



This post is written in collaboration with Aparna Dhinakaran and Erick Siavichay
Common LLM Use Cases: What’s Real and Not Just a Twitter Demo?
Beyond social media demonstrations, LLMs are now providing tangible value across numerous use cases and industries. There are several ways in which this technology is being applied today.
First, LLM-powered assistants, or co-pilots, are increasing in popularity in many industries. For example, several large wealth management firms have developed their own proprietary LLM assistants to help with data processing and financial advice. This allows advisors to make informed decisions quickly, and in a field where time is money and data overload is a constant problem, that’s a big deal.
Second, LLMs are beginning to play a greater role in customer support. Companies are using LLMs to answer customer inquiries about product features, billing issues, troubleshooting guidance, or many other things. The use of LLMs allows for prompt, precise responses, increasing customer satisfaction and freeing up human representatives for more complex tasks. No more waiting on hold for an hour!
Third, LLMs are incredible for content generation. These models generate templated, context-specific outputs that users can easily edit to suit their needs. LLMs are being used to help write emails, summarize transcriptions, generate social media posts, draft articles, and much more.
These practical implementations of LLMs clearly demonstrate their far-reaching capabilities and potential to optimize various business processes. The technology is delivering value beyond social media hype and is poised to reshape industries as it continues to evolve.
LLMs and Proprietary Data: When Do You Need Search and Retrieval
What an LLM Knows and Why It Doesn’t Know Your Data
LLMs are trained on internet-scale data across a large set of sources that are publicly available. These data sets are similar to the open crawl data sources, such as the common crawl. Given that LLMs are trained on billions, or even trillions of data points, their knowledge is extensive and varied across a large number of subjects. LLM architecture enables these models to synthesize this massive amount of data in real-time, allowing them to provide valuable insights and information on diverse topics. For example, if a user is troubleshooting network connectivity issues, an LLM will understand routers, networking equipment, routing protocols, and how different equipment might be used.
However, while LLMs can provide a broad base of knowledge, they are fundamentally limited by the information they have been trained on. An LLM won’t know the specifics of your product documentation or understand the unique workings of your product. If there are updates or changes to your product, an LLM won’t automatically have that information unless it’s included in its training data.
If an LLM did have real-time access to your data, documents, and product specifics, the potential applications would be both immensely impactful:
- A customer support expert, externally facing and ready to handle technical queries
- A product specialist for internal teams, providing immediate, detailed knowledge of your offerings
- A business data analyst to decipher trends and deliver insights
- A codebase expert for your development team, assisting in troubleshooting and innovation
- A security analyst to comb through your codebase, identifying vulnerabilities before they become threats
- An executive assistant capable of delivering immediate, data-driven answers for business analytics
Such an LLM would be highly valuable, offering rapid, autonomous, and top-performing assistance across a range of roles. Now, given these potential benefits, an important question arises: how can we augment LLMs with the ability to process proprietary data they’ve never encountered before?
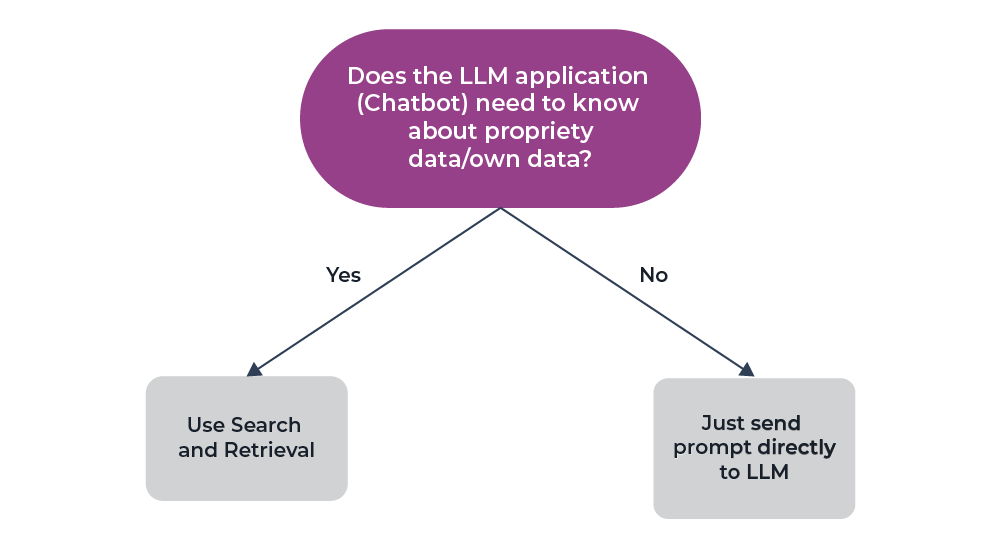
How an LLM Can Respond to Queries About Data It’s Never Seen Before or Can’t Generalize
Traditionally, data is added to an ML model by training the model on that specific data. This leads many to jump to the conclusion that fine tuning LLMs is what is needed to add proprietary data to the equation. Let’s bust that myth: in practice, most data augmentation is accomplished through prompt engineering or search and retrieval methods using a vector database.
