


Shipping an AI agent is easy. Understanding whether it actually works in production is not.
That was the common thread across two AI Builders events in San Francisco at GitHub HQ and Seattle at The Collective, where a few hundred developers gathered to share what they’re learning from deploying agents.
The AI Builders series is designed to bring together the people building AI systems. Rather than just celebrate AI, the goal is to compare notes on what’s working, what’s breaking, and what reliable agent architecture actually needs to look like at scale.
Across five talks and countless hallway conversations, one theme stood out: success with AI agents is no longer defined by model capability alone. It depends on infrastructure and engineering practices like evaluation, observability, orchestration, and governance.
If you’re building or scaling agents in production, here are a few key lessons and architectural patterns to consider.
TL;DR for developers building with agents
- Build an evaluation harness early. It matters more than model selection. Don’t wait until production to measure quality. Define task success metrics, create representative datasets, and automate scoring so you can catch regressions and iterate with confidence.
- Separate fast and powerful models to balance latency and quality. Use low-latency models for real-time user interactions and higher-capability models for background planning or complex reasoning. Clear role separation improves both responsiveness and output quality.
- Instrument observability on real user sessions. Benchmarks are useful, but production behavior is what matters. Capture traces, tool calls, and user feedback to understand how agents actually perform and diagnose failures quickly.
- Apply prompt learning loops to improve agent performance without changing models. Iteratively refine system prompts using an action, evaluation, and improvement cycle. This RL-inspired approach can significantly boost agent performance without changing model weights or system architecture.
- Measure quality alongside velocity. AI tools can increase development speed, but without quality metrics like task success rate, code churn, and rework, you risk optimizing for output rather than real productivity.
AI Builders SF: Building and evaluating the next generation of AI agents
March 31, 2026 · GitHub HQ, San Francisco · Co-hosted with M12 (Microsoft’s Venture Fund)
Nearly 200 developers gathered at GitHub’s HQ in San Francisco, most already running agents in production. The conversation focused on a shared challenge: making those agents reliable through better governance and evaluation.

Manage AI agents at scale with Foundry Control Plane
Amanda Foster, Microsoft
Amanda Foster, a product manager at Microsoft, opened with a challenge a lot of teams are running into: you’ve deployed an agent, or maybe a handful of agents, and now you have no idea what they’re doing or how to govern them at scale.
As agent systems move from prototypes to production, they require a new operational layer, much like distributed systems rely on control planes, logging, and monitoring. Foster highlighted the concept of a control plane, such as Microsoft’s Foundry Control Plane, as a way to coordinate multi-agent systems and ensure they remain reliable.
More broadly, this reflects a shift toward a new operational stack for AI — one that brings together orchestration, observability, governance, and evaluation.
Core components of the agent operational stack
- Orchestration: Coordinate workflows and communication between agents and tools.
- Observability and tracing: Capture prompts, tool calls, latency, and outcomes to understand real-world behavior (for example, Arize AX and the open-source Phoenix platform).
- Evaluation pipelines: Continuously measure task success and detect regressions with automated and human-in-the-loop evaluations.
- Policy and governance: Enforce permissions, guardrails, and cost controls for safe and predictable behavior.
- Human-in-the-loop controls: Enable approval, override, or rollback for high-risk actions.
Takeaway: Successful agentic systems require an operational stack — not just capable individual agents. Early decisions around orchestration, observability, and governance compound quickly as systems scale.

Lessons from building and evaluating a production agent with Arize Alyx
Nancy Chauhan, Arize AI
We built Alyx as an AI engineering agent inside Arize AX to help developers build, debug, evaluate, and improve their AI systems. Developing Alyx also served as a forcing function for rethinking how production agents should be evaluated and underscored how evaluating a production agent differs from evaluating a prototype.
Early in development, the team over-indexed on benchmark performance and underweighted the failures that only emerge in real user sessions. The key lesson: offline benchmarks are necessary but insufficient for evaluating production agents.
Production environments introduce unpredictable failure modes such as tool misuse, context drift, and ambiguous user intent that rarely appear in controlled datasets. That means evaluation harnesses must capture real-world behavior and support continuous monitoring rather than relying solely on periodic testing.
What changes from prototype to production?
| Dimension | Prototype evaluation | Production evaluation |
|---|---|---|
| Data | Static benchmark datasets | Real user interactions |
| Metrics | Accuracy or pass rate | Task success, latency, cost, user satisfaction |
| Failure modes | Known and controlled | Emergent and unpredictable |
| Feedback loop | Periodic testing | Continuous monitoring |
| Human review | Optional | Essential for ambiguous cases |
Key metrics to consider
Developers should expand beyond simple accuracy metrics to include:
- Task success rate: Did the agent accomplish the intended goal?
- Tool success rate: Were external tools used correctly?
- Latency: How long did the agent take to complete the task?
- Cost per task: What was the resource consumption?
- User feedback or satisfaction: How did end users perceive the outcome?
- Failure categorization: What types of errors occur most frequently?
Takeaway: Evaluating production agents requires continuous, real-world measurement. The quality of the evaluation harness often matters more than benchmark performance.

