This piece is co-authored by Evan Jolley
Prompt engineering is a facet of development with LLMs that has garnered massive amounts of hype throughout the industry. Social media is flooded with AI influencers claiming to have created the best prompts for x or y tasks, new guides pop up every day on how to effectively guide LLM output, and in July, Netflix listed a Prompt Engineer position with a staggering salary of $900,000 per year. Despite all of the buzz, prompt engineering is a relatively straightforward but incredibly important concept in harnessing the power of large language models.

At its core, prompt engineering about crafting textual cues that effectively guide AI responses. These prompts, ranging from straightforward templates to complex structures, are instrumental in steering the vast knowledge of LLMs. This article delves into the nuances of prompt engineering, the iterative processes essential for refining prompts, and the challenges that come with them. Understanding prompt engineering is crucial for anyone looking to access the full potential of LLMs in practical applications.
Prompt Engineering: Core Concepts
Prompts serve as textual cues or guides that direct the behavior of LLMs. These cues instruct the AI on how to interpret a query and guide it toward delivering a desired response. Given their fundamental role, understanding the composition and nuances of prompts is essential for effective AI interaction.
A well-crafted prompt can contain several elements, each playing a distinct role:
- Instruction: This provides a specific task or directive for the model to execute. For instance, “Translate the following text into French:” is an instruction.
- Output Indicator: This signifies the desired format or type of the output. For instance, if you’re seeking a list, you might include “in a bulleted list” as an output indicator.
- Context: This offers additional information or background that can lead the model to more relevant and accurate outputs. For example, when asking the model to describe a historical event, providing the desired focus, further details, or an existing source can give context.
It’s worth noting that not all prompts need to contain all these elements. Their inclusion and arrangement depend on the specific task and the level of precision required. Let’s look at some examples to better understand how these components shape LLM output.
Instruction Prompt

Above you can see ChatGPT’s output when prompted with, “Briefly explain the theory of relativity.” It’s impressive that the LLM can summarize such a groundbreaking topic in just 330 words, but what if we need something a bit more concise?
Instruction and Output Indicator Prompt

By adding just four words to our prompt, we have completely changed the LLM’s output. We can take this example a step further by adding a bit of context.
Instruction, Output Indicator and Context Prompt

At the end of the day, prompt engineering is about finding the most effective way to tell an LLM what you want. Making prompts as detailed and direct as possible is almost guaranteed to result in responses more beneficial to the user.
Zero Shot Versus Few Shot Prompting
Zero-shot prompting involves giving a language model a task without any prior examples. In this approach, the model relies solely on its pre-existing knowledge and training.
Zero-Shot Prompt
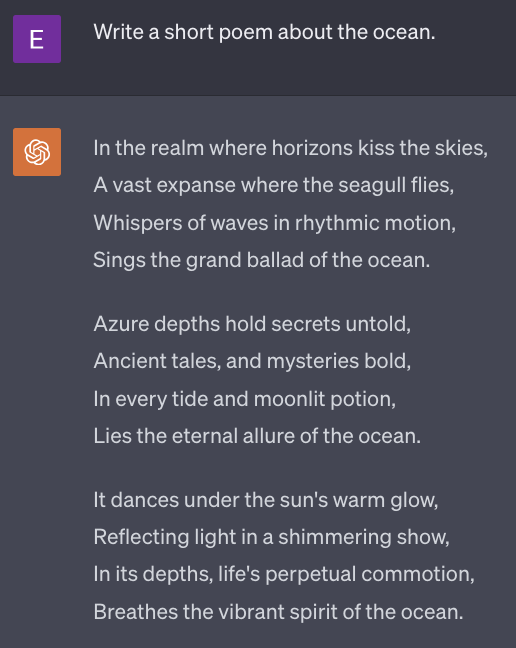
In the zero-shot example, the model is prompted to “Write a short poem about the ocean,” without any additional context or examples. The response generated is purely based on the model’s training and inherent understanding of poetry and the ocean. The result might vary in style and form, as the model has no specific guidance on what type of poem is expected.
In contrast, few-shot prompting involves introducing the model to a handful of examples that orient its response. This method can effectively replace specific instructions about context or output style, allowing the model to infer the desired output based on the examples provided.
