



AI Agent Architecture
In this section, we review basic AI agent architecture setups, and do a deep dive into routers, including function calling, intent-based routing, pure code routing, and best practices for implementation
There are a few common patterns we see across agent deployments today. We’ll walk through an overview of all of those architectures in the following pieces but the below examples are probably the most common.
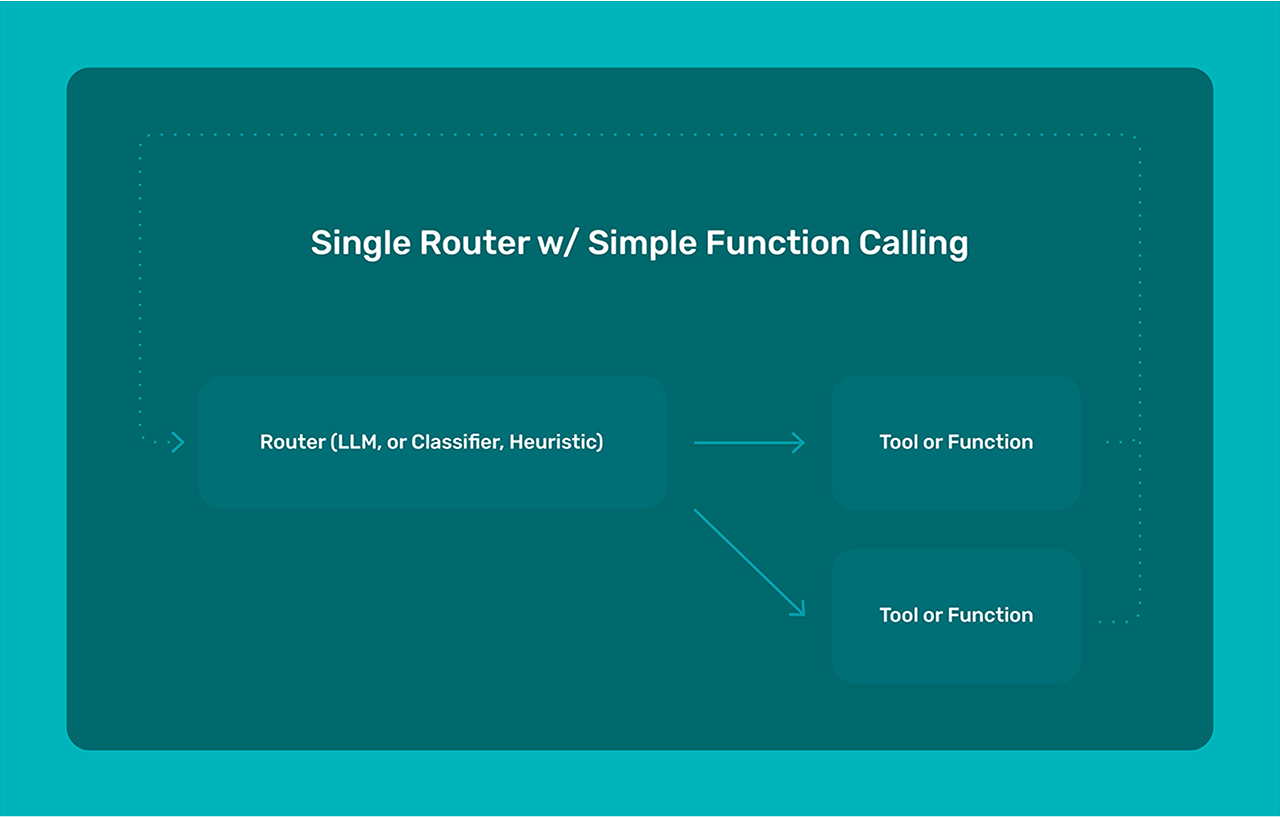
In its simplest form an AI agent or assistant might just be defined with a LLM router and a tool call. We call this first example a single router with functions. We have a single router, that could be an LLM call, a classifier call, or just plain code, that directs and orchestrates which function to call. The idea is that the router can decide which tool or functional call to invoke based on input from the system. The single router comes from the fact that we are using only 1 router in this architecture.