AI Builders Seattle: Architecture, optimization, and productivity
April 2, 2026 · The Collective Seattle · Seattle, WA
Two days later, the conversation moved to Seattle, where the focus shifted to developer workflows and the real-world impact of AI-assisted coding. The talks spanned architecture, prompt optimization, and productivity, with each addressing a different piece of the challenge of scaling AI-powered developer tools.

Multi-model orchestration: The new standard architecture
Chi Wang, Founder of AutoGen / AG2, Google DeepMind
Chi Wang, creator of AutoGen, one of the most widely used multi-agent frameworks, showcased a vision of agentic systems that operate continuously — handling real-time interactions while running background tasks.
His key insight: production agents rarely rely on a single model. Instead, they orchestrate multiple models with distinct roles to balance latency, cost, and capability.
Fast, low-latency models handle real-time user interactions, while more capable models manage background planning and complex reasoning. This multi-model pattern is quickly becoming the default architecture for production AI systems.
Multi-model architecture pattern
| Layer | Model type | Purpose |
|---|---|---|
| Interaction | Fast, low latency | User-facing responses |
| Planning | High capability | Complex reasoning and task decomposition |
| Execution | Specialized | Tool use and task-specific operations |
| Evaluation | Independent | Quality and reliability measurement |
Orchestration example
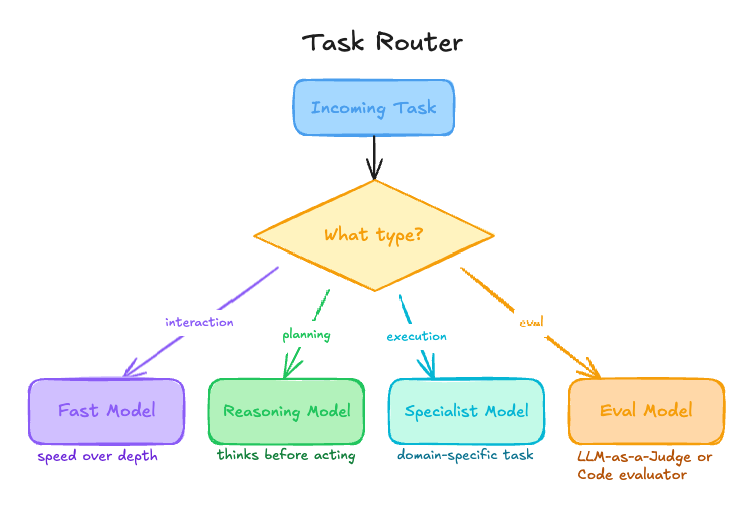
When to use each model type
- Fast models: Real-time chat, UI interactions, and quick classification tasks.
- High-capability models: Planning, reasoning, and long-horizon problem solving.
- Specialized models: Code execution, retrieval, or domain-specific tasks.
- Keep the judge separate from the system being judged: Using a different model to run evals helps prevent self-grading bias.
Takeaway: Effective agent systems are defined not by a single model’s capability, but by how multiple models are orchestrated to work together across the workflow.

