





Building Audio Support with OpenAI: Insights from our Journey

Sally-Ann DeLucia
Director, Product
Introduction
In early October last year, OpenAI launched the beta version of their Realtime API, which introduced an incredible feature: the ability to process audio as both input and output in a low latency environment. And when I say process audio, I don’t just mean converting it to text and passing it to an LLM—the GPT model actually handles raw audio bytes directly. That’s a fairly novel capability, and OpenAI’s implementation is lightning-fast. It even supports Voice Activity Detection (VAD), allowing the API to seamlessly handle real-time adjustments, interruptions, and subsequent requests. Think of it like Siri or Alexa, but far more advanced. Integrated with the right tools and setup, it’s on a completely different level. While intimidating at first, once configured, it quickly becomes clear this API is far beyond what you’d expect from a beta release.
Audio is a remarkably powerful modality, opening doors to LLM applications that go beyond traditional text-based interactions. By incorporating audio, applications can enable richer, multimodal experiences in areas like language learning, virtual assistants, customer support, and more. Recognizing this potential, we knew we had to bring audio support into Arize. As more applications adopt audio, they’ll need robust observability and evaluation tools to ensure quality and performance.
In this blog, I’ll walk you through what we learned while building audio support—sharing key lessons so you don’t have to learn them the hard way. Let’s begin by diving into the technology.
What Is the OpenAI Realtime API?
The OpenAI Realtime API enables teams to create low-latency, multimodal conversational applications with voice-enabled models. These models support real-time text and audio inputs and outputs, voice activity detection, function calling, and much more. But what exactly makes the Realtime API special? Let’s dive in.
