





Learn why machine learning teams are adopting feature stores and how data monitoring can be used in tandem to prevent upstream data quality issues
Introduction
Since Uber first introduced the concept in 2017, the feature store has been rising in popularity as a tool to support data scientists and machine learning engineers with the ability to easily define, discover, and access high-quality data for their machine learning projects.
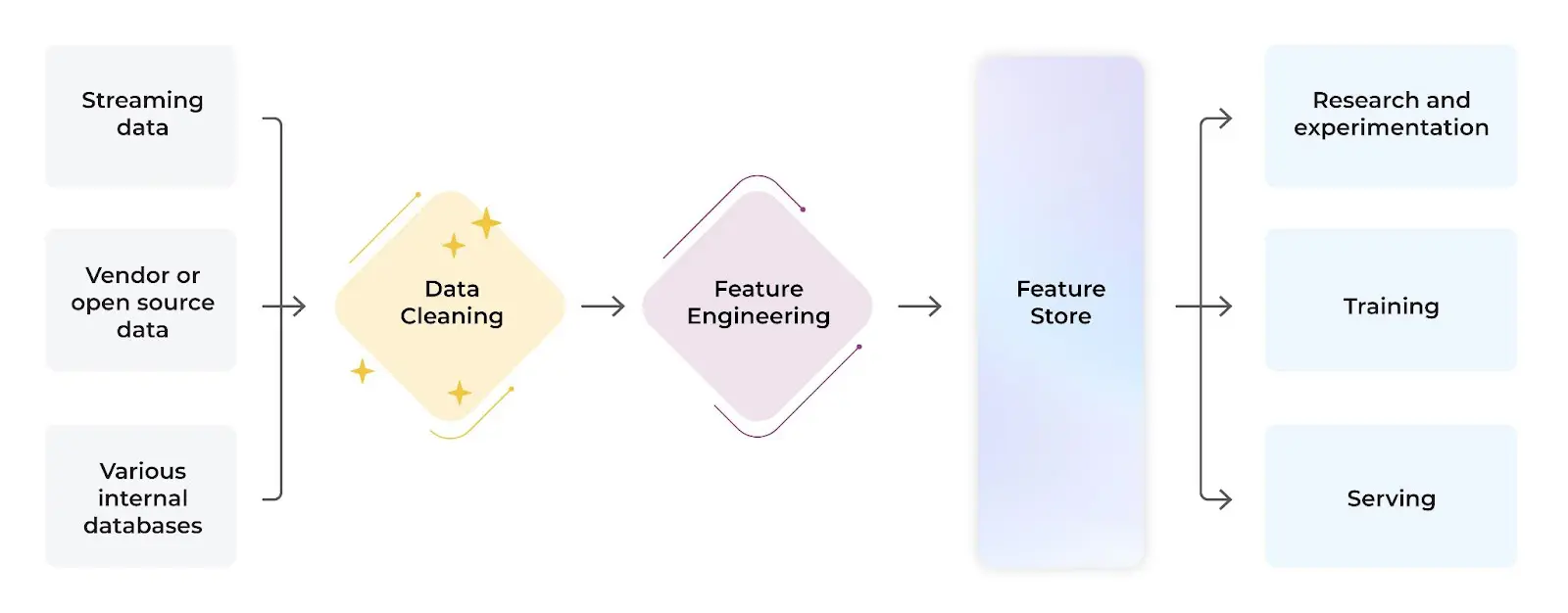
From Feature Engineering To a Feature Store
In machine learning projects, raw data is collected, cleaned, formatted and mathematically transformed into data called a “feature.” Features are required in many different phases of the model lifecycle including experimentation, model training, and model serving to get predictions from the model deployed in production pipelines.