Few-Shot Prompt
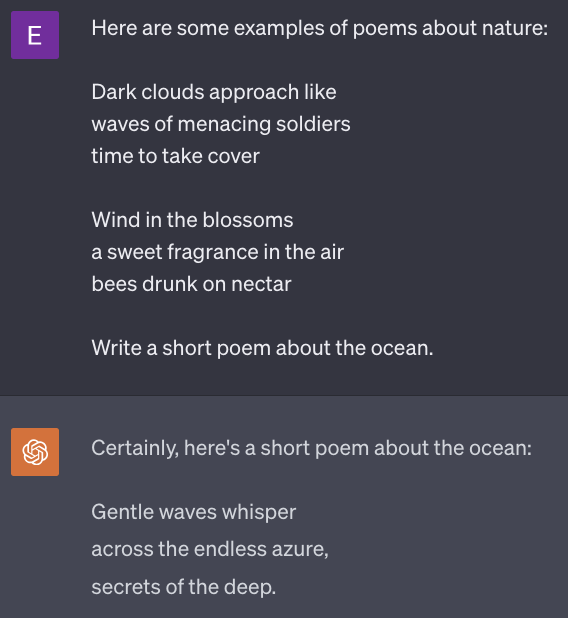
In the few-shot example, the instruction remains the same: “Write a short poem about the ocean.” However, the included examples completely changed the output. Not once did the few-shot prompt explicitly direct the model to output a haiku or to match the tone of the poems provided; the LLM can infer the desired style and format from the provided examples.
Templating
Templating is a foundational aspect of prompt engineering. It involves creating predefined structures or formats that can be populated with specific data to craft prompts. The sophistication of these templates can vary based on requirements and the intricacy of the task at hand.
Single Templating
Simple templates are straightforward, often containing placeholders for data without much additional logic. They are quick to implement and serve well for routine tasks. An example might be: “Find a recipe for {dish_name} that doesn’t include {allergen} and is suitable for {dietary_preference}.”
Complex Templating
Prompt engineering often demands dynamic and adaptable approaches. Especially in scenarios involving a high degree of repetition, coding prompts can vastly improve efficiency and consistency. Tools like Jinja2, an advanced templating engine, become instrumental in these cases.
Key features of Jinja2 include:
- Template Inheritance and Inclusion: This allows for modular design, where templates can inherit properties and structures from one another.
- Macros: Define and import reusable pieces of logic within templates, enhancing efficiency and consistency.
- Autoescaping: HTML templates in Jinja can use autoescaping to protect against cross-site scripting (XSS) vulnerabilities from untrusted inputs.
- Debugging Support: In the event of exceptions or errors, Jinja points directly to the corresponding line in the template, simplifying the debugging process.
Jinja and other advanced tools allow for templating that matches the demands of complex LLM systems.
Let’s construct a few prompts using Jinja2 to illustrate some basic functionality.
Jinja2 Example
First, we define a Jinja2 template as a string. This template includes placeholders for various elements of the prompt, such as the topic and specific content. Placeholders are enclosed in double curly braces {{ }}.
template_str = """
Prompt for the topic "{{ topic }}":
-----------------------------------
{{ content }}
{{ additional_instructions | default('') }}
"""In this template:
- {{ topic }} is a placeholder for the topic name.
- {{ content }} is where the main content of the prompt will be inserted.
- {{ additional_instructions | default(”) }} allows for optional additional instructions. If additional_instructions is not provided, it defaults to an empty string.
We then create a Jinja2 template object from this string.
from jinja2 import Template
template = Template(template_str)We then define a dictionary (‘topics’) where each key is a topic name and the value is another dictionary containing the specific content and additional instructions for that topic.
topics = {
"technology": {
"content": "Discuss the latest trends in artificial intelligence and their impact on society.",
"additional_instructions": "Focus on ethical implications and potential future developments."
},
...
}We use a dictionary comprehension to generate prompts for each topic. The template.render() method is called with the topic and its details, filling in the placeholders in the template.
generated_prompts = {topic: template.render(topic=topic, **details) for topic, details in topics.items()}Finally, we can display the generated prompt for a specific topic, such as “technology”:
generated_prompts["technology"]And the output will be:
| Prompt for the topic “technology”: ———————————– Discuss the latest trends in artificial intelligence and their impact on society.Focus on ethical implications and potential future developments. |
While this example is trivial, it sheds light on how powerful introducing Python syntax to prompt engineering can be. Prompt engineering in LLM systems must be dynamic and malleable in order to keep up with the systems’ complex needs, and when there is a lot of repetition present in prompting, construction of prompts through code can be helpful.