Prompt engineering is a practice used to guide an LLM’s response by querying the model in a more specific way. For example, instead of merely asking a model to “create a quarterly report,” a user could provide specific figures or data in their input, providing context and leading the LLM to a more relevant and accurate output. However, copying large amounts of information into an LLM’s input is not only cumbersome but is also limited by constraints on the amount of text that can be inputted into these models at once.
This is where the concept of “search and retrieval” can enhance LLM capabilities. By pairing LLMs with an efficient search and retrieval system that has access to your proprietary data, you can overcome the limitations of both static training data and manual input. This approach is the best of both worlds, combining the expansive knowledge of LLMs with the specificity and relevance of your own data, all in real-time.
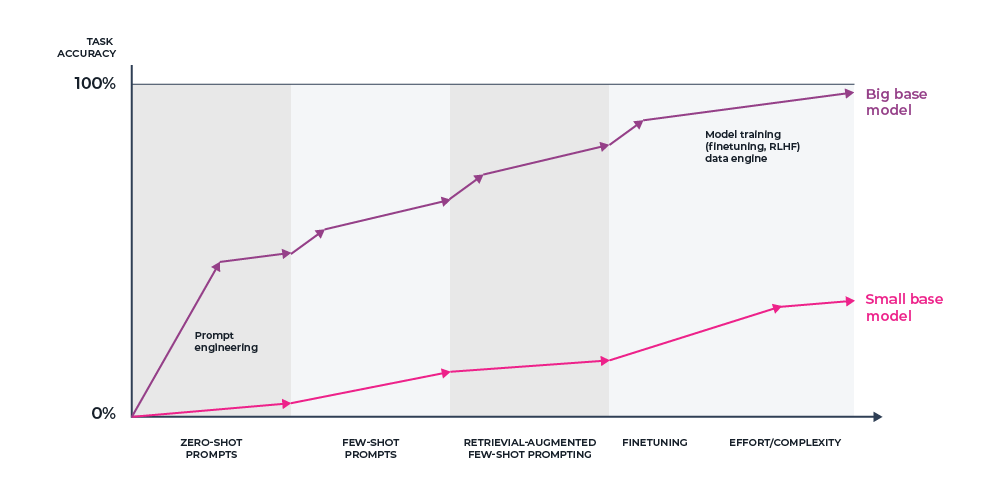
Source: Andrej Karpathy, Twitter
Businesses are connecting their LLM application (e.g. a chatbot) to a vector database, allowing the application to reference specific context related to a user’s query. The results are staggering, with significantly higher accuracy than applications without search and retrieval and less load than fine-tuning the model.
Development: How Search and Retrieval Works
Let’s consider the common scenario of developing a customer support chatbot using an LLM. Usually, teams possess a wealth of product documentation, which includes a vast amount of unstructured data detailing their product, frequently asked questions, and use cases.
This data is broken down into pieces through a process called “chunking.” How you chunk data matters, and in the next piece of our “Build Your Own Chatbot” course, we’ll dig into chunking strategies and evaluation methods.
After the data is broken down, each chunk is assigned a unique identifier and embedded into a high-dimensional space within a vector database. This process leverages advanced natural language processing techniques to understand the context and semantic meaning of each chunk.
When a customer’s question comes in, the LLM uses a retrieval algorithm to quickly identify and fetch the most relevant chunks from the vector database. This retrieval is based on the semantic similarity between the query and the chunks, not just keyword matching.
