


The Evaluator
Your go-to blog for insights on AI observability and evaluation.

Agent harnesses have an expiration date
A benchmark-driven look at why agent harnesses need adaptive finish logic as model behavior changes across Claude, GPT-4o, and Gemma.

AI agent evaluation: How to test, debug, and improve agents in production
Lessons from building and shipping Alyx, our AI agent
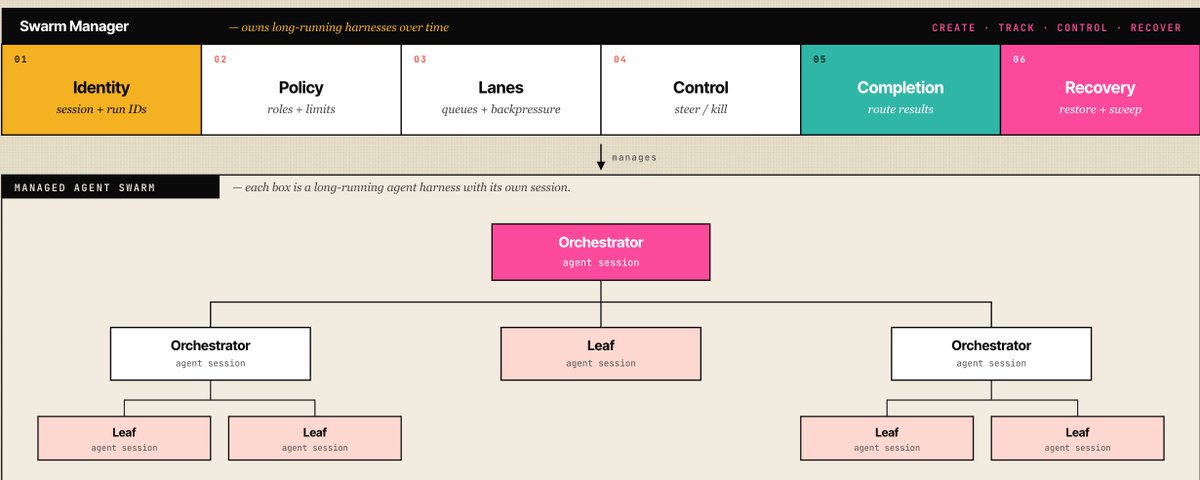
Swarm management in agent harnesses: owning long-running agents
