be prepared as Business \nReply Mail, Courtesy Reply Mail, meter reply mail, or as a USPS Returns service label.\nc. Plain stickers, seals, or a single wire stitch (staple) may be used to fasten the \nopen edge at the top or bottom once the card is folded if affixed so that the \ninner surfaces of the cards can be readily examined. Fasteners must be \naffixed according to the applicable preparation requirements for the price claimed. Any sealing on the left and right sides of the cards, no matter the \nsealing process used, is not permitted.\nd. The first half of a double card must be detached when the reply half is \nmailed for return. \n6.2.10 Enclosures\nEnclosures in double postcards are prohibited at card prices. \n6.3 Nonmachinable Pieces\n6.3.1 Nonmachinable Letters\nLetter-size pieces (except card-size pieces) that meet one or more of the \nnonmachinable characteristics in 1.2 are subject to the nonmachinable \nsurcharge (see 133.1.7 ). \n6.3.2 Nonmachinable Flats\nFlat-size pieces that do not meet the standards in 2.0 are considered parcels, \nand the mailer must pay the applicable parcel price. \n6.4 Parcels \n[7-9-23] USPS Ground Advantage \u2014 Retail parcels are eligible for USPS \nTracking and Signature Confirmation service. A USPS Ground Advantage \u2014 \nRetail parcel is the following:\na. A mailpiece that exceeds any one of the maximum dimensions for a flat \n(large envelope). See 2.1.\nb. A flat-size mailpiece, regardless of thickness, that is rigid or nonrectangular. \nc. A flat-size mailpiece that is not uniformly thick under 2.4. \nd.[7-9-23] A mailpiece that does not exceed 130 inches in combined length \nand girth.\n7.0 Additional Physical Standards for Media Mail and Library \nMail\nThese standards apply to Media Mail and Library Mail:\n\npage_label: 4\nfile_path: /Users/mikeldking/work/openinference/python/examples/llama-index-new/backend/data/101.pdf\n\nDomestic Mail Manual \u2022 Updated 7-9-23101\n101.6.1Retail Mail: Physical Standards for Letters, Cards, Flats, and Parcels\n4.0 Additional Physical Standa rds for Priority Mail Express\nEach piece of Priority Mail Express may not weigh more than 70 pounds. The \ncombined length and girth of a piece (the length of its longest side plus the \ndistance around its thickest part) may not exceed 108 inches. Lower size or weight standards apply to Priority Mail Express addressed to certain APO/FPO \nand DPOs. Priority Mail Express items must be large enough to hold the required \nmailing labels and indicia on a single optical plane without bending or folding.\n5.0 Additional Physical St andards for Priority Mail\nThe maximum weight is 70 pounds. The combined length and girth of a piece \n(the length of its longest side plus the distance around its thickest part) may not \nexceed 108 inches. Lower size and weight standards apply for some APO/FPO \nand DPO mail subject to 703.2.0 , and 703.4.0 , and for Department of State mail \nsubject to 703.3.0 . \n[7-9-23] \n6.0 Additional Physical Standa rds for First-Class Mail and \nUSPS Ground Advantage \u2014 Retail\n[7-9-23]\n6.1 Maximum Weight\n6.1.1 First-Class Mail\nFirst-Class Mail (letters and flats) must not exceed 13 ounces. \n6.1.2 USPS Ground Advantage \u2014 Retail\nUSPS Ground Advantage \u2014 Retail mail must not exceed 70 pounds.\n6.2 Cards Claimed at Card Prices\n6.2.1 Card Price\nA card may be a single or double (reply) stamped card or a single or double postcard. Stamped cards are available from USPS with postage imprinted on \nthem. Postcards are commercially available or privately printed mailing cards. To \nbe eligible for card pricing, a card and each half of a double card must meet the physical standards in 6.2 and the applicable eligibility for the price claimed. \nIneligible cards are subject to letter-size pricing. \n6.2.2 Postcard Dimensions\nEach card and part of a double card claimed at card pricing must be the following: \na. Rectangular.b. Not less than 3-1/2 inches high, 5 inches long, and 0.007 inch thick.\nc. Not more than 4-1/4 inches high, or more than 6 inches long, or greater than \n0.016 inch thick.\nd. Not more than 3.5 ounces (Charge flat-size prices for First-Class Mail \ncard-type pieces over 3.5 ounces.)\n\n Instruction: Based on the above documents, provide a detailed answer for the user question below.\n Answer \"don't know\" if not present in the document.\n ",
"llm.input_messages.1.message.role": "user",
"llm.input_messages.1.message.content": "Hello",
"llm.model_name": "gpt-4-turbo-preview",
"llm.invocation_parameters": "{\"temperature\": 0.1, \"model\": \"gpt-4-turbo-preview\"}",
"output.value": "How are you?" },
"events": [],
"links": [],
"resource": {
"attributes": {},
"schema_url": ""
}
}{
"name": "retrieve",
"context": {
"trace_id": "0x6c80880dbeb609e2ed41e06a6397a0dd",
"span_id": "0x03f3466720f4bfc7",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": "0x7eb5df0046c77cd2",
"start_time": "2024-05-08T21:46:11.044464Z",
"end_time": "2024-05-08T21:46:11.465803Z",
"status": {
"status_code": "OK"
},
"attributes": {
"openinference.span.kind": "RETRIEVER",
"input.value": "tell me about postal service",
"retrieval.documents.0.document.id": "6d4e27be-1d6d-4084-a619-351a44834f38",
"retrieval.documents.0.document.score": 0.7711453293100421,
"retrieval.documents.0.document.content": "<document-chunk-1>",
"retrieval.documents.0.document.metadata": "{\"page_label\": \"7\", \"file_name\": \"/data/101.pdf\", \"file_path\": \"/data/101.pdf\", \"file_type\": \"application/pdf\", \"file_size\": 47931, \"creation_date\": \"2024-04-12\", \"last_modified_date\": \"2024-04-12\"}",
"retrieval.documents.1.document.id": "869d9f6d-db9a-43c4-842f-74bd8d505147",
"retrieval.documents.1.document.score": 0.7672439175862021,
"retrieval.documents.1.document.content": "<document-chunk-2>",
"retrieval.documents.1.document.metadata": "{\"page_label\": \"6\", \"file_name\": \"/data/101.pdf\", \"file_path\": \"/data/101.pdf\", \"file_type\": \"application/pdf\", \"file_size\": 47931, \"creation_date\": \"2024-04-12\", \"last_modified_date\": \"2024-04-12\"}",
"retrieval.documents.2.document.id": "72b5cb6b-464f-4460-b497-cc7c09d1dbef",
"retrieval.documents.2.document.score": 0.7647611816897794,
"retrieval.documents.2.document.content": "<document-chunk-3>",
"retrieval.documents.2.document.metadata": "{\"page_label\": \"4\", \"file_name\": \"/data/101.pdf\", \"file_path\": \"/data/101.pdf\", \"file_type\": \"application/pdf\", \"file_size\": 47931, \"creation_date\": \"2024-04-12\", \"last_modified_date\": \"2024-04-12\"}"
},
"events": [],
"links": [],
"resource": {
"attributes": {},
"schema_url": ""
}
}



Build multi-agent workflows with OpenAI Agents
OpenAI-Agents is a lightweight Python library for building agentic AI apps. It includes a few abstractions:
Agents, which are LLMs equipped with instructions and tools
Handoffs, which allow agents to delegate to other agents for specific tasks
Guardrails, which enable the inputs to agents to be validated
This guide outlines common agent workflows using this SDK. We will walk through building an investment agent across several use cases.
from agents import Agent, Runner, WebSearchTool
agent = Agent(
name="Finance Agent",
instructions="You are a finance agent that can answer questions about stocks. Use web search to retrieve up‑to‑date context. Then, return a brief, concise answer that is one sentence long.",
tools=[WebSearchTool()],
model="gpt-4.1-mini",
)Model support
First class support for OpenAI LLMs, and basic support for any LLM using a LiteLLM wrapper. Support for reasoning effort parameter to tradeoff on reducing latency or increasing accuracy.
Structured outputs
First-class support with OpenAI LLMs. LLMs that do not support json_schema as a parameter are .
Tools
Very easy, using the @function_call decorator. Support for parallel tool calls to reduce latency. Built-in support for OpenAI SDK for WebSearchTool, ComputerTool, and FileSearchTool
Agent handoff
Very easy using handoffs variable
Multimodal support
Voice support, no support for images or video
Guardrails
Enables validation of both inputs and outputs
Retry logic
⚠️ No retry logic, developers must manually handle failure cases
Memory
⚠️ No built-in memory management. Developers must manage their own conversation and user memory.
Code execution
⚠️ No built-in support for executing code
An LLM agent with access to tools to accomplish a task is the most basic flow. This agent answers questions about stocks and uses OpenAI web search to get real time information.
from agents import Agent, Runner, WebSearchTool
agent = Agent(
name="Finance Agent",
instructions="You are a finance agent that can answer questions about stocks. Use web search to retrieve up‑to‑date context. Then, return a brief, concise answer that is one sentence long.",
tools=[WebSearchTool()],
model="gpt-4.1-mini",
)This agent builds a portfolio of stocks and ETFs using multiple agents linked together:
Search Agent: Searches the web for information on particular stock tickers.
Report Agent: Creates a portfolio of stocks and ETFs that supports the user's investment strategy.
portfolio_agent = Agent(
name="Portfolio Agent",
instructions="You are a senior financial analyst. You will be provided with a stock research report. Your task is to create a portfolio of stocks and ETFs that could support the user's stated investment strategy. Include facts and data from the research report in the stated reasons for the portfolio allocation.",
model="o4-mini",
output_type=Portfolio,
)
research_agent = Agent(
name="FinancialSearchAgent",
instructions="You are a research assistant specializing in financial topics. Given an investment strategy, use web search to retrieve up‑to‑date context and produce a short summary of stocks that support the investment strategy at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst.",
model="gpt-4.1",
tools=[WebSearchTool()],
model_settings=ModelSettings(tool_choice="required", parallel_tool_calls=True),
)This agent researches stocks for you. If we want to research 5 stocks, we can force the agent to run multiple tool calls, instead of sequentially.
@function_tool
def get_stock_data(ticker_symbol: str) -> dict:
"""
Get stock data for a given ticker symbol.
Args:
ticker_symbol: The ticker symbol of the stock to get data for.
Returns:
A dictionary containing stock data such as price, market cap, and more.
"""
import yfinance as yf
stock = yf.Ticker(ticker_symbol)
return stock.info
research_agent = Agent(
name="FinancialSearchAgent",
instructions=dedent(
"""You are a research assistant specializing in financial topics. Given a stock ticker, use web search to retrieve up‑to‑date context and produce a short summary of at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst."""