First off, it’s really fast. The API offers low-latency streaming, which is essential for smooth and engaging conversational experiences. It also brings advanced voice capabilities to the table. You can adjust the tone, include natural-sounding laughs or whispers, and even provide tonal direction—all while keeping the responses sounding incredibly natural. On top of that, the Realtime API supports function calling, which is a game-changer for building agents capable of handling complex, real-world tasks.
So how does all of this work? The Realtime API leverages WebSockets, which enable a persistent, bi-directional communication channel between the client (your application) and the server (OpenAI). This means data can flow continuously in both directions, allowing for seamless conversational exchanges. Unlike traditional HTTP, where each request needs its own connection, WebSockets keep the line open, letting the client and server send messages independently of each other.
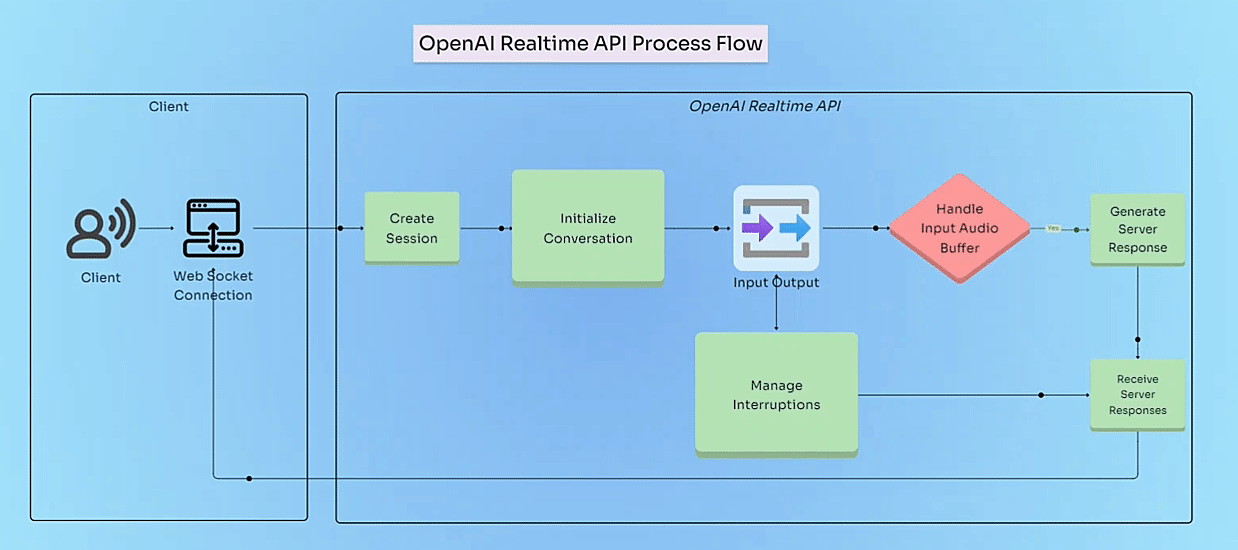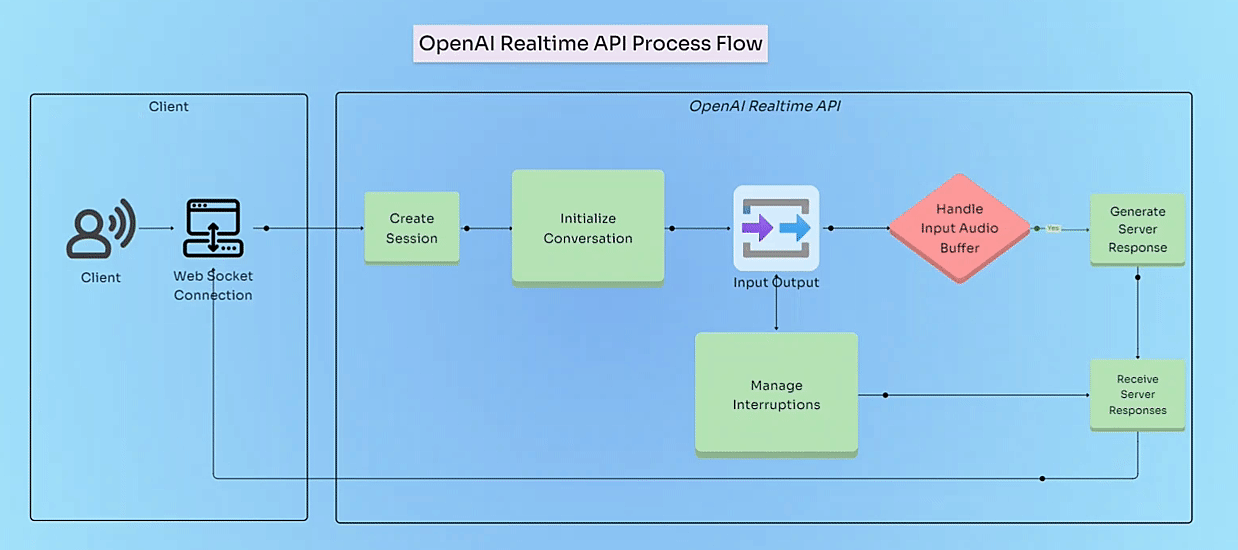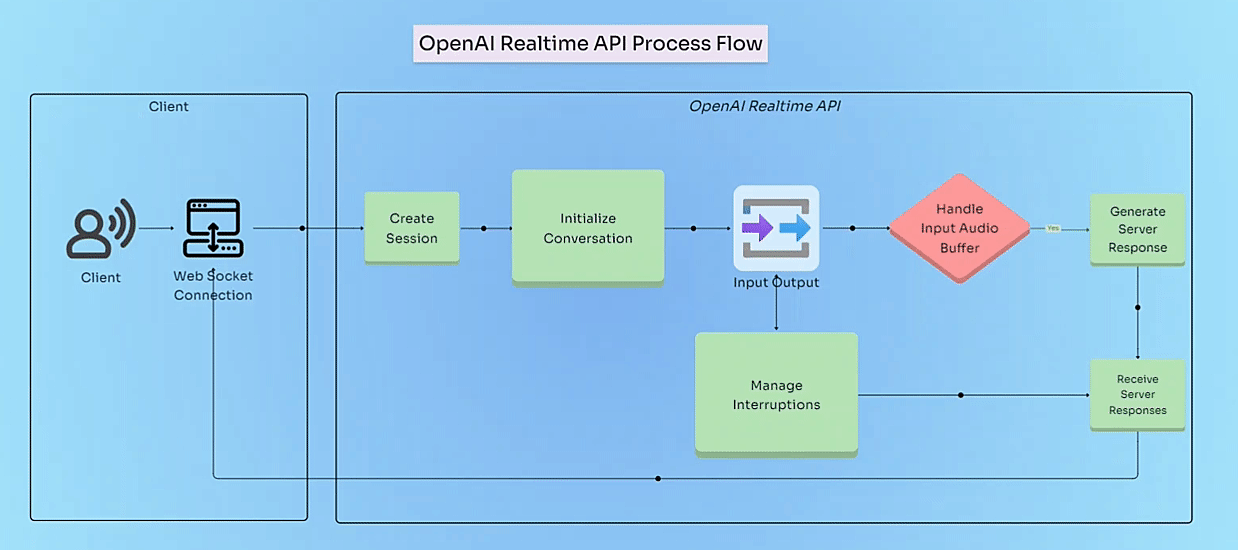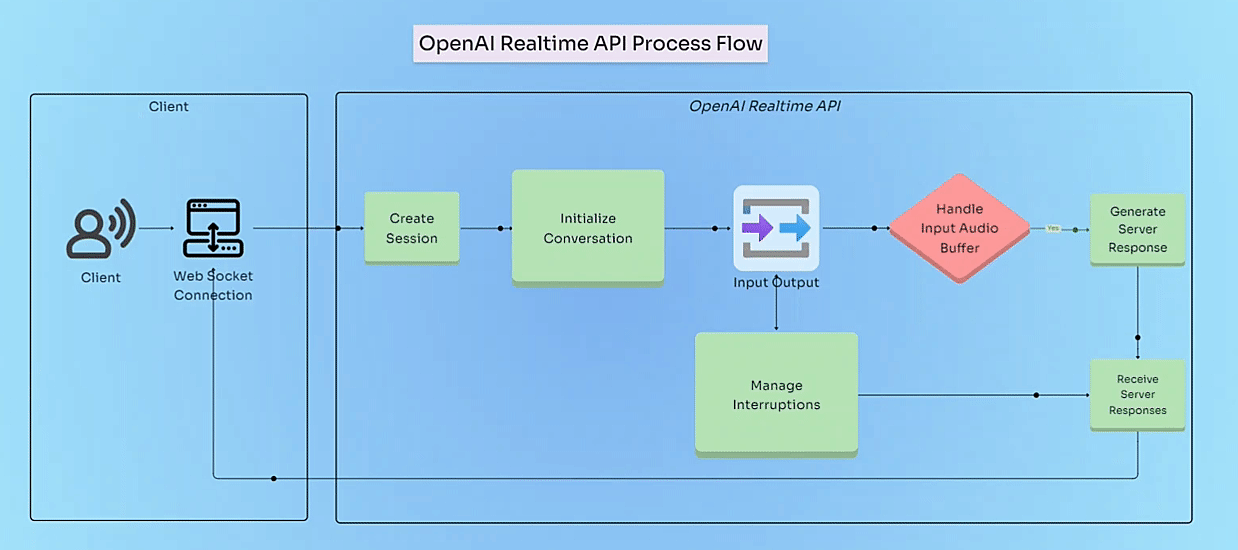
This constant exchange of events is the backbone of the API. Events track what the system is doing and reflect the current state of your application. Whether you’re streaming responses or managing real-time function calls, events give you the insight and control needed to create dynamic and responsive applications. They’re also crucial for tracing your application to Arize.
Navigating Events and Audio Complexity: Key Challenges
As I mentioned earlier, setting up the Realtime API can feel overwhelming, especially if you’re not familiar with WebSockets or audio data. My first piece of advice: start with OpenAI’s Realtime console. It’s an excellent way to see just how impressive this technology is while also getting hands-on experience with how events move back and forth. This helps you build intuition for which events are critical for your application. However, be prepared—there are a lot of events.

To truly understand the challenges and nuances of integrating the Realtime API, we decided to build a toy application from scratch. This hands-on approach wasn’t just for fun—it was a deliberate effort to deeply study how the API works and identify potential pain points that developers might face. By doing so, we gained insights that ultimately shaped the platform support we now offer. For instance, experimenting with event structures and state management in a low-stakes environment helped us understand what the events were that really mattered, as well as the API’s capabilities and limitations. If you’re just starting, I highly recommend trying something similar to solidify your foundation.