As we have built our own harness management tools internally at Arize, and watched external systems like Devin @cognition start managing other Devins, managed agents at @AnthropicAI and long running
Sign up for our newsletter, The Evaluator — and stay in the know with updates and new resources:
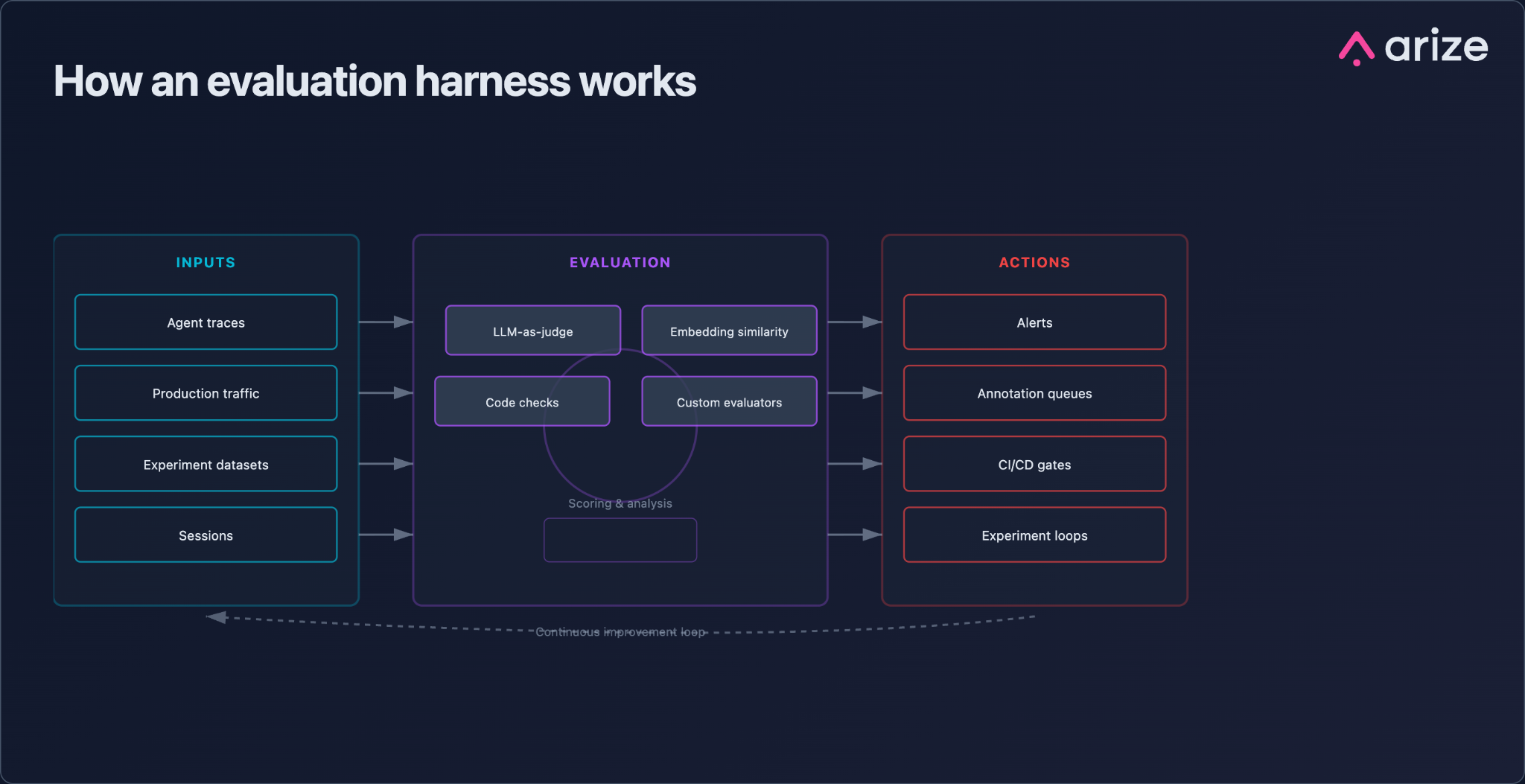
What is an evaluation harness?
An evaluation harness is the standardized infrastructure that decides what gets evaluated, runs the evaluation, and acts on the result.