),
model="gpt-4.1",
tools=[WebSearchTool(), get_stock_data_tool],
model_settings=ModelSettings(tool_choice="required", parallel_tool_calls=True),
)This agent answers questions about investing using multiple agents. A central router agent chooses which worker to use.
Research Agent: Searches the web for information about stocks and ETFs.
Question Answering Agent: Answers questions about investing like Warren Buffett.
qa_agent = Agent(
name="Investing Q&A Agent",
instructions="You are Warren Buffett. You are answering questions about investing.",
model="gpt-4.1",
)
research_agent = Agent(
name="Financial Search Agent",
instructions="You are a research assistant specializing in financial topics. Given a stock ticker, use web search to retrieve up‑to‑date context and produce a short summary of at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst.",
model="gpt-4.1",
tools=[WebSearchTool()],
)
orchestrator_agent = Agent(
name="Routing Agent",
instructions="You are a senior financial analyst. Your task is to handoff to the appropriate agent or tool.",
model="gpt-4.1",
handoffs=[research_agent,qa_agent],
)When creating LLM outputs, often times the first generation is unsatisfactory. You can use an agentic loop to iteratively improve the output by asking an LLM to give feedback, and then use the feedback to improve the output.
This agent pattern creates reports and evaluates itself to improve its output.
Report Agent (Generation): Creates a report on a particular stock ticker.
Evaluator Agent (Feedback): Evaluates the report and provides feedback on what to improve.
class EvaluationFeedback(BaseModel):
feedback: str = Field(
description=f"What is missing from the research report on positive and negative catalysts for a particular stock ticker. Catalysts include changes in {CATALYSTS}.")
score: Literal["pass", "needs_improvement", "fail"] = Field(
description="A score on the research report. Pass if the report is complete and contains at least 3 positive and 3 negative catalysts for the right stock ticker, needs_improvement if the report is missing some information, and fail if the report is completely wrong.")
report_agent = Agent(
name="Catalyst Report Agent",
instructions=dedent(
"""You are a research assistant specializing in stock research. Given a stock ticker, generate a report of 3 positive and 3 negative catalysts that could move the stock price in the future in 50 words or less."""
),
model="gpt-4.1",
)
evaluation_agent = Agent(
name="Evaluation Agent",
instructions=dedent(
"""You are a senior financial analyst. You will be provided with a stock research report with positive and negative catalysts. Your task is to evaluate the report and provide feedback on what to improve."""
),
model="gpt-4.1",
output_type=EvaluationFeedback,
)This is the most advanced pattern in the examples, using orchestrators and workers together. The orchestrator chooses which worker to use for a specific sub-task. The worker attempts to complete the sub-task and return a result. The orchestrator then uses the result to choose the next worker to use until a final result is returned.
In the following example, we'll build an agent which creates a portfolio of stocks and ETFs based on a user's investment strategy.
Orchestrator: Chooses which worker to use based on the user's investment strategy.
Research Agent: Searches the web for information about stocks and ETFs that could support the user's investment strategy.
Evaluation Agent: Evaluates the research report and provides feedback on what data is missing.
Portfolio Agent: Creates a portfolio of stocks and ETFs based on the research report.
evaluation_agent = Agent(
name="Evaluation Agent",
instructions=dedent(
"""You are a senior financial analyst. You will be provided with a stock research report with positive and negative catalysts. Your task is to evaluate the report and provide feedback on what to improve."""
),
model="gpt-4.1",
output_type=EvaluationFeedback,
)
portfolio_agent = Agent(
name="Portfolio Agent",
instructions=dedent(
"""You are a senior financial analyst. You will be provided with a stock research report. Your task is to create a portfolio of stocks and ETFs that could support the user's stated investment strategy. Include facts and data from the research report in the stated reasons for the portfolio allocation."""
),
model="o4-mini",
output_type=Portfolio,
)
research_agent = Agent(
name="FinancialSearchAgent",
instructions=dedent(
"""You are a research assistant specializing in financial topics. Given a stock ticker, use web search to retrieve up‑to‑date context and produce a short summary of at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst."""
),
model="gpt-4.1",
tools=[WebSearchTool()],
model_settings=ModelSettings(tool_choice="required", parallel_tool_calls=True),
)
orchestrator_agent = Agent(
name="Routing Agent",
instructions=dedent("""You are a senior financial analyst. You are trying to create a portfolio based on my stated investment strategy. Your task is to handoff to the appropriate agent or tool.
First, handoff to the research_agent to give you a report on stocks and ETFs that could support the user's stated investment strategy.
Then, handoff to the evaluation_agent to give you a score on the research report. If the evaluation_agent returns a needs_improvement or fail, continue using the research_agent to gather more information.
Once the evaluation_agent returns a pass, handoff to the portfolio_agent to create a portfolio."""),
model="gpt-4.1",
handoffs=[
research_agent,
evaluation_agent,
portfolio_agent,
],
)This uses the following structured outputs.
class PortfolioItem(BaseModel):
ticker: str = Field(description="The ticker of the stock or ETF.")
allocation: float = Field(
description="The percentage allocation of the ticker in the portfolio. The sum of all allocations should be 100."
)
reason: str = Field(description="The reason why this ticker is included in the portfolio.")
class Portfolio(BaseModel):
tickers: list[PortfolioItem] = Field(
description="A list of tickers that could support the user's stated investment strategy."
)
class EvaluationFeedback(BaseModel):
feedback: str = Field(
description="What data is missing in order to create a portfolio of stocks and ETFs based on the user's investment strategy."
)
score: Literal["pass", "needs_improvement", "fail"] = Field(
description="A score on the research report. Pass if you have at least 5 tickers with data that supports the user's investment strategy to create a portfolio, needs_improvement if you do not have enough supporting data, and fail if you have no tickers."
)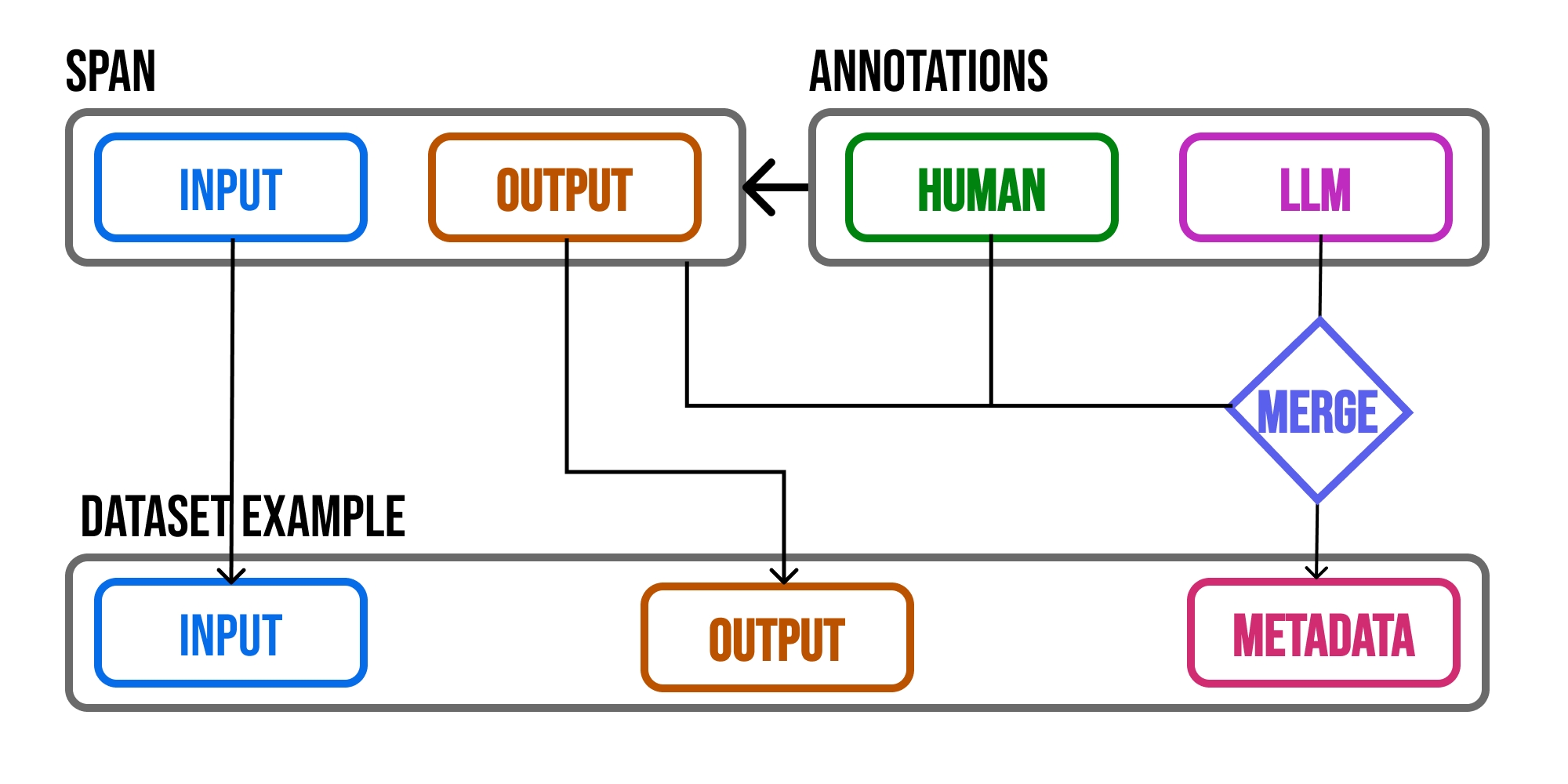
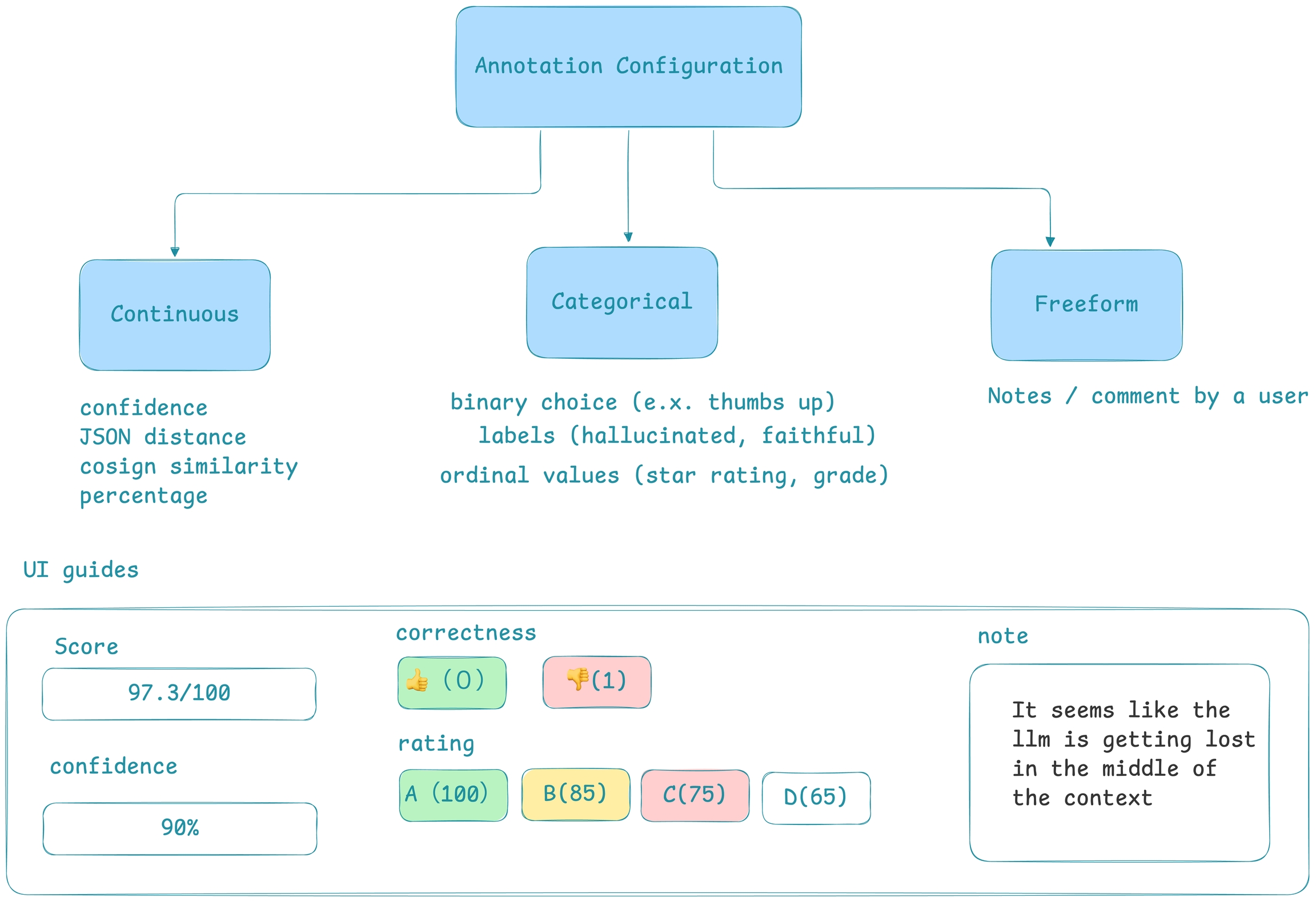
Dive into the difference between Braintrust and Phoenix open source LLM evaluation and tracing
Braintrust is an evaluation platform that serves as an alternative to Arize Phoenix. Both platforms support core AI application needs, such as: evaluating AI applications, prompt management, tracing executions, and experimentation. However, there are a few major differences.
