




ML Infrastructure Tools for Data Preparation

Aparna Dhinakaran
Co-founder & Chief Product Officer
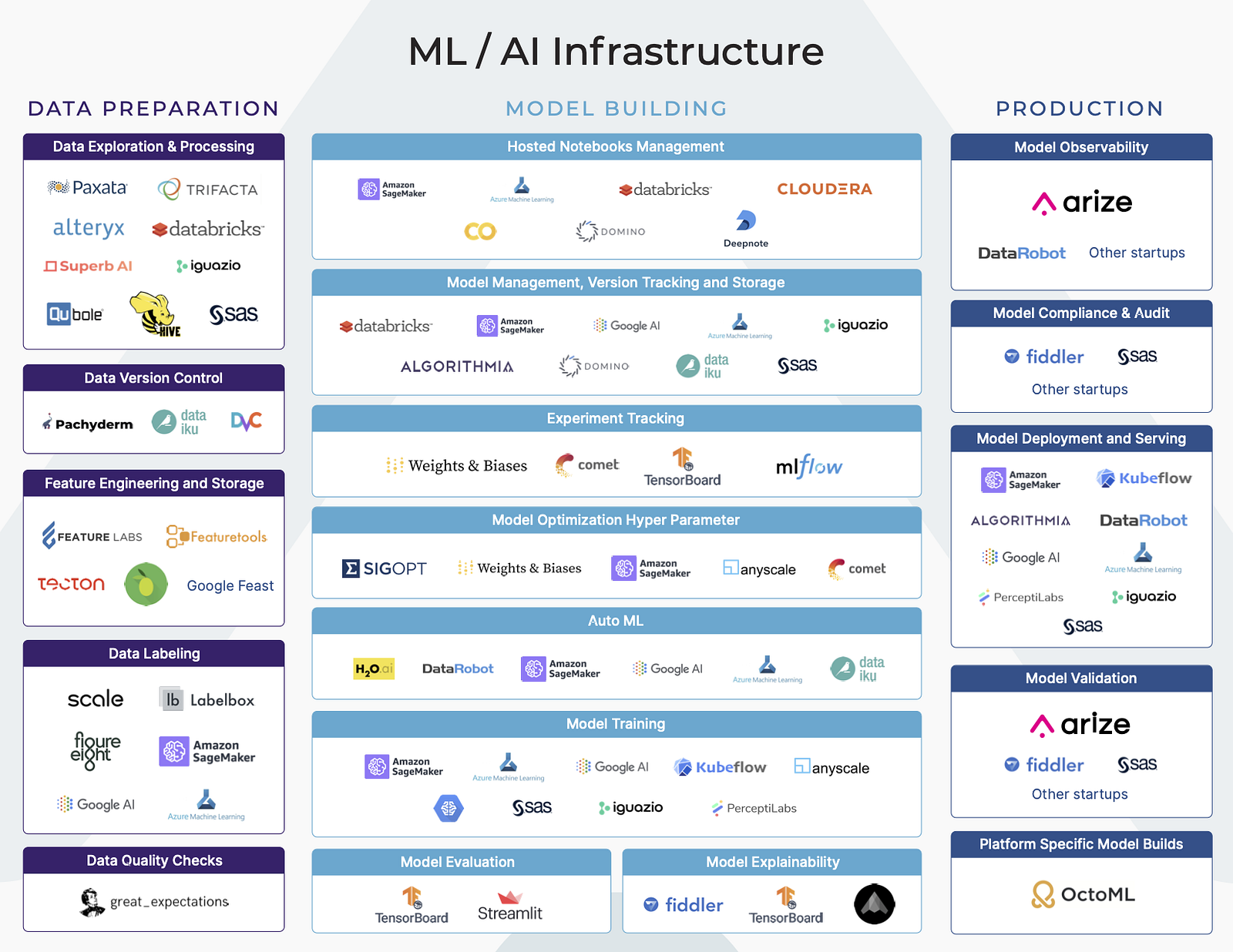
Artificial Intelligence (AI) and Machine Learning (ML) are being adopted by businesses in almost every industry. Many businesses are looking towards ML Infrastructure platforms to propel their movement of leveraging AI in their business. Understanding the various platforms and offerings can be a challenge. The ML Infrastructure space is crowded, confusing, and complex. There are a number of platforms and tools spanning a variety of functions across the model building workflow.
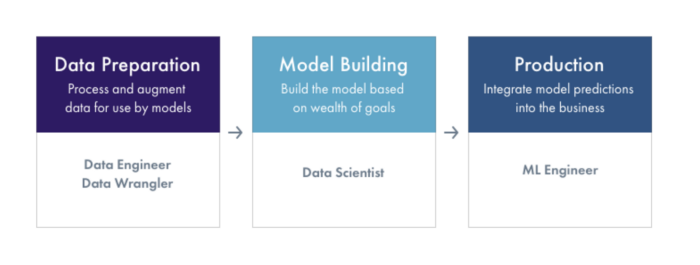
To understand the ecosystem, we broadly break up the machine learning workflow into three stages — data preparation, model building, and production. Understanding what the goals and challenges of each stage of the workflow can help make an informed decision on what ML Infrastructure platforms out there are best suited for your business’s needs.