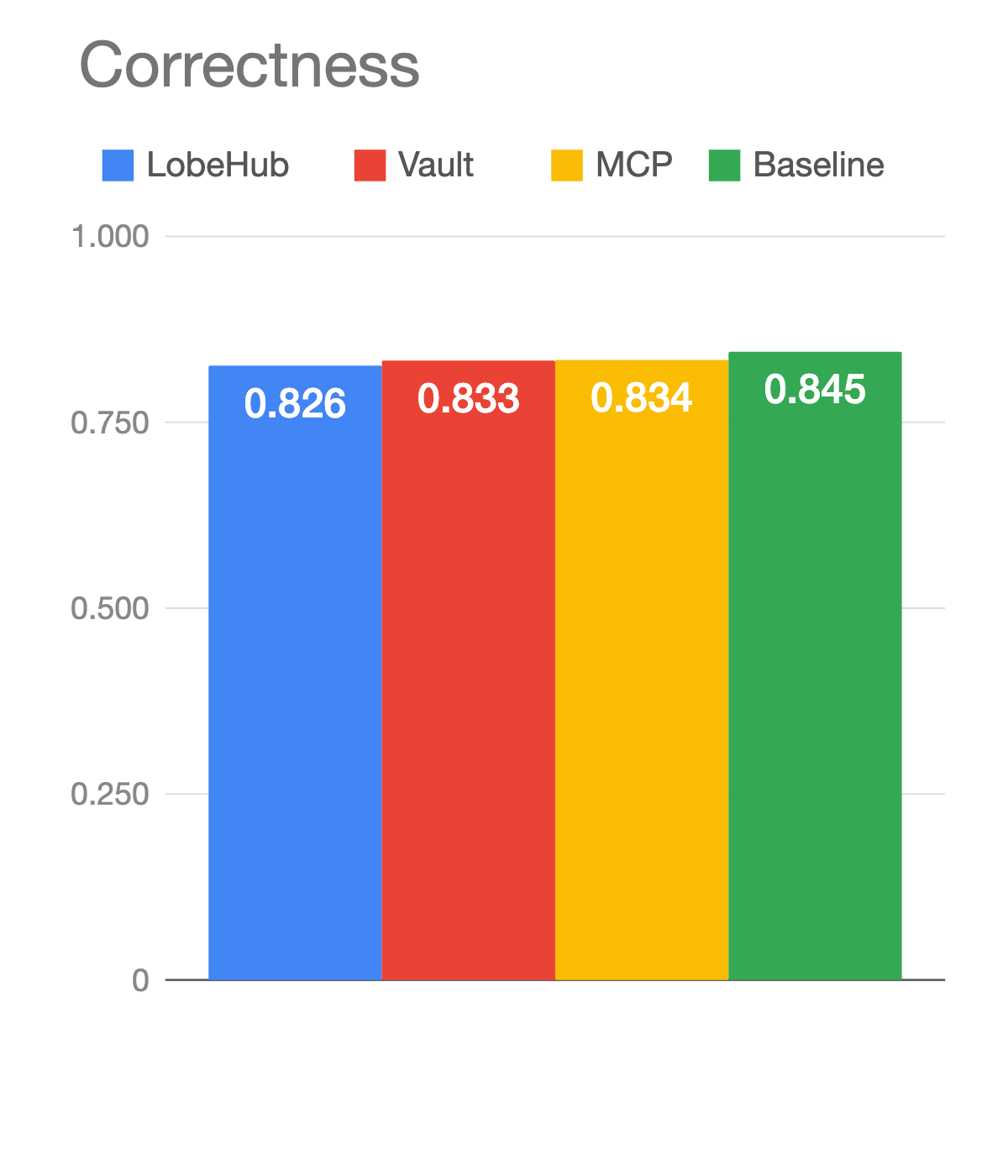
MCP vs. CLI Skills for agents: what our eval found (and which you should use)
Twitter said pick a side. The eval said the question was wrong. Six months ago, MCP (model context protocol) was the hot new thing: tool usage with a built-in discovery…

Why agent telemetry needs standards
Enterprise agents are moving from demos into production workflows, which creates a basic problem: teams need to understand what those agents actually did.
