Over the past few weeks, the Arize team has generated the largest public dataset of hallucinations, as well as a series of fine-tuned evaluation models. We wanted to create a replicable, evolving dataset that can keep pace with model training so that you always know you’re testing with data your model has never seen before. We also saw the prohibitively high cost of running LLM evals at scale, and have used our data to fine-tune a series of SLMs that perform just as well as their base LLM counterparts, but at 1/10 the cost.
In this post you’ll find a recap of a recent session where we talk about what we built, the process we took, and the bottom line results.
Watch
Listen
Learn More
LibreEval: A Smarter Way to Detect LLM Hallucinations
LLMs are getting better and better—but how reliable are their responses, really? Especially when used in RAG systems, hallucinations remain a major challenge. To address this, our team recently launched LibreEval, a new open-source project focused on evaluating hallucinations more accurately and affordably. In a recent paper reading, we walked through the motivation behind the project, how it works, and what it unlocks for the future of LLM evals.
What’s Wrong With Current Evaluation Benchmarks?
For anyone working with LLMs—especially in production—evaluation is key. But many existing benchmarks like HaluEval and HotpotQA are starting to show their age. We saw two major issues:
- Benchmark contamination: The odds of GPT-4 being trained on HaluEval are pretty high. That means models might ace these benchmarks not because they’re robust, but because they’ve memorized the answers. This makes it harder to trust their real-world performance.
- High costs: Running hallucination evals with top-tier models like GPT-4 or Claude 3 can get expensive—fast. You’re effectively doubling inference costs to evaluate generation, which makes frequent testing cost-prohibitive.
LibreEval: Open, Scalable, and Realistic
We built LibreEval to address these issues head-on. It consists of two main components:
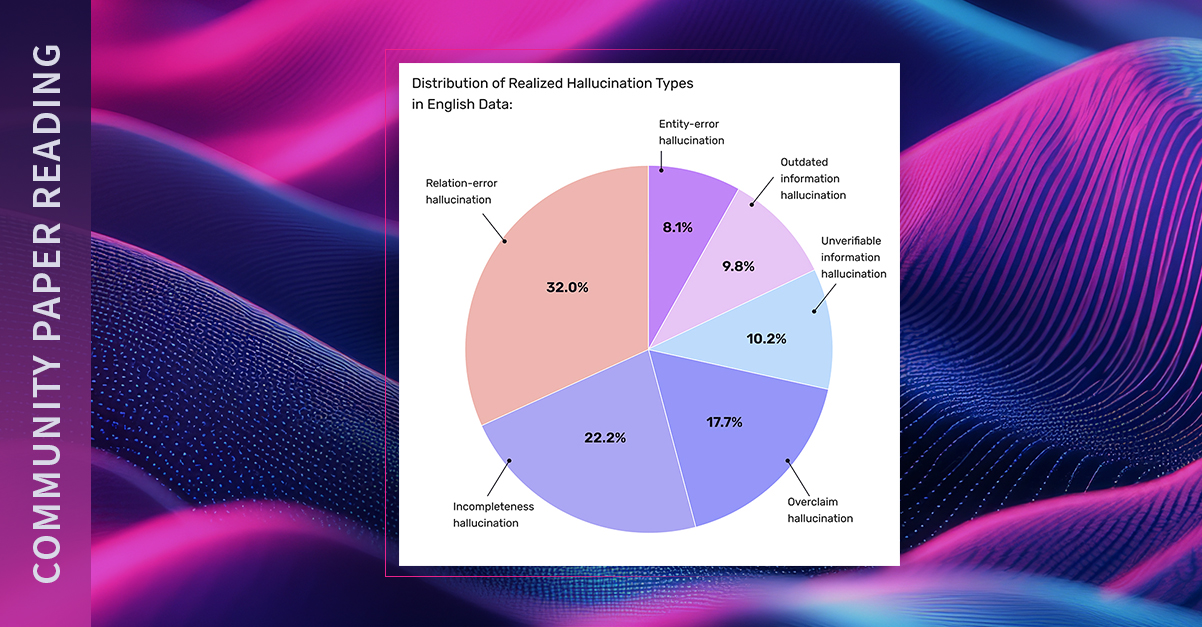
1. A Massive Open-Labeled Hallucination Dataset
- 70K examples, designed specifically to evaluate RAG systems on context adherence
- Multilingual coverage: English, Spanish, French, Japanese, Korean, Chinese, and Portuguese
- Synthetic + real-world hallucinations: The dataset includes both LLM-generated (induced) and naturally occurring examples
- Consensus labeling: Three different LLMs (GPT-4, Claude 3.5 Sonnet, LLaMA 3.2) judged each sample to reach agreement on hallucination status
2. Fine-Tuned Models for Hallucination Detection
We also trained compact, 1.5B-parameter models on the Libra Eval dataset.
These models are:
- Purpose-built for hallucination detection
- Cost-efficient: Fine-tuning cost ~$30 and inference cost is roughly 10x cheaper than using GPT-4
- Highly performant: In some cases, these smaller models outperformed other small LLMs on hallucination detection tasks
Key Takeaways from the Research
Here’s what we learned from building and testing LibreEval:
- Synthetic ≠ natural hallucinations: Most current benchmarks over-index on synthetic examples. Libra Eval reveals that models behave differently when detecting real-world hallucinations.
- Language matters less than expected: Surprisingly, detection performance was fairly consistent across languages—even in non-English examples.
- LLM judges can rival human annotators: In head-to-head comparisons, the consensus labels from LLMs matched (and sometimes exceeded) the quality of labels from human annotation services.
From Research to Reality: A Data Flywheel for Evaluation
LibreEval isn’t just a dataset—it’s becoming the backbone of a continuous evaluation loop inside Arize’s platform:
- Monitor LLM apps in production
- Run hallucination checks using Libra Eval’s lightweight models
- Identify tricky edge cases where models disagree or show low confidence
- Send those examples to human reviewers for adjudication
- Use that feedback to fine-tune the hallucination detectors
- Redeploy improved models—and repeat!
This loop turns evals into a self-improving system. It’s like model monitoring for your model evaluation pipeline.
LibreEval shows that we don’t have to choose between cost and accuracy when evaluating LLMs. By combining open data, fine-tuned small models, and continuous feedback loops, it offers a path forward for scalable and trustworthy LLM monitoring.
Whether you’re building with RAG, deploying LLMs in production, or just trying to understand model behavior better, Libra Eval is a step toward making these systems safer and smarter.