Prompt Template
How to Run the Tool Parameter Extraction Eval
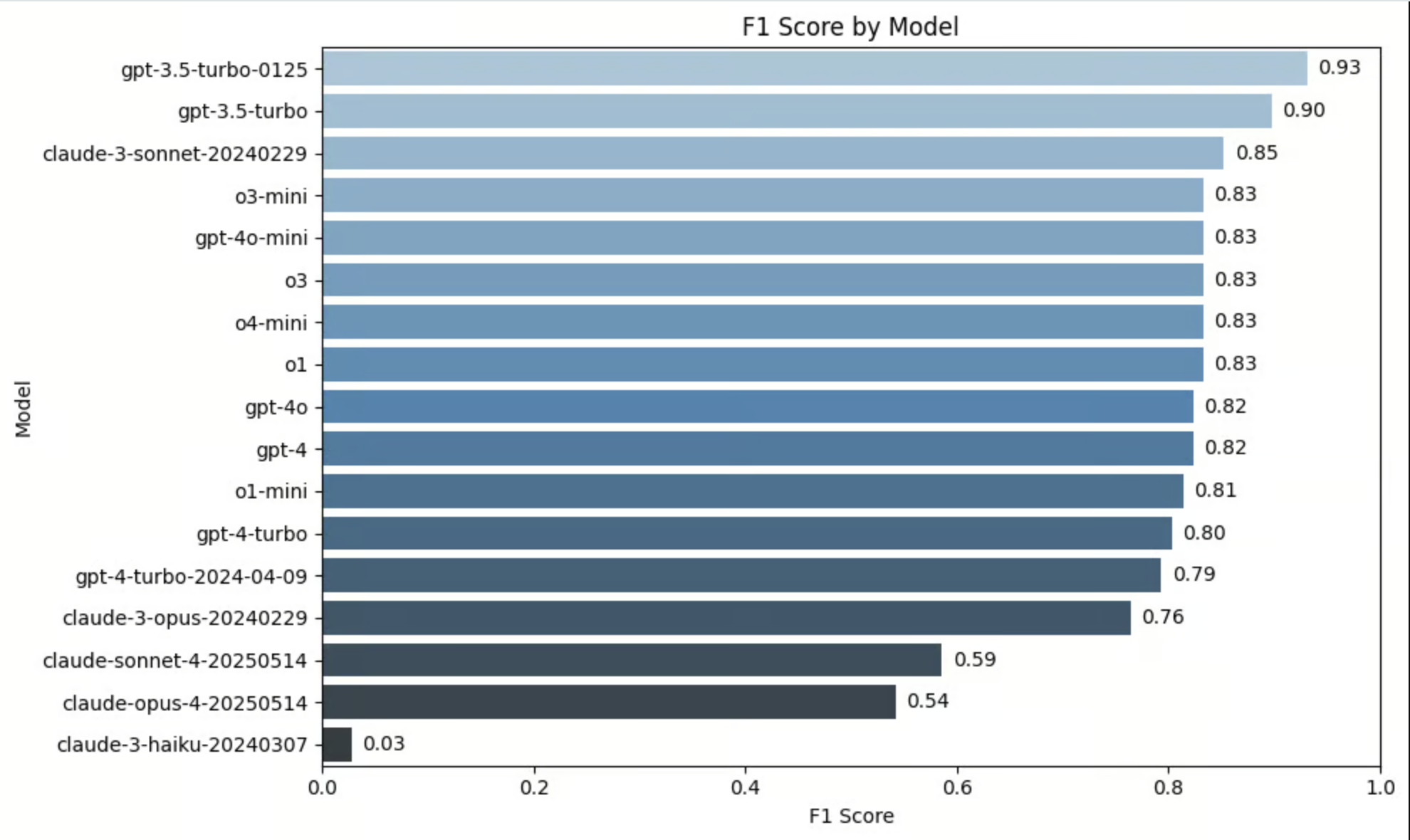
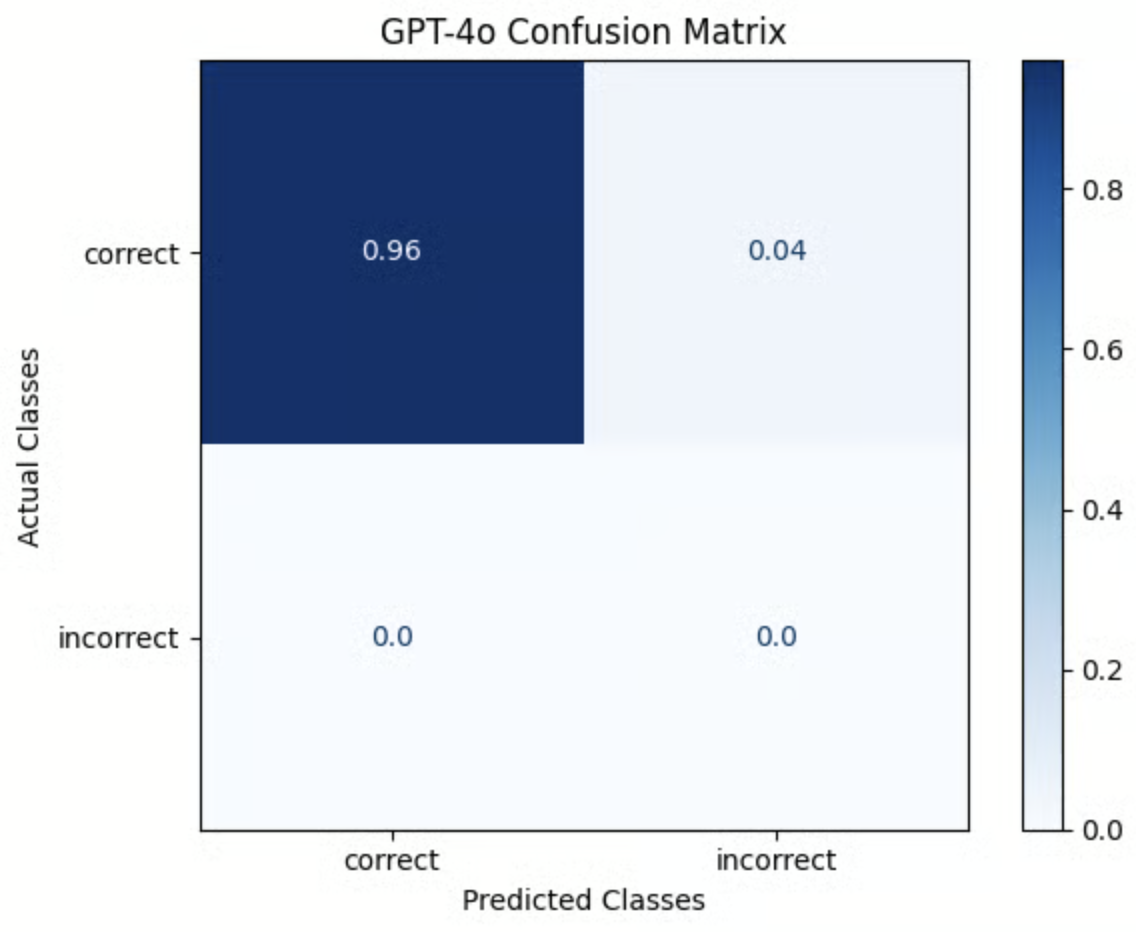
Benchmark Results
This benchmark was obtained using the notebook below. It was run using the Berkeley Function Calling Leaderboard Dataset (BFCL) as a ground truth dataset. Each example in the dataset was evaluated using theTOOL_PARAMETER_EXTRACTION_PROMPT_TEMPLATE above, then the resulting labels were compared against the ground truth label in BFCL Dataset.
Note: Some incorrect examples were added to the dataset to enhance scoring. Details on this methodology are included in the notebook.
Try it out!
Results for OpenAI and Anthropic Models