



A Quick Survey of Drift Metrics
In machine learning systems, drift monitoring is critical to delivering quality ML.
The use cases we see for drift analysis in production ML systems include:
- Detect feature changes between training and production to catch problems ahead of performance dips
- Detect prediction distribution shifts between two production periods as a proxy for performance changes (especially useful in delayed ground truth scenarios)
- Use drift as a signal for when to retrain – and how often to retrain
- Catch feature transformation issues or pipeline breaks
- Detect default fallback values used erroneously
- Find new data to go label
- Find clusters of new data that are problematic for the model in unstructured data
- Find anomalous clusters of data that are not in the training set
The problems above have plagued teams for many years, kicking off an endless search for the perfect drift metric. Here is a hard truth: it does not exist – in ML monitoring, there is no perfect drift metric. That said, we have learned a lot and we do have some well-tested approaches that deliver great results. This section is an attempt to bring more clarity to these metrics and how they are used in model monitoring.
In production, ML teams are almost exclusively working with binned distributions for structured data. Interestingly, how one creates bins can impact drift monitoring ten times more than the metric itself. A zero-bin comparison, for example, will blow up a lot of metrics. At Arize, we have a unique algorithm to handle zero bins outlined here, called out-of-distribution binning (ODB), referenced below.
Prevailing Drift Metrics
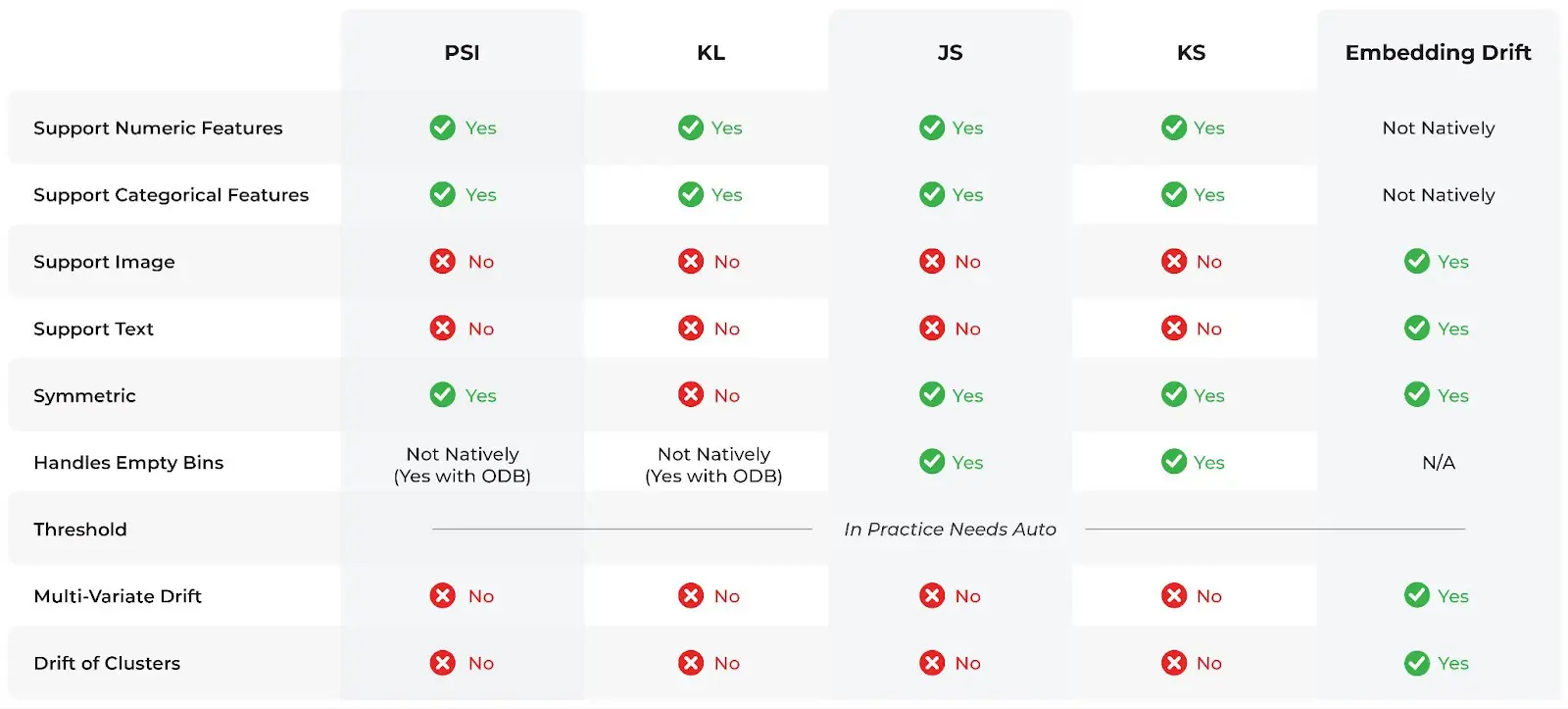
The above table gives a good breakdown of some of the most commonly-used drift metrics and statistical distance checks.
When To Use Drift Metrics
Here is a quick cheat sheet on when to apply drift metrics:
1. Receive Ground Truth in Production In a Timely Manner: If you are lucky enough to receive fast ground truth in production and get performance metrics back in a timely manner. We recommend measuring performance (RMSE, AUC, etc). In addition, feature drift is also highly used to stay ahead of common feature breakage issues.
2. Receive Ground Truth in Production With Large Delays (or No Ground Truth): Prediction drift, comparing a prediction output distribution to a prediction baseline, is used as a proxy for performance. In addition, feature drift is also highly used to stay ahead of common feature breakage issues.
3. Image, NLP or Unstructured Data: Any use of unstructured data is going to require an embedding drift approach. We recommend embedding drift for all unstructured use cases.
✏️ NOTE ON CONCEPT DRIFT: The measurement of concept drift, the drift between prediction and target, is rarely used. When teams receive ground truth in a timely manner, they almost always calculate performance directly (measuring MAE, LogLoss and AUC). If a team does not receive ground truth back in a timely manner, concept drift is irrelevant.h