Braintrust is a proprietary LLM-observability platform that often hits road-blocks when AI engineers need open code, friction-free self-hosting, or things like agent tracing or online evaluation. Arize Phoenix is a fully open-source alternative that fills those gaps while remaining free to run anywhere.
Top Differences (TL;DR)
Phoenix:
100% open source
Free self-hosting forever - no feature gates, no restrictions
Deploy with a single Docker container - truly "batteries included"
Your data stays on your infrastructure from day one
Braintrust:
Proprietary closed-source platform
Self-hosting locked behind paid Enterprise tier (custom pricing)
Free tier severely limited: 14-day retention, 5 users max, 1GB storage
$249/month minimum for meaningful usage ($1.50 per 1,000 scores beyond limit)
Phoenix:
Framework agnostic - works with LangChain, LlamaIndex, DSPy, custom agents, anything
Built on OpenTelemetry/OpenInference standard - no proprietary lock-in
Auto-instrumentation that just works across ecosystems
Deploy anywhere: Docker, Kubernetes, AWS, your laptop - your choice
Braintrust:
Platform-dependent approach
Requires learning their specific APIs and workflows
Limited deployment flexibility on free/Pro tiers
Forces you into their ecosystem and pricing model
Phoenix:
Unlimited evaluations - run as many as you need
Pre-built evaluators: hallucination detection, toxicity, relevance, Q&A correctness
Custom evaluators with code or natural language
Human annotation capabilities built-in
Real-time tracing with full visibility into LLM applications
Braintrust:
10,000 scores on free tier ($1.50 per 1,000 additional)
50,000 scores on Pro ($249/month) - can get expensive fast
Good evaluation features, but pay-per-use model creates cost anxiety
Enterprise features locked behind custom pricing
Phoenix deploys with one Docker command and is free/unlimited to run on-prem or in the cloud. Braintrust’s self-hosting is reserved for paid enterprise plans and uses a hybrid model: the control plane (UI, metadata DB) stays in Braintrust’s cloud while you run API and storage services (Brainstore) yourself, plus extra infra wiring (note: you still pay seat / eval / retention fees, with the free tier capped at 1M spans, 10K scores, 14 days retention).
Phoenix ships OpenInference—an OTel-compatible auto-instrumentation layer that captures every prompt, tool call and agent step with sub-second latency. Braintrust has 5 instrumentation options supported versus Arize Ax & Phoenix who have 50+ instrumentations.
Arize AX and Phoenix are the leaders in agent tracing solutions. Brainstrust does not trace agents today. Braintrust accepts OTel spans but has no auto-instrumentors or semantic conventions; most teams embed an SDK or proxy into their code, adding dev effort and potential latency.
Phoenix offers built-in and custom evaluators, “golden” datasets, and high-scale evaluation scoring (millions/day) with sampling, logs and failure debugging. Braintrust’s UI is great for prompt trials but lacks benchmarking on labeled data and has weaker online-eval debugging.
The Phoenix Evaluation library is tested against public datasets and is community supported. It is an open source tried and tested library, with millions of downloads. It has been running in production for over two years by tens of thousands of top enterprise organizations.
Phoenix and Arize AX include annotation queues that let reviewers label any trace or dataset and auto-recompute metrics. Braintrust lacks queues; “Review” mode is manual and disconnected from evals
Phoenix and AX have released extensive Agent evaluation including path evaluations, convergence evaluations and session level evaluations. The investment in research, material and technology spans over a year of work from the Arize team. Arize is the leading company thinking and working on Agent evaluation.
One of the most fundamental differences is Phoenix’s open-source nature versus Braintrust’s proprietary approach. Phoenix is fully open source, meaning teams can inspect the code, customize the platform, and self-host it on their own infrastructure without licensing fees. This openness provides transparency and control that many organizations value. In contrast, Braintrust is a closed-source platform, which limits users’ ability to customize or extend it.
Moreover, Phoenix is built on open standards like OpenTelemetry and OpenInference for trace instrumentation. From day one, Phoenix and Arize AX have embraced open standards and open standards, ensuring compatibility with a wide range of tools and preventing vendor lock-in. Braintrust relies on its own SDK/proxy approach for logging, and does not offer the same degree of open extensibility. Its proprietary design means that while it can be integrated into apps, it ties you into Braintrust’s way of operating (and can introduce an LLM proxy layer for logging that some teams see as a potential point of latency or risk).
Teams that prioritize transparency, community-driven development, and long-term flexibility often prefer an open solution like Phoenix.
Prototype & iterate fast? → Phoenix (open, free, unlimited instrumentation & evals).
Scale, governance, compliance? → Arize AX (also free to start, petabyte storage, 99.9 % SLA, HIPAA, RBAC, AI-powered analytics).
Open source
OSS
Closed source
Single Docker
Enterprise-only hybrid
LLM Evaluation Library
OSS Pipeline Library and UI
UI Centric Workflows
Open source
✅
–
❌
1-command self-host
✅
✅
❌
Free
✅
Free Tier
Free Tier
✅
✅
✅
✅
✅
❌
✅
✅
✅
✅
✅
❌
✅
✅
❌
✅
✅
✅
✅
✅
❌
🔸 built-in
✅ advanced
❌
❌
✅ full
❌
✅
✅
✅
Online evals (debuggable)
❌
✅
⚠️ limited
Coming Soon
✅
✅
❌
✅
❌
AI-powered search & analytics
❌
✅
❌
❌
✅
❌
✅
✅
⚠️ SOC-2 only
HIPAA / on-prem
–
✅
❌








Langfuse has an initially similar feature set to Arize Phoenix. Both tools support tracing, evaluation, experimentation, and prompt management, both in development and production. But on closer inspection there are a few notable differences:
While it is open-source, Langfuse locks certain key features like Prompt Playground and LLM-as-a-Judge evals behind a paywall. These same features are free in Phoenix.
Phoenix is significantly easier to self-host than Langfuse. Langfuse requires you to separately setup and link Clickhouse, Redis, and S3. Phoenix can be hosted out-of-the-box as a single docker container.
Langfuse relies on outside instrumentation libraries to generate traces. Arize maintains its own layer that operates in concert with OpenTelemetry for instrumentation.
Phoenix is backed by Arize AI. Phoenix users always have the option to graduate into Arize AX, with additional features, a customer success org, infosec team, and dedicated support. Meanwhile, Phoenix is able to focus entirely on providing the best fully open-source solution in the ecosystem.
Langfuse is open-source, but several critical features are gated behind its paid offering when self-hosting. For example:
Prompt Playground
LLM-as-a-Judge evaluations
Prompt experiments
Annotation queues
These features can be crucial for building and refining LLM systems, especially in early prototyping stages. In contrast, Arize Phoenix offers these capabilities fully open-source.
Self-hosting Langfuse requires setting up and maintaining:
A ClickHouse database for analytics
Redis for caching and background jobs
S3-compatible storage for logs and artifacts
Arize Phoenix, on the other hand, can be launched with a single Docker container. No need to stitch together external services—Phoenix is designed to be drop-in simple for both experimentation and production monitoring. This “batteries-included” philosophy makes it faster to adopt and easier to maintain.
Langfuse does not provide its own instrumentation layer—instead, it relies on developers to integrate third-party libraries to generate and send trace data.
Phoenix takes a different approach: it includes and maintains its own OpenTelemetry-compatible instrumentation layer, OpenInference.
In fact, Langfuse supports OpenInference tracing as one of its options. This means that using Langfuse requires at least one additional dependency on an instrumentation provider.
