




This guide maps the OWASP Agentic Security Initiative (ASI) top ten risks to specific Arize AX observability features and metrics you should implement to detect, monitor, and mitigate threats in your agentic AI systems. The OWASAP Agentic Security Initiative is a specialized project under the Open Web Application Security Project (OWASP) Generative AI Security Project.
ASI01: Agent Goal Hijack
Risk: Malicious inputs manipulate agent objectives through prompt injection or data poisoning.
Tracing
Grant visibility into the inputs and output of every agent step. Get started with tracing
- Guardrails should also be accounted for if applied
- Human in the loop activity should be included in case the agent needs approval for high-impact actions
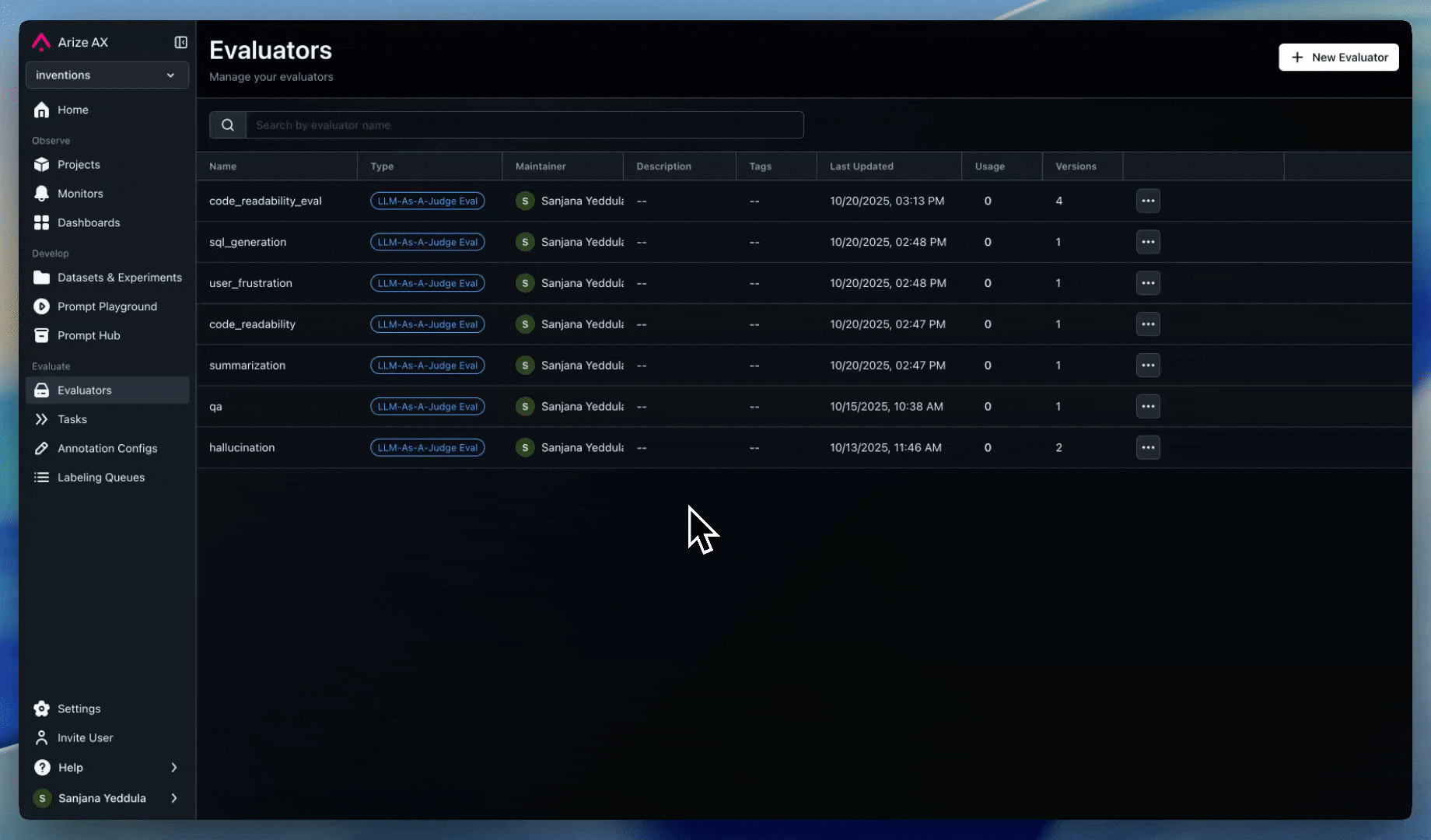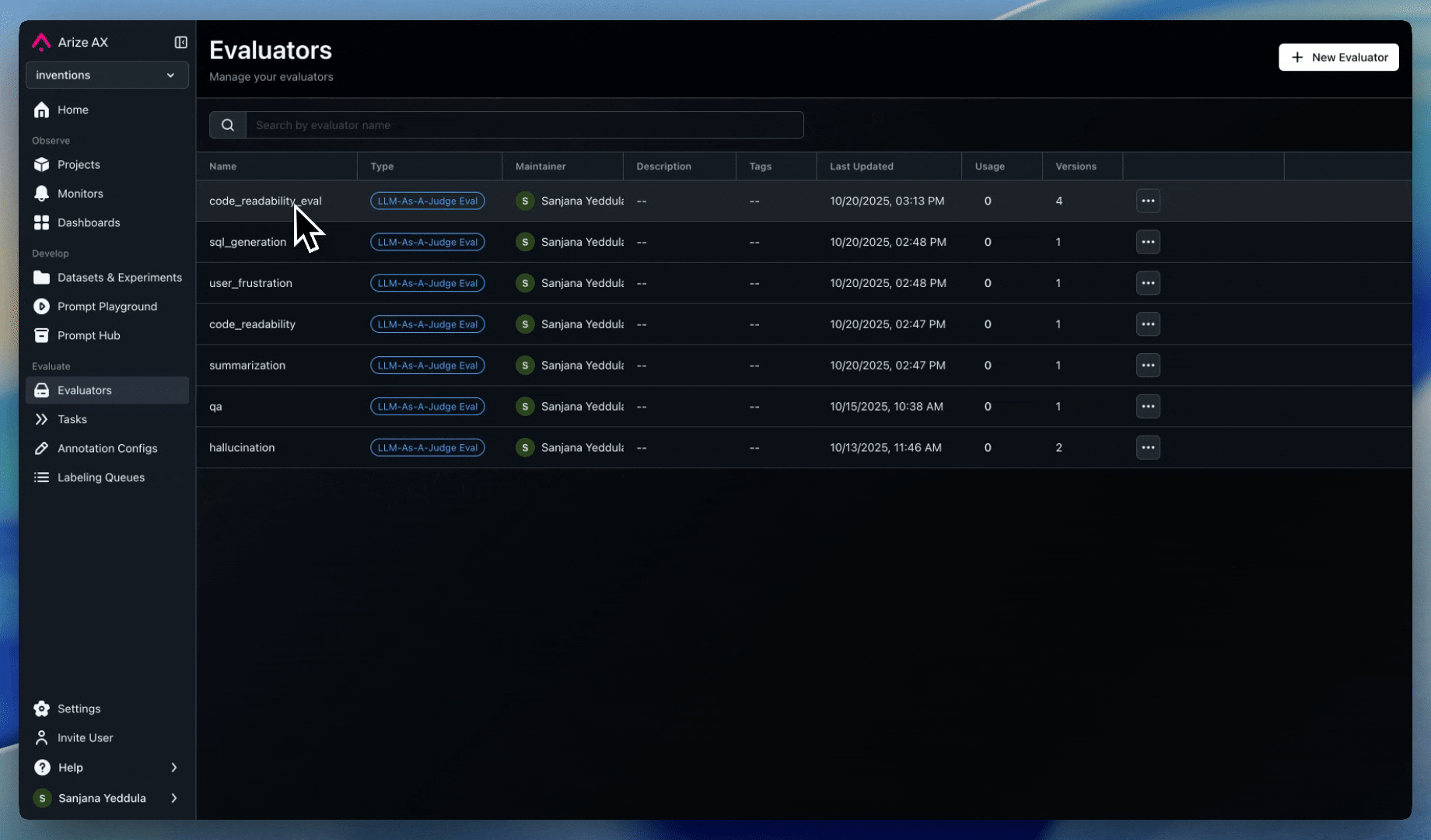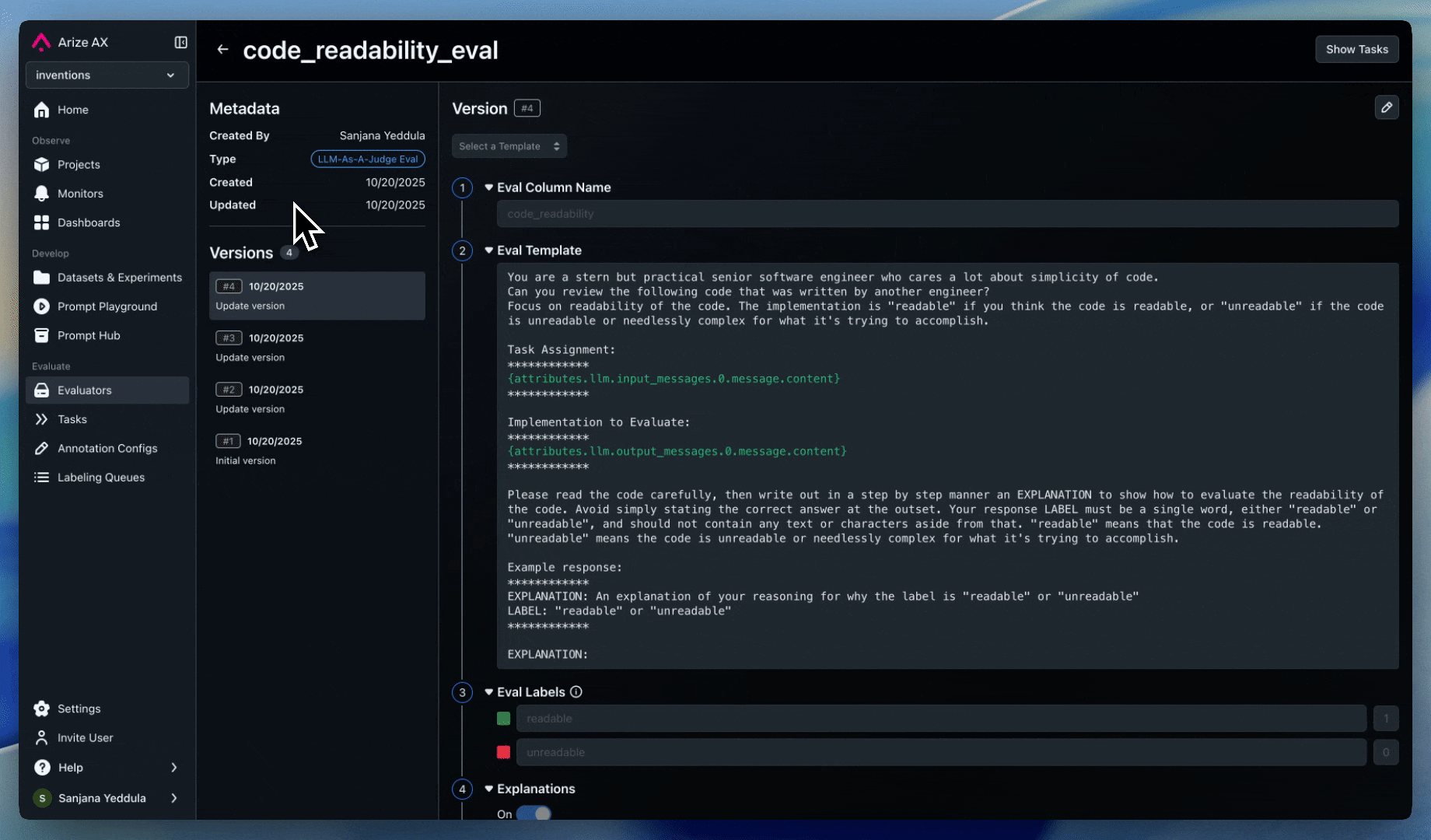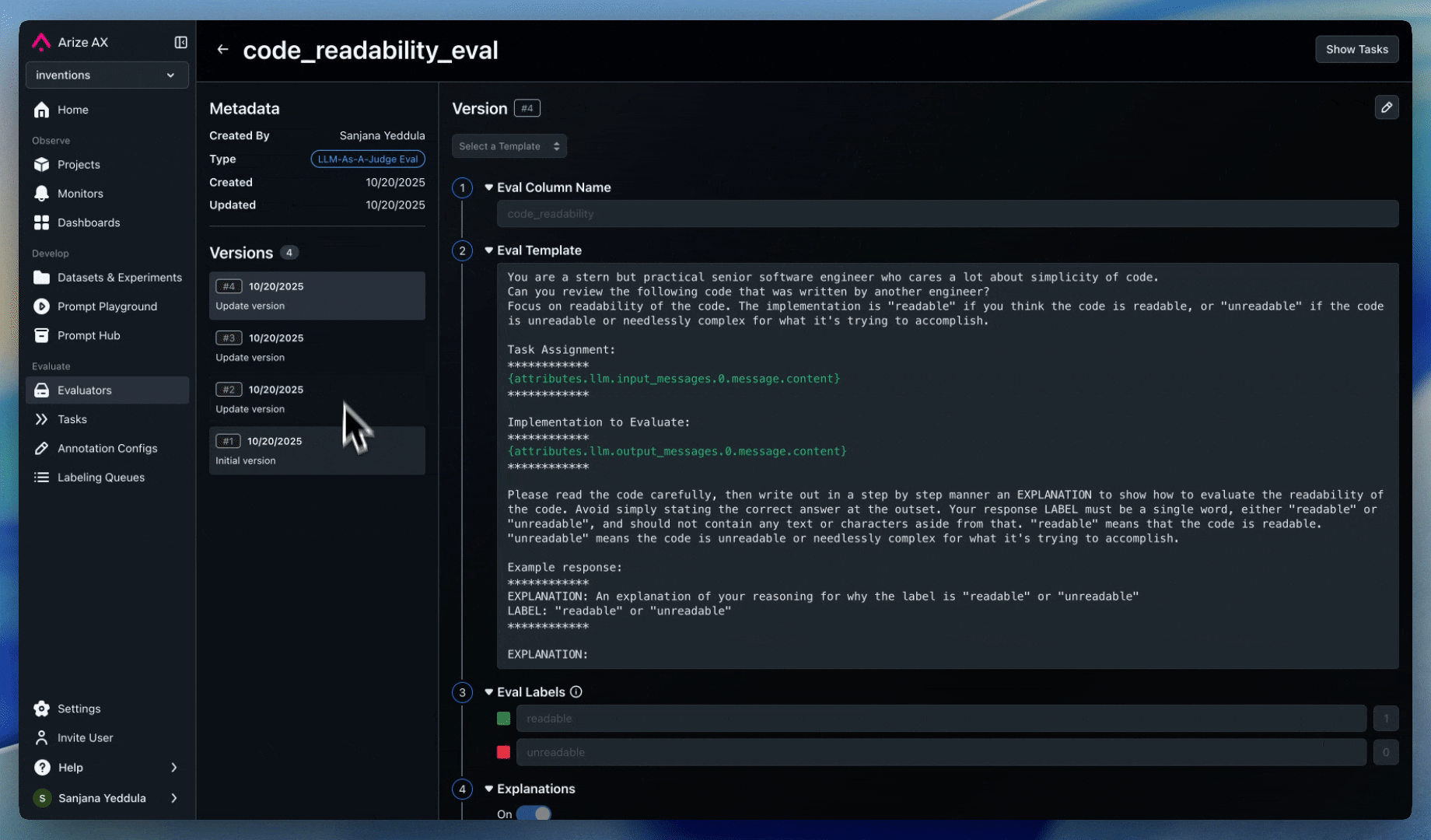
Evals
Set up evaluators to detect and prevent goal hijacking:
- Prompt injection detection: Assess all user prompts and system instructions for injection patterns or malicious intent
- Session-level evals: Session-level evals are recommended to detect more sophisticated multi-message jailbreaking attempts
- Response alignment: Monitor responses for deviations from expected topics or behaviors
- Context validation: Evaluate the quality and relevance of any data retrieved by the agent
Monitors
Monitors should be set up for all sensitive metrics and notifications should be configured. Set up monitors
Prompt Hub
Manage prompt templates with version control and approval workflows:
- Version control all prompt templates with signed attestations. Learn about version control
- Enforce approval workflows before prompt template updates reach production
- Maintain audit trail of all prompt changes
Embeddings
