A version of this article originally appeared on X.
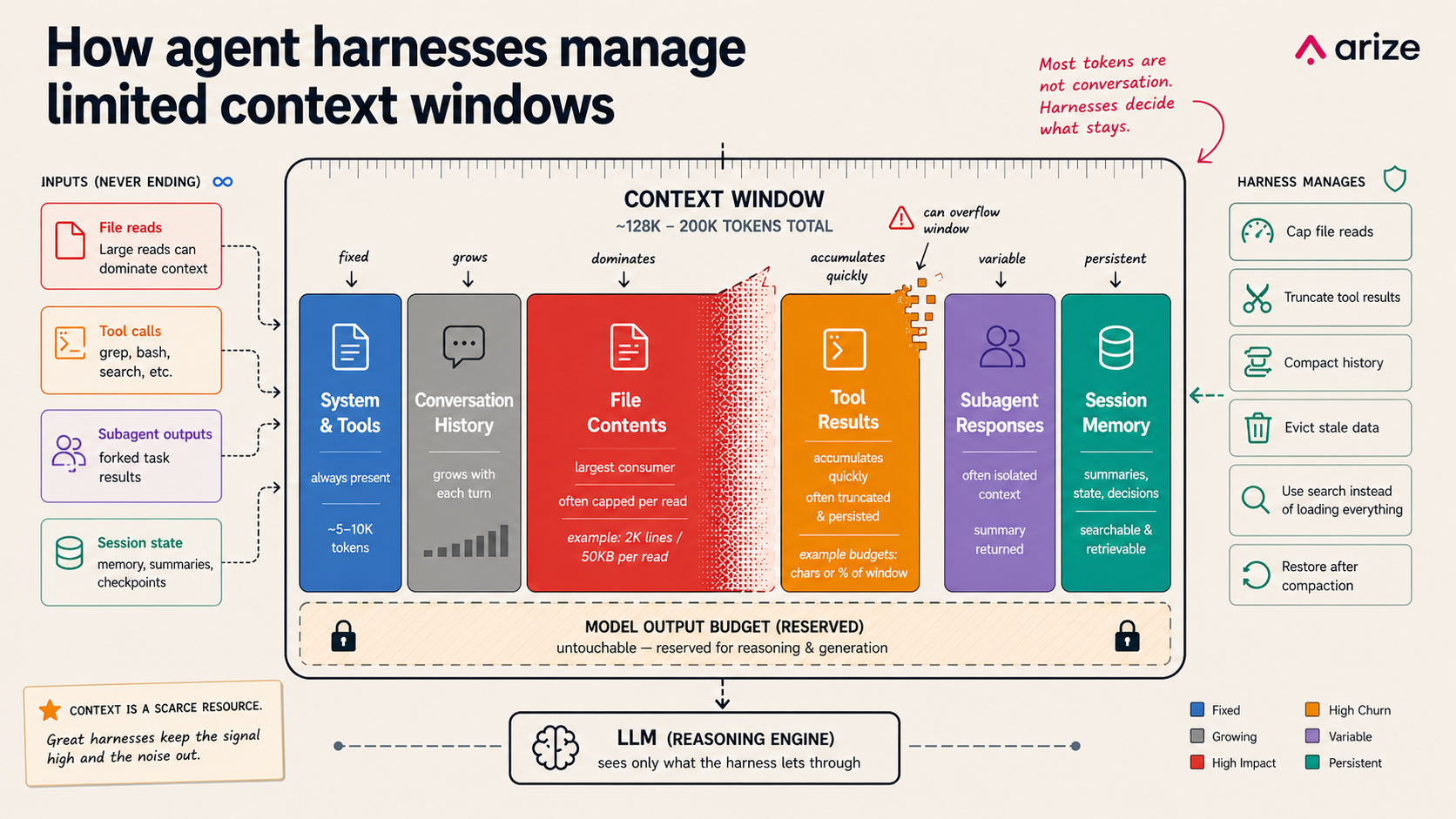
Every agent harness runs into the same limit: the context window is too small for everything the model might want to remember. As sessions grow, file reads expand, subagent calls multiply, and tool outputs pile up, the harness has to decide what stays in the working set, what gets compressed, and what gets retrieved later.
