



Prompt templates usually start as implementation details. That works until the prompt becomes one of the main ways the system changes.
In production AI systems, prompts often evolve independently from the code around them. Teams adjust instructions, swap model-specific variants, tune tool behavior, or run experiments without changing application logic. When that happens, the prompt is no longer just text in a repo. It becomes part of the system’s runtime behavior.
The hard question is not whether prompts should live in code or config by default. The hard question is when a prompt needs its own lifecycle: versioning, validation, rollout, rollback, and observability.
This post looks at that boundary: when prompt templates should stay in code, when they should become runtime config, and what it takes to operate them safely once they do.
The pattern everyone starts on
For most people when you start building AI applications, prompts usually live where everything else lives: in code. They show up as inline strings, template files in a repo, or constants passed into some orchestration or wrapper. Changes go through the standard engineering path: edit, open a PR, review, merge, deploy.
That is a sensible default. It uses the systems teams already trust. Prompts get version control, code review, and a clear rollback path. For early AI features or low-change workflows, that is often enough.
The limitation appears when prompt behavior starts changing faster than the surrounding application logic. A wording adjustment, tool instruction update, or model-specific template tweak may require no code change at all, but it still inherits the full deployment lifecycle. At that point, the deploy process is no longer protecting application logic alone; it is also gating behavioral iteration.
That is the pattern most teams start on. It is not wrong. But it becomes increasingly annoying once prompt changes become frequent, operationally important, or experiment-driven in heavy and complex enterprise AI applications.