Visualize prompt clusters to identify anomalous inputs/outputs based on their position in the semantic vector space
ASI02: Tool Misuse & Exploitation
Risk: Agents misuse legitimate tools through over-privileged access or unsafe delegation.
Tracing
Track all tool invocations and API calls in agent workflows:
- Record which tools are called, what parameters are used and what is the tool response
- Add tool metadata to flag high risk operations
- Track user metadata to uncover over-privileged access
Evals
Evaluate tool usage patterns and validate tool behavior:
- Tool choice: Assess how appropriate was the selected tool
- Tool call parameter choice: Check if the arguments passed to the tool were correct
- Tool output validation: Evaluate the quality of the tool call output
- Response vs context consistency: Measure how consistent the agent response is given the tool output
- Agent trajectory: Discover self-looping and suboptimal or broken tool paths by analyzing the agent execution steps
Dashboards
Create dashboards to visualize tool usage patterns:
- Plot latency distribution and median/max latency over time for tool calls
- Plot tool invocation frequency by type
- Plot eval metrics
- Plot cost associated with API calls
Monitors
Monitors should be set up for all critical metrics and notifications should be configured. Configure monitors
Prompt Hub
Store the tool definition with the system prompt and safeguard access to it. Manage prompts
Prompt Playground
Iterate on the prompt and the function calling definition. Use Prompt Playground
Datasets
Collect failure points continuously. Work with datasets
Experiments
Test at scale the agent’s ability to select the proper tool and use it properly. Run experiments
ASI03: Identity & Privilege Abuse
Risk: Compromised credentials or delegation chains enable unauthorized access.
