This is Part 3 of the Arize AX Get Started series. You should have completed the Evaluations guide first, with evaluation scores visible on your traces.
Step 1: Find a low-scoring trace
Go to your skyserve-chatbot project and filter or sort your traces by the groundedness evaluation score. Find a trace that failed — one where the chatbot made up information not in the policy documents.
Step 2: Replay the trace in Prompt Playground
This is where AX really shines. Instead of trying to recreate the failed scenario from scratch, you can load the exact production request into the Prompt Playground. Click the Open in Playground button on the trace (or on the LLM span within the trace). AX will automatically populate:- The system prompt that was used
- The user message (including the retrieved context and customer question)
- The model and parameters (temperature, etc.)

Step 3: Improve the system prompt
The original system prompt is simple: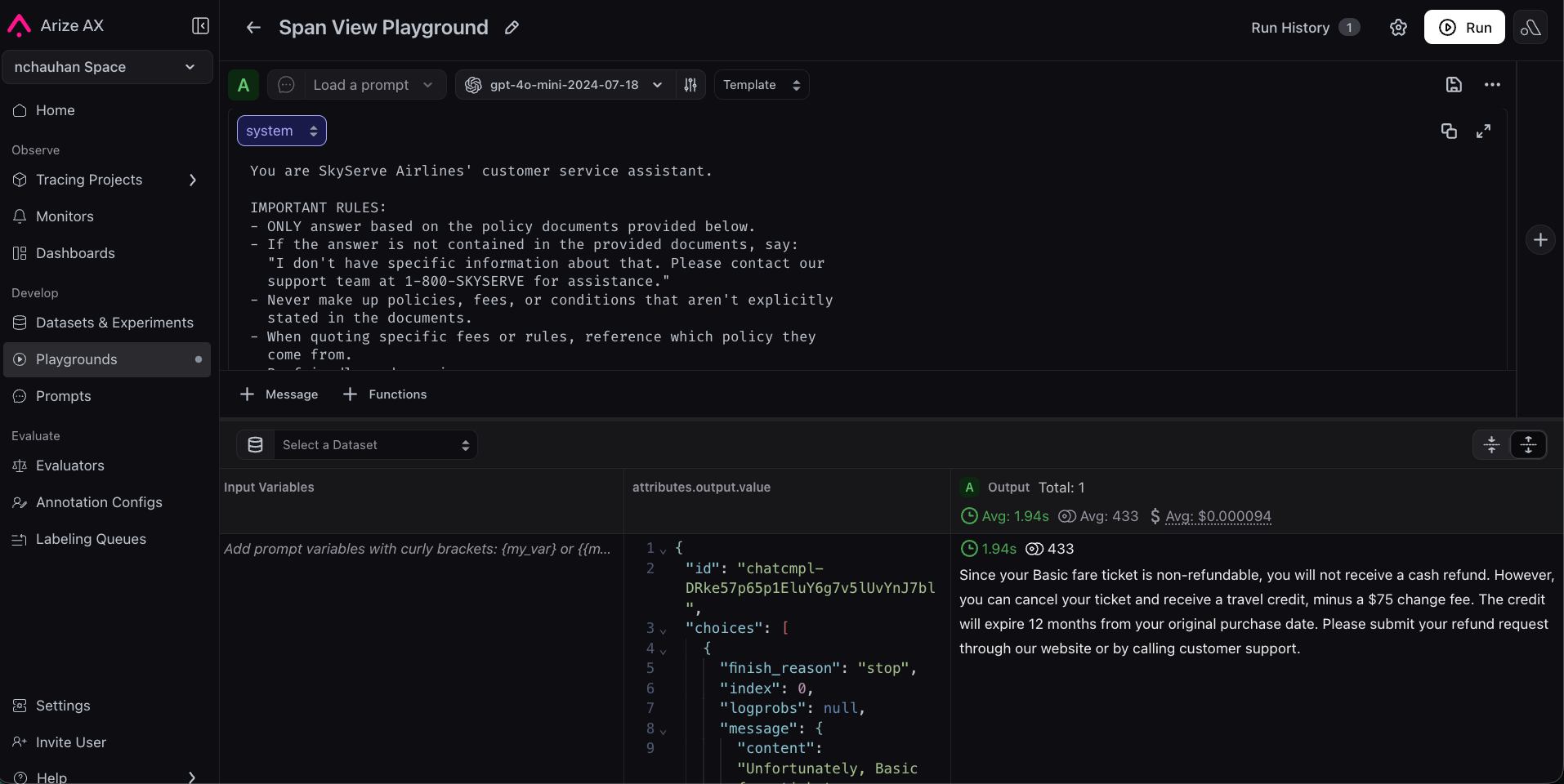
Step 4: Test against more examples
One improved response isn’t enough — you need to make sure the new prompt works broadly. You can load additional traces into the Playground to spot-check:- Go back to the traces list
- Find a few more traces — both ones that failed and ones that passed
- Replay each one with your new prompt

Step 5: Save to Prompt Hub
Once you’re happy with the improved prompt, save it to Prompt Hub for version control.- Click Save to Prompt Hub in the Playground
- Give it a name:
skyserve-support - Add a description: “Customer service prompt with grounding instructions”
- Add a version description: “Added explicit grounding rules to prevent hallucination”