One major challenge we had: we needed to keep meticulous track of state. A single request-response cycle can generate upwards of 100 events, and we needed to aggregate a significant amount of events to get all the data we needed. If your application isn’t tracking state properly, you risk missing critical information, which could impact the quality of responses. This is also important because, due to the nature of WebSockets, the API might send a partial response before completing a tool call. While this is rare, it’s something to be aware of.
Audio data adds another layer of complexity. For those new to audio processing, this shift can be daunting. Unlike structured formats like JSON or DataFrames, audio signals are continuous and high-dimensional, requiring significant storage and computational power. Managing large audio datasets introduces challenges not typically encountered with more standardized data types.
Additionally, audio files come in various formats, like WAV and MP3, each with its own sample rates and bit depths. Ensuring compatibility with the Realtime API means you’ll need to handle these formats carefully. For instance, while developing our evaluation package, we learned that when sending a base64-encoded audio string to OpenAI, the correct file format (e.g., WAV or MP3) must be explicitly specified. If a file’s extension is missing or unreliable, implementing validation mechanisms becomes essential. This might involve checking specific byte patterns at the beginning of the file to accurately determine its format.
How We Built Audio Evaluation Support Lessons Learned
When we set out to support voice applications in Arize, we knew evaluations would play a central role. This gave us a unique opportunity to push the limits of what the model could achieve in audio evaluations. We focused on two critical areas to start: emotion detection and intent recognition.