Phoenix is backed by Arize AI, the leading and best-funded AI Observability provider in the ecosystem.
Arize Phoenix is intended to be a complete LLM observability solution, however for users who do not want to self-host, or who need additional features like Custom Dashboards, Copilot, Dedicated Support, or HIPAA compliance, there is a seamless upgrade path to Arize AX.
The success of Arize means that Phoenix does not need to be heavily commercialized. It can focus entirely on providing the best open-source solution for LLM Observability & Evaluation.
Open Source
✅
✅
Tracing
✅
✅
✅
Auto-Instrumentation
✅
✅
Offline Evals
✅
✅
✅
Online Evals
✅
✅
Experimentation
✅
✅
✅
Prompt Management
✅
✅
✅
Prompt Playground
✅
✅
✅
Run Prompts on Datasets
✅
✅
Built-in Evaluators
✅
✅
✅
Agent Evaluations
✅
✅
Human Annotations
✅
✅
Custom Dashboards
✅
Workspaces
✅
Semantic Querying
✅
Copilot Assistant
✅
If you're choosing between Langfuse and Arize Phoenix, the right tool will depend on your needs. Langfuse has a polished UI and solid community momentum, but imposes friction around hosting and feature access. Arize Phoenix offers a more open, developer-friendly experience—especially for those who want a single-container solution with built-in instrumentation and evaluation tools.




{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<center>\n",
" <p style=\"text-align:center\">\n",
" <img alt=\"phoenix logo\" src=\"https://raw.githubusercontent.com/Arize-ai/phoenix-assets/9e6101d95936f4bd4d390efc9ce646dc6937fb2d/images/socal/github-large-banner-phoenix.jpg\" width=\"1000\"/>\n",
" <br>\n",
" <br>\n",
" <a href=\"https://arize.com/docs/phoenix/\">Docs</a>\n",
" |\n",
" <a href=\"https://github.com/Arize-ai/phoenix\">GitHub</a>\n",
" |\n",
" <a href=\"https://arize-ai.slack.com/join/shared_invite/zt-2w57bhem8-hq24MB6u7yE_ZF_ilOYSBw#/shared-invite/email\">Community</a>\n",
" </p>\n",
"</center>\n",
"<h1 align=\"center\">Tracing CrewAI with Arize Phoenix - Routing Workflow</h1>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%pip install -q arize-phoenix opentelemetry-sdk opentelemetry-exporter-otlp crewai crewai_tools openinference-instrumentation-crewai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5-gPdVmIndw9"
},
"source": [
"## Set up Keys and Dependencies"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note: For this colab you'll need:\n",
"\n",
"* OpenAI API key (https://openai.com/)\n",
"* Serper API key (https://serper.dev/)\n",
"* Phoenix API key (https://app.phoenix.arize.com/)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import getpass\n",
"import os\n",
"\n",
"# Prompt the user for their API keys if they haven't been set\n",
"openai_key = os.getenv(\"OPENAI_API_KEY\", \"OPENAI_API_KEY\")\n",
"serper_key = os.getenv(\"SERPER_API_KEY\", \"SERPER_API_KEY\")\n",
"\n",
"if openai_key == \"OPENAI_API_KEY\":\n",
" openai_key = getpass.getpass(\"Please enter your OPENAI_API_KEY: \")\n",
"\n",
"if serper_key == \"SERPER_API_KEY\":\n",
" serper_key = getpass.getpass(\"Please enter your SERPER_API_KEY: \")\n",
"\n",
"# Set the environment variables with the provided keys\n",
"os.environ[\"OPENAI_API_KEY\"] = openai_key\n",
"os.environ[\"SERPER_API_KEY\"] = serper_key\n",
"\n",
"if \"PHOENIX_API_KEY\" not in os.environ:\n",
" os.environ[\"PHOENIX_API_KEY\"] = getpass.getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"os.environ[\"PHOENIX_CLIENT_HEADERS\"] = f\"api_key={os.environ['PHOENIX_API_KEY']}\"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com/\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "r9X87mdGnpbc"
},
"source": [
"## Configure Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"crewai-agents\", endpoint=\"https://app.phoenix.arize.com/v1/traces\"\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vYT-EU56ni94"
},
"source": [
"# Instrument CrewAI"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from openinference.instrumentation.crewai import CrewAIInstrumentor\n",
"\n",
"CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your Working Agents"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import nest_asyncio\n",
"from crewai import Agent, Crew, Process, Task\n",
"from crewai.flow import Flow, listen, router, start\n",
"from pydantic import BaseModel\n",
"\n",
"research_analyst = Agent(\n",
" role=\"Senior Research Analyst\",\n",
" goal=\"Gather and summarize data on the requested topic.\",\n",
" backstory=\"Expert in tech market trends.\",\n",
" allow_delegation=False,\n",
")\n",
"\n",
"content_strategist = Agent(\n",
" role=\"Tech Content Strategist\",\n",
" goal=\"Craft an article outline based on provided research.\",\n",
" backstory=\"Storyteller who turns data into narratives.\",\n",
" allow_delegation=False,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From here, there are two ways to do this -- through a routing Agent or through ```@router()``` decorator in Flows (allows you to define conditional routing logic based on the output of a method)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Option 1: Define your logic for Router Agent to classify the query & run corresponding Agent"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"routerAgent = Agent(\n",
" role=\"Router\",\n",
" goal=\"Classify each query as either 'research' or 'content outline'.\",\n",
" backstory=\"Triage bot for content workflows.\",\n",
" verbose=False,\n",
")\n",
"\n",
"\n",
"def route(user_input: str, router):\n",
" router_task = Task(\n",
" description=user_input, agent=router, expected_output=\"One word: 'research' or 'content'\"\n",
" )\n",
" router_classify = Crew(\n",
" agents=[router], tasks=[router_task], process=Process.sequential, verbose=False\n",
" )\n",
" router_results = router_classify.kickoff()\n",
" return router_results\n",
"\n",
"\n",
"def type_of_task(router_results):\n",
" if isinstance(router_results, list):\n",
" result = router_results[0]\n",
" result_text = result.text if hasattr(result, \"text\") else str(result)\n",
" else:\n",
" result_text = (\n",
" router_results.text if hasattr(router_results, \"text\") else str(router_results)\n",
" )\n",
" task_type = result_text.strip().lower()\n",
"\n",
" return task_type\n",
"\n",
"\n",
"def working_agent(task_type, user_input: str):\n",
" if \"research\" in task_type:\n",
" agent = research_analyst\n",
" label = \"Research Analyst\"\n",
" else:\n",
" agent = content_strategist\n",
" label = \"Content Strategist\"\n",
"\n",
" work_task = Task(description=user_input, agent=agent, expected_output=\"Agent response\")\n",
" worker_crew = Crew(agents=[agent], tasks=[work_task], process=Process.sequential, verbose=True)\n",
" work_results = worker_crew.kickoff()\n",
" if isinstance(work_results, list):\n",
" output = work_results[0].text if hasattr(work_results[0], \"text\") else str(work_results[0])\n",
" else:\n",
" output = work_results.text if hasattr(work_results, \"text\") else str(work_results)\n",
"\n",
" print(f\"\\n=== Routed to {label} ({task_type}) ===\\n{output}\\n\")\n",
" return output"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Examples Runs"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# âââ 4) Example Runs âââââââââââââââââââââââââââââââââââââââââââââââââââââââââ\n",
"for query in [\n",
" \"Please research the latest AI safety papers.\",\n",
" \"Outline an article on AI safety trends.\",\n",
"]:\n",
" router_output = route(query, routerAgent)\n",
" task_output = type_of_task(router_output)\n",
" working_agent(task_output, query)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Option 2: Define your logic for ```@router()``` Decorator to define routing logic"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"nest_asyncio.apply()\n",
"\n",
"\n",
"# Define Flow State\n",
"class RoutingState(BaseModel):\n",
" query: str = \"\"\n",
" route: str = \"\"\n",
"\n",
"\n",
"# Define Structured Flow\n",
"class RoutingFlow(Flow[RoutingState]):\n",
" def __init__(self, query: str):\n",
" super().__init__(state=RoutingState(query=query))\n",
"\n",
" @start()\n",
" def handle_query(self):\n",
" print(f\"ð¥ Incoming Query: {self.state.query}\")\n",
"\n",
" @router(handle_query)\n",
" def decide_route(self):\n",
" if \"research\" in self.state.query.lower():\n",
" self.state.route = \"research\"\n",
" return \"research\"\n",
" else:\n",
" self.state.route = \"outline\"\n",
" return \"outline\"\n",
"\n",
" @listen(\"research\")\n",
" def run_research(self):\n",
" task = Task(\n",
" description=self.state.query,\n",
" expected_output=\"Summary of findings on AI safety\",\n",
" agent=research_analyst,\n",
" )\n",
" crew = Crew(\n",
" agents=[research_analyst], tasks=[task], process=Process.sequential, verbose=True\n",
" )\n",
" crew.kickoff()\n",
"\n",
" @listen(\"outline\")\n",
" def run_content_strategy(self):\n",
" task = Task(\n",
" description=self.state.query,\n",
" expected_output=\"An article outline about the given topic\",\n",
" agent=content_strategist,\n",
" )\n",
" crew = Crew(\n",
" agents=[content_strategist], tasks=[task], process=Process.sequential, verbose=True\n",
" )\n",
" crew.kickoff()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Examples Runs"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"queries = [\n",
" \"Please research the latest AI safety papers.\",\n",
" \"Outline an article on AI safety trends.\",\n",
"]\n",
"\n",
"for query in queries:\n",
" flow = RoutingFlow(query=query)\n",
" flow.kickoff()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fH0uVMgxpLql"
},
"source": [
"### Check your Phoenix project to view the traces and spans from your runs."
