
Google’s Gemini models represent a powerful leap forward in multimodal AI, particularly in their ability to process and transcribe audio content with remarkable accuracy. However, even advanced models require robust monitoring and evaluation frameworks to ensure consistent quality in production environments.
This is where Arize’s tracing and evaluation capabilities become invaluable. By combining Gemini’s audio transcription prowess with Arize AX’s OpenTelemetry-based tracing infrastructure and the Phoenix evaluation framework, developers can gain unprecedented visibility into their audio processing pipelines.
This blog walks through implementing a complete workflow that not only generates high-quality transcriptions, but also traces each step of the process and evaluates Gemini’s transcription outputs for sentiment analysis, allowing teams to identify issues, measure quality, and continuously improve their audio-based AI applications.
Let’s jump in!
Setting Up Your Environment
The rest of this blog is based on the accompanying tutorial notebook.
Before diving into audio processing with Gemini and tracing with Arize, we need to set up our environment with the necessary dependencies and API configurations. This section will guide you through the installation process and credential setup.
Get Started with Arize AX and Google Cloud
- Sign up for a free Arize AX account and access space, api and developer keys.
- Set up a Google Cloud account and a project ID with access to Gemini API in order to access Gemini Models used in this tutorial.
%pip install -q -U google-genai arize-phoenix-evals arize-phoenix opentelemetry-api opentelemetry-sdk openinference-semantic-conventions arize-otel
Once the dependencies are installed, we can import the necessary modules:
from google import genai
import getpass
import os
import opentelemetry
from opentelemetry import trace
from arize.otel import register
from opentelemetry.trace import Status, StatusCode
from opentelemetry.semconv.trace import SpanAttributes
Configuring API Credentials
Next, we need to set up our API credentials for both Gemini and Arize. For this tutorial you will need a Gemini API Key and Arize Space ID, API Key and Developer Key.
# Configure Gemini API key
GEMINI_API_KEY = getpass.getpass(prompt="Enter your Gemini API Key: ")
gemini_client = genai.Client(api_key=GEMINI_API_KEY)
# Configure Arize credentials
ARIZE_SPACE_ID = getpass.getpass(prompt="Enter your ARIZE SPACE ID Key: ")
ARIZE_API_KEY = getpass.getpass(prompt="Enter your ARIZE API Key: ")
ARIZE_DEVELOPER_KEY = getpass.getpass(prompt="Enter your ARIZE DEVELOPER Key: ")
PROJECT_NAME = "gemini-audio" # Set this to any name you'd like for your app
Setting Up OpenTelemetry Tracing
With our credentials in place, we can now initialize the OpenTelemetry tracing infrastructure that will power our observability pipeline. Arize provides a convenient register function that handles most of the setup for us:
# Setup OTel via our convenience function
tracer_provider = register(
space_id = ARIZE_SPACE_ID,
api_key = ARIZE_API_KEY,
project_name = PROJECT_NAME,
)
trace.set_tracer_provider(tracer_provider)
tracer = trace.get_tracer(__name__)
This configuration establishes the connection between our application and the Arize platform, allowing us to send traces and spans that capture the full lifecycle of our audio processing pipeline.
Preparing Audio Sample
For this tutorial, we’ll use a sample audio file—a recording of President John F. Kennedy’s 1961 State of the Union address. Let’s download it and upload it to Gemini:
# Define the audio file URL
URL = "https://storage.googleapis.com/generativeai-downloads/data/State_of_the_Union_Address_30_January_1961.mp3"
# Download the audio file
!wget -q $URL -O sample.mp3
# Upload the audio file to Gemini
your_file = gemini_client.files.upload(file='sample.mp3')
With this setup complete, we now have all the necessary components to begin processing audio with Gemini and tracking the entire process using Arize’s tracing capabilities.
Audio Processing with Gemini and Tracing with Arize
Now that our environment is configured, we can implement the core functionality of our application: processing audio with Gemini while tracing the entire workflow with Arize. This section demonstrates how to create a structured tracing pipeline that captures each step of the audio transcription process.
Defining the Transcription Task
Let’s start by defining a simple prompt to direct Gemini’s transcription. For this example, we’ll focus on a specific segment of the audio file:
prompt = "Provide a transcript of the speech from 01:00 to 01:30."
Implementing Tracing with OpenTelemetry
One of the key benefits of using Arize’s tracing framework is the ability to create structured spans that represent different stages of our processing pipeline. For brevity, we’ll create three spans to represent our workflow:
- audio_input: Records the initial input prompt
- process_audio: Captures the actual LLM processing of the audio file
- transcript_output: Logs the final transcript result
This hierarchical structure allows us to visualize the complete flow of data through our application and measure performance at each stage.