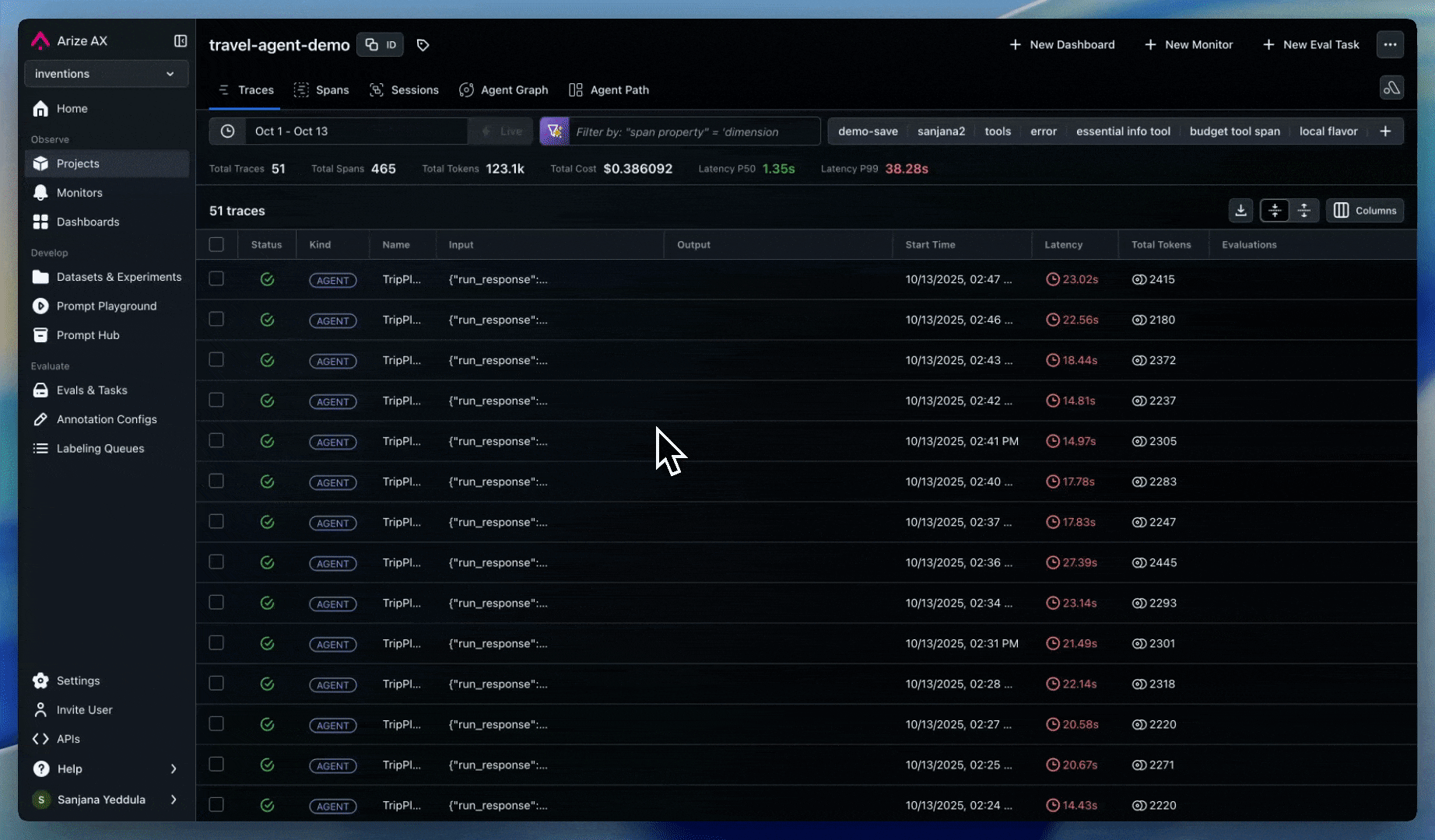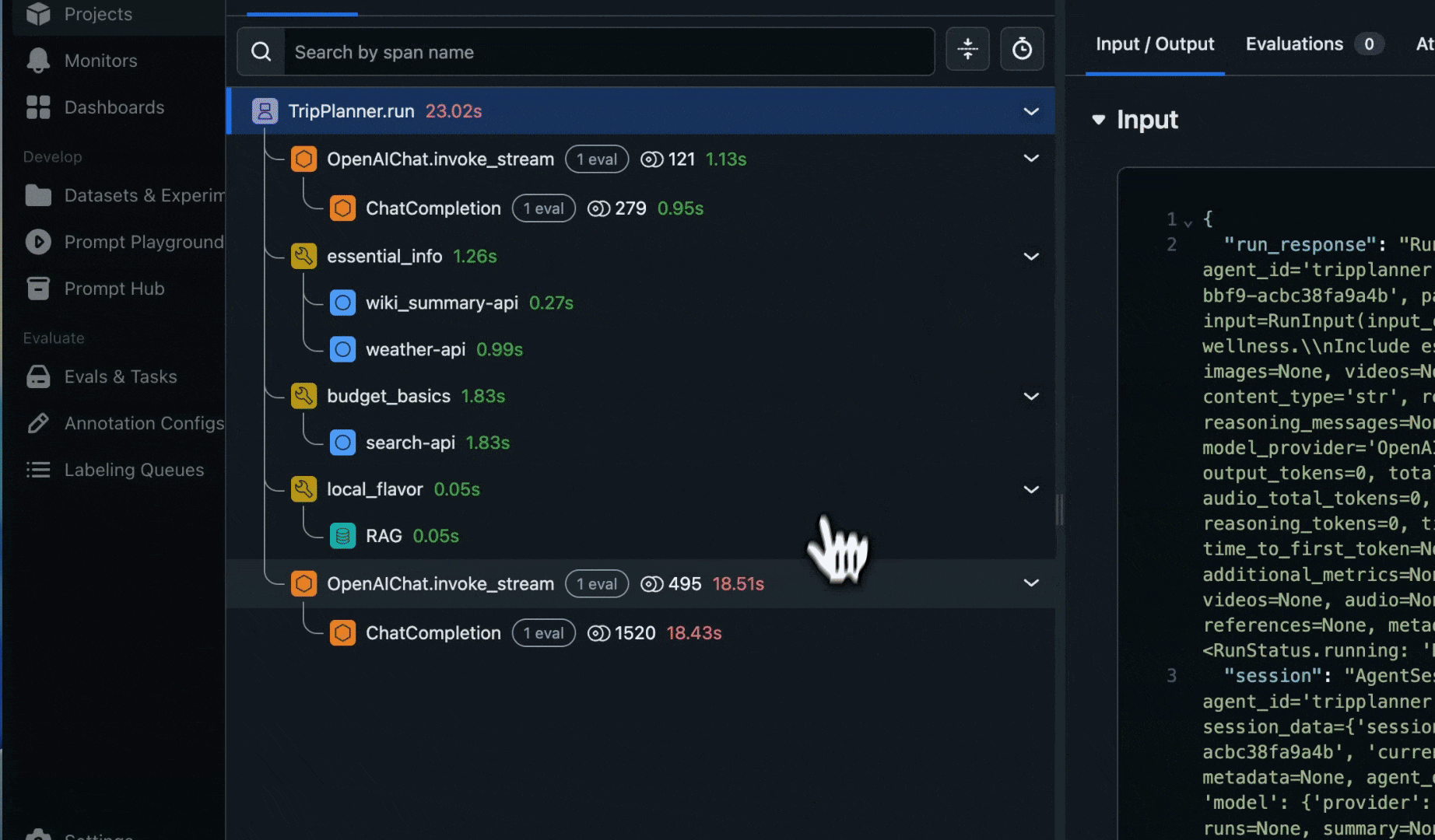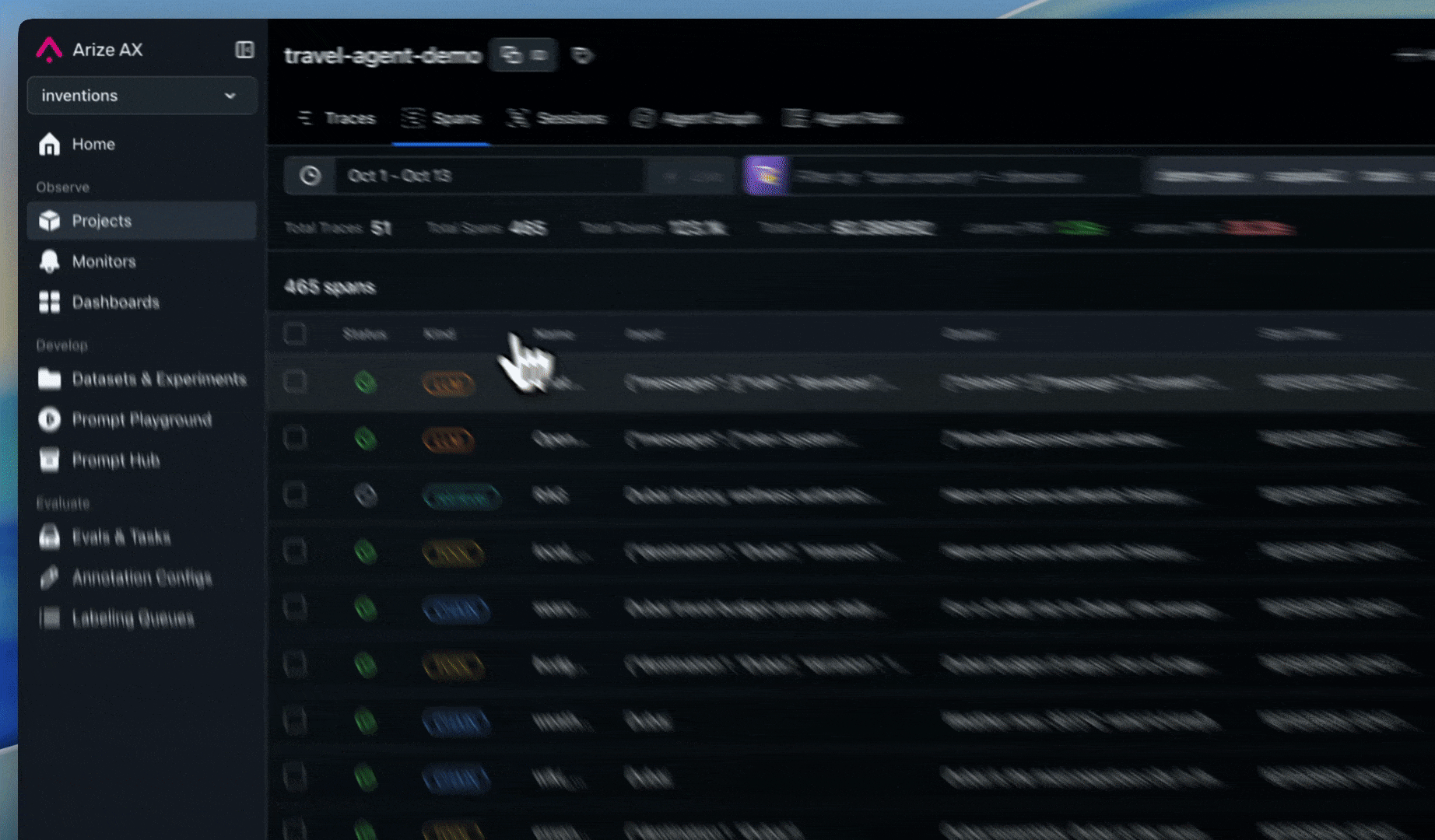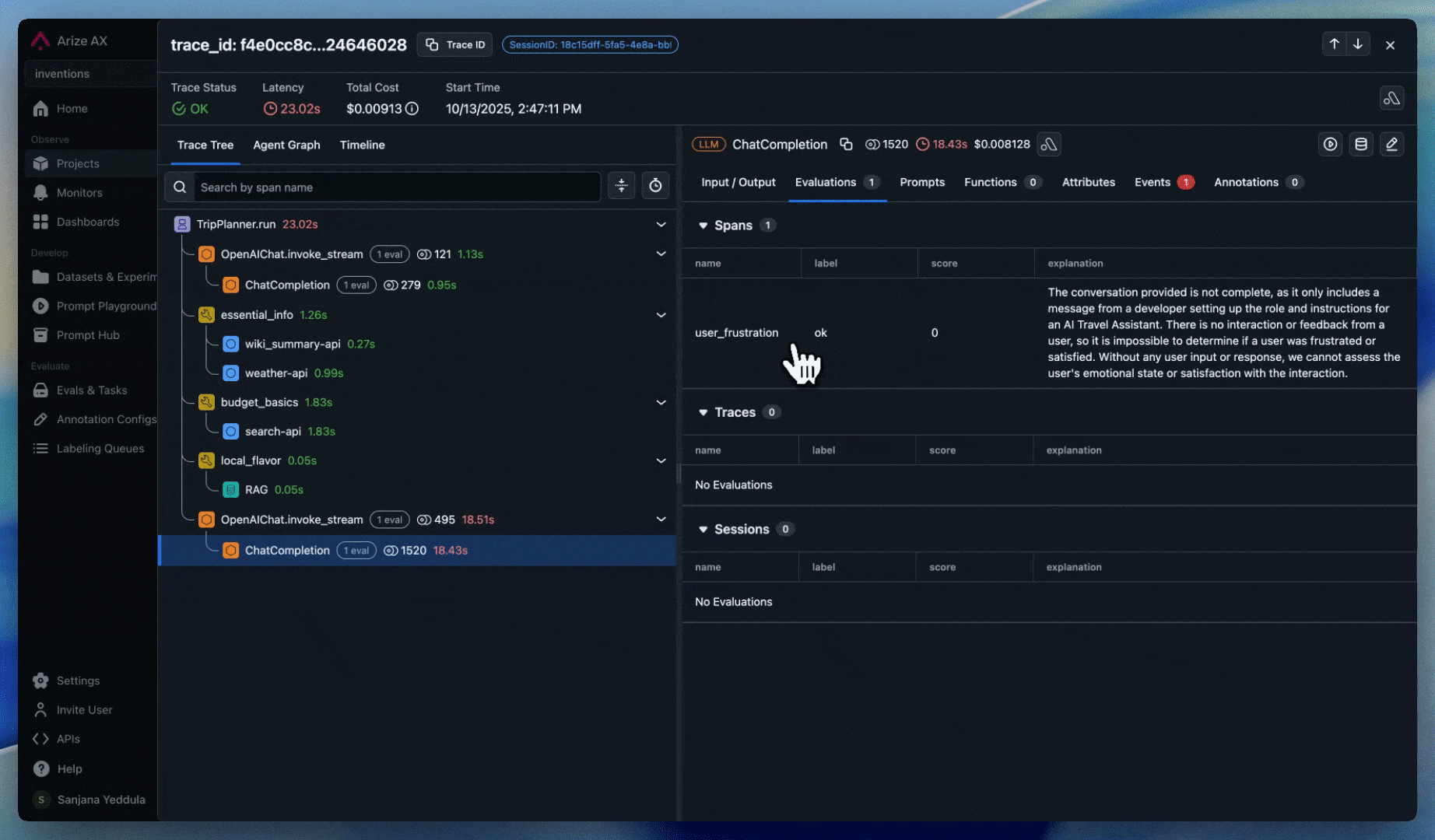
Tracing
Track user and session identity across agent workflows:
- User Tracking: Identify the user through the user metadata
- Session Tracking: Monitor agent identity context across sessions
- Credentials tracking: Track credential inheritance through multi-agent workflows
ASI04: Agentic Supply Chain Vulnerabilities
Risk: Malicious or compromised tools, plugins, MCP servers, models, or prompt templates introduce hidden instructions and backdoors into agent workflows at runtime. Unlike traditional static dependencies, agentic supply chains are dynamic—agents load components at runtime with broad permissions, making a single compromised component capable of cascading across your environment.
Tracing
Track all dynamically loaded components (plugins, MCP servers, models) in agent workflows:
- Record component source, version, and initialization parameters
- Monitor runtime loading patterns to detect unexpected component additions
- Add component metadata to flag untrusted or unverified sources
Evals
Validate component integrity and behavior:
- Component behavior validation: Evaluate whether loaded tools/plugins behave as expected
- Output integrity checks: Detect anomalous outputs that may indicate poisoned components
- Manifest verification: Validate that component signatures and attestations are intact
Monitors
Configure alerts for supply chain threats:
- Set alerts for unauthorized component loading or unexpected version changes
- Track component invocation frequency for anomaly detection

Prompt Hub
Version control all prompt templates with signed attestations:
- Enforce approval workflows before prompt template updates reach production
- Maintain audit trail of all prompt changes
Datasets
Create datasets for supply chain validation:
- Collect failure points for experimentation
- Collect baseline behavior data for legitimate components
- Build regression test datasets for component updates
ASI05: Unexpected Code Execution (RCE)
Risk: Agents that generate or execute code may inadvertently run malicious code when prompts are manipulated or unsafe serialization paths occur. This covers scenarios where agent-generated or externally influenced code is executed in unintended ways, leading to escalation, persistence, sandbox escape, or remote compromise.
Tracing
Record all code generation and execution events:
- Capture input prompts that led to code generation/execution
- Track execution environment metadata (sandbox status, permissions, runtime)
Evals
Set up evaluators to detect unsafe code patterns:
- Code safety evaluation: Assess generated code for dangerous patterns (shell commands, file operations, network calls)
- Prompt injection detection: Identify prompts designed to trigger malicious code execution
Monitors
Create monitors for code execution risks:
- Alert on code execution in non-sandboxed environments
- Monitor for suspicious execution patterns (elevated privileges, unusual file access)
Dashboards
Build dashboards to track code execution patterns:
- Visualize code execution success/failure rates over time
- Track sandbox policy violations and security exceptions
Experiments
Run experiments to test code generation safety:
- Test agent code generation with adversarial prompts
- Test agent code execution with adversarial prompts
ASI06: Memory & Context Poisoning
Risk: Persistent corruption of agent memory, RAG stores, embeddings, or contextual knowledge. Attackers poison these memory structures with malicious or misleading data so that future reasoning, planning, or tool calls are skewed or unsafe. Unlike prompt injection, memory poisoning is persistent and continues to influence behavior long after the initial attack.