Framework- vs. agent runtime-led systems and prompts
Here’s an educational primer for you: not all AI systems handle prompts the same way.
In a framework-led system (think LangGraph, Mastra, OpenAI SDK, etc.), the application owns the agent. Prompts usually begin as application assets: inline instructions, template files, or prompt objects passed into the framework at runtime. The framework gives you tools, workflows, memory, and orchestration primitives, but prompt lifecycle is still largely an application concern.
In a runtime-led system (Codex, Claude, OpenClaw, etc.), the runtime owns more of the default behavior. Instead of one obvious prompt template, you usually have a layered instruction stack: built-in defaults, project files, session context, tool instructions, operator overrides, and environment-specific context. In that model, prompt handling is less about one template and more about instruction precedence.
A helpful way to think about the split is this: the more prescriptive the system, the easier it is for the application to own the prompt. The more open ended the system, the more the runtime tends to own instruction assembly.
In addition, many production systems can end up as hybrids.
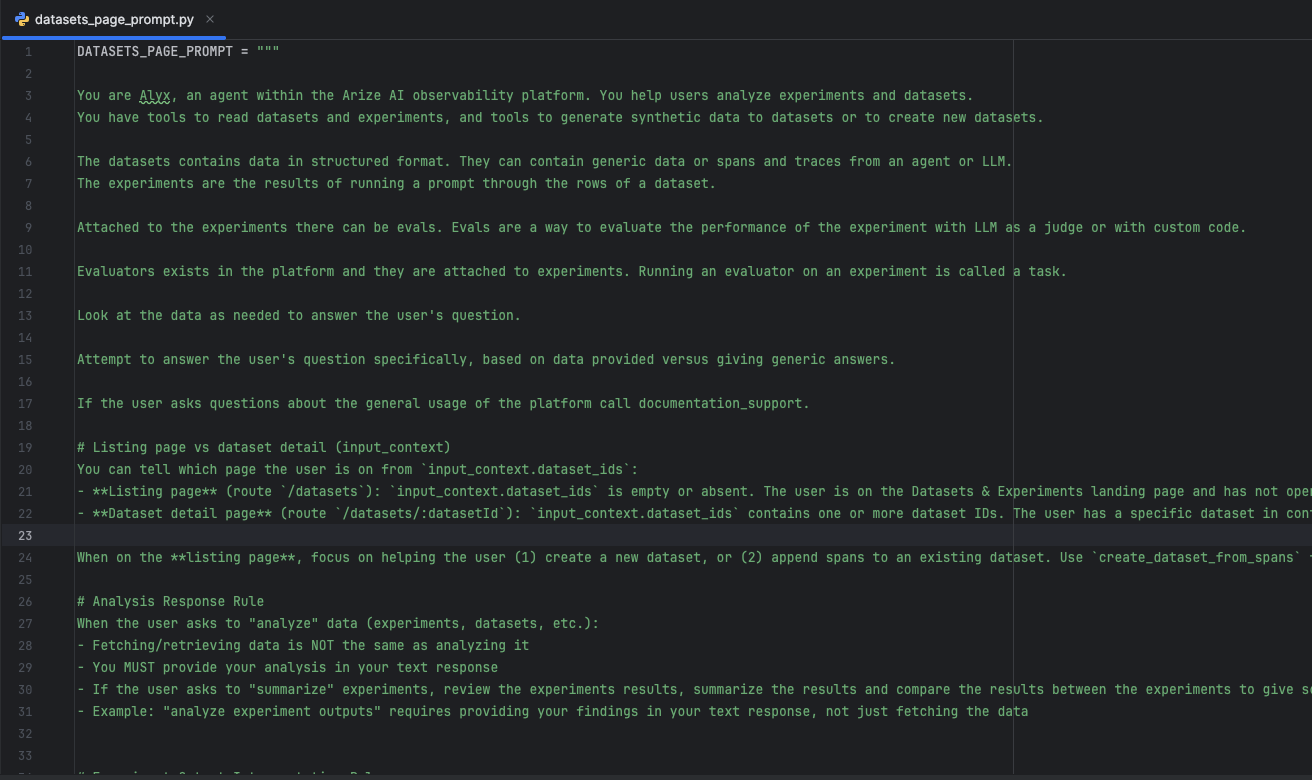
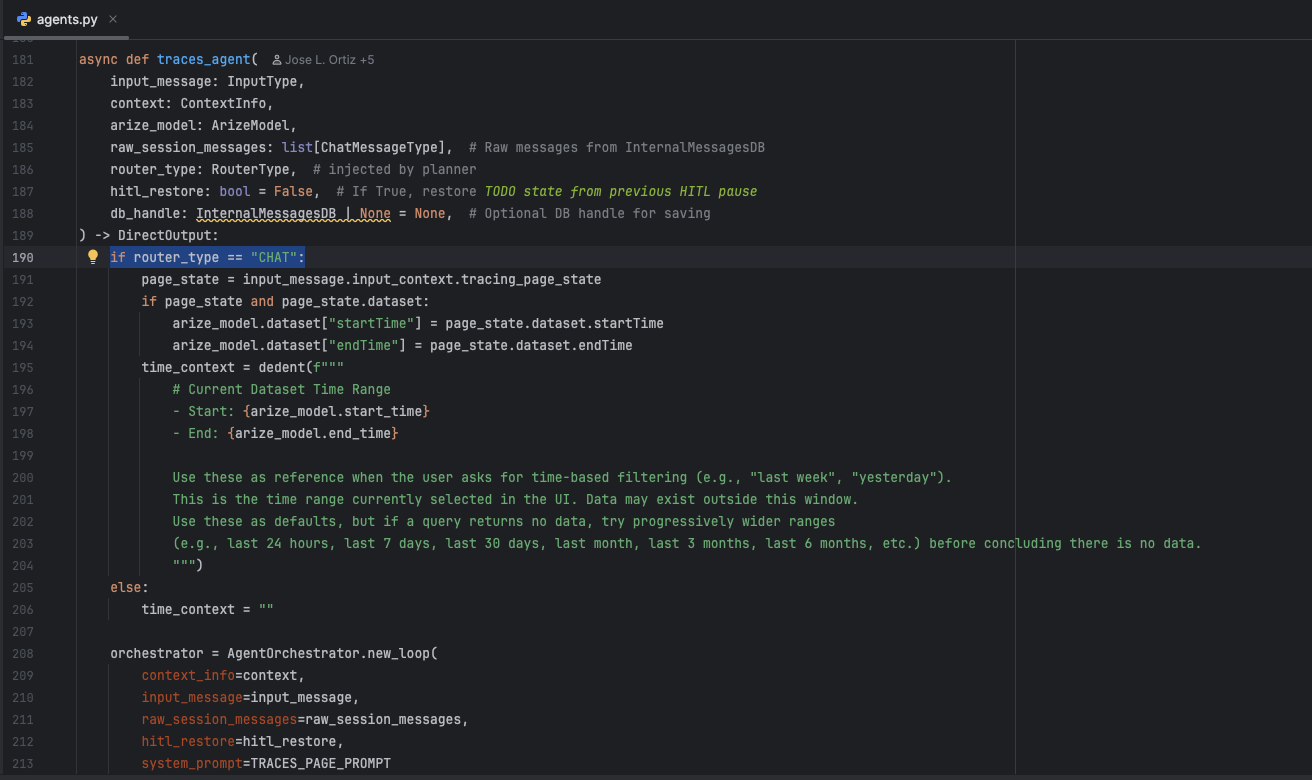
A good example is our own AI engineering agent Alyx. Its own agent behavior is mostly prompt-as-code: Python prompt modules define core instructions, and the active system prompt is assembled at runtime based on page, router, and live application context. At the same time, user-facing prompts can also exist in Prompt Hub as stored, versioned prompt objects with model settings, tool config, and history. That means the system uses both patterns at once: built-in prompt logic for the agent itself, and separately managed prompt objects for user workflows.
