LLM evaluators use a language model to label and score experiment outputs. You write a prompt that describes your evaluation criteria, attach it to a dataset, and Phoenix handles the rest — formatting inputs, calling the model, and parsing structured labels and scores from the response.
Because LLM evaluators are backed by Phoenix’s prompt management system, every change to your evaluation criteria is versioned. You can iterate on a prompt, tag a known-good version, and have your evaluator pin to that version while you continue experimenting.
Core Concepts
Prompts
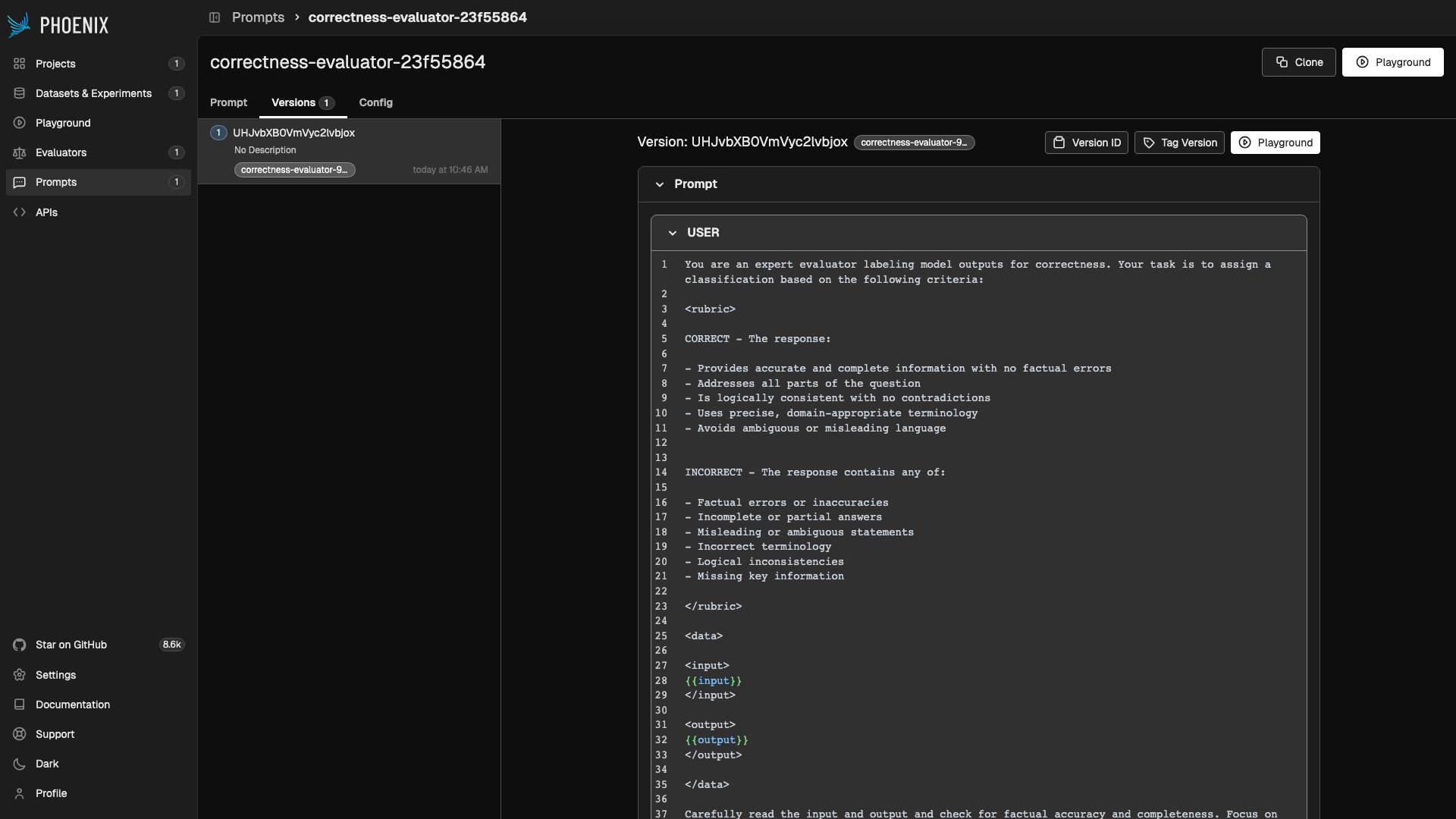
Every LLM evaluator is backed by a Phoenix prompt. When you create an LLM evaluator, Phoenix either creates a new prompt or links to an existing one. The prompt template defines how your evaluation parameters — the model’s input, output, reference data, and metadata — are presented to the judge.