The Process of Prompt Engineering
Now that we have an understanding of what prompts are and their significance in driving LLM interactions, we’ll now dive into the process of crafting them. Effective prompts establish the context and act as a guide for an LLM to produce a desirable output. In this section, we’ll walk through the process of prompt engineering from initial construction to iterative refinement.
How To Construct Effective Prompts
Effective prompt construction sets the stage for the model’s understanding and dictates the quality of the response. Here are some key aspects:
- Understand User Needs: Determine the primary purpose of the LLM for your application. For instance, prompts for an educational LLM chatbot should ensure accurate and appropriate responses, whereas customer service prompts might need to account for edge cases and nuances related to the services being offered.
- Consider Private Data: Mechanisms have been introduced to provide insights into the private or contextual data that influences LLM outputs. PPI can be infused into prompts to make them more relevant and personalized, however, understanding and managing this private data responsibly is extremely important.
- Iterate, Iterate, Iterate: Create initial prompts keeping the user’s needs and the desired output in mind. Then, iterate on these prompts through rigorous testing and user feedback.
Common Tools In Prompt Engineering
Specialized tools have been created to alleviate some of the major pain points in prompt engineering. These tools are designed to streamline the process of creating, managing, and optimizing prompts. Two examples that are quickly emerging as industry standards and prompt registries and playgrounds.
What Is a Prompt Registry?
Prompt registries are centralized repositories for storing, managing, and versioning various prompts used in interactions with language models. They function similarly to how MLFlow tracks different versions of machine learning models. This approach is particularly useful for tracking the changes in prompts over time, understanding their effectiveness, and managing a large collection of prompts in a more organized and accessible manner. It’s a far cry from the chaos of ‘final_prompt_v3_reallyFinal_thisTime.json’, saving prompt engineers from the all-too-familiar and incredibly irritating file labeling challenge faced by professionals across many fields.
In practice, a prompt registry enables better collaboration among teams working on language model applications. It allows for the sharing, editing, and refinement of prompts, making sure that everyone has access to the most up-to-date and effective versions. This is important for maintaining consistency, especially in complex systems with many prompts to keep track of.
What Is a Prompt Playground?
Prompt playgrounds are specialized environments designed for the purpose of of iterative testing and refinement and are crucial in developing effective prompts for large systems utilizing language models. Arize’s Prompt Playground provides an interactive interface where engineers can view prompt/response pairs, experiment with editing existing templates, and deploying new templates, all in real time. Some features and benefits of prompt playgrounds include:
- Prompt Analysis: Quickly uncover poorly performing prompt templates using evaluation metrics.
- Iteration in Real Time: Modify existing templates to enhance coverage for various edge cases.
- Comparison Before Deployment: Before implementing a prompt template in a live environment, teams can compare its responses with other templates within the playground.
Prompt playgrounds’ true value shines in the production stage of an LLM system. In pre-production, prompt playgrounds might be less valuable, as prompt analysis and iteration can be achieved in a notebook or development setting somewhat simply. After deployment, however, the complexity and scale of live environments introduce myriad moving parts, making prompt evaluation considerably more challenging.
Arize’s Prompt Playground can be run easily on your own device. Check out this notebook for the code required to set it up and this documentation for a quick run through of how it works. The playground can also be accessed through specific Arize Spaces.
Let’s look at an example of the playground in use; we’ll access it through a sample Arize space. Once inside your Arize Space, you can select a model to access its performance analytics dashboard.

Once on the dashboard, selected View Performance Tracking will allow us a more granular view into prompt response pairs and their performance.
Selecting Prompt Playground or a specific row of the dataset will take us to Arize’s iterative prompt environment.
Finally, we find ourselves in Arize’s Prompt Playground!