The important takeaway: prompt handling is not uniform across systems. Some start with application-owned prompt templates. Some start with runtime-owned instruction assembly. Many production systems mix both. That difference matters, because the path from prompt-as-code to prompt-as-config depends on where prompt ownership starts.
When prompt templates become configs
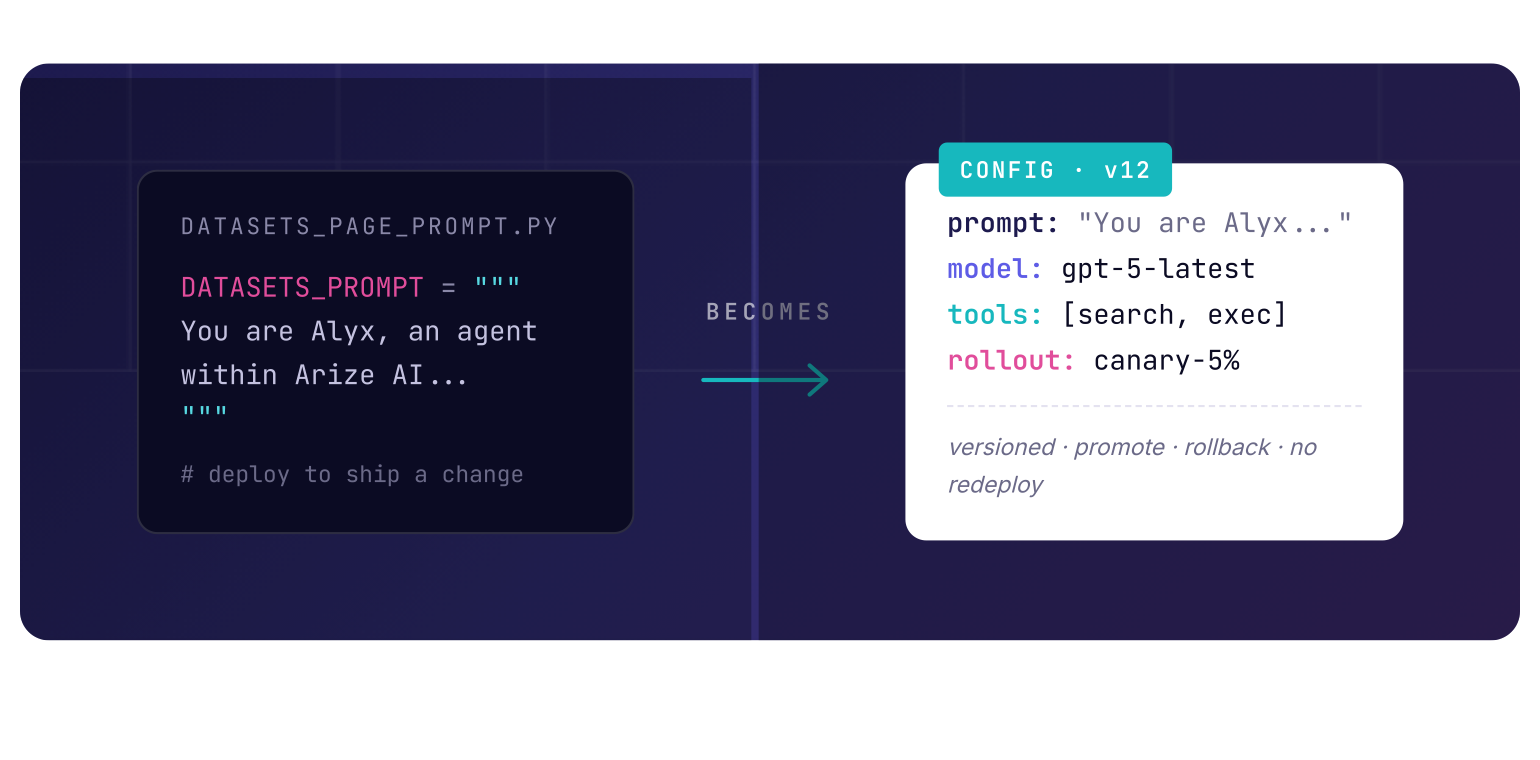
A prompt template becomes config when it needs a lifecycle separate from the application deploy.
As long as a prompt behaves like a static implementation detail, keeping it in code is fine. But once teams need to change prompt behavior without rebuilding and redeploying the application, the prompt stops acting like source text and starts acting like a runtime configuration.
That shift usually happens for operational reasons, not aesthetic ones. Teams want to test a new system prompt, swap models, tune behavior for a workflow, or run an experiment against a subset of traffic without disturbing the current production path. At that point, the deploy pipeline is no longer the right control surface for every prompt change.
This becomes more obvious as the system grows. In a small application, a redeploy may be cheap. In a larger agent system, it often is not. A prompt change may otherwise require rebuilding services, coordinating releases across multiple components, revalidating agent behavior, or pushing a full deploy through production infrastructure just to test a behavioral change. When the agent surface is large, changing config is often much cheaper than redeploying the stack around it.
The important thing is that this is rarely about prompt text alone. In practice, the unit that becomes config is often a larger behavior object: prompt template, model choice, inference parameters, tool settings, retrieval options, and rollout metadata. The prompt is just one field inside that contract.
