from playwright.async_api import async_playwright
import asyncio
import json
import re
from opentelemetry import trace as otel_trace
previous_context = None
async def run_browser():
async with async_playwright() as playwright:
# Launch Chromium browser
browser = await playwright.chromium.launch(headless=False, channel="chrome")
page = await browser.new_page()
await asyncio.sleep(1)
await page.goto("https://google.com/")
previous_actions = []
action_count = 0
# Get the context from the main span (defined in the previous cell)
main_context = otel_trace.set_span_in_context(main_span)
# Start execution phase span
with tracer.start_as_current_span("execution_phase", context=main_context) as execution_span:
add_graph_attributes(execution_span, "executor", "orchestrator", span_kind="CHAIN")
execution_span.set_attribute("browser.launched", True)
execution_span.set_attribute("initial_url", "https://google.com/")
try:
while True: # Infinite loop to keep session alive, press enter to continue or 'q' to quit
action_count += 1
# Get execution context
exec_context = otel_trace.set_span_in_context(execution_span)
# Start action span
with tracer.start_as_current_span(f"action_{action_count}", context=exec_context) as action_span:
add_graph_attributes(action_span, f"action_{action_count}", "executor", span_kind="CHAIN")
# Get action context
action_context = otel_trace.set_span_in_context(action_span)
# Get Context from page with tracing
with tracer.start_as_current_span("get_page_context", context=action_context) as context_span:
add_graph_attributes(context_span, "context_extractor", f"action_{action_count}", span_kind="CHAIN")
accessibility_tree = await page.accessibility.snapshot()
accessibility_tree = parse_accessibility_tree(accessibility_tree)
await page.screenshot(path="screenshot.png")
base64_image = encode_image(imagePath)
previous_context = accessibility_tree
context_span.set_attribute("page.url", page.url)
context_span.set_attribute("accessibility_tree.length", len(accessibility_tree))
# LLM decision making with tracing
with tracer.start_as_current_span("llm_decision", context=action_context) as llm_span:
add_graph_attributes(llm_span, "decision_maker", f"action_{action_count}", span_kind="LLM")
llm_span.set_attribute("llm.model", "meta-llama/Llama-4-Scout-17B-16E-Instruct")
llm_span.set_attribute("previous_actions", str(previous_actions))
response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
temperature=0.0,
messages=[
{"role": "system", "content": execution_prompt},
{"role": "system", "content": f"Few shot examples: {few_shot_examples}. Just a few examples, user will assign you VERY range set of tasks."},
{"role": "system", "content": f"Plan to execute: {steps}\n\n Accessibility Tree: {previous_context}\n\n, previous actions: {previous_actions}"},
{"role": "user", "content":
[
{
"type": "text",
"text": f'What should be the next action to accomplish the task: {task} based on the current state? Remember to review the plan and select the next action based on the current state. Provide the next action in JSON format strictly as specified above.',
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
}
},
]
}
],
)
res = response.choices[0].message.content
llm_span.set_attribute("llm.response", res)
llm_span.set_attribute("llm.usage.total_tokens", response.usage.total_tokens if hasattr(response, 'usage') else 0)
## to remove invisible characters, whitespaces and commas:
# Remove any trailing commas
res = res.rstrip(',')
# Remove any invisible characters
res = ''.join(c for c in res if ord(c) >= 32 or ord(c) == 10 or ord(c) == 13)
print('Agent response:', res)
try:
match = re.search(r'\{.*\}', res, re.DOTALL)
if match:
output = json.loads(match.group(0))
action_span.set_attribute("action.type", output.get("action", "unknown"))
action_span.set_attribute("action.reasoning", output.get("reasoning", ""))
action_span.set_attribute("action.current_state", output.get("current_state", ""))
except Exception as e:
print('Error parsing JSON:', e)
action_span.set_attribute("error", str(e))
continue
# Execute action with tracing
with tracer.start_as_current_span("execute_action", context=action_context) as exec_span:
add_graph_attributes(exec_span, "action_executor", f"action_{action_count}", span_kind="TOOL")
exec_span.set_attribute("action.type", output["action"])