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<center>\n",
" <p style=\"text-align:center\">\n",
" <img alt=\"phoenix logo\" src=\"https://raw.githubusercontent.com/Arize-ai/phoenix-assets/9e6101d95936f4bd4d390efc9ce646dc6937fb2d/images/socal/github-large-banner-phoenix.jpg\" width=\"1000\"/>\n",
" <br>\n",
" <br>\n",
" <a href=\"https://arize.com/docs/phoenix/\">Docs</a>\n",
" |\n",
" <a href=\"https://github.com/Arize-ai/phoenix\">GitHub</a>\n",
" |\n",
" <a href=\"https://join.slack.com/t/arize-ai/shared_invite/zt-1px8dcmlf-fmThhDFD_V_48oU7ALan4Q\">Community</a>\n",
" </p>\n",
"</center>\n",
"<h1 align=\"center\">Tracing CrewAI with Arize Phoenix - Parallelization Workflow</h1>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!pip install -q arize-phoenix opentelemetry-sdk opentelemetry-exporter-otlp crewai crewai_tools openinference-instrumentation-crewai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5-gPdVmIndw9"
},
"source": [
"# Set up Keys and Dependencies"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note: For this colab you'll need:\n",
"\n",
"* OpenAI API key (https://openai.com/)\n",
"* Serper API key (https://serper.dev/)\n",
"* Phoenix API key (https://app.phoenix.arize.com/)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import getpass\n",
"import os\n",
"\n",
"# Prompt the user for their API keys if they haven't been set\n",
"openai_key = os.getenv(\"OPENAI_API_KEY\", \"OPENAI_API_KEY\")\n",
"serper_key = os.getenv(\"SERPER_API_KEY\", \"SERPER_API_KEY\")\n",
"\n",
"if openai_key == \"OPENAI_API_KEY\":\n",
" openai_key = getpass.getpass(\"Please enter your OPENAI_API_KEY: \")\n",
"\n",
"if serper_key == \"SERPER_API_KEY\":\n",
" serper_key = getpass.getpass(\"Please enter your SERPER_API_KEY: \")\n",
"\n",
"# Set the environment variables with the provided keys\n",
"os.environ[\"OPENAI_API_KEY\"] = openai_key\n",
"os.environ[\"SERPER_API_KEY\"] = serper_key\n",
"\n",
"if \"PHOENIX_API_KEY\" not in os.environ:\n",
" os.environ[\"PHOENIX_API_KEY\"] = getpass.getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"os.environ[\"PHOENIX_CLIENT_HEADERS\"] = f\"api_key={os.environ['PHOENIX_API_KEY']}\"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com/\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "r9X87mdGnpbc"
},
"source": [
"## Configure Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"crewai-agents\", endpoint=\"https://app.phoenix.arize.com/v1/traces\"\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vYT-EU56ni94"
},
"source": [
"# Instrument CrewAI"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from openinference.instrumentation.crewai import CrewAIInstrumentor\n",
"\n",
"CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your Agents"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from crewai import Agent, Crew, Task\n",
"from crewai.process import Process\n",
"\n",
"researcher_1 = Agent(\n",
" role=\"LLM Researcher A\",\n",
" goal=\"Research trend #1 in AI and summarize it clearly.\",\n",
" backstory=\"Specializes in model safety and governance.\",\n",
" verbose=True,\n",
")\n",
"\n",
"researcher_2 = Agent(\n",
" role=\"LLM Researcher B\",\n",
" goal=\"Research trend #2 in AI and summarize it clearly.\",\n",
" backstory=\"Expert in multimodal and frontier models.\",\n",
" verbose=True,\n",
")\n",
"\n",
"researcher_3 = Agent(\n",
" role=\"LLM Researcher C\",\n",
" goal=\"Research trend #3 in AI and summarize it clearly.\",\n",
" backstory=\"Focused on AI policy and alignment.\",\n",
" verbose=True,\n",
")\n",
"\n",
"aggregator = Agent(\n",
" role=\"Aggregator\",\n",
" goal=\"Combine and synthesize all research into a single summary report.\",\n",
" backstory=\"Information architect skilled at summarizing multiple sources.\",\n",
" verbose=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your Tasks"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Define parallel research tasks\n",
"task1 = Task(\n",
" description=\"Summarize a major trend in AI safety and model alignment.\",\n",
" expected_output=\"Concise summary of trend #1\",\n",
" agent=researcher_1,\n",
")\n",
"\n",
"task2 = Task(\n",
" description=\"Summarize a key innovation in multimodal or frontier AI systems.\",\n",
" expected_output=\"Concise summary of trend #2\",\n",
" agent=researcher_2,\n",
")\n",
"\n",
"task3 = Task(\n",
" description=\"Summarize a current topic in AI policy, regulation, or social impact.\",\n",
" expected_output=\"Concise summary of trend #3\",\n",
" agent=researcher_3,\n",
")\n",
"\n",
"# Aggregation task\n",
"aggregation_task = Task(\n",
" description=\"Combine the three AI trend summaries into a cohesive single report.\",\n",
" expected_output=\"A synthesized report capturing all three trends.\",\n",
" agent=aggregator,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Crew"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"crew = Crew(\n",
" agents=[researcher_1, researcher_2, researcher_3, aggregator],\n",
" tasks=[task1, task2, task3, aggregation_task],\n",
" process=Process.sequential,\n",
" verbose=True,\n",
")\n",
"\n",
"result = crew.kickoff()\n",
"print(result)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fH0uVMgxpLql"
},
"source": [
"### Check your Phoenix project to view the traces and spans from your runs."
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<center>\n",
" <p style=\"text-align:center\">\n",
" <img alt=\"phoenix logo\" src=\"https://raw.githubusercontent.com/Arize-ai/phoenix-assets/9e6101d95936f4bd4d390efc9ce646dc6937fb2d/images/socal/github-large-banner-phoenix.jpg\" width=\"1000\"/>\n",
" <br>\n",
" <br>\n",
" <a href=\"https://arize.com/docs/phoenix/\">Docs</a>\n",
" |\n",
" <a href=\"https://github.com/Arize-ai/phoenix\">GitHub</a>\n",
" |\n",
" <a href=\"https://arize-ai.slack.com/join/shared_invite/zt-2w57bhem8-hq24MB6u7yE_ZF_ilOYSBw#/shared-invite/email\">Community</a>\n",
" </p>\n",
"</center>\n",
"<h1 align=\"center\">Tracing CrewAI with Arize Phoenix - Orchestrator-Workers Workflow</h1>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%pip install -q arize-phoenix opentelemetry-sdk opentelemetry-exporter-otlp crewai crewai_tools openinference-instrumentation-crewai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5-gPdVmIndw9"
},
"source": [
"# Set up Keys and Dependencies"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note: For this colab you'll need:\n",
"\n",
"* OpenAI API key (https://openai.com/)\n",
"* Serper API key (https://serper.dev/)\n",
"* Phoenix API key (https://app.phoenix.arize.com/)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import getpass\n",
"import os\n",
"\n",
"# Prompt the user for their API keys if they haven't been set\n",
"openai_key = os.getenv(\"OPENAI_API_KEY\", \"OPENAI_API_KEY\")\n",
"serper_key = os.getenv(\"SERPER_API_KEY\", \"SERPER_API_KEY\")\n",
"\n",
"if openai_key == \"OPENAI_API_KEY\":\n",
" openai_key = getpass.getpass(\"Please enter your OPENAI_API_KEY: \")\n",
"\n",
"if serper_key == \"SERPER_API_KEY\":\n",
" serper_key = getpass.getpass(\"Please enter your SERPER_API_KEY: \")\n",
"\n",
"# Set the environment variables with the provided keys\n",
"os.environ[\"OPENAI_API_KEY\"] = openai_key\n",
"os.environ[\"SERPER_API_KEY\"] = serper_key\n",
"\n",
"if \"PHOENIX_API_KEY\" not in os.environ:\n",
" os.environ[\"PHOENIX_API_KEY\"] = getpass.getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"os.environ[\"PHOENIX_CLIENT_HEADERS\"] = f\"api_key={os.environ['PHOENIX_API_KEY']}\"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com/\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "r9X87mdGnpbc"
},
"source": [
"## Configure Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"crewai-agents\", endpoint=\"https://app.phoenix.arize.com/v1/traces\"\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vYT-EU56ni94"
},
"source": [
"# Instrument CrewAI"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from openinference.instrumentation.crewai import CrewAIInstrumentor\n",
"\n",
"CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your Agents"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from crewai import Agent, Crew, Task\n",
"\n",
"# Define worker agents\n",
"trend_researcher = Agent(\n",
" role=\"AI Trend Researcher\",\n",
" goal=\"Analyze current advancements in AI\",\n",
" backstory=\"Expert in tracking and analyzing new trends in artificial intelligence.\",\n",
" verbose=True,\n",
")\n",
"\n",
"policy_analyst = Agent(\n",
" role=\"AI Policy Analyst\",\n",
" goal=\"Examine the implications of AI regulations and governance\",\n",
" backstory=\"Tracks AI policy developments across governments and organizations.\",\n",
" verbose=True,\n",
")\n",
"\n",
"risk_specialist = Agent(\n",
" role=\"AI Risk Specialist\",\n",
" goal=\"Identify potential risks in frontier AI development\",\n",
" backstory=\"Focuses on safety, alignment, and misuse risks related to advanced AI.\",\n",
" verbose=True,\n",
")\n",
"\n",
"synthesizer = Agent(\n",
" role=\"Synthesis Writer\",\n",
" goal=\"Summarize all findings into a final cohesive report\",\n",
" backstory=\"Expert at compiling research insights into executive-level narratives.\",\n",
" verbose=True,\n",
")\n",
"\n",
"orchestrator = Agent(\n",
" role=\"Orchestrator\",\n",
" goal=(\n",
" \"Your job is to delegate research and writing tasks to the correct coworker using the 'Delegate work to coworker' tool.\\n\"\n",
" \"For each task you assign, you MUST call the tool with the following JSON input:\\n\\n\"\n",
" \"{\\n\"\n",
" ' \"task\": \"Short summary of the task to do (plain string)\",\\n'\n",
" ' \"context\": \"Why this task is important or part of the report (plain string)\",\\n'\n",
" ' \"coworker\": \"One of: AI Trend Researcher, AI Policy Analyst, AI Risk Specialist, Synthesis Writer\"\\n'\n",
" \"}\\n\\n\"\n",
" \"IMPORTANT:\\n\"\n",
" \"- Do NOT format 'task' or 'context' as dictionaries.\\n\"\n",
" \"- Do NOT include types or nested descriptions.\\n\"\n",
" \"- Only use plain strings for both.\\n\"\n",
" \"- Call the tool multiple times, one per coworker.\"\n",
" ),\n",
" backstory=\"You are responsible for assigning each part of an AI report to the right specialist.\",\n",
" verbose=True,\n",
" allow_delegation=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your Tasks"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Define the initial task only for the orchestrator\n",
"initial_task = Task(\n",
" description=\"Create an AI trends report. It should include recent innovations, policy updates, and safety risks. Then synthesize it into a unified summary.\",\n",
" expected_output=\"Assign subtasks via the DelegateWorkTool and return a final report.\",\n",
" agent=orchestrator,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Crew"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"crew = Crew(\n",
" agents=[trend_researcher, policy_analyst, risk_specialist, synthesizer],\n",
" tasks=[initial_task],\n",
" manager_agent=orchestrator,\n",
" verbose=True,\n",
")\n",
"# Run the full workflow\n",
"result = crew.kickoff()\n",
"print(result)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fH0uVMgxpLql"
},
"source": [
"### Check your Phoenix project to view the traces and spans from your runs."
