
Updated 12/18/2024
How to Get the Most Out of Your Search and Retrieval Use Case
To create chatbots that are finely tuned to your business needs, it’s important to leverage your unique knowledge base. With RAG (retrieval-augmented generation), you can enhance chatbot performance by integrating relevant insights from your own documents. When you want to provide more information for the LLM, RAG enables your chatbot to deliver more accurate, context-aware responses. RAG draws on both internal knowledge and the latest, real-time information.
What is Retrieval Augmented Generation?
RAG enhances the content produced by LLMs by adding relevant material from external sources. Its strength lies in how it retrieves data, giving LLMs extra context that improves content generation.
This RAG roadmap outlines the key steps from data retrieval to response generation. In this article, we’ll explore these steps and compare online and offline RAG modes. Our journey through the RAG roadmap will not only highlight the technical aspects but also demonstrate the most effective ways to evaluate your search and retrieval results.
What Should You Know Before Using LLM Retrieval Augmented Generation?
As with any roadmap, you need to know your destination and the path to get there before setting off on your journey.
Consider avoiding RAG if you’re optimizing for cost, aiming to prevent data leakage to a proprietary model, new to prompt engineering, or focused on fine-tuning. Here’s a little more about why you might want to avoid RAG in the following scenarios:
- Trying to reduce cost and risk: You are trying to optimize performance. RAG can rack up runtime costs.
- Using proprietary data: If the LLM application you are using does not require secure data to generate responses, you can prompt the LLM directly and use additional tools and agents to keep responses relevant.
- New to prompt engineering: We recommend experimenting with prompt templates and prompt engineering to ask better questions to your LLMs and to best structure your outputs. However, prompts do not add additional context to your user’s queries.
- Fine-tuning your LLM: We recommend fine-tuning your model to get better at specific tasks by providing your LLM explicit examples. After you’ve experimented with performance improvements made by prompt engineering, you can fine-tune. Then you can add relevant content via RAG. Due to the speed and cost of iteration, keeping retrieval indices up-to-date is more efficient than continuously fine-tuning and retraining LLMs.

If you are building a RAG system, you are adding recent knowledge to a LLM application system in hopes that retrieved relevant knowledge will increase factuality and decrease model hallucinations in query responses.
What Are the Key Components of LLM RAG?
There are three key components of RAG. The retrieval engine facilitates search, the augmentation engine integrates the retrieved data with the query, and the generation engine formulates the response using a foundation model. I will expand on each of these below.
Retrieval augmented generation is an intricate system that blends the strengths of generative AI with the capabilities of a search engine. To fully understand RAG, it’s essential to break down its key components and how they function together to create a seamless AI experience.
Here is more detail on the important components of a RAG system:
- Retrieval Engine: This is the first step in the RAG process. It involves searching through a vast database of information to find relevant data that corresponds to the input query. This engine uses sophisticated algorithms to ensure the data retrieved is the most relevant and up-to-date.
- Augmentation Engine: The augmentation engine comes into play when the relevant data is retrieved. It integrates the retrieved data with the input query, enhancing the context and providing a more informed base for generating responses.
- Generation Engine: This is where the actual response is formulated. Using the augmented input, the generation engine, typically a sophisticated language model, creates a coherent and contextually relevant response. This response is not only based on the model’s preexisting knowledge, but also enhanced by the external data sourced by the retrieval engine.
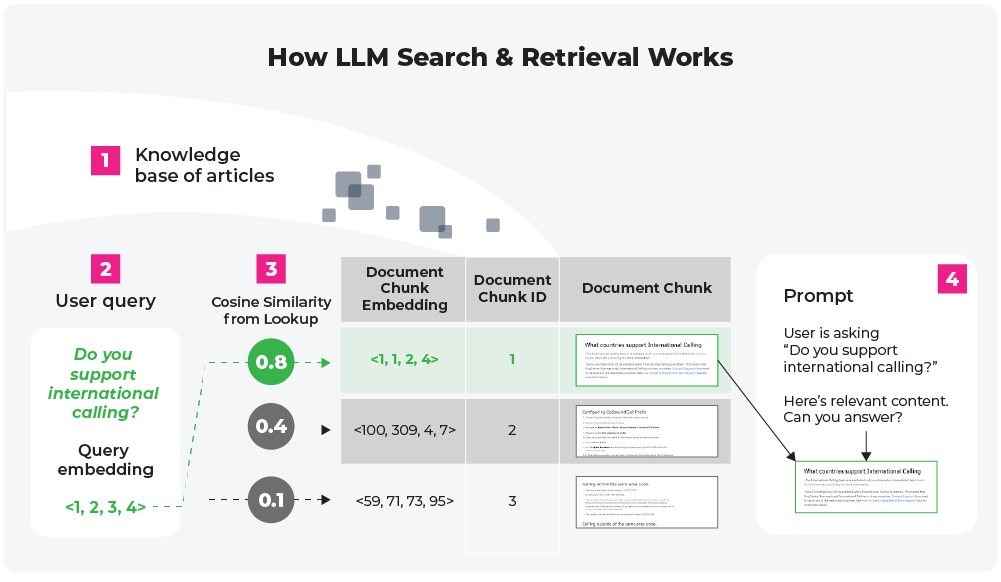
The RAG Roadmap
How Can You Ensure LLM RAG Systems Provide Accurate Answers Based On the Most Current and Relevant Information Available?

