



A version of this article appeared on X and LinkedIn.
If you’re building agents, you’ve probably studied Claude Code’s leaked harness architecture. The design is clean, the loop is elegant, and the finish condition can be explained in five lines of pseudocode. Many teams have understandably borrowed from it. At Arize, we couldn’t help but compare Claude Code’s harness with our own agent’s, Alyx. When I sat down to validate a few things for a quick “how we built it” post, I was surprised at what my eval suite revealed about building a harness that survives multiple model generations.
In this post, I share how I used evals to quantify how a frontier model changed over time and built a provably better harness architecture for adapting to that drift.
The implicit finish, and why it’s a Claude-shaped pattern
Claude models are trained to combine narration and action in a single response. Claude says “let me search for that…” and fires the tool call in the same message. When the Claude Code harness receives a response without tools, it assumes the task has been completed and breaks the loop. Because Claude rarely sends a text-only response while there’s still work to do, this Implicit Finish never exits early.
Here’s pseudocode of Claude Code’s loop:
while True:
response = ask_the_model(messages)
if response has tool calls:
results = run_those_tools()
messages.append(results)
else:
break # we’re done
That else: break is the Implicit Finish. If no tools are requested, surely the model must be done, right? It’s a major assumption about the model under the hood. It’s clean. It’s correct… for Claude, and for harnesses built to accommodate Claude. The pattern got normalized.
OpenAI’s GPT models, historically, worked differently. From 2023 to 2024, GPT would announce its next action in one turn: “I’m going to search for that file now.” Then it would do the search on the following turn. Hooked up to Claude Code’s harness, the implicit finish would interpret that announcement as completion and exit the loop. And this happened, repeatedly:
- Oct 2023: First reports of
finish_reason:stop during function calls - June 2024:
finish_reasonmismatch; tool calls present but flagged as “stop” - Aug 2024: Our internal testing at Arize showed GPT splits text and tools across turns
- Sep 2024: Reliability hit in GPT-4o tool calling
- Aug 2025: GPT-4.1 saying “Hang tight…” without making tool calls
- Feb 2026: OpenClaw + Codex text-only “I’ll do it” responses, zero tool calls, run marked complete
This wasn’t just troubling Alyx. Goose users filed issue after issue about agents that announce action and then stop. The Vercel AI SDK added toolChoice: ‘required’ and stopWhen so callers can sidestep the implicit finish entirely. OpenAI had to patch its own Agents SDK in the opposite direction because their loop was exiting too eagerly when handling Claude’s combined-message responses. The whole ecosystem has been routing around the same implicit-finish assumption, and the shape of the workaround depends on the model.
This is the bug I expected to find when I strapped GPT-4o into a miniature version of Claude Code’s harness. Mostly, I didn’t.
What the eval actually showed
For Alyx, we used an Explicit Finish pattern. The model has to call a finish() tool, and the harness checks the work before accepting it. More tokens, more iterations, but more reliable completion. The design has been working in production since the end of 2025 with no trouble.
To stress-test both designs, I built three mini harnesses:
- Implicit Finish Claude Code’s pattern where an empty tool list means the task is done.
- Explicit Finish Alyx’s pattern. The model must call
finish(). Validation happens before exit. - Adaptive Finish A third variant of my own design that escalates from text-only nudges to required tool calls when it suspects the model is narrating instead of acting.
Then I built an eval suite with Phoenix to demonstrate the win, fully expecting to prove that Explicit Finish always works and Adaptive Finish is the best pattern. (Don’t take my word for it. The harnesses, eval tasks, and runner are all on GitHub.)
The proof refused to cooperate.
I ran Claude Sonnet 4, GPT-4o, and Gemma 4 31B against all three harnesses across 13 tasks. This resulted in 117 runs spanning lookup-and-calculate, research synthesis, file analysis, comparison, iterative refinement, and three long summary-finale tasks designed to provoke narrate-then-act.
Every harness completed every task on every model. The bug I’d built the eval suite around, the one our engineers vividly remembered and had proudly sidestepped, had become a rounding error in present day GPT-4o. Sometime after the launch of Alyx, GPT-4o’s behavior had quietly shifted: it now narrates while acting, more like Claude. Whether this was done purposely by OpenAI for better interop across harnesses or is a symptom of convergence, I cannot say.
But the false finish issue didn’t disappear entirely. The Adaptive Harness caught it twice, once on a comparison task, once on a summary-finale task. Both times, GPT-4o announced an action and exited without performing it:
GPT-4o, summary-finale task:
“Finally, I’ll write a Fun Fact that combines at least three
of the numbers we calculated. Let’s proceed with that.”
✅ EXIT: No tool calls in response.