# Instrumentation: Generate 3 Spans: audio_input --> process_audio with Gemini --> transcription text output
with tracer.start_as_current_span(
"audio_input",
openinference_span_kind="chain",
) as span:
span.set_attribute("input.value", prompt)
span.set_status(Status(StatusCode.OK))
with tracer.start_as_current_span(
"process_audio",
openinference_span_kind="llm",
) as span:
span.set_attribute("input.audio.url", URL)
span.set_attribute("llm.prompts", prompt)
span.set_attribute("input.value", prompt)
# Call Gemini
response = gemini_client.models.generate_content(
model='gemini-1.5-flash',
contents=[
prompt,
your_file,
]
)
span.set_attribute("output.value", response.text)
with tracer.start_as_current_span(
"transcript_output",
openinference_span_kind="chain",
) as span:
span.set_attribute("output.value", response.text)
span.set_attribute("output.audio.transcript", response.text)
Understanding Span Attributes
In the code above, we’re adding several attributes to our spans:
- input.value: Captures the input prompt or data
- input.audio.url: Records the URL of the audio file
- llm.prompts: Stores the exact prompt sent to Gemini
- output.value: Captures the full response text
- output.audio.transcript: Specifically labels the response as a transcript
These attributes enrich our tracing data, making it more useful for analysis and debugging. When viewed in the Arize platform, these traces provide a comprehensive picture of how our application processes audio inputs and generates transcriptions.
Examining the Response
After executing the code, we can examine the text transcription from Gemini:
print(response.text)
This will display the transcription of the specified segment of the audio file. The exact same text is also captured in our trace, allowing for easy correlation between application behavior and trace data.
Visualizing Traces in Arize
Once the execution completes, the spans are automatically sent to the Arize platform where they can be visualized and analyzed. The hierarchical structure of our spans allows us to see the complete flow of data:
- The audio_input span shows the initial prompt and marks the beginning of the process
- The process_audio span contains the LLM processing details including model information and timing
- The transcript_output span captures the final result
This trace data provides valuable insights into performance, latency, and the overall behavior of our audio processing pipeline. By clicking on a span in the Arize UI, you can view all of its attributes, including the full text of prompts and responses. A link to the audio input file is provided so you can playback the audio.
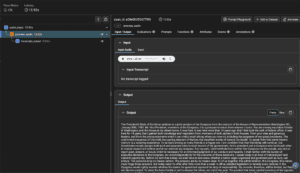
With our tracing pipeline in place, we now have full visibility into our audio transcription process. Next, we’ll explore how to evaluate the quality of these transcriptions using sentiment analysis.
Implementing Evaluation with Gemini as Judge
With our audio transcription pipeline successfully implemented and traced, we can now focus on evaluating the quality of the transcripts. In this section, we’ll implement a sentiment analysis evaluation using Gemini as a judge to evaluate its own outputs—a technique often called “LLM-as-Judge.”
Retrieving Transcription Outputs from Arize
First, we need to retrieve the transcript outputs from Arize to evaluate them. We’ll use Arize’s export functionality to pull the relevant spans:
from datetime import datetime, timezone, timedelta
from arize.exporter import ArizeExportClient
# Initialize the export client
client = ArizeExportClient()
# Export traces containing transcript outputs
primary_df = client.export_model_to_df(
space_id=ARIZE_SPACE_ID,
model_id=PROJECT_NAME,
where="name = 'transcript_output'", # Just pull the spans with name = "transcript_output"
environment=Environments.TRACING,
start_time=datetime.fromisoformat('2025-03-20T07:00:00.000+00:00'),
end_time=datetime.fromisoformat('2025-04-01T06:59:59.999+00:00')
)
# Add a column specifically for our evaluation templates
primary_df["output"] = primary_df["attributes.output.value"]
This code exports only the spans that are labeled with “transcript_output” (from our instrumentation above) from a specific time range and prepares a DataFrame for evaluation by setting an output column that our evaluation template will reference.
Creating an Evaluation Template
SENTIMENT_EVAL_TEMPLATE = """
You are a helpful AI bot that checks for the sentiment in the output text. Your task is to evaluate the sentiment of the given output and categorize it as positive, neutral, or negative.
Here is the data:
[BEGIN DATA]
============
[Output]: {attributes.output.value}
============
[END DATA]
Determine the sentiment of the output based on the content and context provided. Your response should be ONLY a single word, either "positive", "neutral", or "negative", and should not contain any text or characters aside from that word.
Then write out in a step by step manner an EXPLANATION to show how you determined the sentiment of the output. Do not include any text or characters aside from the EXPLANATION. Do not include special characters such as "#" in your response.
Your response should follow the format of the example response below. Provide a LABEL and EXPLANATION. Do not include any special characters or line breaks.