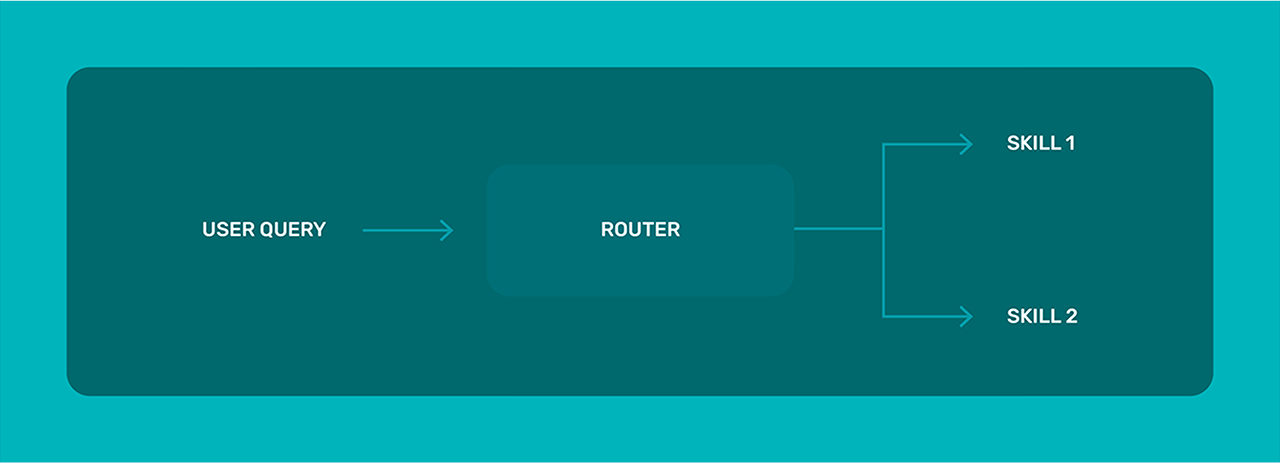
A slightly more complicated assistant we see is a single router with skills. In this case, rather than calling a simple tooling or function call, the router can call a more complex workflow or skill set that might include many components and is an overall deeper set of chained actions. These components (LLM, API, tooling, RAG, and code calls) can be looped and chained to form a skill.
This is probably the most common architecture from advanced LLM application teams in production today that we see.
The general agent architecture gets more complicated by mixing branches of LLM calls with tools and state. In this next case, the router decides which of its skills (denoted in red) to call to answer the user’s question. It may update the shared state based on this question as well. Each skill may also access the shared state, and could involve one or more LLM calls of its own to retrieve a response to the user.
This is still generally straightforward, however, AI agents are usually far more complex. As agents become more complicated, you start to see frameworks built to try and reduce that complexity.
Routers
An agent router serves as the decision-making layer that manages how user requests are routed to the correct function, service, or action within a system. This component is particularly vital in large-scale conversational systems where multiple intents, services, and actions are involved.
Routers are not used by all agents however. Some frameworks like LangGraph or OpenAI Swarm instead spread the job of routing across nodes within an agent.
When to Implement an Agent Router
Agent routers prove particularly valuable in several scenarios:
- Systems with multiple service integrations, including various APIs, databases, or microservices
- Applications handling diverse types of user input, especially in NLP-based systems
- Architectures requiring modular, scalable design patterns
- Systems needing sophisticated error handling and fallback mechanisms
Generally speaking, more complex and/or non-deterministic agents benefit from routers.
Implementation Approaches
Routers typically use one of three different techniques to handle their core routing function:
Function Calling with LLMs
This approach uses an existing LLM to chose between a set of available functions, each representing a skill or branch in the agent. Most modern LLMs are now equipped with function calling capabilities, and as a result you’ll often see agents using GPT-4o, Claude 3.5 Sonnet, or Llama models as routers.
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
}
},
"required": [
"location"
],
"additionalProperties": false
},
"strict": true
}
}
Advantages of this approach:
- Dynamic and flexible processing of complex user inputs
- Minimal routing logic requirements
Some challenges of function calling:
- Higher latency due to real-time LLM processing
- Resource-intensive operations
- Limited control over granular routing logic
- Complexity in implementing fallback strategies
Function calling routers are the most flexible routing option, however they are also the hardest to control. Introducing a function calling router means introducing another stoichastic LLM call that you need to manage. Depending on your agent, the extra flexibility this method adds may be worth it, but if your agent’s routing can be handled using one of the methods below, you’ll reduce your overall testing burden.