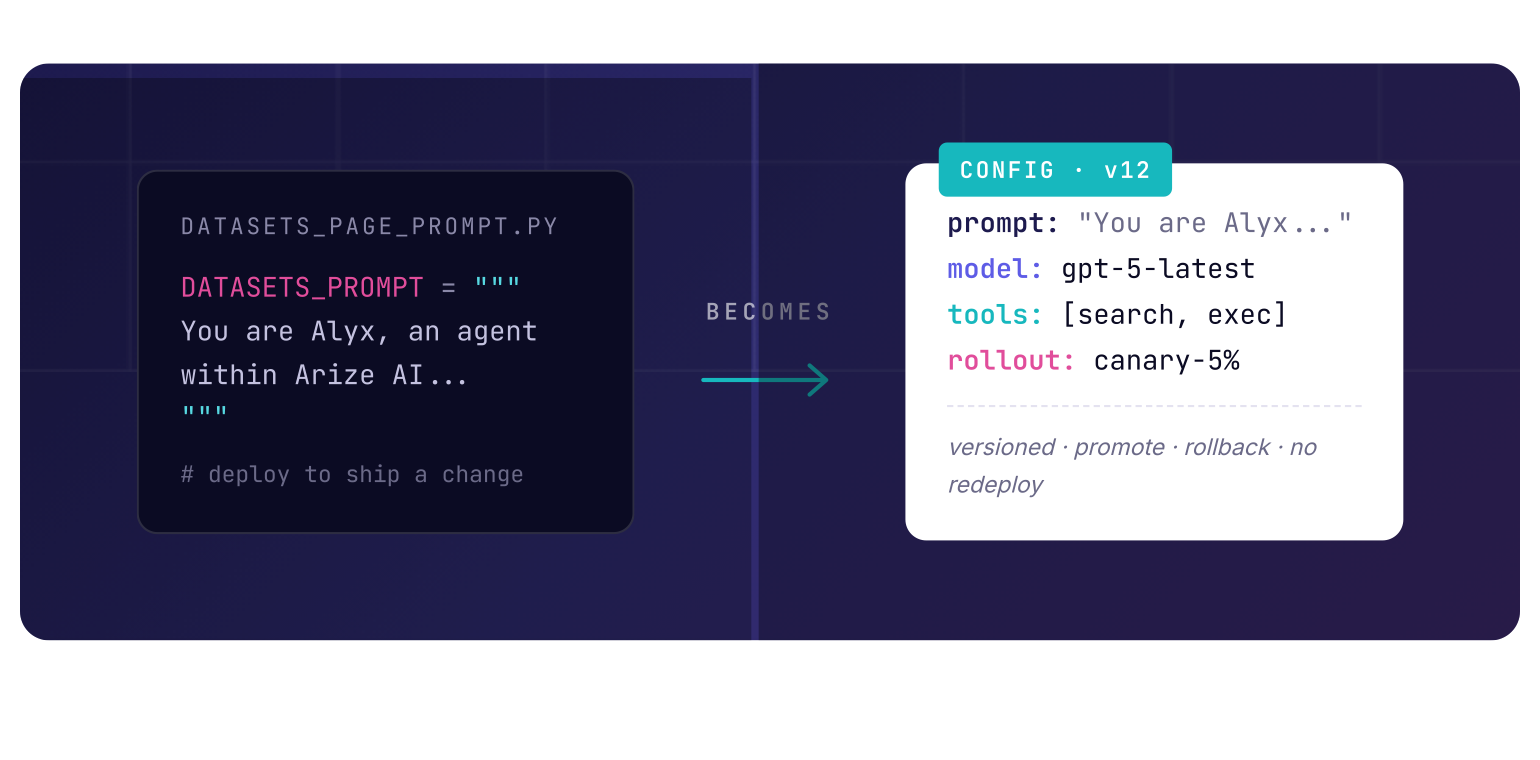
Prompt templates as configs, not code
This post was written in April 2026. Cloud products, feature maturity, and recommended patterns change over time, so readers should treat these examples as directional guidance. For teams already using Arize, there is a natural extension of that pattern. Prompt Playground can sit upstream of the config layer as the place where prompts are edited, compared, and versioned before they are promoted into whatever config system the company already trusts in production.