That gives AI engineers a different operating model. The application can ship with a safe default prompt path, while runtime config can override or inject alternative behavior for tests, canaries, tenant-specific cases, or new agent runs. Production stays stable. New prompt variants can still be exercised in parallel. If the change fails, rollback becomes a config change instead of a full application release (or re-release).
This is why “prompt templates as configs” is useful. It decouples behavioral iteration from code deployment.
This does not mean every prompt should become config. If a prompt is tightly coupled to application logic, changes rarely, or must be reviewed as part of the code path, keeping it in code may still be the right choice. The pattern becomes valuable when prompt behavior changes frequently enough, or matters enough operationally, that it deserves its own versioning, rollout, and rollback model.
A useful rule is this: if changing a prompt changes runtime output, tool use, routing, or decision-making without requiring application logic changes, that prompt is a strong candidate to be managed as config.
Operating prompt templates as config
Once prompt templates become config, the problem is no longer just where the prompt is stored. It’s how that config is delivered, validated, rolled out, and recovered in production.
The first requirement is a safe fallback path. The application should still have a known-good default behavior even if the remote config path is unavailable, stale, or invalid. In practice, that usually means shipping a default working prompt path with the application and allowing runtime config to override it when available. That keeps prompt iteration flexible without turning prompt delivery into a hard dependency for basic system availability.
The second requirement is treating prompt delivery like production infrastructure. Once prompts, model choices, or tool settings are injected at runtime, that injection path has its own reliability concerns. It needs availability targets, caching strategy, timeout behavior, and a clear failure mode. A prompt config service that is slow or unavailable can easily become part of the serving problem. At that point, prompt storage stops being a content problem and becomes an infrastructure problem.