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"<center>\n",
" <p style=\"text-align:center\">\n",
" <img alt=\"phoenix logo\" src=\"https://raw.githubusercontent.com/Arize-ai/phoenix-assets/9e6101d95936f4bd4d390efc9ce646dc6937fb2d/images/socal/github-large-banner-phoenix.jpg\" width=\"1000\"/>\n",
" <br>\n",
" <br>\n",
" <a href=\"https://arize.com/docs/phoenix/\">Docs</a>\n",
" |\n",
" <a href=\"https://github.com/Arize-ai/phoenix\">GitHub</a>\n",
" |\n",
" <a href=\"https://arize-ai.slack.com/join/shared_invite/zt-2w57bhem8-hq24MB6u7yE_ZF_ilOYSBw#/shared-invite/email\">Community</a>\n",
" </p>\n",
"</center>\n",
"<h1 align=\"center\">Tracing CrewAI with Arize Phoenix - Prompt Chaining Workflow</h1>"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%pip install -q arize-phoenix opentelemetry-sdk opentelemetry-exporter-otlp crewai crewai_tools openinference-instrumentation-crewai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5-gPdVmIndw9"
},
"source": [
"# Set up Keys and Dependencies"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note: For this colab you'll need:\n",
"\n",
"* OpenAI API key (https://openai.com/)\n",
"* Serper API key (https://serper.dev/)\n",
"* Phoenix API key (https://app.phoenix.arize.com/)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import getpass\n",
"import os\n",
"\n",
"# Prompt the user for their API keys if they haven't been set\n",
"openai_key = os.getenv(\"OPENAI_API_KEY\", \"OPENAI_API_KEY\")\n",
"serper_key = os.getenv(\"SERPER_API_KEY\", \"SERPER_API_KEY\")\n",
"\n",
"if openai_key == \"OPENAI_API_KEY\":\n",
" openai_key = getpass.getpass(\"Please enter your OPENAI_API_KEY: \")\n",
"\n",
"if serper_key == \"SERPER_API_KEY\":\n",
" serper_key = getpass.getpass(\"Please enter your SERPER_API_KEY: \")\n",
"\n",
"# Set the environment variables with the provided keys\n",
"os.environ[\"OPENAI_API_KEY\"] = openai_key\n",
"os.environ[\"SERPER_API_KEY\"] = serper_key\n",
"\n",
"if \"PHOENIX_API_KEY\" not in os.environ:\n",
" os.environ[\"PHOENIX_API_KEY\"] = getpass.getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"os.environ[\"PHOENIX_CLIENT_HEADERS\"] = f\"api_key={os.environ['PHOENIX_API_KEY']}\"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com/\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "r9X87mdGnpbc"
},
"source": [
"## Configure Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"crewai-agents\", endpoint=\"https://app.phoenix.arize.com/v1/traces\"\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vYT-EU56ni94"
},
"source": [
"# Instrument CrewAI"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from openinference.instrumentation.crewai import CrewAIInstrumentor\n",
"\n",
"CrewAIInstrumentor().instrument(skip_dep_check=True, tracer_provider=tracer_provider)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your Agents"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from crewai import Agent, Crew, Task\n",
"from crewai.process import Process\n",
"\n",
"research_analyst = Agent(\n",
" role=\"Senior Research Analyst\",\n",
" goal=\"Research cutting-edge AI topics and summarize the top 3 trends.\",\n",
" backstory=\"Expert in AI research and trend analysis.\",\n",
" verbose=True,\n",
")\n",
"\n",
"content_strategist = Agent(\n",
" role=\"Tech Content Strategist\",\n",
" goal=\"Create a structured article outline from the research.\",\n",
" backstory=\"Technical storyteller who crafts engaging outlines.\",\n",
" verbose=True,\n",
")\n",
"\n",
"content_reviewer = Agent(\n",
" role=\"Content Reviewer\",\n",
" goal=\"Validate outline for clarity, tone, and completeness.\",\n",
" backstory=\"Editorial expert with a focus on technical accuracy.\",\n",
" verbose=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your Tasks"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"research_task = Task(\n",
" description=\"Summarize the top 3 trends in open-source LLM development.\",\n",
" agent=research_analyst,\n",
" expected_output=\"Bullet points of top 3 trends with brief explanations.\",\n",
")\n",
"\n",
"outline_task = Task(\n",
" description=\"Generate an article outline for CTOs based on the research.\",\n",
" agent=content_strategist,\n",
" expected_output=\"Outline with title, sections, and key points.\",\n",
")\n",
"\n",
"review_task = Task(\n",
" description=\"Review the outline for quality and alignment.\",\n",
" agent=content_reviewer,\n",
" expected_output=\"Reviewed outline with suggestions or approval.\",\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Crew"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"crew = Crew(\n",
" agents=[research_analyst, content_strategist, content_reviewer],\n",
" tasks=[research_task, outline_task, review_task],\n",
" process=Process.sequential,\n",
" verbose=True,\n",
" full_output=True,\n",
")\n",
"\n",
"result = crew.kickoff()\n",
"print(result)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fH0uVMgxpLql"
},
"source": [
"### Check your Phoenix project to view the traces and spans from your runs."
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "SUknhuHKyc-E"
},
"source": [
"# <center>OpenAI agent pattern: evaluator optimizer agent</center>\n",
"\n",
"A starter guide for building an agent which iteratively generates an output based on LLM feedback using the `openai-agents` library.\n",
"\n",
"When creating LLM outputs, often times the first generation is unsatisfactory. You can use an agentic loop to iteratively improve the output by asking an LLM to give feedback, and then use the feedback to improve the output.\n",
"\n",
"In the following example, we'll build a financial report system using this pattern:\n",
"1. **Report Agent (Generation):** Creates a report on a particular stock ticker.\n",
"2. **Evaluator Agent (Feedback):** Evaluates the report and provides feedback on what to improve."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n69HR7eJswNt"
},
"source": [
"### Install Libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install base libraries for OpenAI\n",
"!pip install -q openai openai-agents pydantic\n",
"\n",
"# Install optional libraries for OpenInference/OpenTelemetry tracing\n",
"!pip install -q arize-phoenix-otel openinference-instrumentation-openai-agents openinference-instrumentation-openai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jQnyEnJisyn3"
},
"source": [
"### Setup Keys\n",
"\n",
"Add your OpenAI API key to the environment variable `OPENAI_API_KEY`.\n",
"\n",
"Copy your Phoenix `API_KEY` from your settings page at [app.phoenix.arize.com](https://app.phoenix.arize.com)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from getpass import getpass\n",
"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com\"\n",
"if not os.environ.get(\"PHOENIX_CLIENT_HEADERS\"):\n",
" os.environ[\"PHOENIX_CLIENT_HEADERS\"] = \"api_key=\" + getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"OPENAI_API_KEY = globals().get(\"OPENAI_API_KEY\") or getpass(\"ð Enter your OpenAI API key: \")\n",
"os.environ[\"OPENAI_API_KEY\"] = OPENAI_API_KEY"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kfid5cE99yN5"
},
"source": [
"### Setup Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"openai-agents\",\n",
" endpoint=\"https://app.phoenix.arize.com/v1/traces\",\n",
" auto_instrument=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Creating the agent\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from textwrap import dedent\n",
"from typing import Literal\n",
"\n",
"from agents import Agent, Runner, TResponseInputItem\n",
"from pydantic import BaseModel, Field\n",
"\n",
"CATALYSTS = \"\"\"topline revenue growth, margin expansion, moat expansion, free cash flow generation, usage, pricing, distribution, share buyback, dividend, new products, regulation, competition, management team, mergers, acquisitions, analyst ratings, trading volume, technical indicators, price momentum\"\"\"\n",
"\n",
"\n",
"class EvaluationFeedback(BaseModel):\n",
" feedback: str = Field(\n",
" description=f\"What is missing from the research report on positive and negative catalysts for a particular stock ticker. Catalysts include changes in {CATALYSTS}.\"\n",
" )\n",
" score: Literal[\"pass\", \"needs_improvement\", \"fail\"] = Field(\n",
" description=\"A score on the research report. Pass if the report is complete and contains at least 3 positive and 3 negative catalysts for the right stock ticker, needs_improvement if the report is missing some information, and fail if the report is completely wrong.\"\n",
" )\n",
"\n",
"\n",
"report_agent = Agent(\n",
" name=\"Catalyst Report Agent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a research assistant specializing in stock research. Given a stock ticker, generate a report of 3 positive and 3 negative catalysts that could move the stock price in the future in 50 words or less.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
")\n",
"\n",
"evaluation_agent = Agent(\n",
" name=\"Evaluation Agent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a senior financial analyst. You will be provided with a stock research report with positive and negative catalysts. Your task is to evaluate the report and provide feedback on what to improve.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
" output_type=EvaluationFeedback,\n",
")\n",
"\n",
"report_feedback = \"fail\"\n",
"input_items: list[TResponseInputItem] = [{\"content\": \"AAPL\", \"role\": \"user\"}]\n",
"\n",
"while report_feedback != \"pass\":\n",
" report = await Runner.run(report_agent, input_items)\n",
" print(\"### REPORT ###\")\n",
" print(report.final_output)\n",
" input_items = report.to_input_list()\n",
"\n",
" evaluation = await Runner.run(evaluation_agent, str(report.final_output))\n",
" evaluation_feedback = evaluation.final_output_as(EvaluationFeedback)\n",
" print(\"### EVALUATION ###\")\n",
" print(str(evaluation_feedback))\n",
" report_feedback = evaluation_feedback.score\n",
"\n",
" if report_feedback != \"pass\":\n",
" print(\"Re-running with feedback\")\n",
" input_items.append({\"content\": f\"Feedback: {evaluation_feedback.feedback}\", \"role\": \"user\"})"
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "SUknhuHKyc-E"
},
"source": [
"# <center>OpenAI agent pattern: basic agent</center>\n",
"\n",
"A starter guide for building a basic agent with tool calling using the `openai-agents` library. \n",
"\n",
"Here we've setup a basic agent that can answer questions about stocks using `web_search`. "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n69HR7eJswNt"
},
"source": [
"### Install Libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install base libraries for OpenAI\n",
"!pip install -q openai openai-agents\n",
"\n",
"# Install optional libraries for OpenInference/OpenTelemetry tracing\n",
"!pip install -q arize-phoenix-otel openinference-instrumentation-openai-agents openinference-instrumentation-openai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jQnyEnJisyn3"
},
"source": [
"### Setup Keys\n",
"\n",
"Add your OpenAI API key to the environment variable `OPENAI_API_KEY`.\n",
