


Cross Validation: What You Need To Know, From the Basics To LLMs

Natasha Sharma
Contributor
From the basics to how to do cross validation on large language models
What Is Cross Validation?
Imagine the machine learning model you have created has accuracy as 98%. Do you think the model is actually going to provide correct results 98% of the time? Well no, we do not know how well the model will do when it is asked to make new predictions for data that it has not already seen. This problem is identified as overfitting, when the model is performing too well with familiar data unlike unseen one.
There is a way to overcome this problem: by not using the entire dataset during model training. You can remove some of the data and then train your model on the rest of the data. Once a model is trained, you can use the data to test your model that was removed earlier. This is the basic principle of cross validation.
Cross validation is a performance evaluation technique for machine learning models. It is a technique utilized to prevent overfitting in a predictive model, especially when the available data is insufficient. This method involves dividing the data into a fixed number of folds or partitions, performing the analysis on each fold, and then computing the mean error estimate across all folds.
However, by separating our data into training and testing sets, we risk losing vital information that may be present in the test dataset. To explore possible solutions, we can examine various forms of cross-validation techniques.
Techniques and How To Use Them
There are several different types of methods for out-of-sample testing and we can classify them under two broad categories: non-exhaustive and exhaustive.
Non-Exhaustive Approach
These methods do not utilize all possible ways of splitting the original dataset. As part of this approach, only a subset of all possible combinations of training and testing sets are evaluated. This approach is used to save computational resources when dealing with large datasets or when the model training process is time-consuming. Let’s look into some of the methods in detail.
Hold-Out Method
This is a basic and simplest approach of all the methods. Here the data is first randomly shuffled and then we divide the entire dataset into 2 parts, training and testing set. The sizes of both subsets should be different, with the test set recommended to be smaller than the training set.
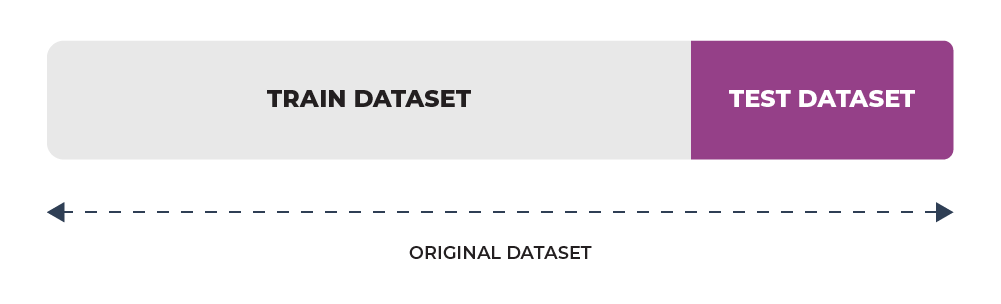
In a typical cross validation process, the outcomes of multiple model testing runs are combined and averaged. In contrast, the holdout method employs a single run for testing (i.e. it is our regular train-test split process). It is easy to implement or use using the scikit-learn train_test_split library.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
iris_df = load_iris()
x, y = iris_df.data, iris_df.target
x_train,x_test,y_train,y_test=train_test_split(
x,y,test_size=0.4,random_state=120)However, it’s important to exercise caution because the results may be significantly misleading by depending on one single run of the test.