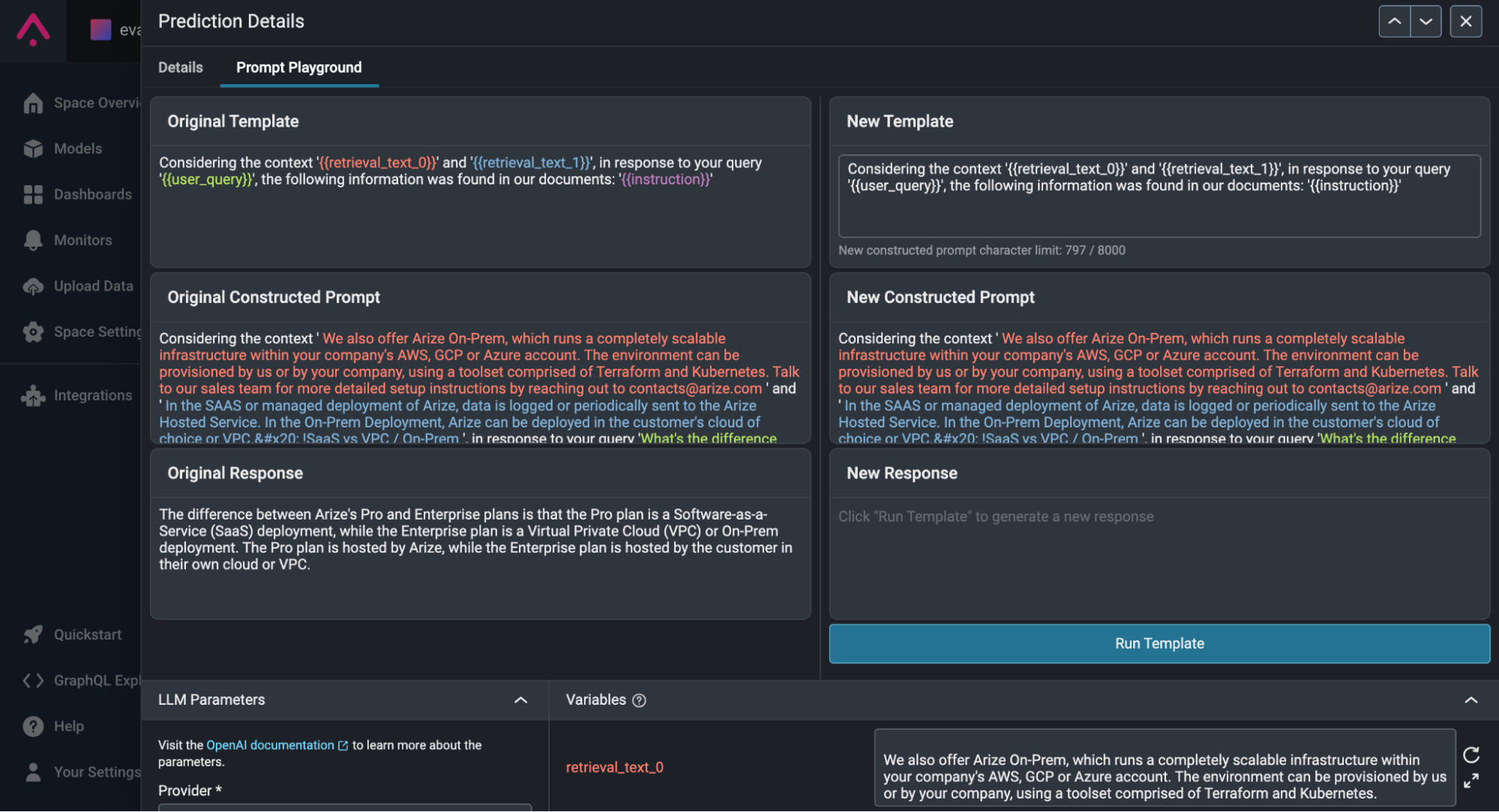
This example prompt is made up of four parts: two pieces of retrieved context, the user’s query, and an instruction for the LLM:

As you can see, the original response to this query was, “The difference between Arize’s Pro and Enterprise plans is that the Pro plan is a Software-as-a-Service (SaaS) deployment, while the Enterprise plan is a Virtual Private Cloud (VPC) or On-Prem deployment. The Pro plan is hosted by Arize, while the Enterprise plan is hosted by the customer in their own cloud or VPC.”