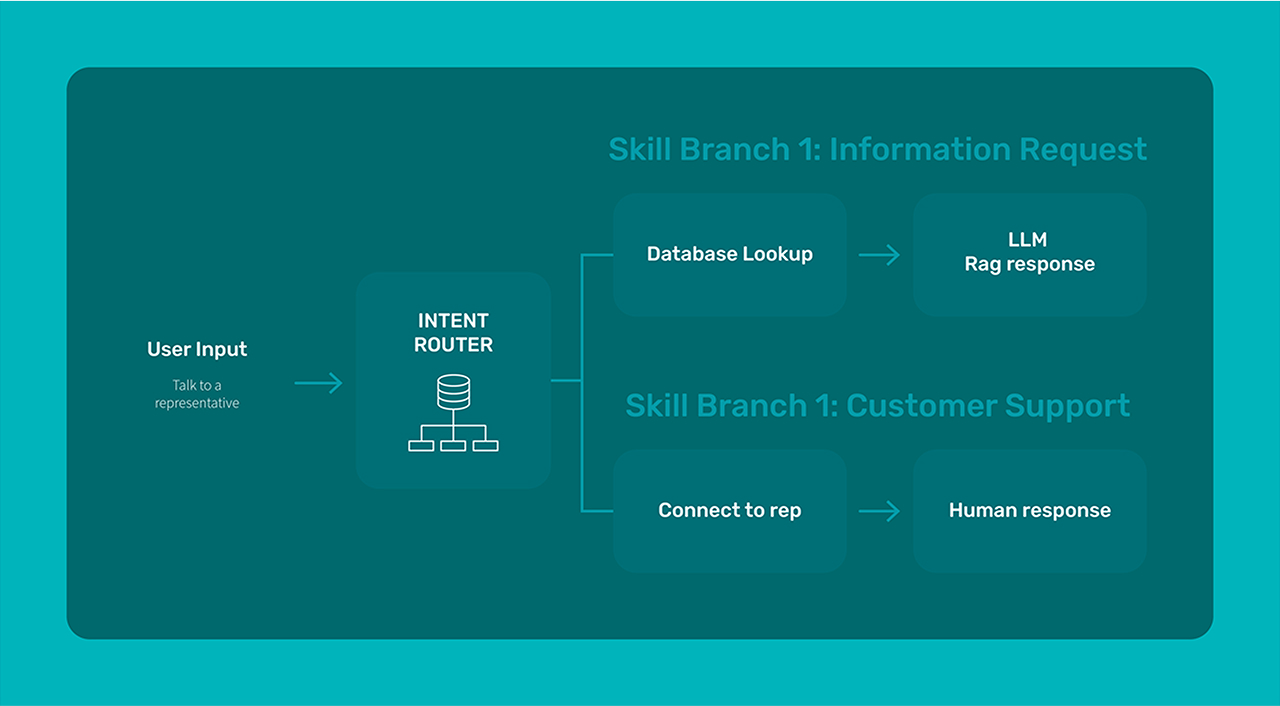
Intent-Based Routing
Intent routers identify user intentions from queries and map them to predefined functions or services. This approach is prevalent in chatbots and virtual assistants where user queries must be categorized into distinct intents.
This approach works well when your agent has a somewhat limited set of capabilities, each which can be mapped to a distinct intent. This technique can struggle with more nuanced intents however.
Advantages:
- Clear structural separation between user input and backend processes
- Straightforward debugging and scaling capabilities
- Easy extension of routing logic for new intents
Challenges:
- Limited flexibility with ambiguous queries
- Difficulty handling requests outside predefined categories
Pure Code Routing
For simpler systems, implementing routing logic directly in the application code without external AI or NLP models can be effective. This approach involves hardcoded routing decisions based on predetermined patterns or rules.