if output["action"] == "navigation":
try:
exec_span.set_attribute("navigation.url", output["url"])
await page.goto(output["url"])
previous_actions.append(f"navigated to {output['url']}, SUCCESS")
exec_span.set_attribute("action.success", True)
except Exception as e:
previous_actions.append(f"Error navigating to {output['url']}: {e}")
exec_span.set_attribute("action.success", False)
exec_span.set_attribute("error", str(e))
elif output["action"] == "click":
try:
exec_span.set_attribute("click.selector", output["selector"])
selector_type, selector_name = output["selector"].split("=")[0], output["selector"].split("=")[1]
res = await page.get_by_role(selector_type, name=selector_name).first.click()
previous_actions.append(f"clicked {output['selector']}, SUCCESS")
exec_span.set_attribute("action.success", True)
except Exception as e:
previous_actions.append(f"Error clicking on {output['selector']}: {e}")
exec_span.set_attribute("action.success", False)
exec_span.set_attribute("error", str(e))
elif output["action"] == "fill" and output["selector"] == "textbox=outband_date":
try:
exec_span.set_attribute("fill.selector", output["selector"])
exec_span.set_attribute("fill.value", output["value"])
# Simulate a click to open the date picker if necessary
await page.click('button=outband_date')
await fill_date(page, 'input[name="outband_date"]', output["value"])
previous_actions.append(f"filled Departure date field with {output['value']}, SUCCESS")
exec_span.set_attribute("action.success", True)
except Exception as e:
previous_actions.append(f"Error filling Departure date field with {output['value']}: {e}")
exec_span.set_attribute("action.success", False)
exec_span.set_attribute("error", str(e))
elif output["action"] == "fill" and output["selector"] == "textbox=return_date":
try:
exec_span.set_attribute("fill.selector", output["selector"])
exec_span.set_attribute("fill.value", output["value"])
# Simulate a click to open the date picker if necessary
await page.click('button=return_date')
await fill_date(page, 'input[name="return_date"]', output["value"])
previous_actions.append(f"filled Return date field with {output['value']}, SUCCESS")