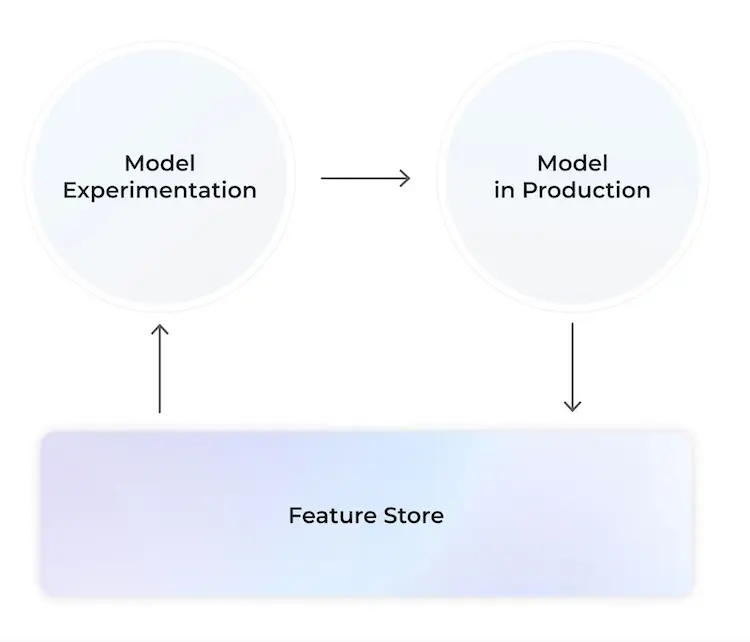
Once the features are calculated, we can begin to develop our model by experimenting with different modeling techniques and feature sets.
When models are trained, they automatically discover patterns in the feature data, encode these patterns mathematically, and then use this information to make informed predictions.
When the model is finalized, it is deployed into production where it consumes feature data to both retrain and produce predictions. Model predictions are often either produced in batch, or in some cases in real time.
What Is a Feature Store?
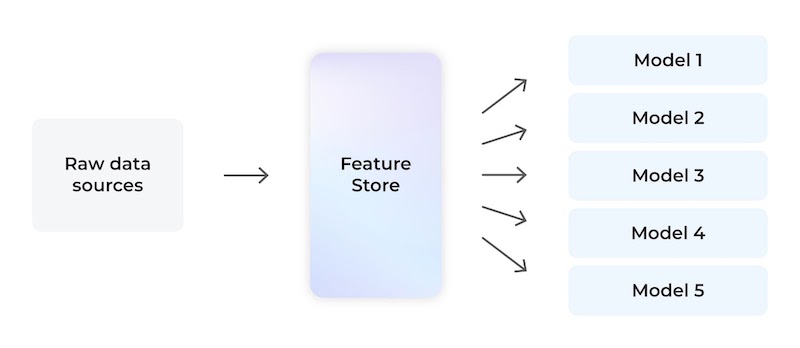
Feature stores can be thought of as a central store of precomputed features. This data store serves features for every step in a machine learning project.
Why Do Teams Use Feature Stores?
Organizations utilize feature stores to streamline a few things across the data and ML lifecycle.
Centralize data
- Feature stores provide a one-stop-shop for data that has already been collected from different sources and stored in a central location.
- Without a feature store, the raw data for a ML project often needs to be collected from multiple different data sources across the company, or even from a vendor or third party. This means data scientists have to identify and access multiple data sources.
Clean data
- Personally identifiable information (PII) or sensitive data that is not required for the ML workflow can be removed before storing it in the feature store.
- Without a feature store, data scientists would have to access sensitive data or create their own method to remove the sensitive data on their own when it is not required for their use case.
Share features across models
- The same features can often be used in multiple models across different use cases. The feature store calculates these features once and makes them available for all ML projects. data scientists can add to this feature bank over time to build up a store of features for other teams to reuse.
- Without a feature store, many of the same feature computations will be rewritten into indifferent models and pipelines. This forces data scientists to perform wasteful rework to recalculate features that may already exist in similar pipelines, and it makes it difficult to maintain consistency of the feature calculations.
Provide a common interface to the features
- Part of the feature store is a standardized inference to the data itself and shared feature encoders for ML pipelines to help enforce consistent results across online and offline applications.
- Without a feature store, different code or transformations could result in slightly unexpected or erroneous results in the model. This often manifests in online and offline feature skew.
Reduce feature latency
- An online feature store provides precomputed features to support serving real-time predictions with with low latency
- Without a feature store, features will need to be calculated at the time of the inference request, resulting in additional calculations needed at the time of the request – ultimately impacting application latency.
Navigate feature versioning
- Feature stores apply versioning to the data. Time traveling data snapshotting allows for point-in-time analysis for backtesting a model, or root causing a data bug.