This response is factually incorrect – Arize Enterprise can be on SaaS! This is a clear example of a model hallucination, as the provided context never confirms or denies if Arize’s Enterprise Plan can be on SaaS.
Let’s see if we can engineer a prompt that leads to a better response. Let’s modify the instruction to say “If the information to answer the question is not found in the context, respond with ‘I don’t know.’”
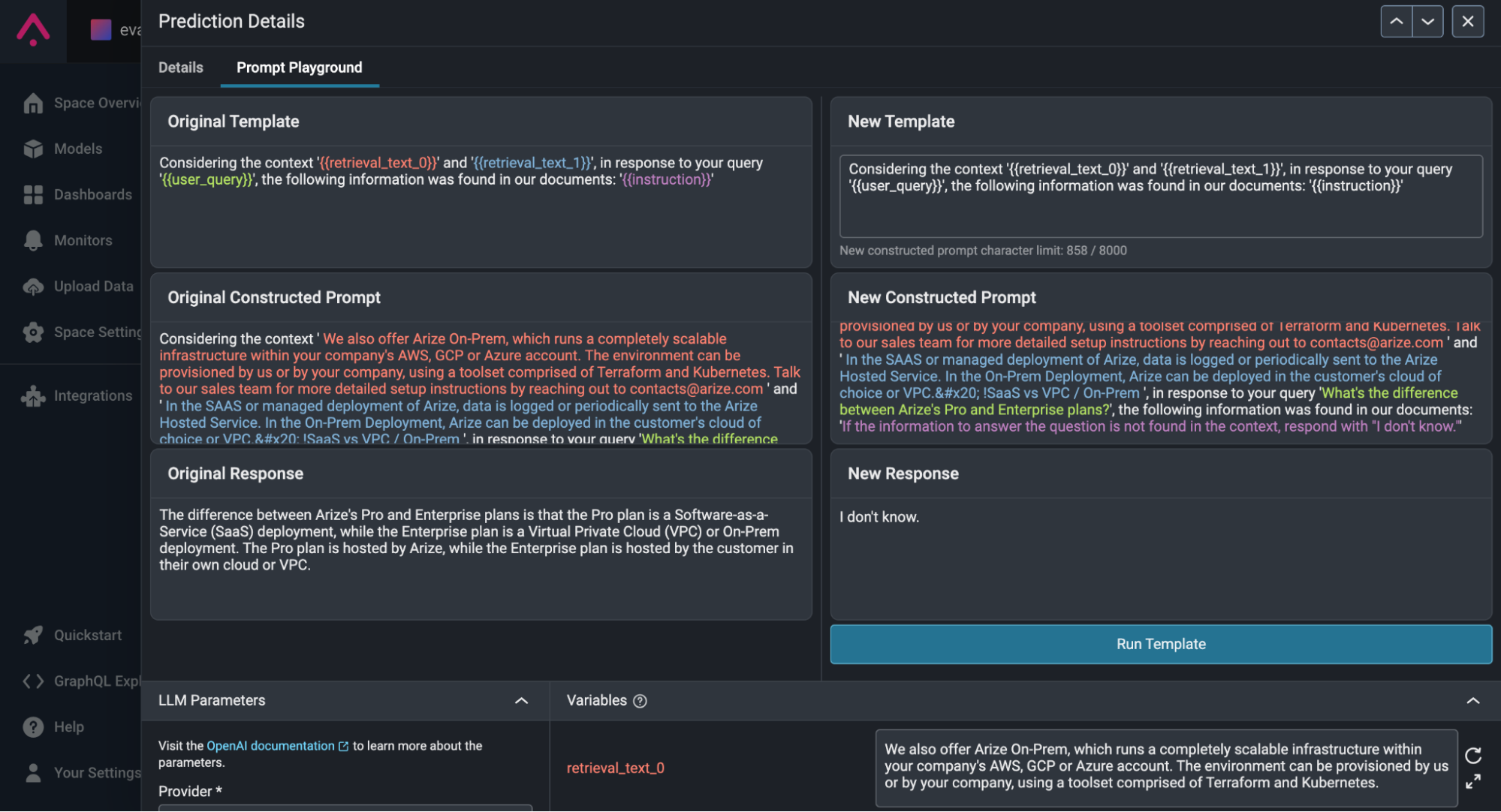
As you can see, our new prompt leads to the response “I don’t know,” preventing our application from providing inaccurate information to users. Without Arize’s Prompt Playground, identifying this prompt, analyzing its shortcomings, engineering a solution, and testing the new prompt’s effectiveness would have been a convoluted endeavor with many variables to keep track of. With it, anyone can succeed in prompt engineering.