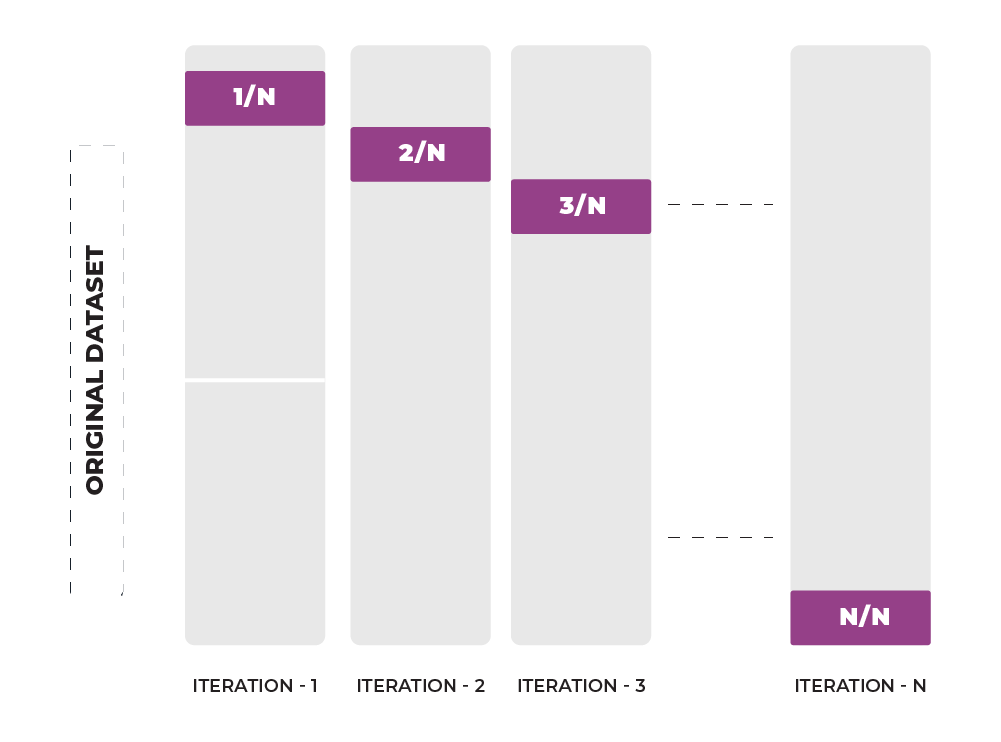
K-Fold Method
This method randomly partitions the dataset into K sub samples, called folds. It involves repeating the procedure k times, where each of the k subsamples is used once as validation data. The results from each of the k runs are then averaged to produce a single estimation. Compared to the repeated random sub-sampling method, this approach has the advantage that all observations are used for both training and validation, and each observation is used for validation exactly once.

Let’s take an example of 5-fold cross-validation. The dataset is divided into five subsets, or folds. During the first iteration, one fold is kept aside as the test set while the remaining four are used to train the model. In the second iteration, another fold is selected as the test set, while the remaining three are used for training. This process is repeated until each fold has been used as the test set exactly once.
import numpy as np
from sklearn.model_selection import KFold, train_test_split
from sklearn.datasets import load_iris
iris_df = load_iris()
x, y = iris_df.data, iris_df.target
cv = KFold(n_splits=5, random_state=42, shuffle=True)
for train_index, test_index in cv.split(x,y):
X_train, X_test, y_train, y_test = train_test_split(x,y,test_size=0.4)While 10-fold cross-validation is a commonly used technique, the value of k can vary based on specific requirements. When K=n (number of total observations in a dataset), it is equivalent to leave-one-out cross-validation.
Exhaustive Approach
This approach, as the name sounds, involves examining all possible solutions or outcomes. We divide the original dataset into all the possible ways to train and test subsets. It is typically used when the problem space is relatively small or when it is computationally feasible to examine all possible solutions.
Leave-P-Out Method
In this method, we use P number of points out from the total number of data points N. We train the model on (N – P) data points and test the model on P data points. We need to iteratively run this trial for all the possible combinations of P and (N – P). To calculate the final performance metric, we can average accuracies of total iterations.
import numpy as np
from sklearn.model_selection import LeavePOut
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])
lpo = LeavePOut(2)
i=0
for train_index, test_index in lpo.split(X):
print("Fold: ", i)
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")
i = i+1Leave-One-Out Method
This is similar to Leave-P-Out except in this method we remove only 1 data point of the original dataset. Basically, training a model N times, where N is the number of data points in the set, with each training excluding one data point and using the excluded point for prediction.
import numpy as np
from sklearn.model_selection import LeaveOneOut
X = np.array([[1, 2], [3, 4]])
y = np.array([1, 2])
lpo = LeaveOneOut()
i=0
for train_index, test_index in lpo.split(X):
print("Fold: ", i)
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")
i = i+1There is minimal chance of data bias as we are using every data point throughout the process but execution time is higher compared to other methods. Similarly to the previous method here also, we average the accuracy of all the iterations.