Boosting Claude Code performance with prompt learning
Jim Bennett, Arize AI
Jim Bennett, a principal developer experience engineer at Arize, shared how prompt learning can significantly improve agent performance without changing the underlying model. Using an RL-inspired loop — action, evaluation, and improvement — the team iteratively refined the system prompt based on natural language feedback from evaluation results.
The impact was substantial: optimized prompts alone led to up to an 11% improvement on SWE-Bench Lite for Claude Code, making prompt optimization one of the most cost-effective levers for enhancing agent performance.
Example: a prompt-learning workflow
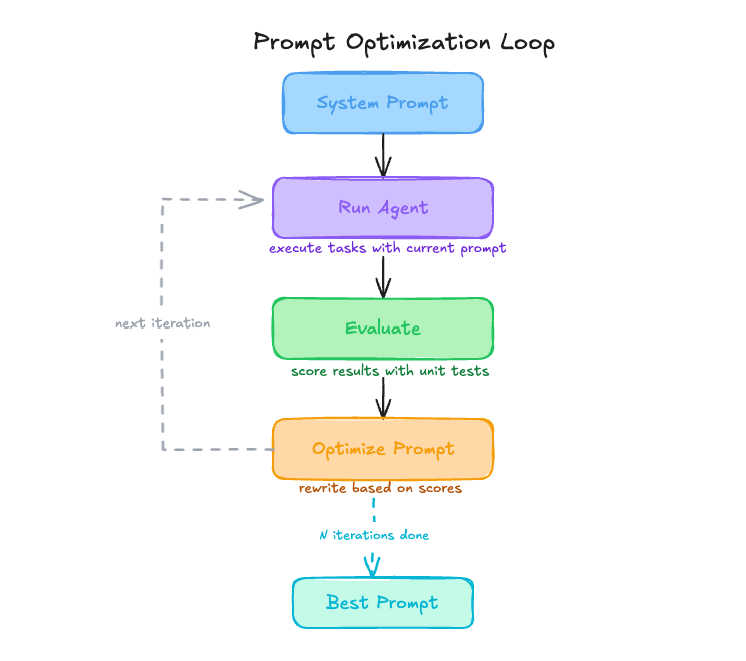
This loop mirrors a reinforcement learning cycle, where evaluation signals guide iterative improvements to the system prompt.
How a prompt-learning workflow loop works
- Run the agent on a representative task set (for example, SWE-Bench).
- Evaluate outputs using deterministic metrics such as unit tests.
- Refine the system prompt using LLM-generated feedback.
- Repeat until performance improvements plateau.
An additional insight was that incorporating a project’s Git history into the evaluation and optimization process significantly improved success rates for in-repo tasks. By learning a repository’s conventions and architectural patterns, the agent becomes better aligned with the codebase it operates in.
When to use prompt learning
- Model changes are impractical due to cost or deployment constraints.
- Domain-specific behavior is required for a particular codebase or workflow.
- Deterministic evaluation signals, such as unit tests, are available.
- Rapid iteration is needed without modifying system architecture.
Takeaway: Meaningful gains in agent performance don’t always require new models. Often, better instructions and a robust evaluation loop are enough.

Measuring developer productivity in AI-assisted workflows
Chris Griffing, GitKraken
Chris Griffing shared one of the most provocative insights of the night: across more than 2,000 teams using AI coding tools, developer productivity is up roughly 25%, but code churn increased by 9x. While the exact methodology varies by organization, the trend highlights a growing gap between speed and code stability.
Teams are shipping faster, but the volume of code that gets written and then reverted or rewritten has exploded. The implication isn’t that AI tools are bad, but that measuring productivity by output volume alone misses the true signal of engineering impact.
Metrics to track for AI-assisted development
Developers and engineering leaders should track a balanced set of speed and quality metrics to understand the real impact of AI on their workflows:
- Task success rate: The percentage of AI-assisted tasks that achieve their intended outcome without significant rework.
- Rework or code churn: The frequency with which AI-generated code is modified, reverted, or rewritten.
- Time to merge: The duration from pull request creation to merge, reflecting review efficiency and code readiness.
- Bug introduction rate: The number of defects introduced in AI-assisted changes relative to human-written code.
- Developer satisfaction: Qualitative feedback indicating whether AI tools genuinely improve the developer experience.

What we’re seeing
Across both cities, a few consistent patterns emerged from the talks, Q&As, and conversations afterward:
- Evaluation design is still underinvested. Every team we talk to uses AI models. Not every team has a real eval pipeline. The ones that do move faster and waste less time debugging the wrong things.
- The evaluation harness matters more than many teams expect. Chris’ talk, Jim’s talk, and our own Alyx experience all point in the same direction. You can get more out of your agent by improving the infrastructure around it than by swapping models.
- Production surprises you. The failure patterns you see in development don’t hold in production. You need real observability on real user sessions, not just benchmark scores from a controlled split.
Join us at the next AI Builders event near you
We’re keeping this going. The next AI Builders events are open for registration now.
AI Third Thursdays: April 16, San Francisco
We’re opening up the new Arize rooftop in downtown San Francisco for the first night of a brand new monthly Thursday series. These nights are specifically for AI builders to connect, share what they’re working on, and hang out. The first one is April 16, so mark your calendar and RSVP.
Arize Observe: June 4, San Francisco
Our flagship full-day conference. June 4 at Shack15 at the Ferry Building — a full day covering evals, observability, and the real engineering challenges behind production AI systems. More details coming soon.