Evaluation of Prompts
Let’s set up an example that showcases how simple differences in prompt templates can lead to large differences. Here is a notebook where you can run this experiment yourself.
First, we will import all necessary dependencies:
import csv
import os
from phoenix.experimental.evals import (
OpenAIModel
)For our context we will use the introduction of this Google DeepMind article published recently about the discovery of 2.2 million new materials through deep learning. Additionally, we have a set of questions that can be answered using the context and a set of ground truth answers for comparison with model responses. For example, the question “Does this context mention a subsidiary of a Fortune 500 company?” has a ground truth answer of, “Yes, Google DeepMind is mentioned.”
Let’s bring in this data:
# Pull in context data
context = ""
with open("google_deepmind.txt", "r") as file:
context = file.read()
# Pull in response pair data
response_pairs = []
with open("response_pairs.csv", "r") as file:
response_pairs = list(csv.reader(file, delimiter=","))
questions = [row[0] for row in response_pairs]
answers = [row[1] for row in response_pairs]Now we can define our two prompt templates. Template #1 is more structured and provided clear instruction for the model, while template #2 is simply the context followed by the question. Remember, the exact same context and questions will be inputted in these templates.
| template1 = “Context: {context} Question: {question} Answer the question concisely based on information provided in the context. The answer should completely and accurately address the question asked using relevant context. Answer:”template2 = “{context} {question}” |
Additionally, we can define a single evaluation prompt template to assist in evaluating model responses. The responses to templated queries will be compared to the ground truth answers provided in the dataset, given a binary indicator whether or not they are correct, and averaged to calculate the template’s final score.
| evaluation_template = “You are given a correct answer and a sampled answer. You must determine whether the sampled answer is correct based on the correct answer. Here is the data:\n[BEGIN DATA]\n\n[question]: {questions}\n\n[correct answer]: {correct_answer}\n\n[sampled_answer]: {sampled_answer}\n[END DATA]\n\nYour response must be a single number, either 1 or 0, and should not contain any text or characters aside from that word. 1 means that the sampled answer answers the question as well as the given correct answer. 0 means it does not.” |
Let’s conduct our experiment. The questions and context will be inputted into each prompt template and used to query the model using this function:
def prompt(prompt_template):
sampled_answers = []
for question in questions:
filled_prompt_template = prompt_template.format(context=context, question=question)
response_text = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": filled_prompt_template},
]
).json()
response_obj = json.loads(response_text)
content = response_obj["choices"]
[0]
["message"]
["content"]
sampled_answers.append(content)
return sampled_answersFinally, the returned answers will be evaluated using this function:
def eval(sampled_answers):
total = 0
for i, sampled_answer in enumerate(sampled_answers):
filled_evaluation_template = evaluation_template.format(question=questions[i], correct_answer=answers[i], sampled_answer=sampled_answer)
response_text = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": filled_evaluation_template},
]
).json()
response_obj = json.loads(response_text)
content = response_obj["choices"]
[0]
["message"]
["content"]
total += int(content)
score = total/len(sampled_answers)
return scoreIn the 10 trials and over 800 total model queries we ran, template #1 scored just over 0.92 (meaning the system answered the query correctly 92% of the time) and template #2 scored 0.85. Feel free to experiment with the notebook yourself, changing context and tinkering with templates to further understand their nuance. Differences in prompts, regardless of how subtle they may be, have concrete impact on the performance of LLM systems. Rigorously testing templates and evaluating their outcomes is a necessary step in developing with effective conversational AI.
For more on this topic, check out our comprehensive guide to LLM evaluations.
Conclusion
Prompt engineering is an important aspect of maximizing the capabilities of large language models. By understanding this process, developers can significantly improve the accuracy and relevance of LLM responses. Made more accessible through tools like prompt registries and playgrounds, the iterative process of prompt refinement is important for fine-tuning these prompts to meet specific user needs and contexts. As with everything in LLMOps, it’s an evolving discipline but one that rewards those that invest the time!