




Agents in the Wild



Introduction
Companies all over the world are experimenting with chatbot agents, tools like Anthropic computer use and OpenAI Operator have turned heads by connecting agents to outside websites, and frameworks like LangGraph, CrewAI, and LlamaIndex Workflows are helping developers around the world build structured agents.
However, despite their popularity, AI agents have yet to make a strong splash outside of the AI ecosystem. Very few agents have taken off among either consumer or enterprise users.
With this in mind, we decided it was time to help teams navigate the new frameworks and new agent directions. What tools are available, and which should you use to build your next application? How can you evaluate and improve your agent?
Our other motivation behind this series is that our team built our own complex agent to act as a copilot within our Arize platform. We took a TON of learnings away from this process, and now feel more qualified to offer our opinion on the current state of AI agents.
In this handbook, we’ll deep dive on each of these topics and close out with a comprehensive overview on agent evaluation. We’re hopeful that this resource can help arm AI engineers everywhere to build the best agents possible.
Before we can turn to the advanced questions like evaluating agents and comparing frameworks, let’s examine the current state of agent architectures.
To align ourselves before we jump in, it helps to define what we mean by an agent. LLM-based agents are software systems that string together multiple processing steps, including calls to LLMs, in order to achieve a desired end result. Agents typically have some amount of conditional logic or decision-making capabilities, as well as a working memory they can access between steps.