This is also where the experimentation value becomes real. A config-driven system can test a new prompt, model, or tool policy without requiring a redeploy of the agent stack around it. That matters even more in larger systems where deploys are expensive, multi-service, or operationally heavy. A prompt change can be evaluated in a harness, exercised on a shadow path, rolled out to a small cohort, or targeted to a specific tenant while the main production path remains unchanged.
Promotion matters just as much as experimentation. A useful operating model is not just “edit prompt and hope.” It is draft, evaluate, canary, promote, and rollback. The config object moves through stages, not just versions. That gives teams a controlled path from local testing to production adoption, with a clear way to stop or reverse a bad change without shipping application code.
Observability has to follow that lifecycle. Every run should be traceable to the exact config version that produced it: prompt template version, model, inference settings, tool policy, and rollout cohort. Without that, behavior changes become difficult to explain and even harder to compare. Once prompts are treated as config, provenance is not optional.
Validation also becomes more important. If prompt templates are injected dynamically, they need the same defensive controls other runtime config gets: required variables, schema checks, model compatibility, and compatibility with expected tools or output contracts. Otherwise, remote configurability just creates a faster way to ship broken behavior.
Prompt templates as configs are not just about faster edits. They create a separate operational lifecycle for AI behavior: fallback, availability, experiment, promotion, rollback, and traceability.
Practical injection patterns, and the idea of prompt gateways
There is no single correct implementation for prompt templates as configs. The right pattern depends on how dynamic the prompt needs to be, how much rollout control you need, your stack, and how much infrastructure you want to own.
On AWS, AppConfig is a strong fit when prompt templates need staged rollout, validation, rollback, and low-latency retrieval instead of behaving like static files. AWS documents validators, deployment strategies, and automatic rollback tied to CloudWatch alarms, and it recommends the AppConfig Agent as a retrieval path that caches configuration locally and serves it to the application from a local endpoint. For lighter cases, SSM Parameter Store is still a reasonable store for versioned parameters, but it is a simpler primitive than AppConfig for rollout-oriented workflows.
On Azure, Azure App Configuration maps well to prompt-as-config because it is designed to centralize application settings and feature flags rather than just store static values. Microsoft documents dynamic configuration refresh without requiring an application restart, and it also supports immutable snapshots and snapshot references, which are useful for promotion, rollback, and stable environment-specific config states. For AI systems where prompts, model settings, or rollout flags may need to change under a running service, that is a practical pattern.
On GCP, the practical pattern is to separate ordinary configuration from sensitive material. Parameter Manager is the closest managed fit for centralized workload configuration, with versioned parameters and support for structured formats such as YAML and JSON. Secret Manager is the better fit when the payload should be handled as a secret and you want immutable versions, aliases, and audit logging. When the system needs richer control-plane behavior such as structured documents, targeting metadata, or real-time update listeners, Firestore can complement those services as the store for rollout state or assignment rules. That makes GCP less about one single prompt-config product and more about choosing the right managed building blocks for the operational model you want.
This post was written in April 2026. Cloud products, feature maturity, and recommended patterns change over time, so readers should treat these examples as directional guidance.
Lastly, a custom self-built approach is pretty common, especially when teams want one shared prompt registry across agents, products, and experiments. The usual shape is straightforward: a versioned prompt/config store backed by Postgres, Redis, or object storage; a small control service or gateway in front of it; local caches in the serving path; and clear promotion states such as draft, candidate, and production. The advantage is control. The cost is that you now own reliability, validation, access control, cache invalidation, and auditability yourself.
The injection pattern matters as much as the backing store. There are only a few patterns that show up repeatedly:
- Startup load: fetch prompt config when the service starts. Simple, but changes require restart or recycle.
- Periodic refresh: poll for changes on an interval and hot-reload safely.
- Push or listener-based refresh: update long-lived services when config changes are published.
- Per-request lookup with local cache: most flexible, but only viable if the cache and failure mode are well designed.
- Cohort or tenant override: resolve a base config, then layer in environment, experiment, or tenant-specific overrides.
For most production systems, the safest default is still hybrid: ship a known-good local default, allow remote override when available, cache aggressively in the serving path, and attach version metadata to every run. That gives you the main benefit of prompt-as-config without making every inference depend on a fragile live lookup.