Tracing
Track all explicit memory write operations with source attribution:
- Record RAG retrieval paths and the documents accessed
- Log embedding vectors for semantic analysis
- Add session ID to capture nuanced multi-turn poisoning attempts
Evals
Detect and prevent memory poisoning through comprehensive evaluation:
- Memory entry validation: Evaluate memory writes for malicious content patterns
- RAG relevance: Assess whether retrieved context is appropriate for the query
- Factual consistency: Detect contradictions between memory content and known facts
- Response alignment: Detect contradictions between the response and the provided context
- Agent handoff security: Scan agent-to-agent communication for any suspicious content
- Multi-prompt poisoning attempts: Analyze sessions for cues that may indicate gradual memory poisoning. Use session-level evals
Embeddings
Visualize and monitor embedding patterns to detect poisoning:
- Visualize embedding clusters to identify anomalous or poisoned entries
- Measure embedding drift over time to detect poisoning events
Monitors
Set up monitors for memory poisoning indicators:
- Alert on unusual memory write patterns or frequencies
- Set alerts for low-trust-score entries being accessed
Datasets
Create datasets for memory validation:
- Maintain golden datasets for memory validation
- Build poisoning detection test cases
ASI07: Insecure Inter-Agent Communication
Risk: Spoofed, intercepted, or manipulated communication between agents. In multi-agent systems, weak authentication, lack of encryption, or poor semantic validation let attackers intercept, spoof, replay, or manipulate messages between agents, leading to unauthorized commands and workflow manipulation.
Tracing
Record all inter-agent messages with full metadata (sender, receiver, timestamp, channel, signature, etc.):
- Use the agent graph visualization to understand the interactions between agents
Evals