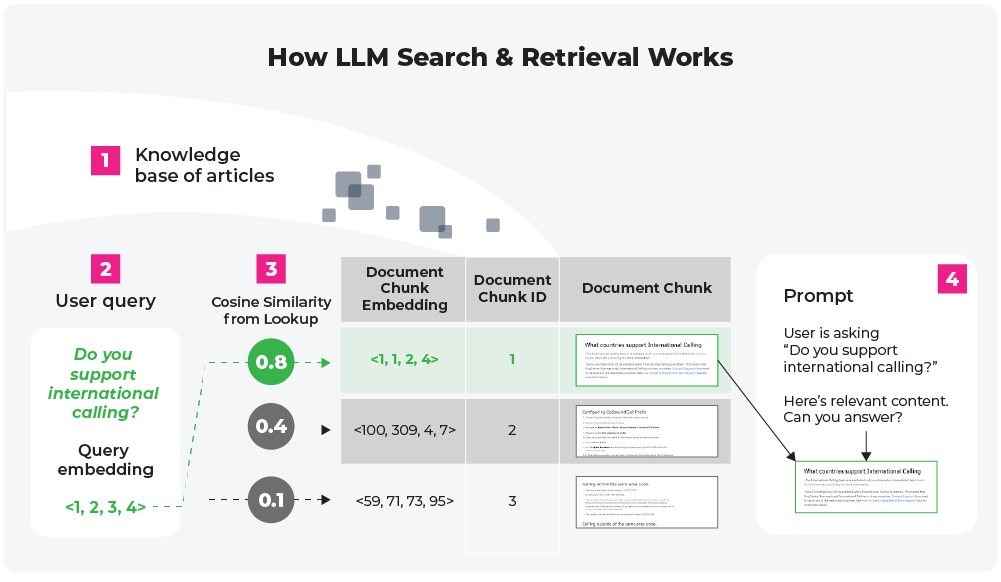
The picture above shows how search and retrieval is used with a prompt template (4) in order to generate a final LLM prompt context. The above view is the search and retrieval LLM use case in its simplest form: a document is broken into chunks, these chunks are embedded into a vector store, and the search and retrieval process pulls on this context to shape LLM output.
This approach offers a number of advantages. First, it significantly reduces the time and computational resources required for the LLM to process large amounts of data, as it only needs to interact with the relevant chunks instead of the entire documentation.
Second, it allows for real-time updates to the database. As product documentation evolves, the corresponding chunks in the vector database can be easily updated. This ensures that the chatbot always provides the most up-to-date information.
Finally, by focusing on semantically relevant chunks, the LLM can provide more precise and contextually appropriate responses, leading to improved customer satisfaction.
Production: Common Problems With Search and Retrieval Systems
While the search and retrieval method greatly enhances the efficiency and accuracy of LLMs, it’s not without potential pitfalls. Identifying these issues early can prevent them from impacting user experience.
One such challenge arises when a user inputs a query that doesn’t closely match any chunks in the vector store. The system looks for a needle in a haystack but finds no needle at all. This lack of match, often caused by unique or highly specific queries, can leave the system to draw on the “most similar” chunks available – ones that aren’t entirely relevant.
In turn, this leads to a subpar response from the LLM. Since the LLM depends on the relevance of the chunks to generate responses, the lack of an appropriate match could result in an output that’s tangentially related or even completely unrelated to the user’s query.