We’ve spent the last two years building Alyx, Arize’s in-product agent, and we have hit every version of this problem. We saw sessions grow until the model lost track of the task, file reads consume half the context window with boilerplate, and tool results crowd out the actual conversation.
The important question is no longer just what goes into the prompt. It is how the harness manages context over time. The best systems do not treat the context window like a passive transcript buffer. They manage it actively: keeping high-value state close, paging through data on demand, building indexes to find what’s needed (grep does this), and truncating content in a way that hints at what else can be accessed.
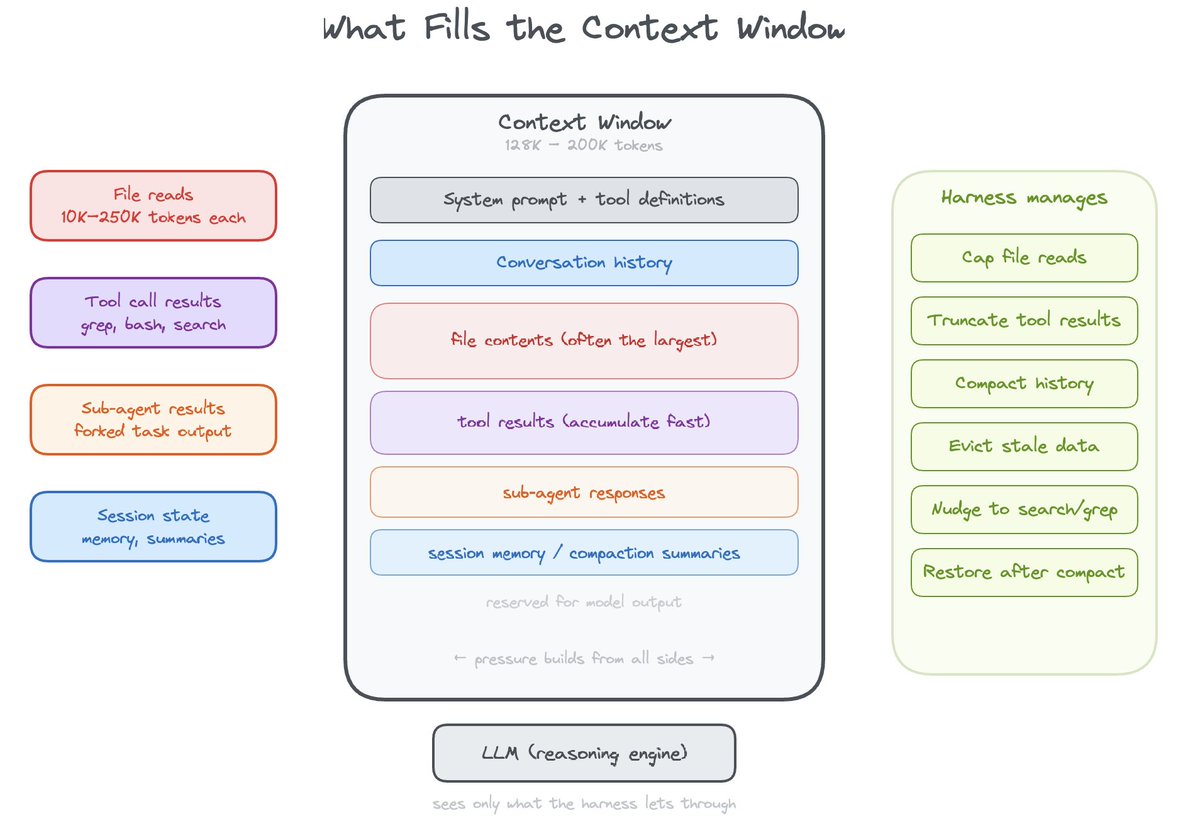
Pi, OpenClaw, Claude Code, and Letta all make different choices here, but they are converging on a similar underlying pattern. Context is no longer just whatever fits in the transcript. It is something the system has to manage actively. The real design question is how much of that management happens inside the harness, and how much the model is expected to do for itself.