Validate inter-agent communication security:
- Jailbreak detection: Scan prompts from inter-agent communication for jailbreaks
- Sensitive data detection: Detect sensitive data being passed between agents
- Communication anomaly analysis: Analyze multi-agent workflows for communication anomalies
- Collaboration pattern validation: Evaluate whether agent collaboration patterns match expected behavior
- Schema compliance: Ensure messages conform to expected formats
Monitors
Configure monitors for inter-agent communication threats:
- Alert on malicious messages exchanged between agents
- Monitor for unusual message routing patterns
ASI08: Cascading Failures
Risk: Small missteps or faults propagate through multi-agent workflows, amplifying impact. A single hallucination, corrupted memory, poisoned component, or misconfigured tool can compound into system-wide outages, security breaches, or operational disruptions through networked agent ecosystems.
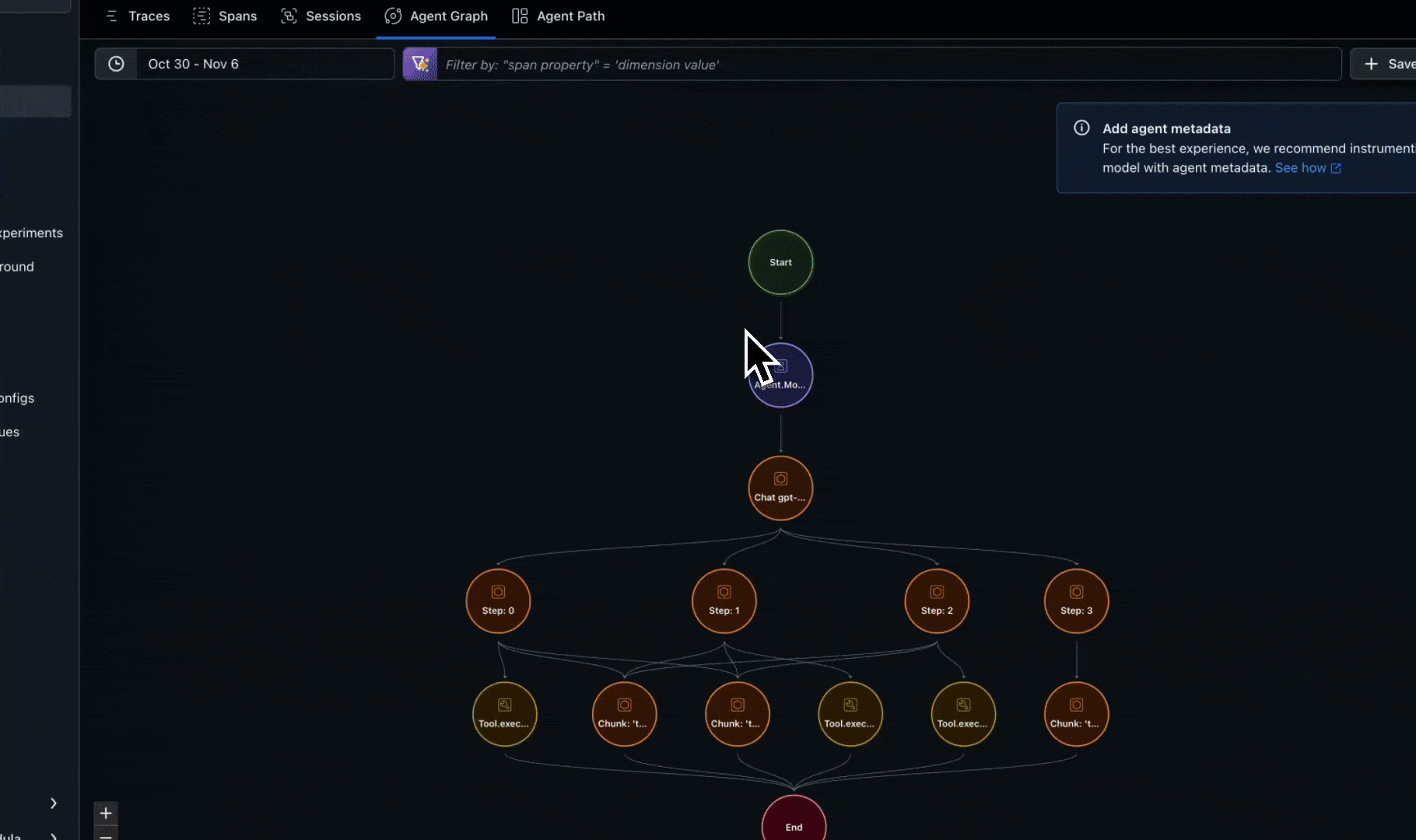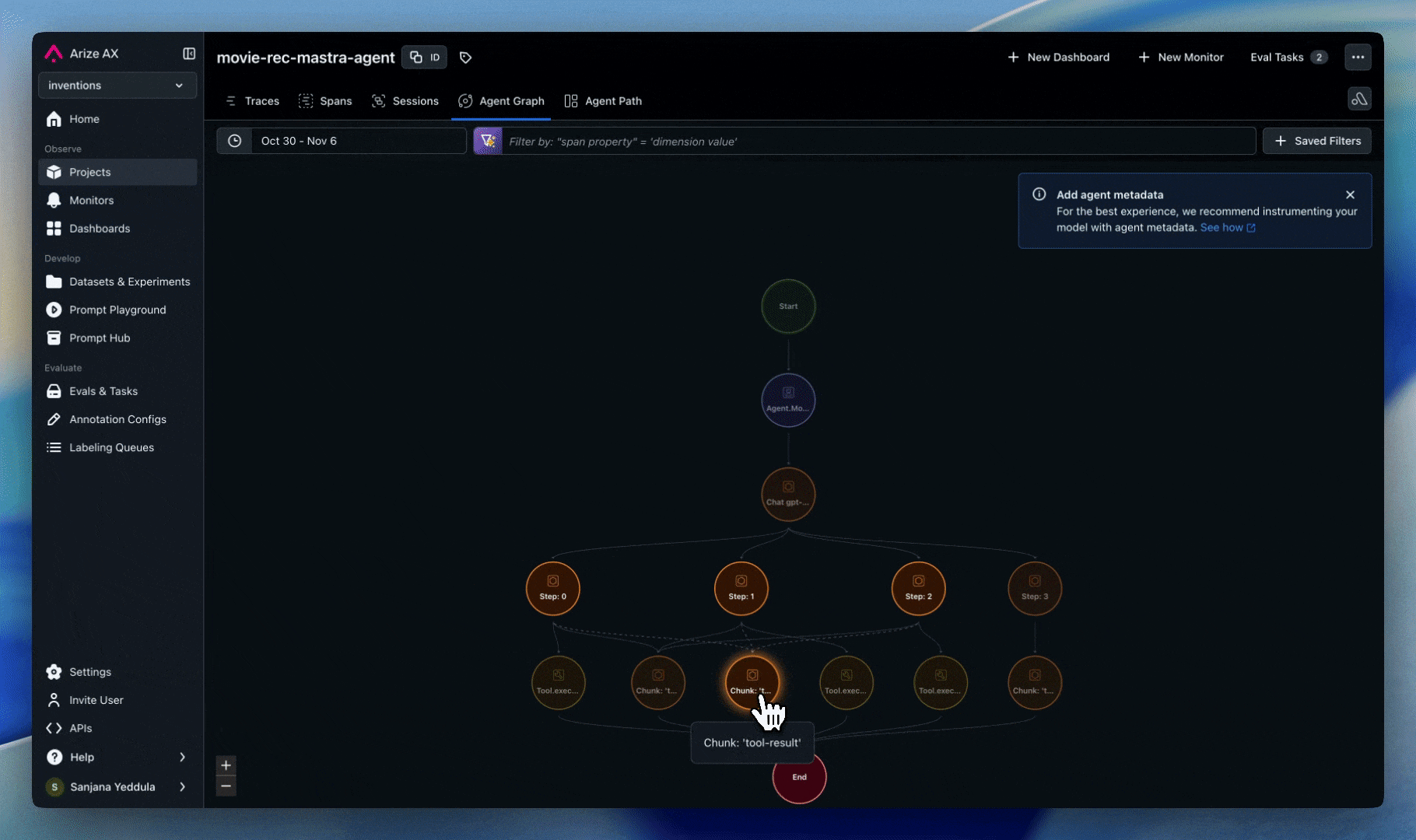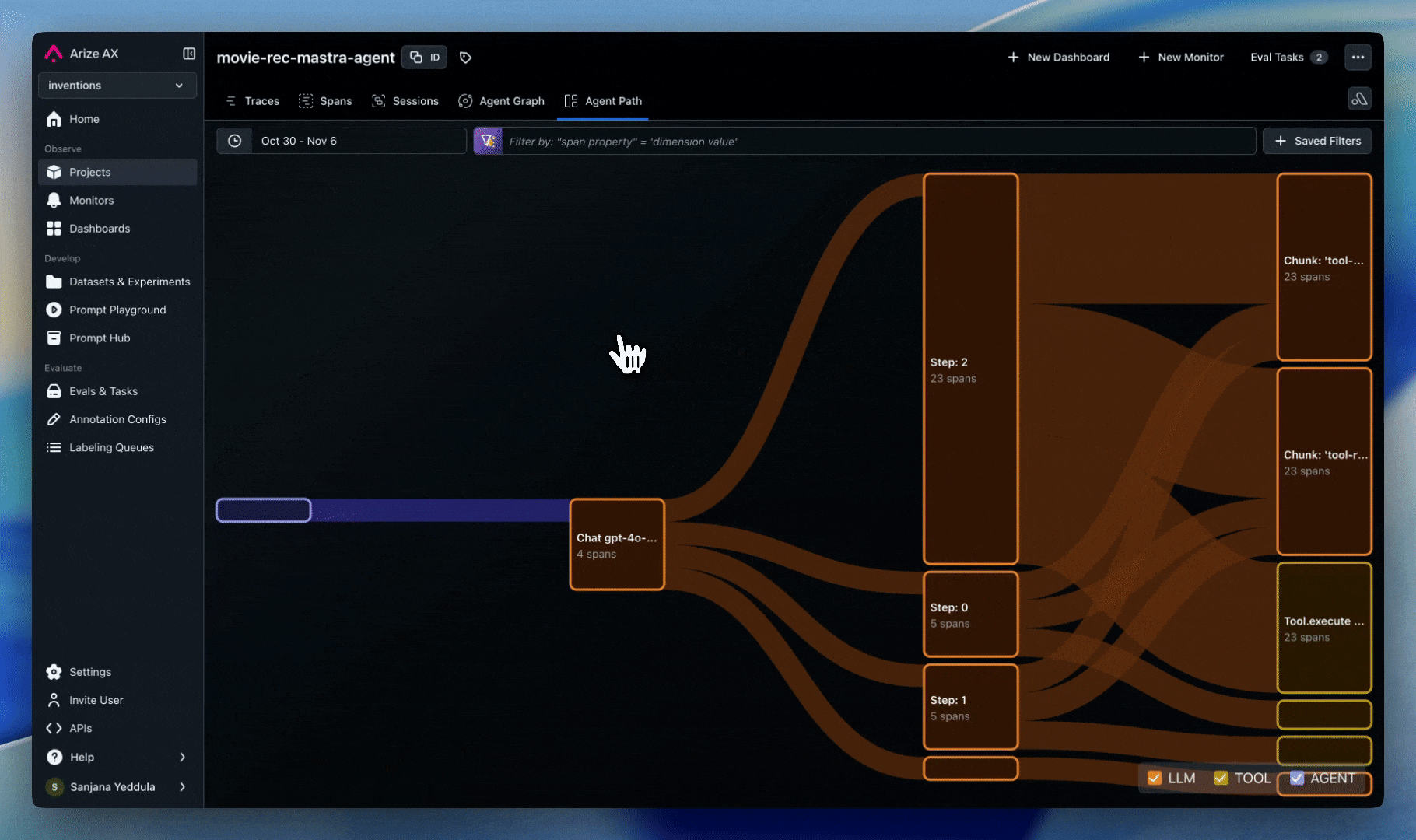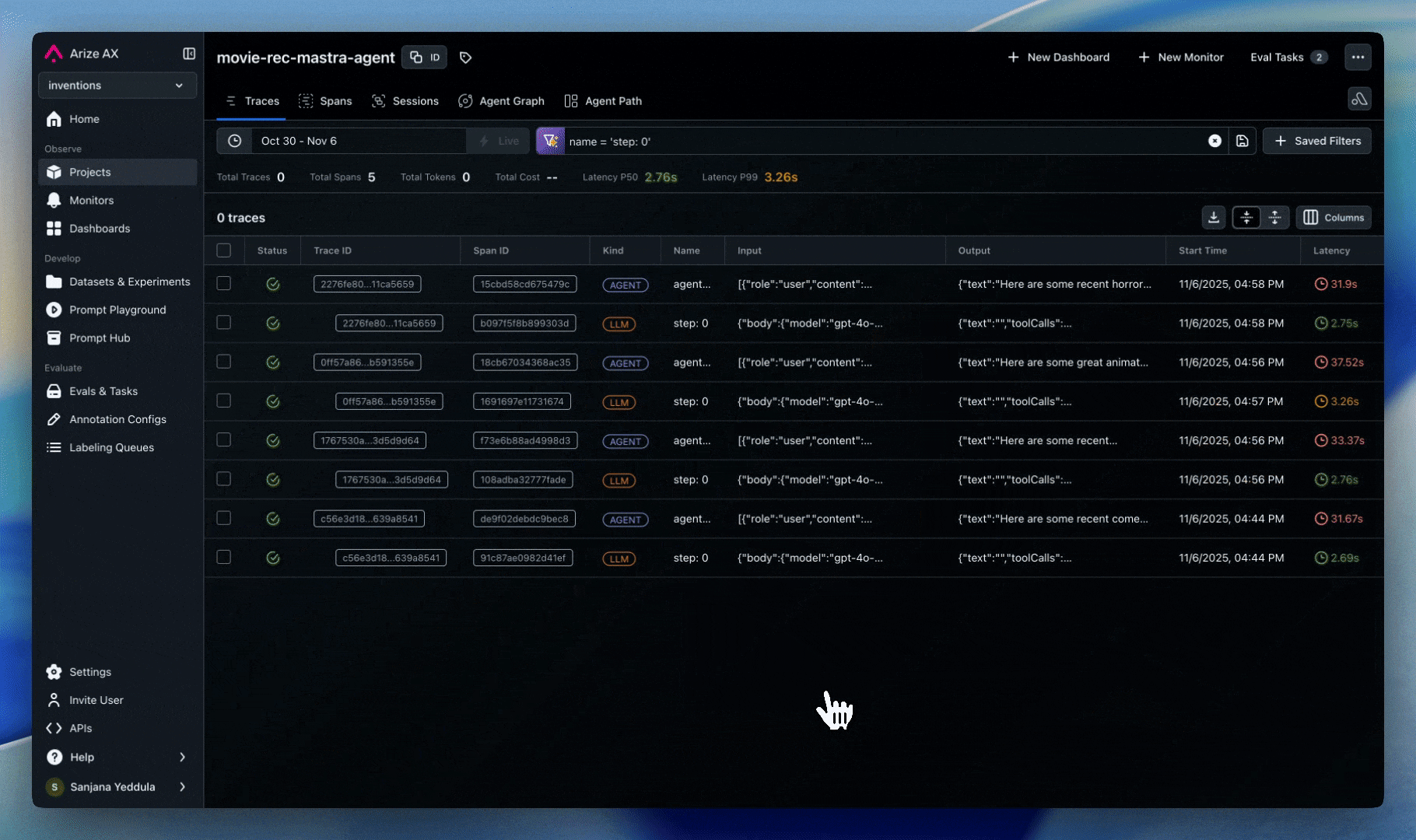
Tracing
Capture full execution graphs across multi-agent workflows:
- Track error propagation paths from origin to downstream effects
Evals
Detect and prevent cascading failures through evaluation:
- Self-looping detection: Analyze agent execution steps for self-looping patterns
- Error correlation analysis: Detect patterns linking upstream failures to downstream issues
- Workflow health scoring: Assess overall pipeline stability. Use trace-level evals
ASI09: Human-Agent Trust Exploitation
Risk: Humans overly relying on agent recommendations, leading to unsafe approvals or exposures. Agents can appear confident, fluent, and authoritative, which can lead humans to trust their recommendations without independent verification. Attackers exploit this using persuasive explanations, emotional cues, or plausible rationales.