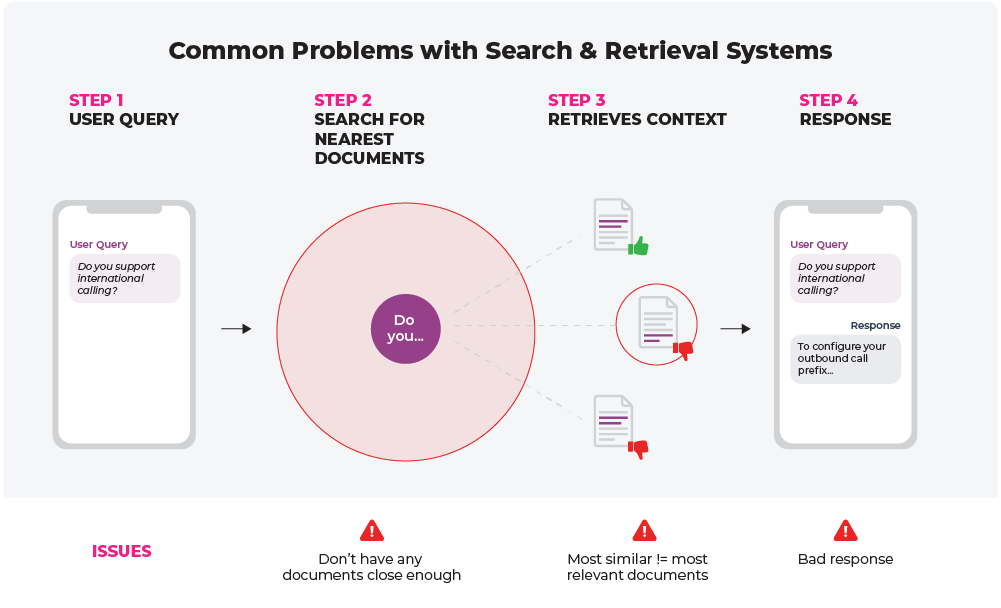
Irrelevant or subpar responses from the LLM can frustrate users, lowering their satisfaction and ultimately causing them to lose trust in the system and product as a whole. Monitoring three main things can help prevent these issues:
Query Density (Drift): Query density refers to how well user queries are covered by the vector store. If query density drifts significantly, it signals that our vector store may not be capturing the full breadth of user queries, resulting in a shortage of closely associated chunks. Regularly monitoring query density enables us to spot these gaps or shortcomings. With this insight, we can augment the vector store by incorporating more relevant chunks or refining the existing ones, improving the system’s ability to fetch data in response to user queries.
Ranking Metrics: These metrics evaluate how well the search and retrieval system is performing in terms of selecting the most relevant chunks. If the ranking metrics indicate a decline in performance, it’s a signal that the system’s ability to distinguish between relevant and irrelevant chunks might need refinement.
User Feedback: Encouraging users to provide feedback on the quality and relevance of the LLM’s responses helps gauge user satisfaction and identify areas for improvement. Regular analysis of this feedback can point out patterns and trends, which can then be used to adjust your application as necessary.
Refinement: How to Optimize and Improve Search and Retrieval
Optimization of search and retrieval processes should be a constant endeavor throughout the lifecycle of your LLM-powered application, from the building phase through to post-production.
During the building phase, attention should be given to developing a robust testing and evaluation strategy. This approach allows you to identify potential issues early on and optimize your strategies, forming a solid foundation for the system.
Key areas to focus on include:
- Chunking Strategy: Evaluating how information is broken down and processed during this stage can help highlight areas for improvement in performance.
- Retrieval Performance: Assessing how well the system retrieves information can indicate if you need to employ different tools or strategies, such as context ranking or HYDE.
Upon release, optimization efforts should continue as you enter the post-production phase. Even after launch, with a well-defined evaluation strategy, you can proactively identify any emerging issues and continue to improve your model’s performance. Consider approaches like:
- Expanding your Knowledge Base: Adding documentation can significantly improve your system’s response quality. An expanded data set allows your LLM to provide more accurate and tailored responses.
- Refining Chunking Strategy: Further modifying the way information is broken down and processed can lead to marked improvements.
- Enhancing Context Understanding: Incorporating an extra ‘context evaluation’ step helps the system incorporate the most relevant context into the LLM’s response.
Specifics on these and other strategies for continuous optimization will be detailed in the following sections of this course. Remember, the goal is to create a system that not only meets users’ needs at launch but also evolves with them over time.
Conclusion
LLMs are proving themselves as game-changers across various industries. Their capacity to process a vast amount of information, deliver precise responses to queries, and generate content is already revolutionizing the way businesses operate.
Yet, the true transformative power of LLMs is when they are augmented with proprietary data through search and retrieval methods. This balance between the extensive knowledge of an LLM and your specific data creates a highly tailored and relevant solution for users.
In the next piece of our “Build Your Own Chatbot” course, we will get hands-on, providing a step-by-step guide on setting up an LLM-powered chatbot, and more importantly, how to augment it with your data and evaluate it along the way. Stay tuned!