Why context management matters for AI agents
Context management determines whether long-running agents stay coherent. It affects how well an agent can inspect files, remember prior decisions, call tools, delegate to subagents, and recover from context pressure. If the harness gets this wrong, the model may lose the task, miss important state, or waste most of its context on low-value output.
In practice, every context management decision encodes an assumption about model behavior. Should the harness proactively constrain context usage, or should it rely on the model to manage the budget correctly on its own?
The bet: trust the model to manage its own context
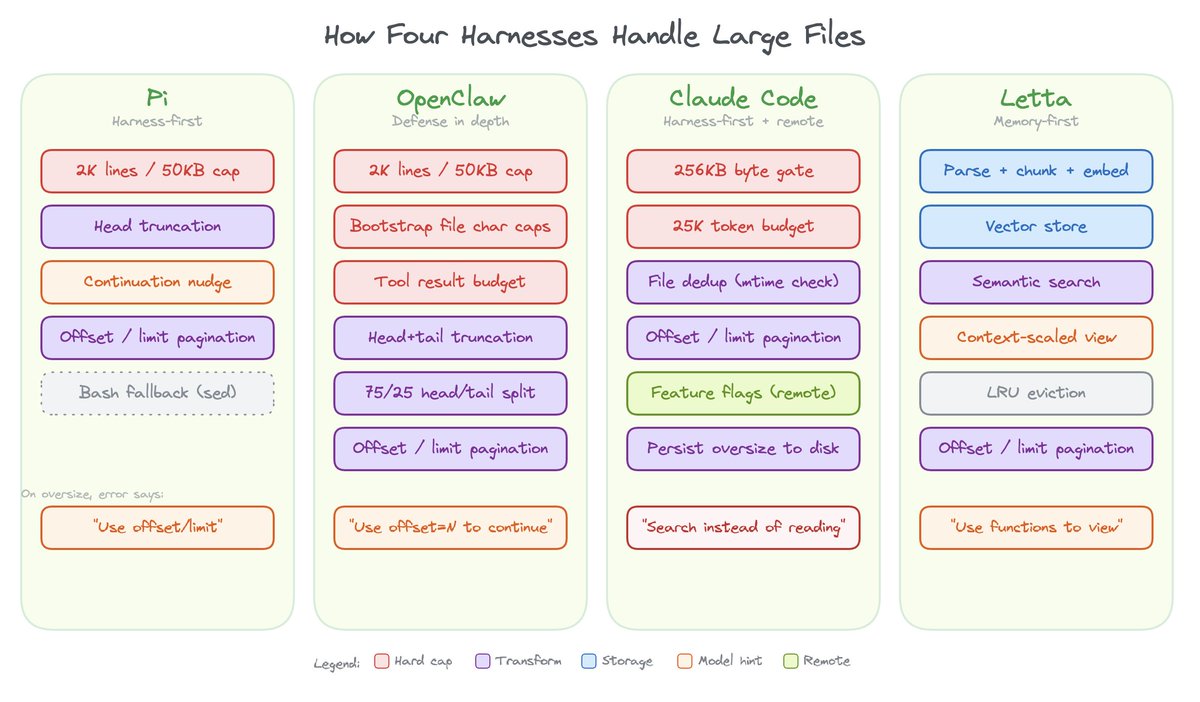