Emotion is key because it provides insight into how users interact with applications. Are users confused, frustrated, or happy? Knowing this can be incredibly valuable for improving user experiences. Emotion detection, paired with regular evaluations, offers a window into how applications respond to users’ needs. For instance, the ability to control audio output means you can assess whether your application is responding inappropriately—like sounding angry or dismissive—so you can address it.
Intent recognition is equally important for understanding how well the API interprets user requests. This helps determine whether the application made the right decision to address a query. For example, if your application uses multiple tools, intent detection can ensure the right tool was called—or identify gaps where new tools are needed. With these two focus areas in mind, we began benchmarking and building our evaluation package.
The Right Tools for the Job
One early realization was that we didn’t need to use the Realtime API for evaluations. Realtime capabilities, like low-latency voice activity detection (VAD), are essential for conversational experiences like support or call center applications. For evaluations, however, low latency wasn’t a requirement. Instead, we opted for the chat completions API, which is also audio-enabled. Making the call is straightforward—just send the audio and text in separate messages. Simple enough.
completion = client.chat.completions.create(
model="gpt-4o-audio-preview",
modalities=["text", "audio"],
audio={"voice": "alloy", "format": "wav"},
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is in this recording?"
},
{
"type": "input_audio",
"input_audio": {
"data": encoded_string,
"format": "wav"
}
}
]
},
]
)
Benchmarking: The Highs and Lows
If we were going to publish evaluation templates, we needed to benchmark them thoroughly. Recommending a template without ensuring its performance wasn’t an option. Here’s what we found:
Intent Recognition
Intent recognition was a breeze. GPT-4 handled it effortlessly, delivering excellent results right out of the gate. While we opted not to release a single intent template (because intents vary widely across use cases), we included a skeleton template in our cookbook for users to build upon.
Emotion Detection
Emotion detection, however, was another story. OpenAI claimed the model could interpret nuanced emotions in audio, so I had high hopes. I started with well-known emotion detection datasets like RAVDESS and CREMA-D, both of which feature controlled, actor-generated audio with golden labels. But the results were dismal—about 1% accuracy. I couldn’t believe it.
I iterated on the prompt, adding more detailed instructions and refining the format. No improvement. I moved to another dataset, rinsed and repeated. Still nothing. Frustration mounted as I noticed the model defaulting to “neutral” most of the time. Why? I began to suspect the issue was the datasets themselves.
RAVDESS and CREMA-D are highly controlled and exaggerated, with short, scripted sentences—scenarios that don’t align well with GPT’s strengths. Switching to the IEMOCAP (labels / data) dataset was a game-changer. This dataset features more natural conversations, closely mirroring GPT’s capabilities in understanding nuanced, real-world language. The results? A dramatic improvement in accuracy. This experience was a valuable reminder: models like GPT aren’t magic—they excel in natural, conversational contexts but may struggle with artificially constrained tasks.
Crafting Multimodal Prompt Templates
One unique challenge with audio evaluations was constructing multimodal prompt templates. Unlike text-based evaluations, where prompts are a single template with variable placeholders, audio requires a different approach. The audio must be sent as a separate message, alongside task guidelines and response instructions.
We experimented with several layering techniques for these templates. Ultimately, the best approach was to “sandwich” the audio between the task instructions and response expectations. This structure worked well for evaluations and for general use of the chat completions API with audio. If you’re developing with this API, keep in mind the need to treat audio as a distinct input.
Conclusion
Building audio-enabled applications presents a unique set of challenges, from understanding event flows and managing complex audio data, to crafting effective multimodal templates. These experiences have taught us valuable lessons about the nuances of realtime APIs, the importance of proper state management, and the complexities of working with high-dimensional data like audio.
Fortunately, tools like Arize are here to help you with your own journey. With instrumentation support, you gain visibility into the realtime events and state transitions critical to debugging and optimizing your applications. From addressing realtime challenges to ensuring robust evaluations, Arize provides the tools and support you need to confidently navigate the complexities of audio-enhanced LLM applications. With the right tools and a thoughtful approach, you can build transformative experiences that leverage the full potential of audio as a modality.
Key Takeaways
- Master Event Flows: Understanding how events are exchanged is foundational for understanding and developing with the Realtime API.
- Track State Meticulously: Proper state tracking ensures coherent and timely responses, especially in complex systems.
- Handle Audio Data Thoughtfully: Audio formats, storage, and validation require careful attention to avoid compatibility issues.
- Choose the Right OpenAI API: Match the API to your use case—realtime for conversational latency, chat completions for non-time-sensitive tasks.
- Lean on Arize for Support: Use Arize’s tools to gain visibility, benchmark models, and iterate with confidence.