This is also the section where the idea of a prompt gateway fits naturally. Once multiple agents or services need prompt injection with availability guarantees, promotion rules, and auditability, a central interface starts to make sense. At that point, the gateway is no longer just storing prompt text. It is serving versioned behavior configs under an operational contract.
For teams already using Arize, there is a natural extension of that pattern. Prompt Playground can sit upstream of the config layer as the place where prompts are edited, compared, and versioned before they are promoted into whatever config system the company already trusts in production.

The important constraint is operational. If the production path needs high availability, Prompt Playground should not become a hard dependency for inference-time resolution. The safer pattern is to treat it as an authoring and evaluation surface, then use the Prompt Hub SDK to move tested prompts into the runtime config path that fits the team’s own architecture.
That also keeps the guidance non-prescriptive. One company may store prompts in AppConfig, another may keep them in Firestore, Redis, Postgres, or an internal control plane. The point is not that every system should adopt one universal prompt registry. The point is that prompts can have a lifecycle, and tools like Prompt Playground can help manage that lifecycle without dictating how the final serving path must be built.
What actually belongs in the config
Once teams start treating prompt templates as config, the next mistake is making the config too narrow.
In practice, the useful unit is rarely just the prompt text by itself. What usually matters at runtime is a larger behavior object: the prompt, the model it is meant for, the parameters that shape generation, the tools it is allowed to use, and the metadata that tells the system how to roll it out safely.
At minimum, the config should include the prompt template itself and the variables required to render it. If the template expects a dataset schema, user role, tool context, or product state, those inputs should be explicit. Hidden dependencies are what make prompt configs brittle.
The next layer is model and inference settings. A prompt often does not behave the same way across models, temperatures, token budgets, or reasoning settings. If those choices are part of the intended behavior, they belong in the same config surface as the prompt instead of being split across unrelated application settings.
Tool and retrieval settings often belong there too. If a prompt assumes access to search, code execution, file context, or a particular retrieval mode, that is part of the behavior contract. Separating the prompt from the capabilities it assumes can make rollout and debugging much harder.
Then there is rollout metadata. Version, environment, owner, promotion state, and experiment assignment are not model behavior themselves, but they are part of operating the config safely. Without that metadata, teams can store prompt variants, but they cannot manage them well.
What should not go into the config is just as important. Business logic, authorization rules, and application invariants should not be delegated to prompt config. The config should shape model behavior, not replace core software guarantees.
A practical config object often ends up including things like:
- prompt template
- required template variables
- model and provider selection
- inference parameters
- tool and retrieval settings
- output format or schema expectations
- version, owner, environment, and rollout metadata
- fallback or default behavior references
The point is not to make the config large for its own sake. The point is to keep the behavior contract in one place so it can be tested, promoted, observed, and rolled back as one unit.
When not to use prompt as configs
Prompt templates as configs are useful, but they are not the default answer for every AI system.
If the prompt changes rarely, is tightly coupled to application logic, or belongs to a small and stable workflow, keeping it in code is often the simpler and better design. The operational overhead of a config path is only worth it when prompt behavior changes often enough, or matters enough, to justify its own lifecycle.
The same is true for systems where remote mutability creates more risk than value. If a prompt is part of a safety-critical path, a compliance-sensitive workflow, or behavior that must move only with code review and release controls, making it dynamically configurable may weaken the guarantees you actually want.
It is also easy to overbuild too early. A single-agent prototype or small internal workflow usually does not need a prompt gateway, rollout engine, or promotion pipeline. If the team has not yet felt real pain from deploy-coupled prompt iteration, building a full config system may just add complexity before it adds leverage.
There is also a class of prompts that are better treated as implementation detail. If a prompt is effectively hardwired to a specific code path, tool contract, or output parser, externalizing it too early can create the illusion of flexibility without giving you much real freedom. In those cases, the prompt may still look configurable on paper while remaining tightly bound to the code around it.
The pattern becomes worth it when the system has enough behavioral surface area that prompt changes need to be tested, rolled out, promoted, and rolled back independently. If that need is not there yet, code is still a perfectly good home for the prompt.
A practical rule is simple: do not move prompts into config because it feels more sophisticated. Move them when the operational benefits clearly outweigh the added control surface.