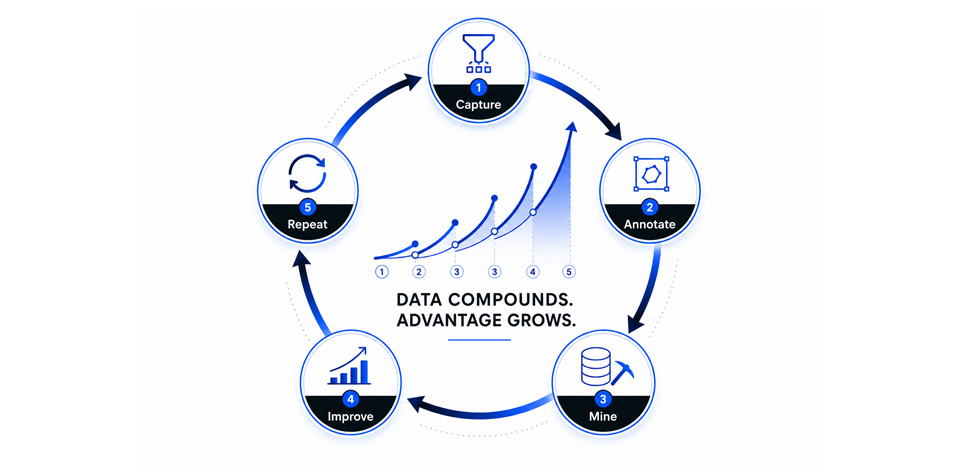
Using context graphs: build a data moat like Google’s using your enterprise data
Enterprise software is on the verge of its first compounding data loop, the same kind of self-reinforcing mechanism that built the most valuable consumer businesses of the last twenty years….
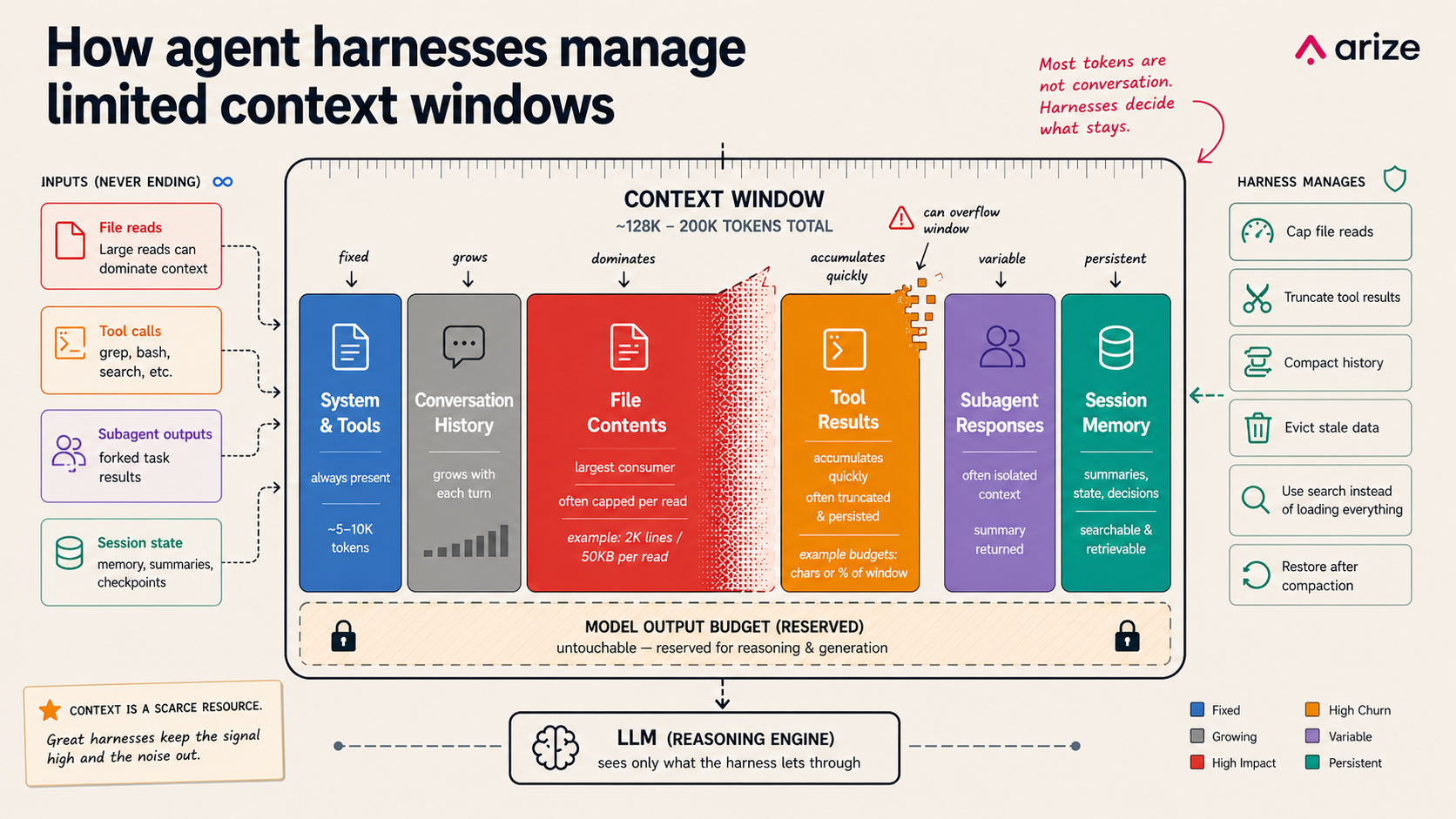
Context management in agent harnesses: memory, files, and subagents
A version of this article originally appeared on X. Every agent harness runs into the same limit: the context window is too small for everything the model might want to remember….