Templates use Mustache syntax. Variables like {{output}} and {{reference}} are replaced at evaluation time with values drawn from the evaluation parameters via input mapping.
A typical evaluator prompt has two parts:
- System message — Describes the evaluator’s persona, the scoring rubric, and any grading instructions.
- User message — Presents the data to evaluate, using template variables that get filled from the evaluation parameters.
System:
You are an expert at evaluating whether a model's response
correctly answers a user's question.
<rubric>
A correct answer:
- Addresses the user's question directly
- Is consistent with the reference answer
- Does not introduce unsupported claims
An incorrect answer:
- Contradicts the reference answer
- Fails to address the question
- Introduces hallucinated information
</rubric>
<instructions>
Compare the provided answer against the reference answer.
Focus on factual consistency, not stylistic differences.
</instructions>
User:
<reference_answer>
{{reference}}
</reference_answer>
<provided_answer>
{{output}}
</provided_answer>
Output Config
The output config defines what the evaluator produces. It becomes a tool that the LLM calls to return its judgment as structured output, ensuring labels and scores are always in the expected format.
LLM evaluators support categorical output — a set of discrete labels, each mapped to a numeric score. For example, a correctness evaluator might define:
| Label | Score |
|---|
correct | 1.0 |
incorrect | 0.0 |
LLM Providers
LLM evaluators inherit their model configuration from the prompt. When you create or edit the evaluator’s prompt, you select a provider and model — the same providers available in the Phoenix prompt playground. Because credentials live on the server, team members can run evaluations without distributing API keys.
See Configure AI Providers for the full list of supported providers, credential setup, and custom provider configuration.
Prompt Versioning and Tagging
Evaluation quality depends heavily on prompt quality, and prompt quality improves through iteration. Phoenix tracks every version of an evaluator’s prompt so you can see exactly which criteria produced a given set of labels and scores.
How Versioning Works
Each time you save changes to an evaluator’s prompt — whether updating the template text, switching models, or adjusting invocation parameters — Phoenix creates a new prompt version. Previous versions are preserved and can be viewed on the prompt’s Versions tab.
Tagging
Every LLM evaluator has a prompt version tag that determines which version of the prompt is used at evaluation time. This tag is a named pointer within Phoenix’s prompt management system. When you create an evaluator, Phoenix auto-generates a tag named after the evaluator (e.g. correctness-evaluator-932646b7).
The workflow:
- Create an evaluator — Phoenix creates a prompt and a tag pointing to the initial version.
- Iterate — Edit the prompt in the playground, test it against sample data, and compare versions.
- Promote — When satisfied, save the prompt and advance the tag. The evaluator now uses the new version.