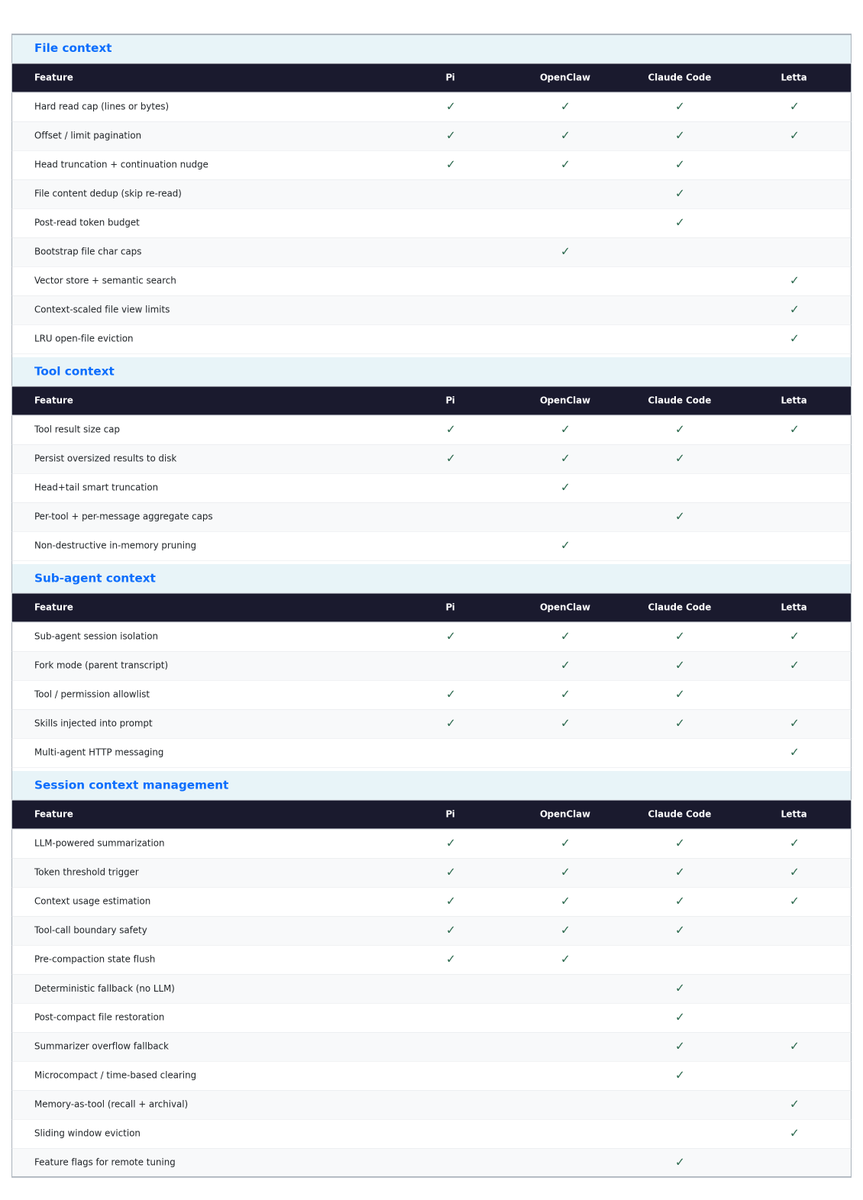
File reads make this concrete. When a model needs to read a file larger than what fits in context, someone has to decide what to keep. All four harnesses support offset and limit parameters for pagination.
Pi (pi-mono)
Pi reads files with a hard cap of 2,000 lines or 50KB, whichever hits first, even if the model doesn’t ask for a slice. Content is head-truncated, and the tool output appends an explicit continuation nudge: [Showing lines 1-2000 of 50000. Use offset=2001 to continue.] The tool description reinforces this: “output is truncated to 2000 lines or 50KB. Use offset/limit for large files.”
Pi’s approach is harness-first: the harness protects you, then teaches the model to paginate.