This approach is obviously more limited by the needs of your agent, however if you are working with an agent who’s routing can be hard-coded in this way, pure code routing is recommended.
def classify_intent(user_input):
# Basic rule-based classification
if "SELECT" in user_input.upper() or "FROM" in user_input.upper():
return "execute_sql"
elif "analyze" in user_input.lower() or "summarize" in user_input.lower():
return "analyze_data"
return "unknown"
Advantages:
- Superior performance and efficiency
- Complete control over routing logic
- Optimization capabilities for specific use cases
Challenges:
- Limited flexibility
- Scaling difficulties
- Significant rework required for system modifications
Best Practices for Implementation
- Scope Management: Maintain focused and limited scope for router components. Breaking complex tasks into smaller, manageable skills improves execution accuracy and system reliability. This modular approach ensures that each component has a clear, single responsibility.
- Clear Guidelines: Develop comprehensive function calling guidelines and explicit router definitions. Well-documented tool descriptions significantly enhance function call accuracy and system maintainability. This documentation serves as a crucial reference for both development and maintenance phases.
- Performance Monitoring: Implement robust monitoring solutions to track router performance and system behavior. Tools like Arize Phoenix can provide detailed visibility into application operations, helping identify optimization opportunities and potential issues before they impact users.
Making the Right Choice
The selection of an agent routing approach should be guided by several key factors:
- System complexity requirements
- Scalability needs
- Performance constraints
- Maintenance considerations
Whether implementing function calling with LLMs, intent routing, or pure code solutions, ensure your routing logic maintains modularity, scalability, and ease of maintenance. Consider starting with a simpler approach and evolving the system based on actual usage patterns and performance metrics.
An effective agent router is fundamental to building robust AI systems that can handle diverse user requests efficiently. By carefully considering implementation approaches and following established best practices, you can create a routing system that balances flexibility, performance, and maintainability. Regular monitoring and iterative improvements will ensure your agent router continues to meet your system’s evolving needs.
Skills
Agent skills are the fundamental building blocks of an agent’s functionality. These are discrete capabilities that an agent’s router activates based on user intent, allowing the agent to fulfill a wide range of tasks. By compartmentalizing functionality into specific skills, agents can execute complex workflows in a modular, efficient, and maintainable way.
What Are Skills?
Skills are self-contained operations or tasks that an agent can perform. Each skill is designed to address a specific type of user intent and operates as a reusable, independent unit. Think of skills as tools in a toolbox—each tool serves a distinct purpose, and the router selects the right tool for the job.
What Can Skills Be Made Of?
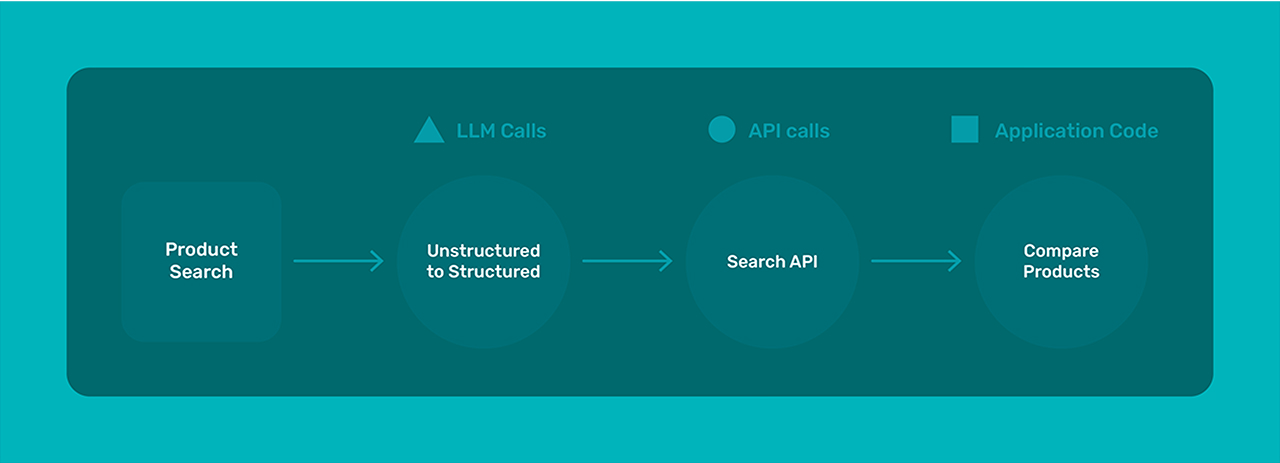
Skills are not limited to a single type of operation. Instead, they can consist of a variety of components:
- Other LLM Calls: Skills may involve chaining language model outputs to refine responses, summarize information, or generate content.