To ensure accuracy and relevance, successful RAG applications leverage data indexing, input query processing, search and re-ranking, prompt augmentation, response generation, and evaluation.
- Data Indexing: Before RAG can retrieve information, the system aggregates and organizes the data into an index, which serves as a reference point for the retrieval engine.
- Input Query Processing: The system processes and interprets the user’s input during input query processing, creating the search query for the retrieval engine.
- Search and Ranking: The retrieval engine searches the indexed data and ranks the results based on their relevance to the input query.
- Prompt Augmentation: The system combines the most relevant information with the original query, creating an augmented prompt that provides a richer source for response generation.
- Response Generation: Finally, the generation engine uses this augmented prompt to create an informed and contextually accurate response.
- Evaluation: A critical step in any pipeline is checking how effective it is relative to other strategies, or when you make changes. Evaluation provides objective measures on accuracy, faithfulness, and speed of responses.
By following these steps, RAG systems can provide answers that are not just accurate but also reflect the most current and relevant information available. This process is adaptable to both online and offline modes, each with its unique applications and advantages.

Retrieval Augmented Generation in Action: Example Application
To explore how RAG is applied, consider a scenario where a chatbot uses RAG to query a private knowledge base.
Scenario: AI Chatbot in Customer Service
Imagine a customer service chatbot for a large electronics company that’s equipped with a RAG system to handle customer queries more effectively.
It handles:
- Customer Query Processing: When a customer asks a question, such as “What are the latest updates to your smartwatch series?”, the chatbot processes this input to understand the query’s context.
- Retrieval from Knowledge Base: The retrieval engine then searches the company’s up-to-date product database for information relevant to the latest smartwatch updates.
- Augmenting the Query: The chatbot combines the retrieved information about smartwatch updates with the original query to enhance its response.
- Generating an Informed Response: The chatbot uses RAG to generate responses, combining internal knowledge with the latest retrieved information like features and pricing.
This scenario showcases how RAG can enhance the effectiveness of AI in customer service, providing responses that are both accurate and current. The integration of RAG allows the chatbot to offer information that might not be part of its initial programming, ideally making it more responsive to the user’s needs.
Why is the Development of LLM RAG Significant to the Industry?
By seamlessly integrating search and retrieval capabilities with generative AI, LLM RAG systems offer a level of responsiveness and accuracy that is unparalleled in traditional language models.
The significance of RAG lies in its ability to enhance AI responses with real-time, externally sourced data, making AI interactions more relevant and informed. This has vast implications across various sectors, from improving customer service chatbots to aiding in complex research and data analysis tasks.
Now, if you wanted to make your roadmap repeatable for everyone else who would want to take the same route you just took, wouldn’t you? This is where LLM observability comes into play.
How Should LLM RAG Systems Best Evaluated?
RAG evaluation leverages retrieval metrics and response metrics to vet whether answers are accurate, relevant, toxic, timely — or something else. See our companion piece for more details.
Evaluate LLM RAG
Using Arize-Phoenix, an open source solution for AI observability and large language model evaluation, we can map each step you took to create your RAG application system – try it out for yourself!