OpenClaw
OpenClaw inherits Pi’s read tool and its 2K line / 50KB truncation. It acts the same on normal file reads. On top of that, it layers additional caps for bootstrap files, one-time context files loaded at session start: 12,000 chars per file and 60,000 chars total. When a bootstrap file exceeds its budget, it uses a 75% head / 25% tail split: you see the beginning and end, with the middle cut.
Tool results get a separate budget: 16,000 chars or 30% of the context window, whichever is smaller. When the tail looks “important” (errors, JSON close braces, summary keywords), it switches to head+tail mode; otherwise it just keeps the beginning.
OpenClaw’s approach is defense in depth: Pi’s truncation as the first layer, then additional caps on bootstrap injection, then tool result budgets on top.
Claude Code
Claude Code applies a two-layer defense on file reads. The first gate is a 256KB byte cap checked via a stat call before the file is even opened – if the file exceeds that, the read is rejected immediately with an error that points the model to use offset/limit or grep instead. The second gate runs after the read: the output is token-counted against a 25,000 token budget, catching files that slip under the byte cap but are token-dense. Both limits are remotely tunable by Anthropic via GrowthBook feature flags without shipping a new release.
Even when a file is under the cap, the tool defaults to returning 2,000 lines from the beginning, and any line longer than 2,000 characters gets truncated. The model has to explicitly request more with offset and limit parameters.
The tool description is a full multi-paragraph prompt that explains pagination, mentions the size cap, covers image/PDF/notebook support, and encourages parallel reads across multiple files. The offset and limit parameters have their own descriptions telling the model they’re for files too large to read at once. There’s also a conditional instruction that surfaces the 256KB cap directly in the prompt depending on a feature flag.
The file dedup system is worth noting too. If the model re-reads the same file at the same range and the time hasn’t changed, Claude Code returns a stub instead of the full content, avoiding duplicate tokens in context.
Claude Code’s approach is harness-first with remote tunability: a pre-read byte gate, a post-read token gate, line-count and line-length defaults, an actionable error message, a rich tool prompt, read deduplication, and feature flags that let Anthropic adjust all of it server-side.
Letta
Letta takes a fundamentally different approach. Every uploaded file is parsed, chunked, and embedded into a vector store, so the agent gets both exact and semantic search. This gives it three file tools: open_files for direct viewing (reads raw text), grep_files for exact pattern matching (also raw text), and semantic_search_files for meaning-based retrieval against the embedded passages.
When a file is “open” in the agent’s context, its visible content is truncated to a per-file character limit that scales with the model’s context window across five tiers: 5,000 chars for 8K context, 15,000 for 32K, 25,000 for 128K, and 40,000 for 200K+. The number of simultaneously open files scales too, from 3 for small models up to 15 for very large ones, with a fallback default of 5. An LRU policy evicts the least-recently-accessed files when that limit is exceeded.
Letta’s approach is memory-first: files live in both raw text and a vector store (embedded chunks), the context window only shows a managed view, and the model uses tools to access more.
Where the real engineering is: session pruning
As conversations grow, every harness has to decide what to keep and what to throw away. This is where the design differences become most meaningful, because compaction policy determines whether long-running agents stay coherent or slowly degrade.