In this first post, we’ll deep dive into how agents are built today, the current problems with modern agents, and some initial solutions.
Early Agent Architectures: The Failure of ReAct Agents
Let’s be honest, the idea of an Agent isn’t new. There have been countless agents launched on AI Twitter claiming amazing feats of intelligence. This first generation were mainly ReAct (reason, act) agents. They were designed to abstract as much as possible, and promised a wide set of outcomes.
Unfortunately, this first generation of agent architectures really struggled. Their heavy abstraction made them hard to use, and despite their lofty promises, they turned out to not do much of anything.
In reaction to this, many people began to rethink how agents should be structured. In the past year we’ve seen great advances, now leading us into the next generation of agents.
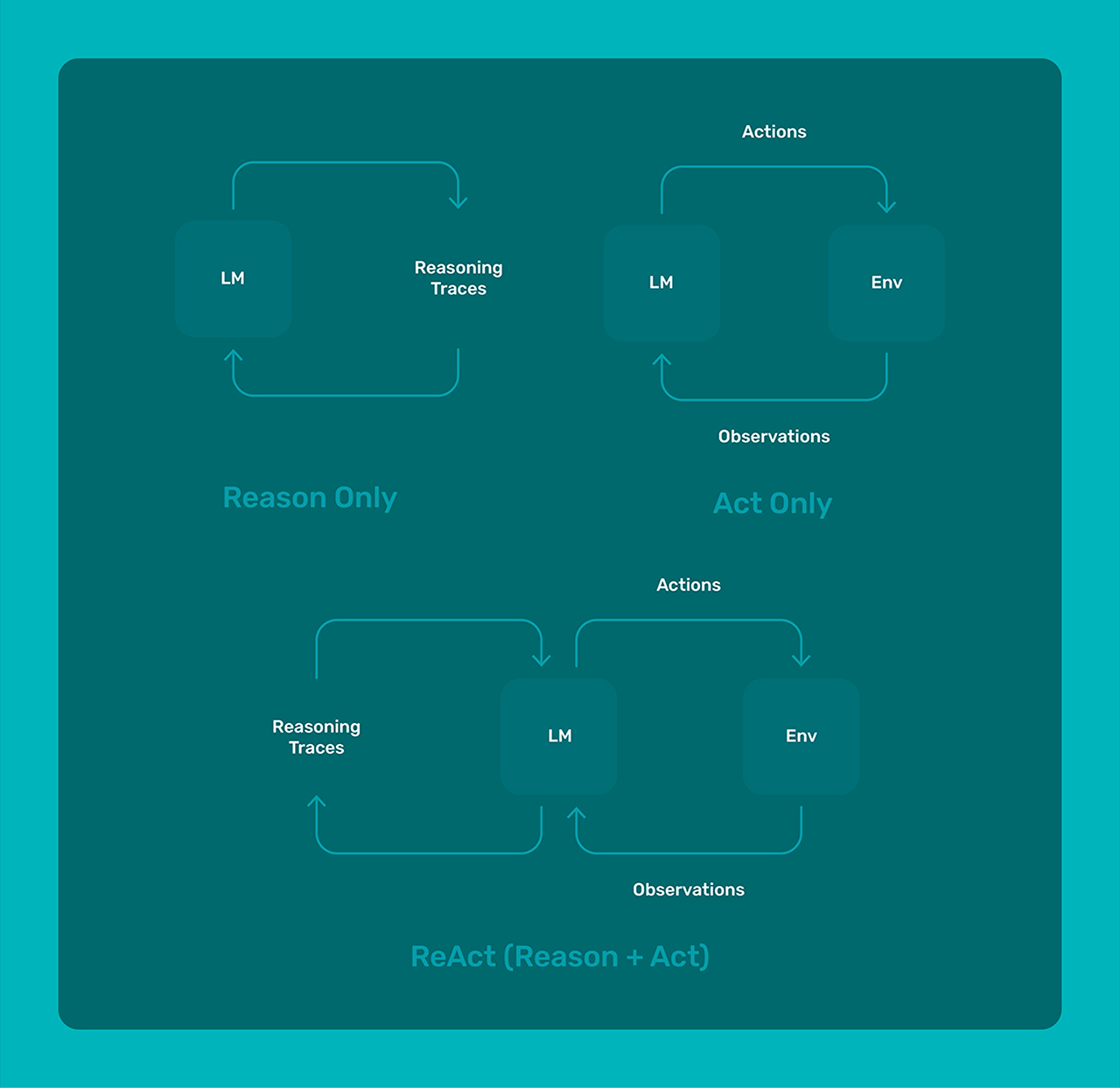
The New Generation of AI Agents
This new generation of agents is built on the principle of defining the possible paths an agent can take in a much more rigid fashion, instead of the open-ended nature of ReAct. Whether agents use a framework or not, we have seen a trend towards smaller solution spaces – aka a reduction in the possible things each agent can do. A smaller solution space means an easier to define agent, which often leads to a more powerful agent.
This second generation covers many different types of agents, however it’s worth noting that most of the agents or assistants we see today are written in code without frameworks, have an LLM router stage, and process data in iterative loops.
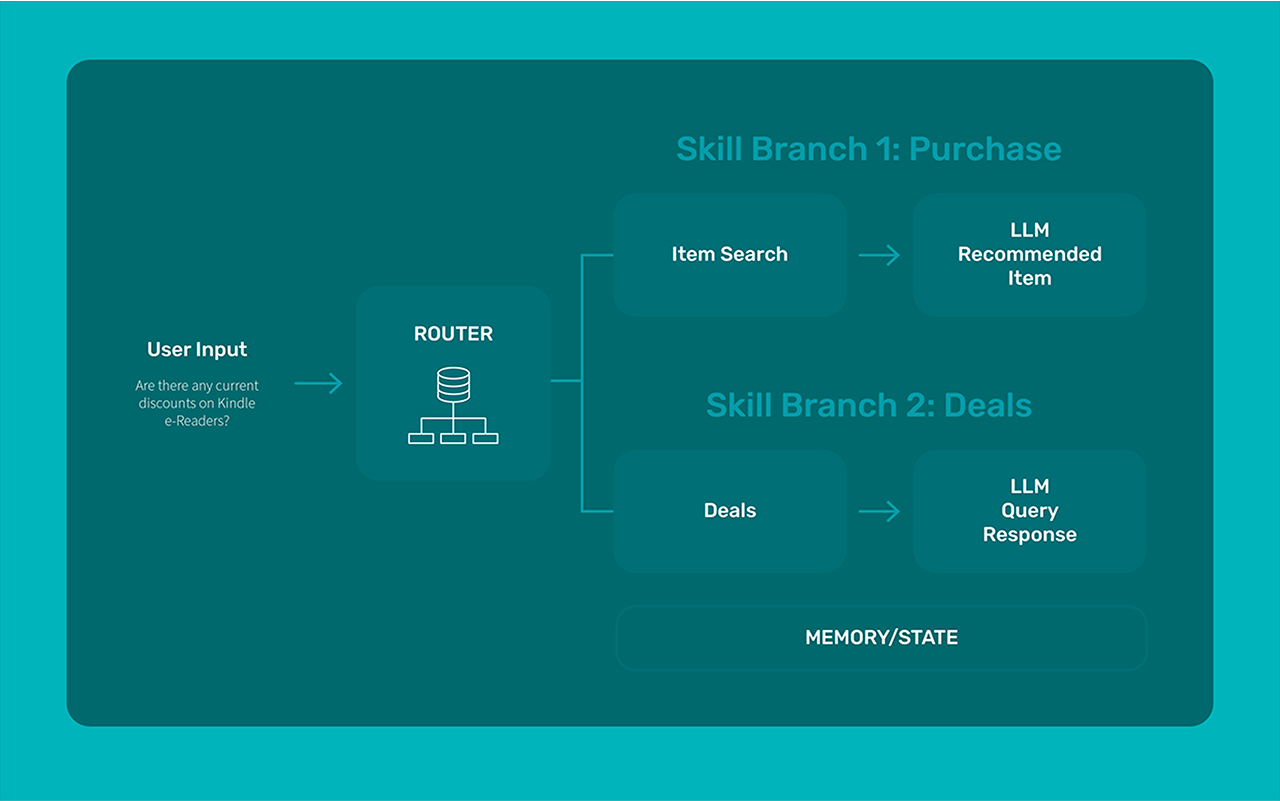
What Makes Up An Agent?