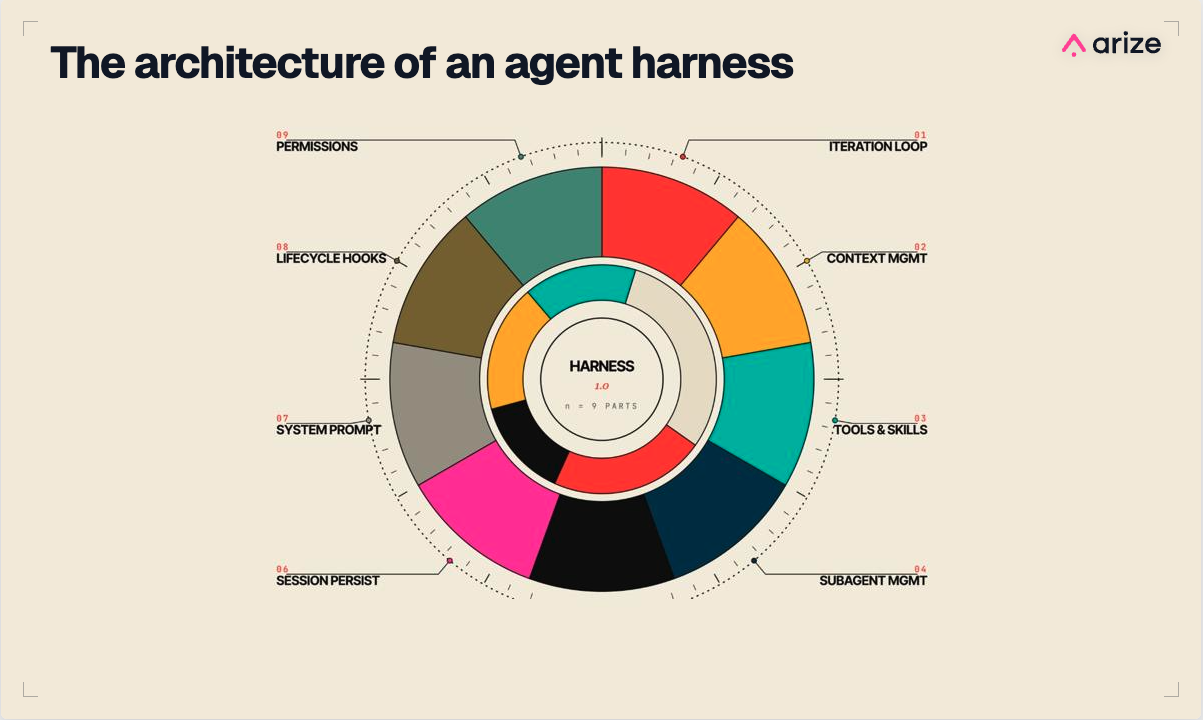
What is an agent harness?
A version of this article originally appeared on X. Someone asked me at a hacker event last week: “Can anyone actually tell me what a harness really is?” It was…