Announce the fun fact, exit before writing it: classic narrate-then-act. It is less reliably reproducible than it was a year ago, but still there, completely invisible in a transcript that ends on a coherent sentence. Both times, the Adaptive Harness flagged the exit, sent a nudge, and the work got finished.
This is how the Adaptive Harness detects whether the agent is done yet using positional awareness, in pseudo code:
trailing_text = text[-300:]
for pattern in NARRATE_PATTERNS_COMPILED:
for match in pattern.finditer(trailing_text):
chars_after = len(trailing_text) – match.end()
if chars_after < 100:
matched.append(match.group(0))
If real content follows the narration, the model is doing the thing it announced. If nothing follows, it’s about to exit. These ~10 lines caught two false finishes across the entire 117-run benchmark and routed each back to the model with a nudge instead of a silent exit.
Let me break down how each harness performed:
| Harness | Completed | Correct | False finishes caught | Total tokens |
|---|---|---|---|---|
| Implicit | 39/39 (100%) | 3/9 | — | 858K |
| Adaptive | 39/39 (100%) | 4/9 | 2 | 913K (+6%) |
| Explicit | 39/39 (100%) | 4/9 | 0 | 965K (+12%) |
Here, completion means the loop exited normally, and correctness means the final output actually answered the question fully. This is a stricter bar that catches tasks where the agent finished confidently but skipped a step.
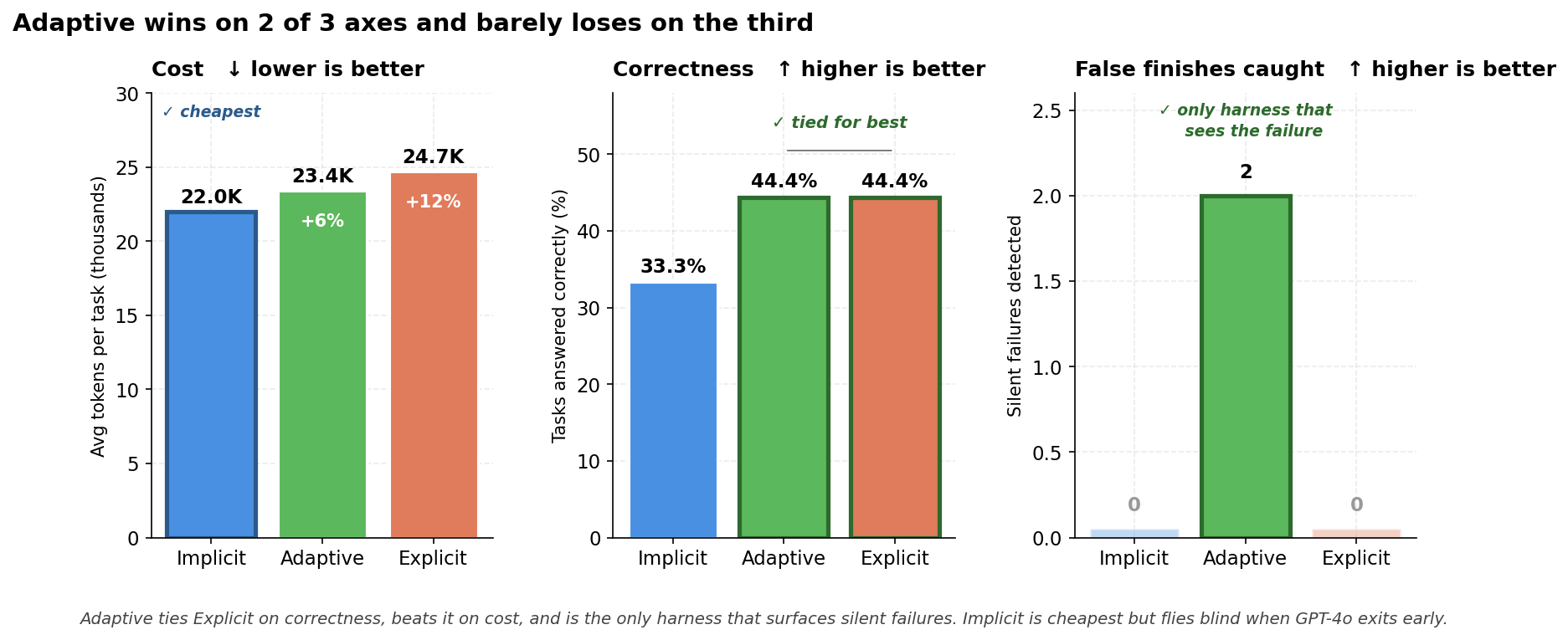
- Implicit is the cheapest harness, and the cheapest harness is the only one that misses both silent failures.