Many agents have a node or component we call a router, that decides which step the agent should take next. In our assistant we have multiple fairly complex router nodes. The term router normally refers to an LLM or classifier making an intent decision of what path to take. An agent may return to this router continuously as they progress through their execution, each time bringing some updated information. The router will take that information, combine it with its existing knowledge of the possible next steps, and choose the next action to take.
The router itself is sometimes powered by a call to an LLM. Most popular LLMs at this point support function calling, where they can choose a component to call from a JSON dictionary of function definitions. This ability makes the routing step easy to initially set up. As we’ll see later however, the router is often the step that needs the most improvement in an agent, so this ease of setup can bely the complexity under the surface.
Each action an agent can take is typically represented by a component. Components are blocks of code that accomplish a specific small task. These could call an LLM, or make multiple LLM calls, make an internal API call, or just run some sort of application code. These go by different names in different frameworks. In LangGraph, these are nodes. In LlamaIndex Workflows, they’re known as steps. Once the component completes its work, it may return to the router, or move to other decision components.
Depending on the complexity of your agent, it can be helpful to group components together as execution branches or skills. Say you have a customer service chatbot agent. One of the things this agent can do is check the shipping status of an order. To functionally do that, the agent needs to extract an order id from the user’s query, create an api call to a backend system, make that api, parse the results, and generate a response. Each of those steps may be a component, and they can be grouped into the “Check shipping status” skill.
Finally, many agents will track a shared state or memory as they execute. This allows agents to more easily pass context between various components.
Do You Need an AI Agent?
Agents cover a broad range of systems. There is so much hype about what is “agentic” these days. How can you decide whether you actually need an agent? What types of applications even require an agent?
For us, it boils down to three criteria:
- Does your application follow an iterative flow based on incoming data?
- Does your application need to adapt and follow different flows based on previously taken actions or feedback along the way?
- Is there a state space of actions that can be taken? The state space can be traversed in a variety of ways, and is not just restricted to linear pathways.
Common Problems with AI Agents
Agents powered by LLMs hold incredible potential, yet they often struggle with several common pitfalls that limit their effectiveness.
One major challenge is long-term planning. While these models are powerful, they often falter when it comes to breaking down complex tasks into manageable steps. The process of task decomposition can be daunting, leading agents to get stuck in loops, unable to progress beyond certain points. This lack of foresight means they can lose track of the overall goal, requiring manual correction to get back on course.
Another issue is the vastness of the solution space. The sheer number of possible actions and paths an agent can take makes it difficult to consistently achieve reliable outcomes. As a result, the results can be inconsistent, leading to unpredictability in performance. This inconsistency not only undermines the reliability of agents but also makes them expensive to run, as more resources are required to achieve the desired results.
It is worth mentioning that current agent trends have pushed the market further towards constrained agents that can only choose from a set of possible actions, effectively limiting the solution space.
Finally, agents often struggle with malformed tooling calls. When faced with poorly structured or incorrect inputs, they can’t easily recover, leading to failures that require human intervention. These challenges highlight the need for more robust solutions that can handle the complexities of real-world applications while delivering reliable, cost-effective results.
Addressing Challenges with AI Agents
One of the most effective strategies is to map the solution space beforehand. By thoroughly understanding and defining the range of possible actions and outcomes, you can reduce the ambiguity that agents often struggle with. This preemptive mapping helps guide the agent’s decision-making process, narrowing down the solution space to more manageable and relevant options.
Incorporating domain and business heuristics into the agent’s guidance system is another powerful approach. By embedding specific rules and guidelines related to the business or application, you can provide the agent with the context it needs to make better decisions. These heuristics act as a compass, steering the agent away from less relevant paths and towards more appropriate solutions, which is particularly useful in complex or specialized domains.
Being explicit about action intentions is also crucial. Clearly defining what each action is intended to accomplish ensures that the agent follows a logical and coherent path. This explicitness helps prevent the agent from getting stuck in loops or deviating from its goals, leading to more consistent and reliable performance. Modern frameworks for agent development luckily encourage this type of strict definition.
Creating a repeatable process is another key strategy. By standardizing the steps and methodologies that agents follow, you can ensure that they perform tasks consistently across different scenarios. This repeatability not only enhances reliability but also makes it easier to identify and correct errors when they occur.
Finally, orchestrating with code and more reliable methods rather than relying solely on LLM planning can dramatically improve agent performance. This involves swapping your LLM router for a code-based router where possible. By using code-based orchestration, you can implement more deterministic and controllable processes, reducing the unpredictability that often comes with LLM-based planning.