Example response:
============
EXPLANATION: An explanation of your reasoning for why the label is "positive", "neutral", or "negative"
LABEL: "positive" or "neutral" or "negative"
============
"""
This template is carefully structured to:
- Clearly define the task for how Gemini should evaluate the text transcription output from the audio processing step on this variable: {attributes.output.value}
- Specify the exact format expected in the response: LABEL and EXPLANATION
- Request a step-by-step explanation of the reasoning
Setting Up the LLM-as-Judge Evaluation
Now we can use Phoenix Evals, part of the Arize ecosystem, to run our sentiment evaluation:
import pandas as pd
import os
import phoenix.evals
from phoenix.evals import (
GeminiModel,
llm_classify,
)
# Configure Google authentication for Phoenix Evals
!gcloud auth application-default login
!gcloud config set project audioevals
# Initialize the Gemini model for evaluation
project_id = "audioevals"
gemini_model = GeminiModel(model="gemini-1.5-pro", project=project_id)
# Define possible sentiment categories
rails = ["positive", "neutral", "negative"]
# Run the evaluation
evals_df = llm_classify(
data=primary_df,
template=SENTIMENT_EVAL_TEMPLATE,
model=gemini_model,
rails=rails,
provide_explanation=True
)
# Prepare the results for logging back to Arize
evals_df["eval.sentiment.label"] = evals_df["label"]
evals_df["eval.sentiment.explanation"] = evals_df["explanation"]
evals_df["context.span_id"] = primary_df["context.span_id"]
In this code:
- We authenticate with Google Cloud to use Gemini (You will need an account and project id created prior to running this cell)
- We initialize the Gemini model for evaluation (note this could be different from the model used for transcription). In this case we use gemini-1.5-pro, known for it’s reasoning capabilities.
- We define the possible sentiment categories as “rails” [“positive”, “neutral”, “negative”]
- We run the evaluation using llm_classify, which applies our template to each transcript
- We format the results for logging back to Arize
Examining the Evaluation Results
After running the evaluation, we can examine the results:
evals_df.head()
This shows us a DataFrame containing:
- The sentiment label assigned to each transcript
- The explanation for each sentiment determination
- Execution information such as status and processing time
- References back to the original spans via context.span_id

Sending Evaluation Results to Arize
Finally, we can send these evaluation results back to Arize to connect them with our original traces:
from arize.pandas.logger import Client
# Initialize Arize client
arize_client = Client(
space_id=ARIZE_SPACE_ID,
api_key=ARIZE_API_KEY,
developer_key=ARIZE_DEVELOPER_KEY
)
# Send the evaluation results to Arize
arize_client.log_evaluations_sync(evals_df, "gemini-audio")
This links our evaluation results with the original traces in Arize, creating a comprehensive view of both the transcription process and the quality assessment.
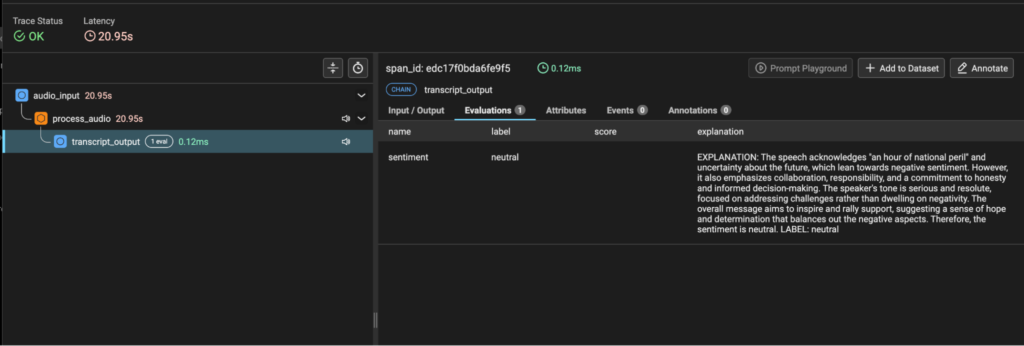
By implementing this evaluation pipeline, we’ve added a crucial layer of quality assessment to our audio transcription workflow. This allows us to not only monitor the transcription process but also to understand the sentiment patterns in the transcribed content, which could be valuable for applications like customer sentiment analysis from call recordings.
Resources and Next Steps
As we’ve demonstrated throughout this blog, combining Gemini’s powerful audio processing capabilities with Arize’s tracing and evaluation framework creates a robust system for building and monitoring audio transcription applications. Here’s a summary of what we’ve covered in this guide.
Key Takeaways
- End-to-End Observability: Using OpenTelemetry with Arize provides comprehensive visibility into your audio processing pipeline, from initial prompt to final transcript.
- Quality Assessment: Implementing LLM-as-Judge evaluations with Gemini allows you to objectively assess transcript sentiment without human annotation.
- Complete Workflow: We’ve implemented a full pipeline from audio input to sentiment evaluation, with complete observability across the entire process.
Final Thoughts
The combination of advanced multimodal AI like Gemini with robust observability tools like Arize represents a powerful approach to building reliable AI systems. By implementing proper tracing and evaluation, you can ensure that your audio processing applications deliver high-quality results that can be monitored, measured, and improved.
We hope this guide helps you implement audio processing pipelines with confidence and clarity. The tracing and evaluation techniques demonstrated here provide a foundation for building responsible and observable AI systems.
Resources
To continue your journey with Gemini audio processing and Arize tracing, here are some valuable resources:
- Gemini Models – Explore the family of Google’s Gemini models for various use cases.
- Arize Documentation – Comprehensive guides for tracing and evaluation
- Tracing Overview – To deepen your understanding of tracing concepts
- Phoenix Evals GitHub– For exploring evaluation techniques
Happy building!