- Without a feature store, it can be difficult to trace back the exact state or value of a feature for a given point in time. This can make debugging and experimentation challenging if not impossible.
What Are the Top Feature Stores?
Generally, feature stores are either offered as standalone, third-party tools or as part of broader cloud offerings. Most Arize customers with feature stores in place use a purpose-built tool like Tecton, however teams wanting to build on top of open-source solutions have several options (i.e. Feast, Feathr). Additionally, cloud offerings (Amazon, Databricks) are also available as easy add-ons to existing stacks.
Third-Party Tools
Tecton
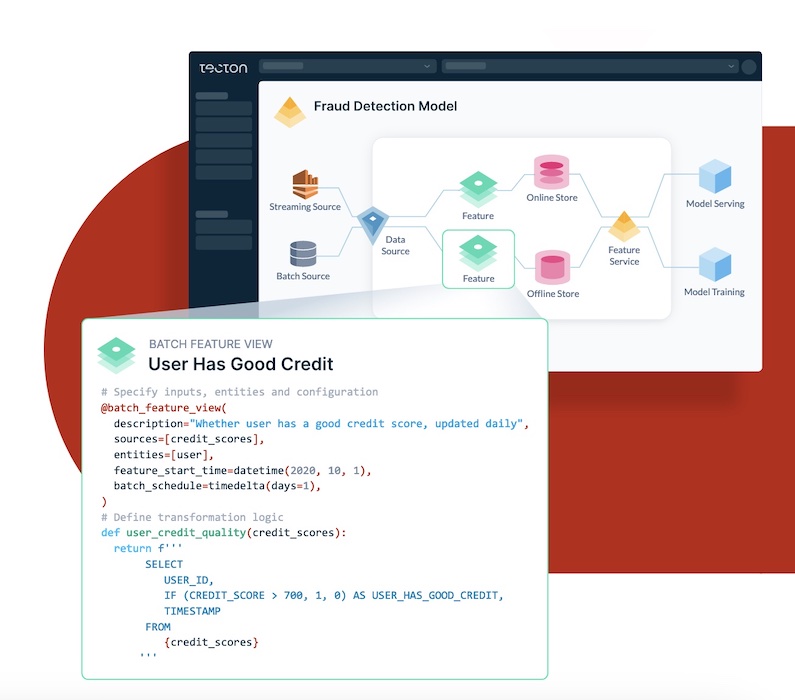
Tecton is a popular fully-managed feature platform built to orchestrate the complete lifecycle of features, from transformation to online serving, with enterprise-grade SLAs. With Tecton, ML teams can define and manage features using code in a git repository; automatically compute and orchestrate batch, streaming, and real-time feature transformations; store and serve feature data for training and inference; and share, discover, and manage access to features. Its customers include Atlassian, HelloFresh, Progressive, Mercury Insurance, Vital, and others.
See also: Feast, an open source feature store maintained by Tecton, Twitter, Shopify and others.
Feathr
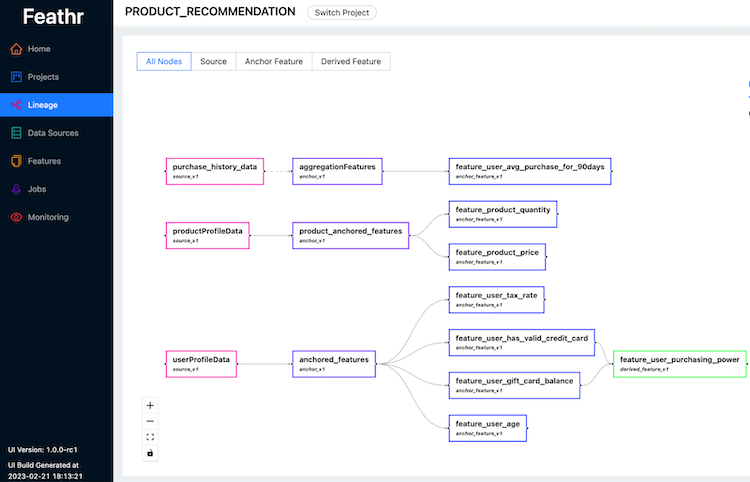 Feathr is the feature store developed at LinkedIn that was made an open source project in the spring of 2022. Feathr lets users: define features based on raw data sources (batch and streaming) using pythonic APIs; register and get features by names across model training and inference and share features across an organization. Feathr automatically computes feature values and joins them to training data, using point-in-time-correct semantics to avoid data leakage. Feathr also supports materializing and deploying your features for use online in production.