"\n",
"Copy your Phoenix `API_KEY` from your settings page at [app.phoenix.arize.com](https://app.phoenix.arize.com)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from getpass import getpass\n",
"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com\"\n",
"if not os.environ.get(\"PHOENIX_CLIENT_HEADERS\"):\n",
" os.environ[\"PHOENIX_CLIENT_HEADERS\"] = \"api_key=\" + getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"OPENAI_API_KEY = globals().get(\"OPENAI_API_KEY\") or getpass(\"ð Enter your OpenAI API key: \")\n",
"os.environ[\"OPENAI_API_KEY\"] = OPENAI_API_KEY"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kfid5cE99yN5"
},
"source": [
"### Setup Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"openai-agents\",\n",
" endpoint=\"https://app.phoenix.arize.com/v1/traces\",\n",
" auto_instrument=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "bLVAqLi5_KAi"
},
"source": [
"## Create your basic agent"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from agents import Agent, Runner, WebSearchTool\n",
"\n",
"agent = Agent(\n",
" name=\"Finance Agent\",\n",
" instructions=\"You are a finance agent that can answer questions about stocks. Use web search to retrieve upâtoâdate context. Then, return a brief, concise answer that is one sentence long.\",\n",
" tools=[WebSearchTool(search_context_size=\"low\")],\n",
" model=\"gpt-4.1-mini\",\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"\n",
"result = await Runner.run(agent, \"what is the latest news on Apple?\")\n",
"\n",
"# Get the final output\n",
"print(result.final_output)\n",
"\n",
"# Get the entire list of messages recorded to generate the final output\n",
"pprint(result.to_input_list())"
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "SUknhuHKyc-E"
},
"source": [
"# <center>OpenAI agent pattern: parallelization</center>\n",
"\n",
"A starter guide for building an agent with parallel LLM and tool calling using the `openai-agents` library.\n",
"\n",
"In this example, we are building a stock research agent. If we want to research 5 stocks, we can force the agent to run multiple tool calls, instead of sequentially."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n69HR7eJswNt"
},
"source": [
"### Install Libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install base libraries for OpenAI\n",
"!pip install -q openai openai-agents yfinance\n",
"\n",
"# Install optional libraries for OpenInference/OpenTelemetry tracing\n",
"!pip install -q arize-phoenix-otel openinference-instrumentation-openai-agents openinference-instrumentation-openai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jQnyEnJisyn3"
},
"source": [
"### Setup Keys\n",
"\n",
"Add your OpenAI API key to the environment variable `OPENAI_API_KEY`.\n",
"\n",
"Copy your Phoenix `API_KEY` from your settings page at [app.phoenix.arize.com](https://app.phoenix.arize.com)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from getpass import getpass\n",
"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com\"\n",
"if not os.environ.get(\"PHOENIX_CLIENT_HEADERS\"):\n",
" os.environ[\"PHOENIX_CLIENT_HEADERS\"] = \"api_key=\" + getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"OPENAI_API_KEY = globals().get(\"OPENAI_API_KEY\") or getpass(\"ð Enter your OpenAI API key: \")\n",
"os.environ[\"OPENAI_API_KEY\"] = OPENAI_API_KEY"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kfid5cE99yN5"
},
"source": [
"### Setup Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"openai-agents\",\n",
" endpoint=\"https://app.phoenix.arize.com/v1/traces\",\n",
" auto_instrument=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Creating your agent"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"\n",
"import yfinance as yf\n",
"\n",
"\n",
"def get_stock_data(ticker_symbol):\n",
" stock = yf.Ticker(ticker_symbol)\n",
" data = stock.info\n",
" return {\n",
" \"symbol\": data.get(\"symbol\"),\n",
" \"current_price\": data.get(\"currentPrice\"),\n",
" \"market_cap\": data.get(\"marketCap\"),\n",
" \"sector\": data.get(\"sector\"),\n",
" \"industry\": data.get(\"industry\"),\n",
" \"description\": data.get(\"longBusinessSummary\"),\n",
" \"trailing_pe\": data.get(\"trailingPE\"),\n",
" \"forward_pe\": data.get(\"forwardPE\"),\n",
" \"dividend_yield\": data.get(\"dividendYield\"),\n",
" \"beta\": data.get(\"beta\"),\n",
" \"fifty_two_week_high\": data.get(\"fiftyTwoWeekHigh\"),\n",
" \"fifty_two_week_low\": data.get(\"fiftyTwoWeekLow\"),\n",
" \"fifty_day_moving_average\": data.get(\"fiftyDayAverage\"),\n",
" \"two_hundred_day_moving_average\": data.get(\"twoHundredDayAverage\"),\n",
" \"recommendation_key\": data.get(\"recommendationKey\"),\n",
" \"revenue_growth\": data.get(\"revenueGrowth\"),\n",
" \"earnings_growth\": data.get(\"earningsGrowth\"),\n",
" \"profit_margins\": data.get(\"profitMargins\"),\n",
" }\n",
"\n",
"\n",
"pprint(get_stock_data(\"AAPL\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"from textwrap import dedent\n",
"\n",
"from agents import Agent, Runner, TResponseInputItem, WebSearchTool, function_tool\n",
"from agents.model_settings import ModelSettings\n",
"\n",
"\n",
"@function_tool\n",
"def get_stock_data_tool(ticker_symbol: str) -> dict:\n",
" \"\"\"\n",
" Get stock data for a given ticker symbol.\n",
" Args:\n",
" ticker_symbol: The ticker symbol of the stock to get data for.\n",
" Returns:\n",
" A dictionary containing stock data such as price, market cap, and more.\n",
" \"\"\"\n",
" return get_stock_data(ticker_symbol)\n",
"\n",
"\n",
"research_agent = Agent(\n",
" name=\"FinancialSearchAgent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a research assistant specializing in financial topics. Given a stock ticker, use web search to retrieve upâtoâdate context and produce a short summary of at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
" tools=[WebSearchTool(), get_stock_data_tool],\n",
" model_settings=ModelSettings(tool_choice=\"required\", parallel_tool_calls=True),\n",
")\n",
"\n",
"user_input = input(\"Enter the stock tickers you want to research: \")\n",
"input_items: list[TResponseInputItem] = [{\"content\": user_input, \"role\": \"user\"}]\n",
"\n",
"orchestrator = await Runner.run(research_agent, input_items)\n",
"orchestrator_output = orchestrator.final_output\n",
"pprint(orchestrator_output)"
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "SUknhuHKyc-E"
},
"source": [
"# <center>OpenAI agent pattern: prompt chaining agent</center>\n",
"\n",
"A starter guide for building an agent which chains two prompts together to generate an output using the `openai-agents` library.\n",
"\n",
"In the following example, we'll build a stock portfolio creation system using this pattern:\n",
"1. **Search Agent (Generation):** Searches the web for information on particular stock tickers.\n",
"2. **Report Agent (Generation):** Creates a portfolio of stocks and ETFs that supports the user's investment strategy."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n69HR7eJswNt"
},
"source": [
"### Install Libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install base libraries for OpenAI\n",
"!pip install -q openai openai-agents pydantic\n",
"\n",
"# Install optional libraries for OpenInference/OpenTelemetry tracing\n",
"!pip install -q arize-phoenix-otel openinference-instrumentation-openai-agents openinference-instrumentation-openai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jQnyEnJisyn3"
},
"source": [
"### Setup Keys\n",
"\n",
"Add your OpenAI API key to the environment variable `OPENAI_API_KEY`.\n",
"\n",
"Copy your Phoenix `API_KEY` from your settings page at [app.phoenix.arize.com](https://app.phoenix.arize.com)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from getpass import getpass\n",
"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com\"\n",
"if not os.environ.get(\"PHOENIX_CLIENT_HEADERS\"):\n",
" os.environ[\"PHOENIX_CLIENT_HEADERS\"] = \"api_key=\" + getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"OPENAI_API_KEY = globals().get(\"OPENAI_API_KEY\") or getpass(\"ð Enter your OpenAI API key: \")\n",
"os.environ[\"OPENAI_API_KEY\"] = OPENAI_API_KEY"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kfid5cE99yN5"
},
"source": [
"### Setup Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"openai-agents\",\n",
" endpoint=\"https://app.phoenix.arize.com/v1/traces\",\n",
" auto_instrument=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Creating the agent\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"from textwrap import dedent\n",
"\n",
"from agents import Agent, Runner, TResponseInputItem, WebSearchTool\n",
"from agents.model_settings import ModelSettings\n",
"from pydantic import BaseModel, Field\n",
"\n",
"\n",
"class PortfolioItem(BaseModel):\n",
" ticker: str = Field(description=\"The ticker of the stock or ETF.\")\n",
" allocation: float = Field(\n",
" description=\"The percentage allocation of the ticker in the portfolio. The sum of all allocations should be 100.\"\n",
" )\n",
" reason: str = Field(description=\"The reason why this ticker is included in the portfolio.\")\n",
"\n",
"\n",
"class Portfolio(BaseModel):\n",
" tickers: list[PortfolioItem] = Field(\n",
" description=\"A list of tickers that could support the user's stated investment strategy.\"\n",
" )\n",
"\n",
"\n",
"portfolio_agent = Agent(\n",
" name=\"Portfolio Agent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a senior financial analyst. You will be provided with a stock research report. Your task is to create a portfolio of stocks and ETFs that could support the user's stated investment strategy. Include facts and data from the research report in the stated reasons for the portfolio allocation.\"\"\"\n",
" ),\n",
" model=\"o4-mini\",\n",
" output_type=Portfolio,\n",
")\n",
"\n",
"research_agent = Agent(\n",
" name=\"FinancialSearchAgent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a research assistant specializing in financial topics. Given an investment strategy, use web search to retrieve upâtoâdate context and produce a short summary of stocks that support the investment strategy at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
" tools=[WebSearchTool()],\n",
" model_settings=ModelSettings(tool_choice=\"required\", parallel_tool_calls=True),\n",
")\n",
"\n",
"user_input = input(\"Enter your investment strategy: \")\n",
"input_items: list[TResponseInputItem] = [\n",
" {\"content\": f\"My investment strategy: {user_input}\", \"role\": \"user\"}\n",
"]\n",
"\n",
"\n",
"research_output = await Runner.run(research_agent, input_items)\n",
"pprint(research_output.final_output)\n",
"\n",
"input_items = research_output.to_input_list()\n",
"portfolio_output = await Runner.run(portfolio_agent, input_items)\n",
"pprint(portfolio_output.final_output)"
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "SUknhuHKyc-E"
},
"source": [
"# <center>OpenAI agent pattern: orchestrator and workers</center>\n",
"\n",
"A starter guide for building an agent loop using the `openai-agents` library.\n",
"\n",