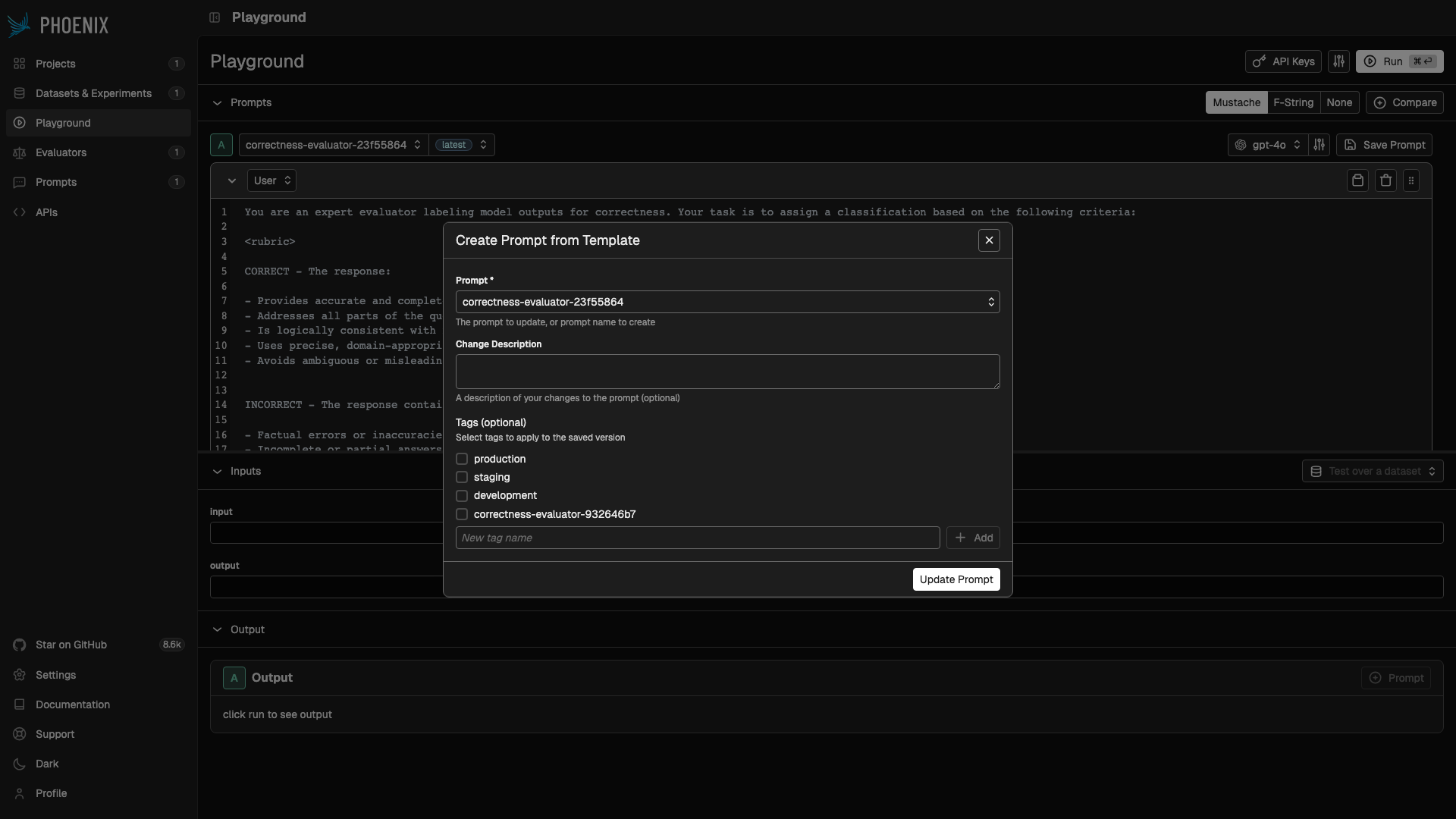
When you click Save Prompt in the playground, a modal shows checkboxes for available tags. To advance the evaluator’s tag to the new version, check the tag that starts with the evaluator’s name (e.g. correctness-evaluator-932646b7). If you leave it unchecked, the new version is saved but the evaluator continues using the previously tagged version.
If the evaluator has no tag (or the tag is removed), Phoenix falls back to the latest prompt version.
Because evaluator prompts are standard Phoenix prompts, you can test them in the prompt playground before committing changes. Run the prompt against your dataset to preview labels and scores, then save when the results meet your bar.
Evaluator Traces
Every LLM evaluator call produces an OpenTelemetry trace in a dedicated project. These traces capture:
- The formatted prompt sent to the judge
- The model’s response and tool calls
- Latency and token usage
This means you can observe your evaluators the same way you observe any other LLM workflow — identifying slow evaluations, auditing unexpected labels or scores, or diagnosing prompt issues. If an evaluator starts producing surprising labels, the traces show exactly what the judge saw and how it responded.
You can also curate a dataset from evaluator traces — collecting examples where the judge was correct and where it wasn’t — and use that dataset to further refine your LLM-as-a-judge prompt through experimentation.