Each of these broad stages of the Machine Learning workflow (Data Preparation, Model Building and Production) have a number of vertical functions. Some of these functions are part of a larger end-to-end platform, while some functions are the main focus of some platforms.
Since models are built and learned from data, the first step of building a model is data preparation — the process of extracting inputs to the model from data. There are a number of tools to help data scientists source data, transform data, and add labels to datasets. In this blog post, we will dive deep into understanding what are the goals of data preparation, challenges organizations face in this stage of the ML workflow, and when data scientists decide it is time to move onto the next stage of the workflow.
What is Data Preparation?
Ask any data scientist and they will tell you A LOT of their time is spent in data preparation. The data preparation phase of the pipeline is used to turn raw data into model input features used to train the model. Features are transformations on the cleaned data that provide the actual model inputs.
In the early stages of the pipeline, raw data is sourced across different data stores and lakes in an organization. The next stage involves data processing to clean, transform and extract features to generate consistent inputs in the feature selection stage. Large tech companies at the forefront of using ML Infrastructure (Google, Facebook, Uber, etc) will typically have central feature storage, so many teams can extract value without duplicate work.
The data preparation stage involves a number of steps: sourcing data, ensuring completeness, adding labels, and data transformations to generate features.
Sourcing Data
Sourcing data is the first step and often the first challenge. Data can live in various data stores, with different access permissions, and can be littered with personally identifiable information (PII).
The first step in data preparation involves sourcing data from the right places and consolidating data from different data lakes within an organization. This can be difficult if the model’s inputs, predictions, and actuals are received at different time periods and stored in separate data stores. Setting a common prediction or transaction ID can help tie predictions with their actuals.
This stage can often involve data management, data governance and legal to determine what data sources are available to use. The roles working in this stage usually involve the data engineer, data scientist, legal, and IT.
Example ML Infrastructure Companies in Data Storage: Elastic Search, Hive, Qubole
Completeness
Once the data is sourced, there are a series of checks on completeness needed to determine if the data collected can be turned into meaningful features. First, it is important to understand the length of historical data available to be used. This helps understand if the model builder has enough data for training purposes (a year’s worth of data, etc). Having data that has seasonal cycles and identified anomalies can help the model build resiliency.
Data completeness can also include checking if the data has proper labels. Many companies have problems with the raw data in terms of cleanliness. There can be multiple labels that mean the same thing. There will be some data that is unlabeled or mislabeled. A number of vendors offer Data Labeling services that employ a mix of technology and people to add labels to data and clean up issues.
Example ML Infrastructure Companies in Data Labeling: Scale AI, Figure Eight, LabelBox, Amazon Sagemaker
It is also important to have some check on whether the data seen is a representative distribution. Was the data collected over an unusual period of time? This is a tougher question because it is specific to the business and data will continue to change over time.
Data Processing
Once the data is collected and there is enough data across time with the proper labels, there can be a series of data transforms to go from raw data to features the model can understand. This stage is specific to the types of data that the business is using. For categorical values, it is common practice to use one-hot encoding. For numeric values, there can be some form for normalization based on the distribution of the data. A key part of this process is to understand your data, including data distributions.
Data processing can also involve additional data cleaning and adding data quality checks. Since models depend on the data they are training on, it is important to ensure clean data through removing duplicated events, indexing issues, and other data quality issues.
A set of data wrangling companies allow data scientists, business analysts, and data engineers to define rules for transformations to clean and prepare the data. These companies can range from no code, low code, to developer focused platforms.
Lastly, there are ongoing data quality checks that are done on training data to make sure what is clean today will be clean tomorrow.
Data preparation is integral to the model’s performance. There are a lot of challenges to getting complete and clean data. With all of the work that goes into building a training dataset from data sourcing to all of the data transformations, it can be difficult to track all of the versioned data transformations that can impact model performance. As an organization grows, a feature store with common data transformations can reduce duplicative work and compute costs.
ML Infrastructure Companies in Data Wrangling: Trifacta, Pixata, Alteryx
ML Infrastructure Companies in Data Processing: Spark, DataBricks, Qubole, Hive
ML Infrastructure Companies in Data Versioning, Feature Storage & Feature Extraction: Stealth Startups, Pachyderm, Alteryx
What Happens After Data Preparation
Once data scientists have the data ready, In some cases, the handoff between data preparation and model building is structured with a data file or feature store with processed data. In other cases, the handoff is fluid. In larger organizations the Data Engineering team is responsible for getting the data into a format that the data scientists can use for model building.
In many managed notebooks such as Databricks Managed Notebooks, Cloudera Data Science Workbench, Domino Data Labs Notebooks, the data preparation workflow is not separate from the model building. Feature selection is dependent on data so that function begins to blur the line between data preparation and model building.
ML Infrastructure Companies in Notebook Management: Databricks, Cloudera Workbench, Domino, Stealth Startups
Up Next
We’ll be doing a deeper dive into ML Infrastructure companies in the model building segment of the ML Workflow.
Contact Us
If this blog post caught your attention and you’re eager to learn more, follow us on Twitter and Medium! If you’d like to hear more about what we’re doing at Arize AI, reach out to us at contacts@arize.com. If you’re interested in joining a fun, rockstar engineering crew to help make models successful in production, reach out to us at jobs@arize.com!