Pi (pi-mono)
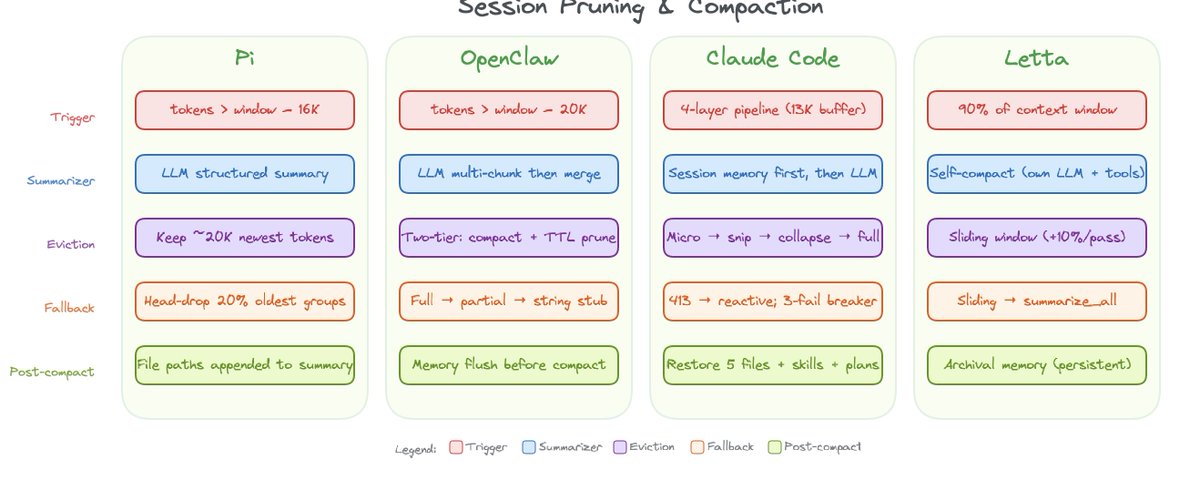
Pi uses compaction: LLM-powered summarization triggered by a token threshold.
- Trigger: Estimated context tokens exceed contextWindow – reserveTokens (default reserve: 16,384 tokens)
- What’s kept: Walks backward through conversation, keeping the most recent ~20,000 tokens of messages (keepRecentTokens)
- What’s summarized: Everything older gets passed to the LLM for summarization
- Where the summary goes: Becomes a synthetic user message prepended to the kept tail
- Tool-call safety: Never cuts at an orphaned tool result. Walks boundaries to keep tool-call/tool-result pairs intact
OpenClaw
OpenClaw runs two distinct context management mechanisms on top of Pi’s compaction:
- Trigger: History exceeds 50% of the context window (maxHistoryShare, default 0.5)
- What’s kept: History is split into equal-mass token chunks; the oldest chunk is dropped, the rest is kept with tool-call/result pairs repaired
- What’s summarized: Dropped content goes through staged multi-pass LLM summarization with a merge step
- Where the summary goes: Same as Pi – synthetic message prepended to the kept tail
- Tool-call safety: repairToolUseResultPairing fixes any orphaned tool results after chunk dropping; splitMessagesByTokenShare avoids cutting inside a tool-call/result pair
- Pre-compaction flush: A silent agentic turn lets the agent persist state to memory files before history disappears
- Second layer: Non-destructive in-memory pruning of tool results (soft-trim, then hard-clear) on a 5-minute cache TTL, protecting the persistent conversation while reclaiming context for the current request
Claude Code
Claude Code manages context through pre-query optimization and LLM-powered compaction.
- Trigger: Estimated tokens exceed the effective context window minus a 13,000-token buffer (compaction fires around 167K tokens for a 200K-context model)
- What’s summarized: The full conversation is sent to the model with a structured 9-section prompt covering primary request, key technical concepts, files and code, errors and fixes, problem solving, all user messages, pending tasks, current work, and optional next step
- Where the summary goes: Becomes a user message telling the model the session is being continued from a previous conversation that ran out of context
- Post-compact restoration: Up to 5 recently-read files are re-attached to context after compaction, within a token budget
- Summarizer safety: The model produces an analysis scratchpad and a final summary in separate tagged blocks. The scratchpad is stripped before the summary enters context, improving quality without bloating the result
- Fallback on prompt-too-long: If the compaction call itself hits the context limit, a deterministic head-drop removes the oldest API-round groups (20% of groups or enough to close the token gap)
Pre-query optimization (every API call, regardless of context pressure). Before each model call, Claude Code runs a pipeline that manages tool results but leaves conversation text untouched. Oversized tool results are persisted to disk and replaced with 2KB previews, with a per-tool cap of 50,000 characters and a per-message aggregate cap of 200,000 characters, so a 60KB grep result gets offloaded on the very first turn of a new session.