exec_span.set_attribute("action.success", True)
except Exception as e:
previous_actions.append(f"Error filling Return date field with {output['value']}: {e}")
exec_span.set_attribute("action.success", False)
exec_span.set_attribute("error", str(e))
elif output["action"] == "fill":
try:
exec_span.set_attribute("fill.selector", output["selector"])
exec_span.set_attribute("fill.value", output["value"])
selector_type, selector_name = output["selector"].split("=")[0], output["selector"].split("=")[1]
res = await page.get_by_role(selector_type, name=selector_name).fill(output["value"])
await asyncio.sleep(1)
await page.keyboard.press("Enter")
previous_actions.append(f"filled {output['selector']} with {output['value']}, SUCCESS")
exec_span.set_attribute("action.success", True)
except Exception as e:
previous_actions.append(f"Error filling {output['selector']} with {output['value']}: {e}")
exec_span.set_attribute("action.success", False)
exec_span.set_attribute("error", str(e))
elif output["action"] == "finished":
exec_span.set_attribute("task.completed", True)
exec_span.set_attribute("task.summary", output.get("summary", "Task completed"))
print(output.get("summary", "Task completed"))
break
await asyncio.sleep(1)
# Or wait for user input
user_input = input("Press 'q' to quit or Enter to continue: ")
if user_input.lower() == 'q':
break
except Exception as e:
print(f"An error occurred: {e}")
execution_span.set_attribute("error", str(e))
finally:
# Only close the browser when explicitly requested
await browser.close()
execution_span.set_attribute("browser.closed", True)
execution_span.set_attribute("total_actions", action_count)
# End the main span after execution completes
main_span.end()
execution_span.set_attribute("browser.closed", True)
execution_span.set_attribute("total_actions", action_count)
# Make sure to end main_span if it's still active
try:
await run_browser()
finally:
if main_span and not main_span.is_recording():
pass # Already ended
elif main_span:
main_span.end()
# Run the async function
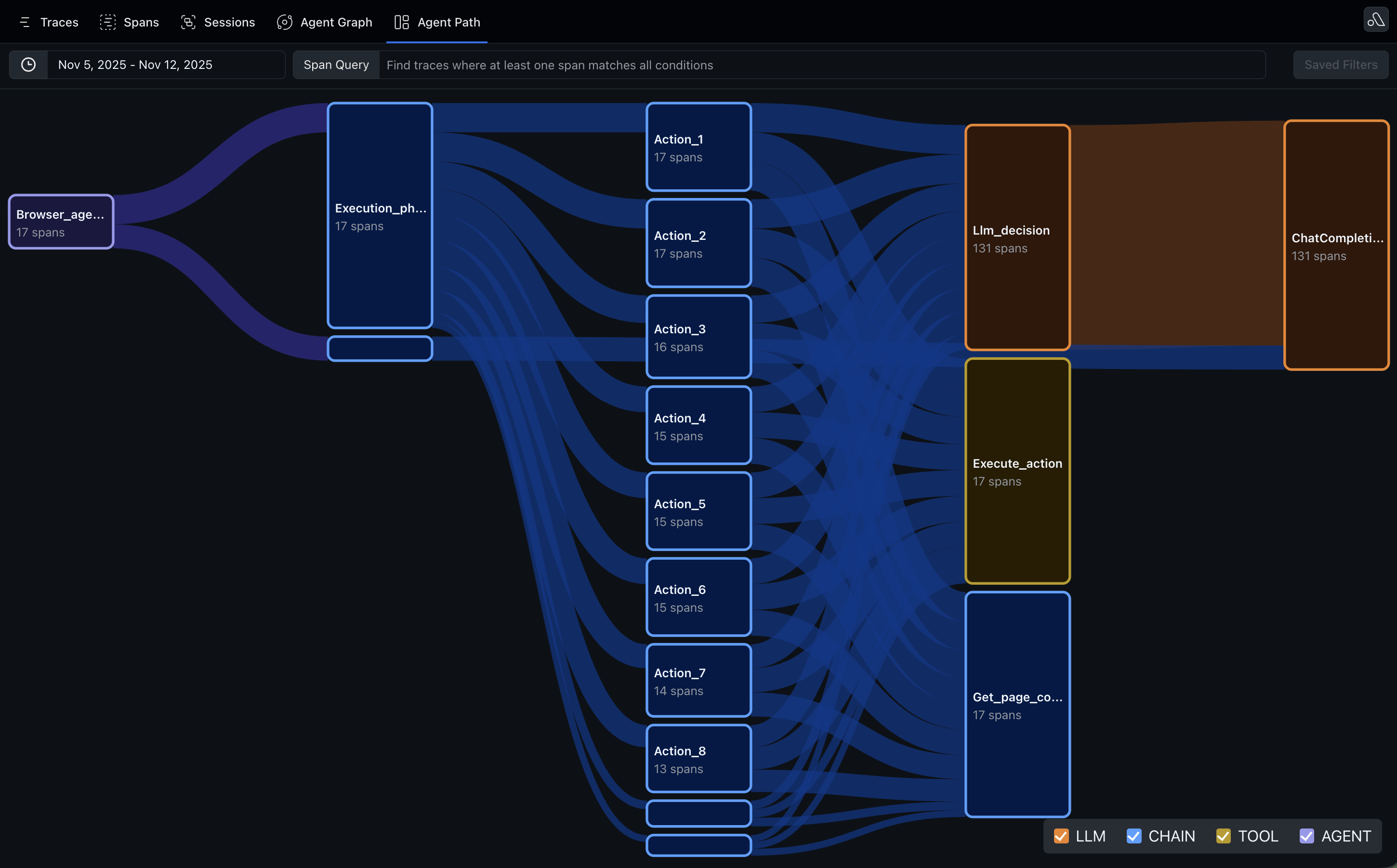
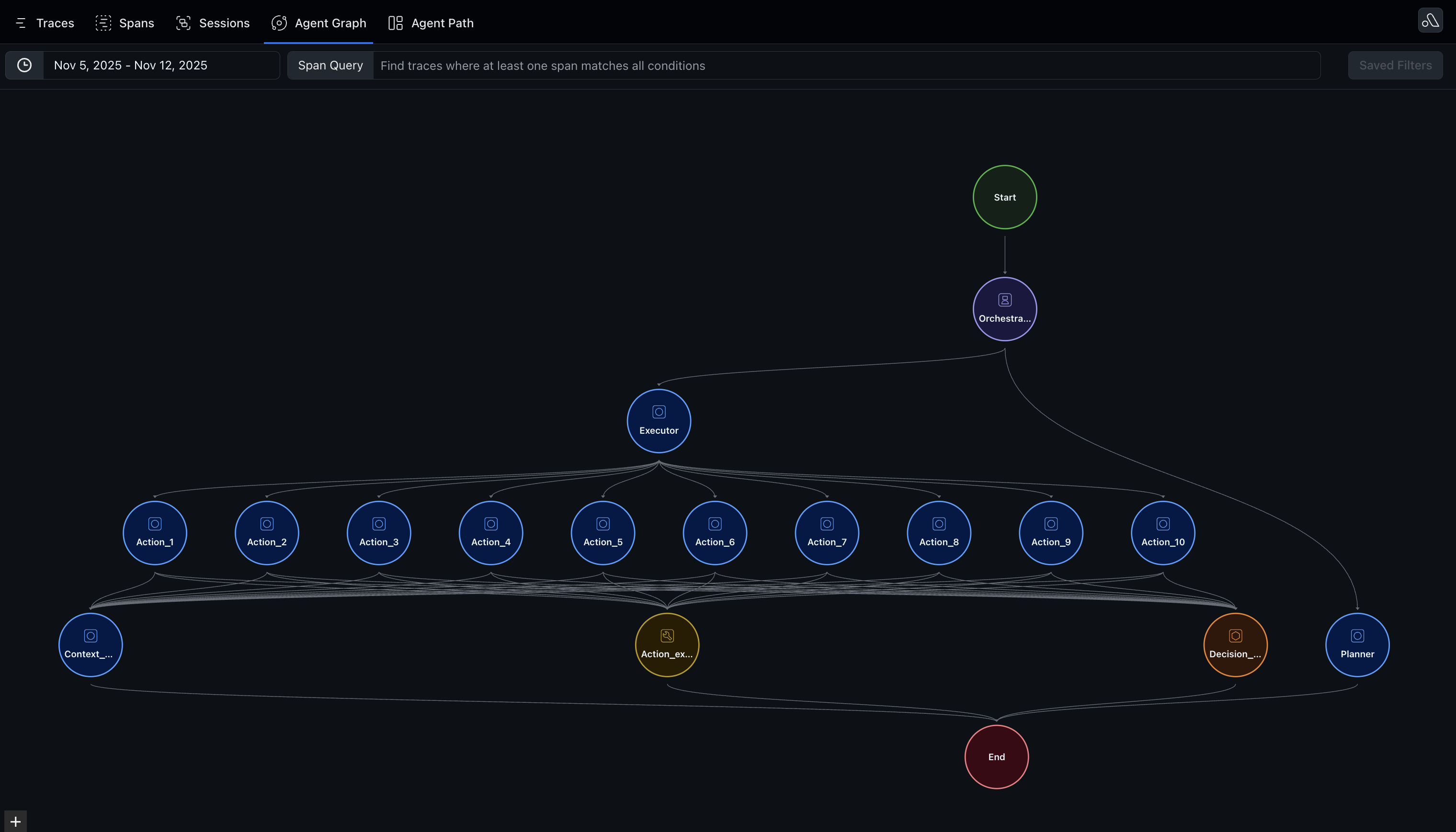 Sankey View
Sankey View