Rolling Cross Validation
Conventional cross-validation methods are not suitable for sequential data, such as time-series, because it’s not feasible to randomly assign data points to the training or test set. This is because using future values to predict past values is illogical and violates the temporal ordering of the data. Rolling CV is a technique used to evaluate the performance of a predictive model on time-series data or sequential data.

In rolling cross validation, a window of fixed size is moved through the dataset, with each window containing a subset of the data. The model is then trained on the data within the window and evaluated on the data outside the window. The window is then moved forward by a fixed number of steps and the process is repeated until the entire dataset has been used for evaluation.
Now that we are familiar with some of the popular cross validation techniques, let’s identify when it is absolutely necessary to use it.
When and Where To Use
Limited Data – When the available data is limited, cross-validation can be used to maximise the use of the available data for training and validation. By partitioning the data into several subsets, cross-validation allows the model to be trained and evaluated on different portions of the data.
Model Selection – When there are multiple models to choose from, cross-validation can be used to compare their performance and select the best one. By training and evaluating each model on different subsets of the data, cross-validation provides an unbiased estimate of the model’s generalization error.
Hyperparameter Tuning – When a model has hyperparameters that need to be tuned, cross-validation can be used to select the best combination of hyperparameters. By evaluating the performance of the model with different hyperparameters on different subsets of the data, cross-validation allows the hyperparameters to be tuned without overfitting to the training data.
Outlier Detection – Cross-validation can also be used for outlier detection. By comparing the performance of a model on different subsets of the data, cross-validation can identify outliers that have a significant impact on the model’s performance.
While cross-validation is a useful technique for evaluating model performance, it is not without its limitations. If we don’t choose the CV methods as per the data needs, it can impact the advantages it has to offer.
Modern Application: Large Language Models
Cross-validation is especially important for large language models (LLMs) because they are often trained on massive datasets with millions or even billions of examples. Such large datasets can be challenging to work with, as it can be difficult to know if the model is truly generalizing well to new examples or if it has simply memorized the training set.
Cross validation can also help us tune the hyperparameters of the model, such as the learning rate, batch size, and regularization strength, to improve its performance. By experimenting with different hyperparameter settings and using cross-validation to evaluate the results, we can find the best combination of hyperparameters for our specific task and dataset. There are many pre-trained models available like BERT, which we can fine tune using a cross validation process.
Keeping the purpose of this article in mind, in this section we will only explore one part of cross validation in LLMs. Here we will create a text classification model using BERT and use K-fold cross validation to measure the accuracy of our model with different subset of the data.
Get the Data & Clean
Get the data and preprocess using tokenization, padding, and encoding the text data.