Letta
Letta manages context through multiple compaction strategies, with a two-stage summarizer fallback when the primary path overflows.
- Trigger: Compaction fires when estimated context usage exceeds 90% of the context window
- Sliding window eviction: Starts at 30% of messages (not 10%), then increases by 10% per iteration until token usage drops below the goal. Keeps the most recent messages, evicts the oldest
- Self-compact mode: Uses the agent’s own model to summarize, so no separate summarizer cost or configuration is needed
- Two-stage fallback on summarizer overflow: First, clamps tool returns to 5,000 characters and retries. If that still overflows, middle-truncates the transcript keeping 30% head and 30% tail, dropping the middle
- Warning threshold: A separate 75% memory warning fires before the 90% compaction trigger
Subagent context management
Across the harnesses we looked at, subagents are generally isolated from the parent session. None of the examples here copies the full parent conversation history into the child. The question is what workspace context they inherit.
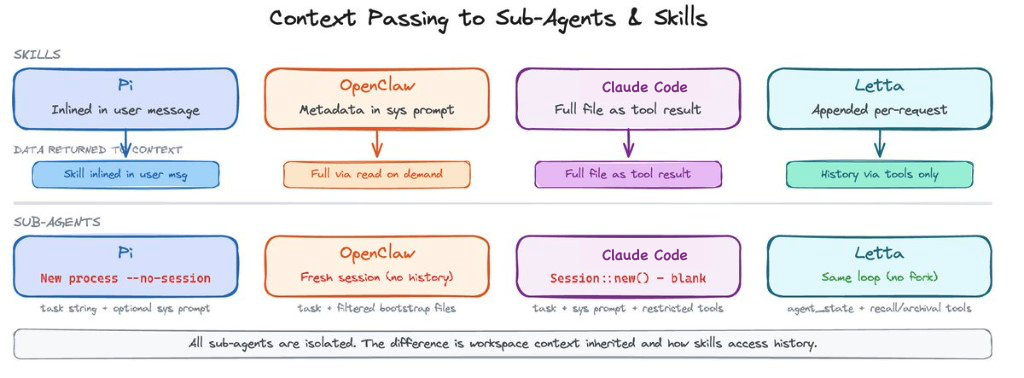
Pi spawns a new process per delegated task with an in-memory session. The child receives the task string as its only user message. No parent conversation history is passed.
OpenClaw gives sub-agents fresh isolated sessions by default, no parent transcript. A fork mode exists that copies the parent’s transcript into the child, but only for same-agent spawns. Workspace context is filtered to a minimal allowlist (AGENTS.md, TOOLS.md, SOUL.md).
Claude Code has two paths. The default typed-agent path creates a blank conversation: the delegated prompt becomes the only user message, with no parent history. A newer fork path passes the entire parent message history into the child for prompt cache sharing, plus a synthetic assistant message and placeholder tool results. Tools are rebuilt for the worker with their own permission mode; async agents get an explicit allowlist (Read, Grep, Glob, Shell, Edit, Write, WebSearch, and a few others). Skills referenced in the agent definition are eagerly preloaded. The full skill content is injected as user messages into the initial conversation, not loaded on demand.
Letta does not fork at all for normal tool execution. Tools run within the main agent loop. Historical context is accessed through dedicated search tools: conversation search for recall memory and archival memory search for the embedding store.
Where the agent harness designs converge
The most striking finding from comparing these four codebases is not how different they are. It is how much they agree.
All four harnesses hard-cap file reads. All four support offset/limit pagination. All four cap tool result sizes. All four isolate sub-agent sessions. All four run LLM-powered compaction triggered by a token threshold. All four estimate context usage and detect pressure. These are not coincidences. They are convergent solutions to the same engineering problem: a fixed-size working set that has to feel infinite.