- Explicit pays a 12% premium and matches Adaptive on correctness, but doesn’t surface the false finishes that Adaptive does.
- Adaptive is correct, catches false finishes, and is the second cheapest in token consumption.
One way to make the Explicit Harness more reliable might be to give the agent a todo-list tool and require it to mark every step complete before finish() is accepted. But that increases the complexity of the harness, increasing its token consumption. It is a design trade-off, more complexity, cost, and new failure modes to gain a very reliable task completion logic.
For 6% more token usage than Implicit, the Adaptive Harness catches false finishes and is as correct as Explicit for less. That’s a real improvement.
The hidden-tuning trap I caught myself in
I almost shipped this article with a section about how Claude was breaking on long sequential tasks.
The first run of the benchmark showed Claude hitting max_iterations on two of my three longest tasks, identically across all three harness designs. It looked like the model the harness was designed for no longer fit the harness. I had the chart, the table, the headline: “Static per-model assignment is the brittle pattern.” It was going to be the centerpiece of the post.
Then I checked my own harness configuration.
The iteration cap was set to 15. My longest tasks had 10-15 subtasks. Claude wasn’t hitting the wall because it had outgrown the harness. It had hit the wall because I hadn’t given it enough headroom above the subtask count. I adjusted the tasks to leave room, and the “Claude break” disappeared. Across the final 117-run benchmark, Claude hit 100% completion on every harness.
The bug was in my configuration, not in Claude.
This underscored something I almost missed while chasing the implicit-finish story: every harness has hidden tunings that are quietly model-specific. Exit conditions. Iteration caps. Retry budgets. Error-parsing heuristics. Tool-call format expectations. Context-window assumptions. Every one of these is a bet you’ve placed on a model’s behavior, whether you wrote it down as a design decision or not.
The way you find these is by running evals on multiple models, on different task shapes, regularly. Or you ship them and let your customers find them for you.
When the model moves underneath you
If I’d written this article six months ago, the headline would have been “Claude Code’s harness breaks on GPT.” It largely doesn’t anymore.
- Harness performance is a function of (model × task structure), and neither are constants. Models update. Tasks vary. A loop that passes today on one suite can fail tomorrow on the same suite with a new model checkpoint, and pass on the same model under a different task shape.
- Building for multiple models and across time turns out to be a different discipline from building a clean loop. If your evals don’t cover both axes, you can’t know whether your agent works.
Do these now
- Default to an Adaptive Harness. This design caught two real false finishes on GPT-4o that the Implicit Harness would have failed on silently. It improved correctness from 3/9 to 4/9. It cost 6% more in tokens. The Implicit Harness is cheaper but invisible when it fails. The Explicit Harness is twice as expensive on the cost side and matches the Adaptive Harness on correctness while losing the trace observability. The Adaptive Harness architecture is worth investigating for multi-model deployments.
- Surface your harness’s hidden tunings. The iteration cap that almost made me ship a fake Claude-broke-on-Claude story wasn’t a load-bearing design decision; it was a default I’d never revisited. Pull these constants out of the code and into your eval suite as configurable variables, so when a model changes or when a task shape pushes past your assumptions you see immediately which assumption no longer holds.
- Run evals on multiple models. I ran the same tests against Gemma 4 31B alongside Claude Sonnet 4 and GPT-4o. All three models hit 100% completion across all three harnesses. None of them surfaced narrate-then-act except GPT-4o on those two specific tasks. Without the multi-model test, I’d have written a Claude-only or GPT-only architecture and missed the underlying assumptions impacting harness performance. The detector that caught GPT’s two slip-ups also costs nothing on Claude and Gemma, where it never fired. That’s the design that survives a model update.
Build the suite, not just the loop
The Adaptive Harness ended up being the most reliable and only marginally more expensive than the lightest option. But the harness wasn’t the point. The point is that the eval suite was ready to go the day a new model dropped, so when GPT-4o tried to exit early, I saw it within minutes instead of in production. And when I almost shipped a story blaming Claude for an iteration cap I’d set myself, the same suite saved me from embarrassing myself, or worse, spreading false information in an already noisy space.
Claude Code’s loop is a beautiful piece of agent design, and there’s a lot to learn from it. But any harness, including the one you build next, is implicitly optimized for the model you’re testing against on the day you write it.
By building evals designed to reproduce edge cases, I ended up with a harness that adapts to different model behaviors instead of optimizing for only one. Now I can re-checking that adaptation every time a new model ships.
Don’t take my word for any of this. The harnesses, eval tasks, and runner are all on GitHub. Poke all the holes you like into them, and let me know what you find.