import pandas as pd
import nltk
import re
from nltk.corpus import stopwords
twitter_df = pd.read_csv("/content/twitter_training.csv",header=None)
col=['id','type','label','review']
twitter_df.columns=col
twitter_df['label'].replace({'Negative':0,'Irrelevant':1,'Neutral':2,'Positive':3},inplace=True)
nltk.download('punkt')
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
%%time
#Removes Punctuations
def remove_punctuations(data):
punct_tag=re.compile(r'[^\w\s]')
data=punct_tag.sub(r'',data)
return data
#Removes HTML syntaxes
def remove_html(data):
html_tag=re.compile(r'<.*?>')
data=html_tag.sub(r'',data)
return data
#Removes URL data
def remove_url(data):
url_clean= re.compile(r"https://\S+|www\.\S+")
data=url_clean.sub(r'',data)
return data
#Removes Emojis
def remove_emoji(data):
emoji_clean= re.compile("["
u"\U0001F600-\U0001F64F"
u"\U0001F300-\U0001F5FF"
u"\U0001F680-\U0001F6FF"
u"\U0001F1E0-\U0001F1FF"
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
data=emoji_clean.sub(r'',data)
url_clean= re.compile(r"https://\S+|www\.\S+")
data=url_clean.sub(r'',data)
return data
#remove stopwords
stop_words.add('subject')
stop_words.add('http')
def remove_stopwords(text):
return " ".join([word for word in str(text).split() if word not in stop_words])
twitter_df['review'] = twitter_df['review'].apply(lambda z: remove_stopwords(z))
twitter_df['review']=twitter_df['review'].apply(lambda z: remove_punctuations(z))
twitter_df['review']=twitter_df['review'].apply(lambda z: remove_html(z))
twitter_df['review']=twitter_df['review'].apply(lambda z: remove_url(z))
twitter_df['review']=twitter_df['review'].apply(lambda z: remove_emoji(z))
twitter_d = twitter_df[['review','label']]import tensorflow as tf
X = twitter_d['review']
Y = twitter_d['label']
Y = tf.keras.utils.to_categorical(Y)Preprocessing the Data
Preprocess the data by using tokenizer, encoder, etc.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from collections import Counter
unique_words = Counter()
twitter_d['review']=twitter_d['review'].str.lower().str.split()
out = Counter(twitter_d['review'].explode())
max_sequence_len = 0
vocab_size = len(out)
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(twitter_d['review'])
sequences = tokenizer.texts_to_sequences(X_train)
padded = pad_sequences(sequences, maxlen=max_sequence_len, padding='post')When we will train and test the model using CV, we will be using this tokenizer.
Choose the Model
Choose the model and compile the same. The model architecture can be defined when we start to train it and then we can set the hyperparameters, such as learning rate, batch size, and number of epochs.
from tensorflow.keras import regularizers
from tensorflow.keras.regularizers import l2
from transformers import TFBertForSequenceClassification
import tensorflow as tf
model = TFBertForSequenceClassification.from_pretrained('bert-base-multilingual-cased', num_labels=4)
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])Train & Evaluate the Model
Train the model on k1 folds of the data, using one fold for validation. Repeat this process k times, using each fold once as the validation set. Evaluate the performance of the model on each fold using accuracy. You can use the average of the performance metrics across all folds to get an estimate of the model’s performance.
import tensorflow as tf
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
kfold = KFold(n_splits=5)
test_pred=np.zeros((len(X_test),4))
for train_index, test_index in kfold.split(X, Y):
tokenizer.fit_on_texts(X[train_index])
training_sequences = tokenizer.texts_to_sequences(X[train_index])
training_padded = pad_sequences(training_sequences, maxlen=max_sequence_len, padding='post')
train_inputs=training_padded
train_labels=Y[train_index]
tokenizer.fit_on_texts(X[test_index])
test_sequences = tokenizer.texts_to_sequences(X[test_index])
test_padded = pad_sequences(training_sequences, maxlen=max_sequence_len, padding='post')
val_inputs=test_padded
test_labels=Y[test_index]
lr=tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss',
factor=0.5,
patience=5)
early_stopping=tf.keras.callbacks.EarlyStopping(patience=5)
model.fit(train_inputs, train_labels,epochs=20, verbose = 1,
validation_data=(val_inputs,test_labels),
batch_size = 128,callbacks=[early_stopping,lr])
results=model.evaluate(val_inputs,test_labels)Furthermore, we can optimize hyperparameters by using the results from cross-validation to tune the hyperparameters of the model, such as the learning rate, batch size, or number of epochs. Once you optimize the hyperparameters, test the model on a separate test set that hasn’t been used for training or validation. Evaluate the model’s performance on this test set and report the results.
Summary
Throughout this article, we touch base from basics of cross validation to how it can be used in modern applications. Here are some of the major topics we covered:
- Cross Validation is important for choosing a machine learning model with best performance.
- Depending on the requirement, we can choose the CV method and each CV works differently and if not applied correctly might affect the model’s performance.
- Cross validation is one of the basic steps which we follow in ML and continues to be important with large language models