The convergence runs deeper than just having the same features. The specific design choices rhyme. Pi and OpenClaw both head-truncate file reads and append a continuation nudge. Claude Code and OpenClaw both persist oversized tool results to disk. Pi, OpenClaw, and Claude Code all enforce tool-call/result boundary safety during compaction. Three of the four support forking parent transcripts into sub-agents. The harnesses are arriving at the same answers independently.
These patterns are not limited to coding agents. Arize’s own Alyx assistant, built for data exploration instead of code editing, independently arrived at the same designs.
Alyx caps tool results at a 10,000-token budget and uses binary search to find the largest dataset slice that fits. It deduplicates idempotent tool calls by pruning repeated previews from conversation history, keeping only the most recent. It splits large JSON payloads into a compressed LLM-visible preview and a full server-side copy the model can drill into via jq, the same “persist oversized results outside context” pattern that Pi, OpenClaw, and Claude Code use for file reads. It does head+tail truncation on long cell values with back-references to the full content. It estimates token pressure with a char/4 heuristic and forces a checkpoint when the conversation crosses 50,000 tokens, at which point the model writes its own state summary before history is pruned, combining Claude Code’s deterministic compaction trigger with OpenClaw’s pre-compaction state flush. Its subagents launch in an isolation pattern that all four harnesses use. A product built for an entirely different domain converged on the same context management playbook.
50 years of computing taught us that the best memory management is the kind the program never thinks about. Registers, cache lines, page tables, swap. Each layer managed by the system, each invisible to the layer above. The program just runs.
Agent harnesses are moving in the same direction. The goal is not to show the model everything. It is to give it the right working set at the right time and allow it to dynamically make decisions to manage its own context.
FAQs: context management in agent harnesses
What is context management in an AI agent harness?
Context management is the set of policies and mechanisms an agent harness uses to control what enters, remains in, or is removed from the model’s active context window. This can include conversation history, system and project instructions, file excerpts, tool results, memory entries, retrieved documents, and summaries.
Why does context management matter for AI agents?
AI agents often work across long conversations, codebases, documents, tools, memory systems, and delegated tasks. Good context management helps keep important state available, avoids spending tokens on low-value detail, reduces context-window failures, and limits pollution from large tool outputs or exploratory work.
How do agent harnesses handle large files?
Common strategies include limiting how much of a file or tool result can be read at once, exposing chunked or offset-based reads, truncating oversized outputs, and using search or retrieval tools so the model can ask for the relevant part instead of loading an entire file. Some systems also keep large knowledge outside the prompt and retrieve it on demand; for example, Letta distinguishes in-context memory blocks from searchable files, archival memory, and external RAG stores.
How do subagents manage context?
Subagent behavior depends on the harness. A common design is to give a subagent its own context window, focused instructions, selected tools, and a specific task, then return only a final answer or summary to the parent. This keeps exploratory reads, logs, and tool calls out of the parent conversation. Some systems also offer fork or inherit modes where the child receives the parent’s current conversation context, so isolated context should not be assumed universally.
What do Pi, OpenClaw, Claude Code, and Letta have in common?
They all treat context as a managed resource rather than simply appending everything indefinitely. They use some combination of compaction or summarization, bounded or incremental access to large content, retrieval from out-of-context stores, session or history limits, and delegated work in separate contexts.
The details differ. Pi core emphasizes extensibility, skills, dynamic context, and compaction, but it does not ship built-in subagents. OpenClaw embeds Pi in a messaging-gateway architecture and adds session orchestration, subagent spawning, history limiting, compaction safeguards, and context pruning. Claude Code supports built-in and custom subagents that normally run in their own context windows, plus experimental forked subagents that inherit the parent conversation. Letta and Letta Code provide memory abstractions, searchable archival memory, file search, compaction, and built-in subagents.