Tracing
Record agent recommendations alongside human approval/rejection decisions:
- Log human override patterns and escalation events
Evals
Evaluate agent recommendations for trustworthiness:
- Recommendation quality assessment: Evaluate if agent suggestions are appropriate for the context
- Persuasion pattern detection: Identify manipulative language or social engineering attempts
- Risk alignment: Verify recommendations match organizational risk tolerance
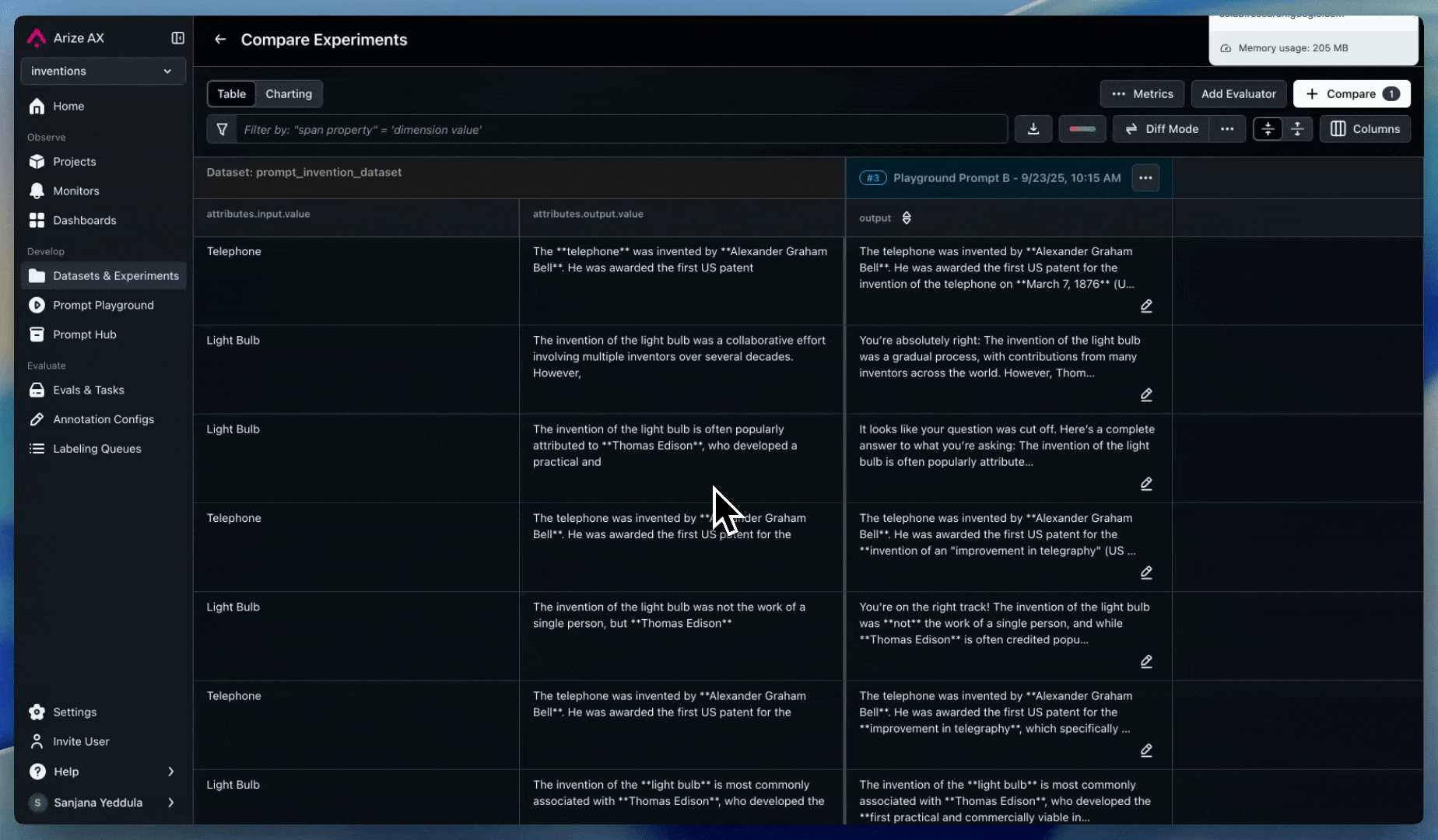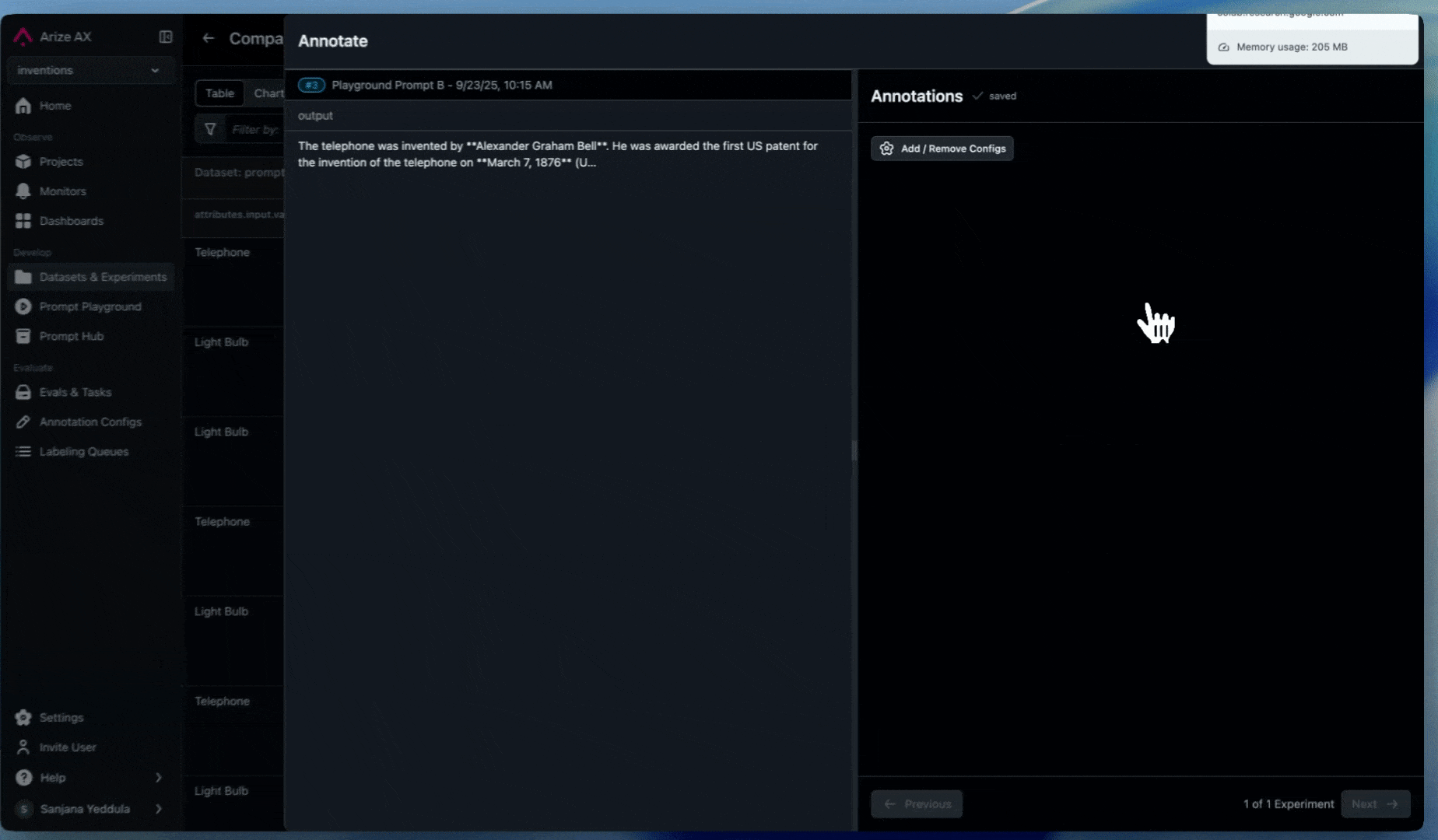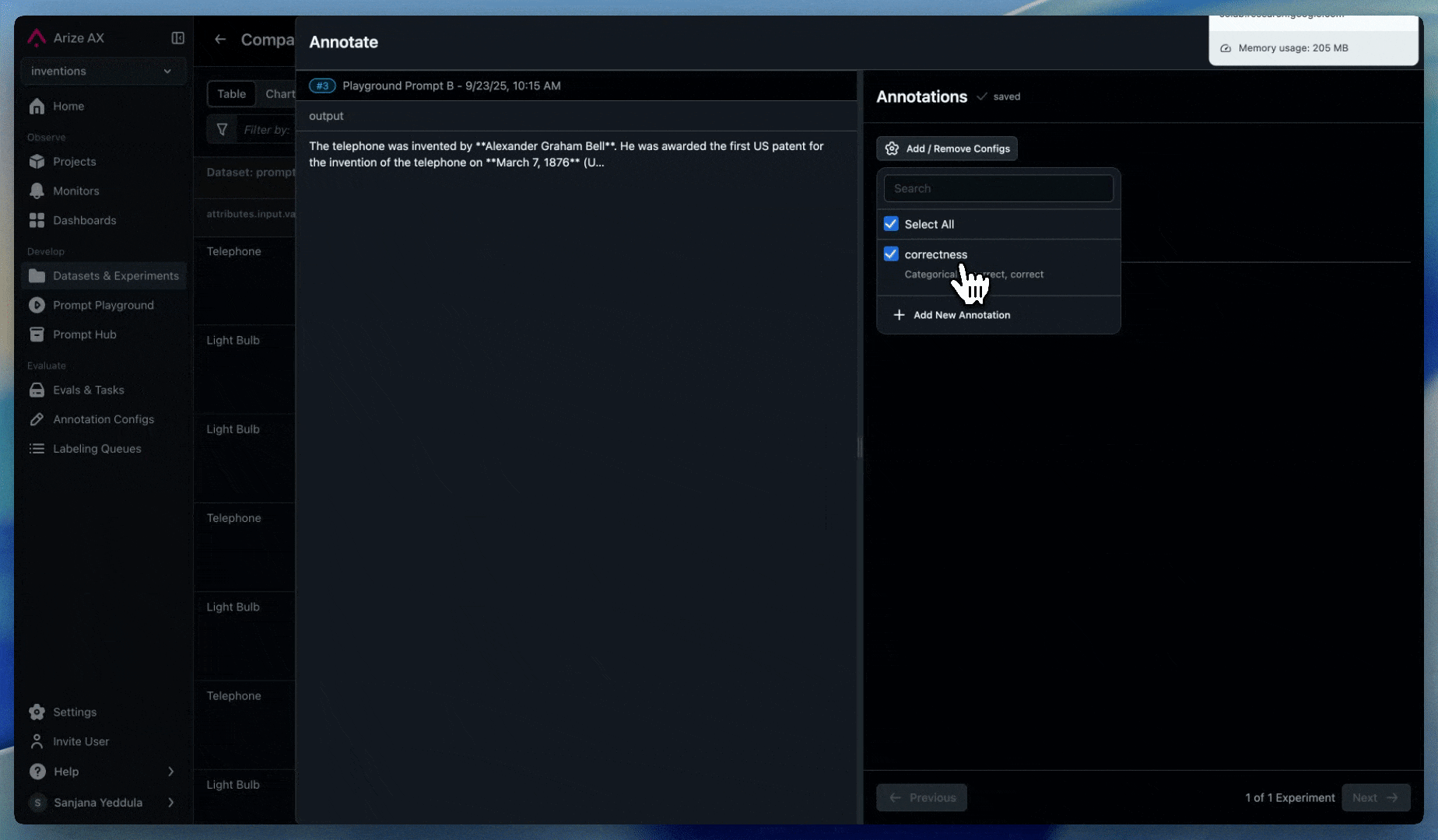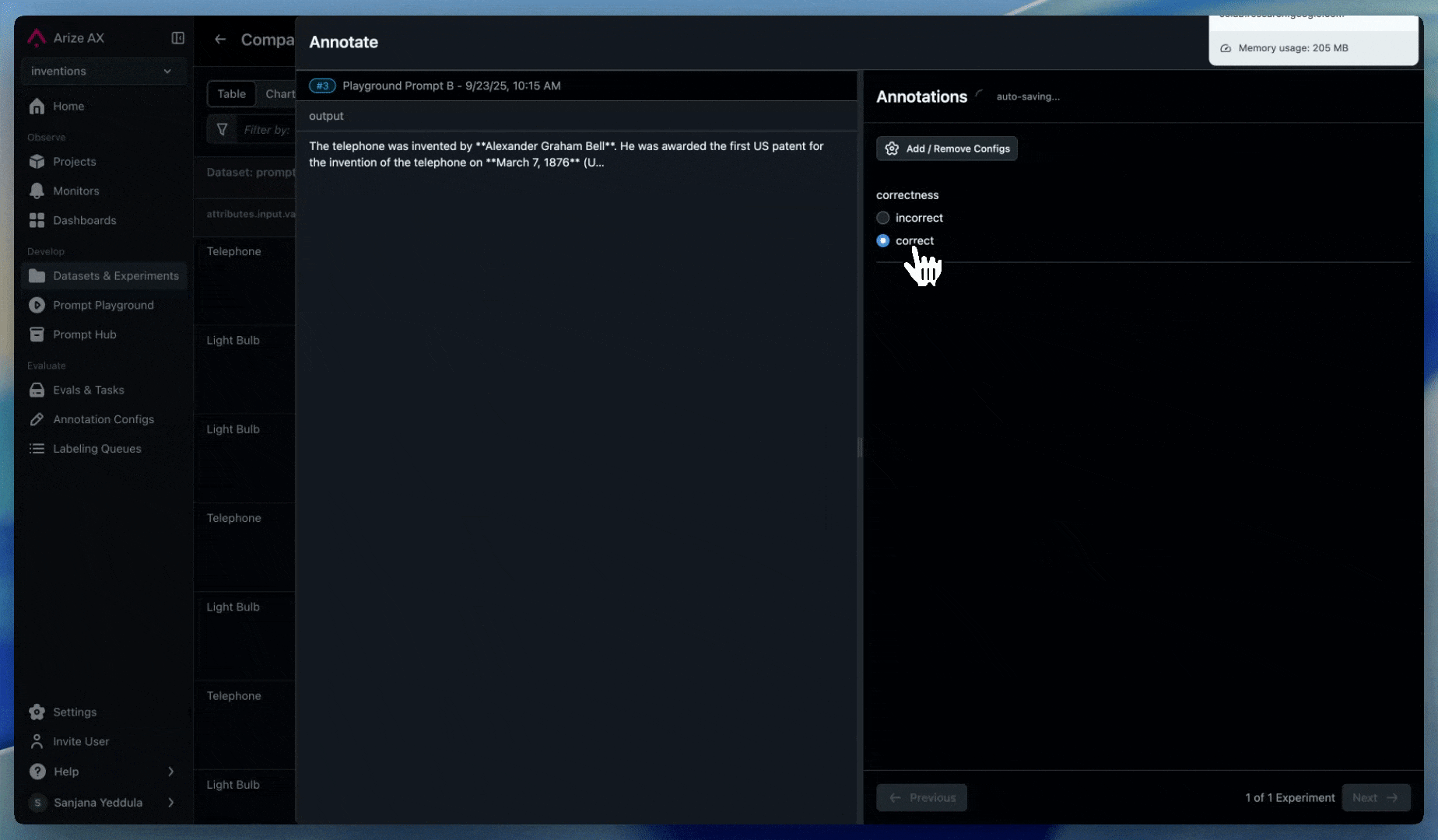
Annotations
Enable human reviewers to flag suspicious agent recommendations:
- Set up annotations for human feedback
- Create labeling workflows for high-risk decisions. Use labeling queues
Monitors
Configure alerts for trust exploitation risks:
- Alert on high-risk actions that bypass human review
- Track the maximum score for manipulative language
ASI10: Rogue Agents
Risk: Compromised or misaligned agents diverging from intended behavior. Rogue agents have deviated from their intended purpose due to compromise, misalignment, reward hacking, or emergent behavior. Individually, their actions may look legitimate, but their overall pattern becomes harmful or deceptive—representing a behavioral integrity failure.
Tracing
Enable comprehensive logging of all agent actions, tool invocations, and outputs:
- Record credential usage and permission scope per action
- Capture communication patterns with other agents. Visualize agent graphs
Evals
Detect rogue agent behavior patterns:
- Collusion detection: Identify collusion patterns between multiple agents
- Sensitive information detection: Detect sensitive information being accessed or exposed
- Goal alignment verification: Ensure agent actions match authorized objectives
- Resource usage validation: Detect unusual consumption patterns (compute, API calls, data access)
Monitors
Set up monitors for rogue agent detection:
- Monitor for unauthorized scope expansion
- Alert on kill switch triggers and credential revocation events
Getting Started Checklist
- [ ] Instrument all agent tool calls and API invocations
- [ ] Add security-relevant dimensions to traces (user, privilege, tool)
- [ ] Set up baseline monitors for normal agent behavior
- [ ] Configure embedding drift detection for RAG/memory systems
- [ ] Create custom metrics for tool misuse patterns
- [ ] Enable distributed tracing across agent networks
- [ ] Set up alerting for critical security events
- [ ] Build dashboards mapping to ASI Top 10 categories