"This pattern uses orchestators and workers. The orchestrator chooses which worker to use for a specific sub-task. The worker attempts to complete the sub-task and return a result. The orchestrator then uses the result to choose the next worker to use until a final result is returned.\n",
"\n",
"In the following example, we'll build an agent which creates a portfolio of stocks and ETFs based on a user's investment strategy.\n",
"1. **Orchestrator:** Chooses which worker to use based on the user's investment strategy.\n",
"2. **Research Agent:** Searches the web for information about stocks and ETFs that could support the user's investment strategy.\n",
"3. **Evaluation Agent:** Evaluates the research report and provides feedback on what data is missing.\n",
"4. **Portfolio Agent:** Creates a portfolio of stocks and ETFs based on the research report."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n69HR7eJswNt"
},
"source": [
"### Install Libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install base libraries for OpenAI\n",
"!pip install -q openai openai-agents\n",
"\n",
"# Install optional libraries for OpenInference/OpenTelemetry tracing\n",
"!pip install -q arize-phoenix-otel openinference-instrumentation-openai-agents openinference-instrumentation-openai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jQnyEnJisyn3"
},
"source": [
"### Setup Keys\n",
"\n",
"Add your OpenAI API key to the environment variable `OPENAI_API_KEY`.\n",
"\n",
"Copy your Phoenix `API_KEY` from your settings page at [app.phoenix.arize.com](https://app.phoenix.arize.com)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from getpass import getpass\n",
"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com\"\n",
"if not os.environ.get(\"PHOENIX_CLIENT_HEADERS\"):\n",
" os.environ[\"PHOENIX_CLIENT_HEADERS\"] = \"api_key=\" + getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"OPENAI_API_KEY = globals().get(\"OPENAI_API_KEY\") or getpass(\"ð Enter your OpenAI API key: \")\n",
"os.environ[\"OPENAI_API_KEY\"] = OPENAI_API_KEY"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kfid5cE99yN5"
},
"source": [
"### Setup Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"openai-agents\",\n",
" endpoint=\"https://app.phoenix.arize.com/v1/traces\",\n",
" auto_instrument=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Creating the agents"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"from textwrap import dedent\n",
"from typing import Literal\n",
"\n",
"from agents import Agent, Runner, TResponseInputItem, WebSearchTool\n",
"from agents.model_settings import ModelSettings\n",
"from pydantic import BaseModel, Field\n",
"\n",
"\n",
"class PortfolioItem(BaseModel):\n",
" ticker: str = Field(description=\"The ticker of the stock or ETF.\")\n",
" allocation: float = Field(\n",
" description=\"The percentage allocation of the ticker in the portfolio. The sum of all allocations should be 100.\"\n",
" )\n",
" reason: str = Field(description=\"The reason why this ticker is included in the portfolio.\")\n",
"\n",
"\n",
"class Portfolio(BaseModel):\n",
" tickers: list[PortfolioItem] = Field(\n",
" description=\"A list of tickers that could support the user's stated investment strategy.\"\n",
" )\n",
"\n",
"\n",
"class EvaluationFeedback(BaseModel):\n",
" feedback: str = Field(\n",
" description=\"What data is missing in order to create a portfolio of stocks and ETFs based on the user's investment strategy.\"\n",
" )\n",
" score: Literal[\"pass\", \"needs_improvement\", \"fail\"] = Field(\n",
" description=\"A score on the research report. Pass if you have at least 5 tickers with data that supports the user's investment strategy to create a portfolio, needs_improvement if you do not have enough supporting data, and fail if you have no tickers.\"\n",
" )\n",
"\n",
"\n",
"evaluation_agent = Agent(\n",
" name=\"Evaluation Agent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a senior financial analyst. You will be provided with a stock research report with positive and negative catalysts. Your task is to evaluate the report and provide feedback on what to improve.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
" output_type=EvaluationFeedback,\n",
")\n",
"\n",
"portfolio_agent = Agent(\n",
" name=\"Portfolio Agent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a senior financial analyst. You will be provided with a stock research report. Your task is to create a portfolio of stocks and ETFs that could support the user's stated investment strategy. Include facts and data from the research report in the stated reasons for the portfolio allocation.\"\"\"\n",
" ),\n",
" model=\"o4-mini\",\n",
" output_type=Portfolio,\n",
")\n",
"\n",
"research_agent = Agent(\n",
" name=\"FinancialSearchAgent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a research assistant specializing in financial topics. Given a stock ticker, use web search to retrieve upâtoâdate context and produce a short summary of at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
" tools=[WebSearchTool()],\n",
" model_settings=ModelSettings(tool_choice=\"required\", parallel_tool_calls=True),\n",
")\n",
"\n",
"orchestrator_agent = Agent(\n",
" name=\"Routing Agent\",\n",
" instructions=dedent(\"\"\"You are a senior financial analyst. You are trying to create a portfolio based on my stated investment strategy. Your task is to handoff to the appropriate agent or tool.\n",
"\n",
" First, handoff to the research_agent to give you a report on stocks and ETFs that could support the user's stated investment strategy.\n",
" Then, handoff to the evaluation_agent to give you a score on the research report. If the evaluation_agent returns a needs_improvement or fail, continue using the research_agent to gather more information.\n",
" Once the evaluation_agent returns a pass, handoff to the portfolio_agent to create a portfolio.\"\"\"),\n",
" model=\"gpt-4.1\",\n",
" handoffs=[\n",
" research_agent,\n",
" evaluation_agent,\n",
" portfolio_agent,\n",
" ],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_input = input(\"Enter your investment strategy: \")\n",
"input_items: list[TResponseInputItem] = [{\"content\": user_input, \"role\": \"user\"}]\n",
"\n",
"while True:\n",
" orchestrator = await Runner.run(orchestrator_agent, input_items)\n",
" orchestrator_output = orchestrator.final_output\n",
" pprint(orchestrator_output)\n",
"\n",
" input_items = orchestrator.to_input_list()\n",
" if isinstance(orchestrator_output, Portfolio):\n",
" break\n",
" print(\"Going back to orchestrator\")\n",
" # input_items.append({\"content\": f\"Keep going\", \"role\": \"user\"})\n",
"\n",
"print(\"AGENT COMPLETE\")"
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "SUknhuHKyc-E"
},
"source": [
"# <center>OpenAI agent pattern: routing</center>\n",
"\n",
"A starter guide for building an agent loop using the `openai-agents` library.\n",
"\n",
"This pattern uses routing to choose which specialized agent to use for a specific sub-task. The specialized agent attempts to complete the sub-task and return a result.\n",
"\n",
"In the following example, we'll build an agent which creates a portfolio of stocks and ETFs based on a user's investment strategy.\n",
"1. **Router Agent:** Chooses which worker to use based on the user's investment strategy.\n",
"2. **Research Agent:** Searches the web for information about stocks and ETFs that could support the user's investment strategy.\n",
"3. **Question Answering Agent:** Answers questions about investing like Warren Buffett."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "n69HR7eJswNt"
},
"source": [
"### Install Libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install base libraries for OpenAI\n",
"!pip install -q openai openai-agents\n",
"\n",
"# Install optional libraries for OpenInference/OpenTelemetry tracing\n",
"!pip install -q arize-phoenix-otel openinference-instrumentation-openai-agents openinference-instrumentation-openai"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jQnyEnJisyn3"
},
"source": [
"### Setup Keys\n",
"\n",
"Add your OpenAI API key to the environment variable `OPENAI_API_KEY`.\n",
"\n",
"Copy your Phoenix `API_KEY` from your settings page at [app.phoenix.arize.com](https://app.phoenix.arize.com)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"from getpass import getpass\n",
"\n",
"os.environ[\"PHOENIX_COLLECTOR_ENDPOINT\"] = \"https://app.phoenix.arize.com\"\n",
"if not os.environ.get(\"PHOENIX_CLIENT_HEADERS\"):\n",
" os.environ[\"PHOENIX_CLIENT_HEADERS\"] = \"api_key=\" + getpass(\"Enter your Phoenix API key: \")\n",
"\n",
"OPENAI_API_KEY = globals().get(\"OPENAI_API_KEY\") or getpass(\"ð Enter your OpenAI API key: \")\n",
"os.environ[\"OPENAI_API_KEY\"] = OPENAI_API_KEY"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kfid5cE99yN5"
},
"source": [
"### Setup Tracing"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from phoenix.otel import register\n",
"\n",
"tracer_provider = register(\n",
" project_name=\"openai-agents\",\n",
" endpoint=\"https://app.phoenix.arize.com/v1/traces\",\n",
" auto_instrument=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Creating the agents"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"from textwrap import dedent\n",
"\n",
"from agents import Agent, Runner, TResponseInputItem, WebSearchTool\n",
"from agents.model_settings import ModelSettings\n",
"\n",
"qa_agent = Agent(\n",
" name=\"Investing Q&A Agent\",\n",
" instructions=dedent(\"\"\"You are Warren Buffett. You are answering questions about investing.\"\"\"),\n",
" model=\"gpt-4.1\",\n",
")\n",
"\n",
"research_agent = Agent(\n",
" name=\"Financial Search Agent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a research assistant specializing in financial topics. Given a stock ticker, use web search to retrieve upâtoâdate context and produce a short summary of at most 50 words. Focus on key numbers, events, or quotes that will be useful to a financial analyst.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
" tools=[WebSearchTool()],\n",
" model_settings=ModelSettings(tool_choice=\"required\", parallel_tool_calls=True),\n",
")\n",
"\n",
"orchestrator_agent = Agent(\n",
" name=\"Routing Agent\",\n",
" instructions=dedent(\n",
" \"\"\"You are a senior financial analyst. Your task is to handoff to the appropriate agent or tool.\"\"\"\n",
" ),\n",
" model=\"gpt-4.1\",\n",
" handoffs=[\n",
" research_agent,\n",
" qa_agent,\n",
" ],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_items: list[TResponseInputItem] = []\n",
"\n",
"while True:\n",
" user_input = input(\"Enter your question: \")\n",
" if user_input == \"exit\":\n",
" break\n",
" input_item = {\"content\": user_input, \"role\": \"user\"}\n",
" input_items.append(input_item)\n",
" orchestrator = await Runner.run(orchestrator_agent, input_items)\n",
" orchestrator_output = orchestrator.final_output\n",
" pprint(orchestrator.last_agent)\n",
" pprint(orchestrator_output)\n",
" input_items = orchestrator.to_input_list()"
]
}
],
"metadata": {
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
}