- API Calls: Skills can interact with external APIs to retrieve or send data. For example, a weather query skill might call a weather API to fetch real-time conditions.
- Pure Application Code: Some skills are implemented directly in code to handle specific business logic or computational tasks without relying on external services.
- Database Queries: Skills can connect to structured data sources, running SQL queries or interfacing with NoSQL databases to fetch relevant information.
- Multi-Step Workflows: A single skill may involve orchestrating multiple subtasks, such as combining data retrieval, LLM processing, and validation logic.
Common Types of Skills
Below are some commonly implemented agent skills across different use cases:
- Retrieval-Augmented Generation (RAG): Integrates with knowledge bases or document stores to retrieve contextually relevant data and enhance LLM outputs.
- API Interaction: Fetches external information (e.g., weather, stock prices, shipping data) or triggers external actions (e.g., sending emails, creating tickets).
Code Generation and Execution: Produces and executes code snippets dynamically, often for automating repetitive tasks or data processing. - Database Querying: Enables agents to interact with structured data, performing queries to retrieve or update records.
- Reflection and Iteration: Allows agents to review their prior responses, analyze them for errors or improvements, and generate updated outputs.
- Data Analysis: Processes datasets to generate summaries, visualizations, or statistical insights.
Workflow Automation: Manages multi-step processes by coordinating several sub-skills to achieve an overarching goal.
How Skills Fit Into Agent Architectures
In agent architectures, skills operate as discrete, closed units. This modularity ensures that skills can be developed, tested, and maintained independently.
Here’s how they fit into the broader system:
- Interaction with Memory: Skills may read from or write to an agent’s memory. For example, a conversation history skill might log user interactions, while a summarization skill might use memory to generate context-aware responses.
- Interaction with State: Skills often update or depend on the agent’s state, which reflects the current session’s context or task-specific variables.
- Role of the Router: The router serves as the decision-making component, analyzing user intent and determining which skill to invoke. Importantly, routers treat skills as black boxes—they don’t need to understand the internal workings of a skill, only what it does and when to call it.
Best Practices for Developing Agent Skills
- Design for Modularity: Ensure each skill performs a single, well-defined function. This makes skills easier to debug, test, and reuse across different agents.
- Follow Clear Interfaces: Define input and output standards for each skill. Consistency across skills allows the router to call them seamlessly.
- Incorporate Error Handling: Skills should gracefully handle failures, such as API timeouts or invalid inputs, and provide useful error messages to the router.
- Optimize for Performance: Avoid unnecessary complexity in skills. For instance, cache frequently accessed data to reduce redundant calls.
- Document Skills Thoroughly: Provide clear documentation for each skill, including its purpose, inputs, outputs, and dependencies. This ensures easy onboarding for developers and smooth integration into agent workflows.
- Test in Isolation: Validate each skill independently before integrating it into an agent. Unit tests can help ensure reliability and catch edge cases early.
- Enable Observability: Incorporate logging and monitoring into skills to track their performance and debug issues effectively.
By following these principles, you can create robust, adaptable agent skills that enhance the overall capabilities of your agents and make them more maintainable over time.
Memory and State
The term “memory” is often used in discussions about LLM applications, but it’s an abstraction that can mean different things to different people. Broadly, memory refers to any mechanism by which an LLM application stores and retrieves information for future use. This can encompass state in its many forms:
- Persisted state: Data stored in external databases or other durable storage systems
- In-application state: Information retained only during the active session, which disappears when the application restarts.
What Is State in LLM Applications?
State is the mechanism which a system retains and uses information over time, connecting past interactions to current behavior. In software engineering, state can be categorized into two main types:
- Stateful systems retain context
Stateless systems treat each interaction independently, with no memory of prior exchanges. - LLM models are stateless. They process each query as a standalone task, generating outputs based solely on the current input. This simplifies model architecture but poses challenges for LLM applications that require context continuity – especially agents.
For example, in a chatbot, messages within the same session may appear stateful, as they influence ongoing interactions. However, once the session ends, the application reverts to a stateless design, if there is no information persisted across sessions.
