



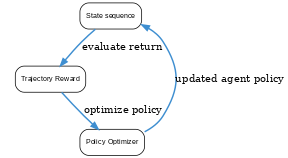
StarPO (State-Thinking-Actions-Reward Policy Optimization) is a training paradigm for LLM-based agents that optimizes entire interaction trajectories rather than stepwise decisions. Introduced as part of the RAGEN system, StarPO treats a multi-turn agent dialogue with an environment as one long sequence (state, thought, action, reward, …) and performs policy gradient updates on the sequence-level return. This allows the agent to credit assign outcomes to intermediate reasoning steps (i.e. thoughts) and handle long-horizon dependencies. StarPO can incorporate reasoning-aware rewards – such as rewarding correct chain-of-thought steps – to directly improve the agent’s internal decision-making process. By optimizing over whole trajectories with importance sampling and trajectory filtering to stabilize training, StarPO enabled emergence of more coherent multi-turn strategies in LLM agents (paper.)
Glossary of AI Terminology
What is StarPO (trajectory optimization for LLM agents)?

StarPO
Bi-weekly AI Research Paper Readings
Stay on top of emerging trends and frameworks.