Feathr is the feature store developed at LinkedIn that was made an open source project in the spring of 2022. Feathr lets users: define features based on raw data sources (batch and streaming) using pythonic APIs; register and get features by names across model training and inference and share features across an organization. Feathr automatically computes feature values and joins them to training data, using point-in-time-correct semantics to avoid data leakage. Feathr also supports materializing and deploying your features for use online in production.
Cloud Tools
Databricks Feature Store
The Databricks Feature Store library is available on Databricks Runtime for Machine Learning and is accessible through Databricks notebooks and workflows. The Databricks Feature Store helps with discoverability (lets you browse and search for existing features); lineage (data sources used to create the feature table are saved and accessible); an integration with model scoring and serving to make model deployment and updates easier; and point-in-time lookups to support time series and event-based use cases that require point-in-time correctness.
SageMaker Feature Store
Amazon’s SageMaker Feature Store enables users to: store, share, and manage ML model features for training and inference to promote feature reuse across ML applications; ingest features from any data source including streaming and batch such as application logs, service logs, clickstreams, sensors, and tabular data from AWS or third party data sources; incorporate lineage tracking; execute point-in-time queries to retrieve the state of each feature at the historical time of interest; and more.
Should You Monitor Your Feature Store?
Feature stores can fail silently. When a model breaks or produces poor results, the root cause is often traced back to the data itself. Many common machine learning issues can be solved by applying the right monitoring and quality checks to the data.
If that data is centralized in a single feature store, it can be easier to maintain it. By applying data quality monitoring to the feature store, practitioners can automatically catch data issues before they impact model performance.
There are several common data issues where monitoring can make a big difference.
Data quality monitors can catch issues such as missing values, change in data format or unexpected values (change in data cardinality). An ML observability platform can be used to automatically detect and alert on these types of data quality issues, which are common with feature data.
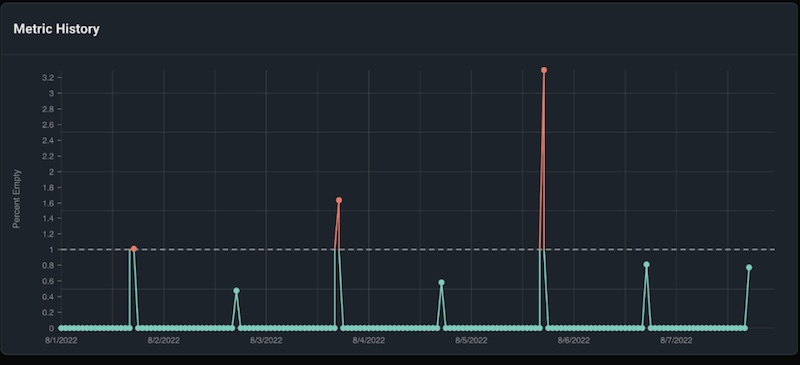
This example shows a triggered data quality monitor for the % empty metric on a model feature
Data drift monitors can catch statistical distribution shifts due to natural changes over time. Drift can be measured using metrics such as PSI, KL Divergence, and more. An ML observability platform can be used to automatically detect and alert on the kind of statistical drift that is common in feature data.
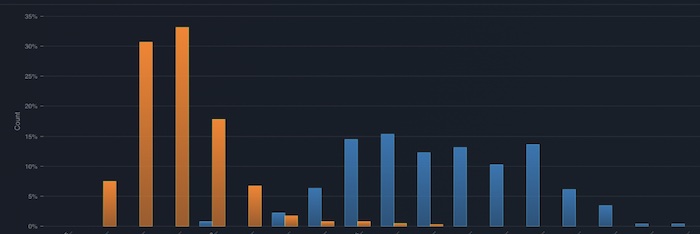
This example shows prediction drift between production and training data distributions
Additionally, training-serving skew can also be identified by troubleshooting for data consistency between offline and online feature calculations and code.
Get Started
Interested in taking the next steps in better monitoring your feature store and ML data? Check out Arize’s documentation, sign up for a free Arize account and join the Arize community.