Agents on the other hand, are typically stateful. Each action an agent takes is informed by previous actions, responses, or user messages.
Why Managing Memory & State is Essential
Applications require state to deliver consistent, coherent, and efficient user experiences. Without it:
- Users are forced to repeat information
- Applications can’t adapt to ongoing context
- Processing redundant information increases costs
Managing state requires balancing the things you need, and the things you don’t for the particular application.
LLM State Management Considerations
If you’ve built your own agent, you’ll have full control over what is stored in your state. Here are a few useful factors to consider when establishing your agent’s state.
1. How long should the information be retained?
- The context in which state should be carried will affect the design of your state management system, illustrative examples below:
- End User Examples
- State Across Messages:
- Maintains continuity during an ongoing session but resets once the session ends. Useful for chatbots, iterative problem-solving, or workflows.
- State Across Sessions:
- Persists information across sessions, enabling personalization or long-term task tracking. Essential for applications like virtual assistants or collaborative tools.
- State Across Messages:
- Agent Examples
- State Across Tool Calls
- Does each tool execution need to carry over context, or can the tools operate independently?
- State Across Multiple Agents
- In multi-agent systems, should agents share state, or should they operate with isolated knowledge?
- State Across Tool Calls
2. What is the available context window in your LLM?
LLMs have a fixed context window, limiting how much information they can process at once. As the input grows, performance can degrade, costs increase, and hallucinations become more frequent. State management strategies must account for these limitations to ensure relevance without exceeding token context windows.
3. Costs
Stateful designs often improve user experience and application performance but come with increased costs. Persisted data and larger prompts increase storage and processing demands. Balancing the cost of maintaining state against its benefits is critical for sustainable applications.
4. LLM Application Performance
Depending on the outcome you are trying to produce, some folks might need more complex state management to actually achieve the outcome they desire while others can implement something more simple and still achieve their required results. Some can go with a more brute force approach while others might need to refine the state system.
Storing Conversation History
Conversation History is the most common information stored as state. Indeed, if you’re using a LLM function calling router, you may be required to pass in previous messages to even get a response.
The most basic approach to storing conversation history involves including all past messages—user inputs, model outputs, tool responses—in subsequent prompts. While straightforward and intuitive, it can quickly run into problems:
- Degraded performance: Large prompts reduce model quality.
- High costs: Token usage grows quadratically with conversation length.
- Context limits: Long histories can exceed the model’s capacity.
This approach works for short interactions but scales poorly in more complex applications. A more nuanced approach is to use a sliding window.
A sliding window retains only the most recent messages, discarding older ones to maintain a fixed context size.
- Benefits: Keeps context relevant, stays within model limits, and controls token costs.
- Drawbacks: Risks losing important earlier details and struggles with long-term dependencies.
Sliding windows balance efficiency and relevance but may require supplementation for applications needing deeper context. That supplementation typically comes in the form of summarization.
Summarization condenses past interactions into a compact form. This reduces token usage but has limitations:
- Loss of detail: Important nuances may be omitted.
- Uncertainty: Summaries may not include information needed in future interactions.
Summarization works best as part of a hybrid strategy rather than a standalone solution.
Combining Strategies
Blending approaches—such as combining recent message windows with past summaries—offers a practical balance. This ensures recent context is preserved while retaining essential historical information.
These foundational techniques provide a starting point for managing state effectively, tailored to the specific needs of your application.
Storage Types
Choosing the right storage type depends on the persistence requirements, cost, and latency of your application. Here’s an example below
- Ephemeral conversation history:
- Temporarily stored in application memory, used during a single session. For example, a shopping assistant might track interactions in real time without needing to persist data for future sessions.
- Persistent conversation history:
- Stored in a durable database or vector store, enabling access to prior context across sessions. This is essential for applications like personal assistants that need long-term memory for personalization.
- The persistence storage medium—whether a database, blob storage, knowledge graph, or retrieval-augmented generation (RAG) system—should align with your application’s complexity, latency requirements, and cost constraints.
Collaboration / Organization Approaches
In complex problem-solving scenarios, deploying multiple AI agents can enhance efficiency and effectiveness. This section delves into multi-agent frameworks, common collaboration strategies, and guidelines for choosing between multi-agent and single-agent approaches.