
How foundation models are offering exciting new possibilities for businesses across industries
What Are Foundation Models?
Foundation models are large-scale machine learning models pre-trained on extensive datasets. These models are trained to learn general-purpose representations across various data modalities, including text, images, audio, and video. Their key strengths lie in their size, pre-training, self-supervised learning, generalization, and adaptability.

Take GPT-4, for instance, a giant in the field with a staggering 170 trillion parameters, trained on more than 5 trillion words. Such large models are pre-trained on massive datasets, a process that requires enormous computational resources. However, their self-supervised nature means they don’t need explicit labels to learn – they uncover patterns in the provided data themselves.
The generalization ability of foundation models is another of their key traits. They’re not designed for one specific task but are built to understand and interact with data in a human-like manner. Lastly, they’re adaptable. Through methods like fine-tuning or prompt engineering, these models can be customized to perform a wide variety of tasks, demonstrating their versatility and efficiency in numerous applications. Due to their versatility and efficiency, foundation models have shown great promise in a wide range of applications, enabling cross-modal learning and interactions.
Why Are Foundation Models Growing In Popularity?
The emergence of foundation models might appear sudden, but in reality, they are the outcome of an intricate evolution in the field of AI. Tracing their lineage back to the diverse techniques, models, and groundbreaking developments in machine learning, these models represent the pinnacle of AI achievements to date. From the early days of hand-crafted features to the era of BERT and GPT, foundation models have come a long way. They have reshaped the AI landscape and are continually sculpting the future of machine learning.
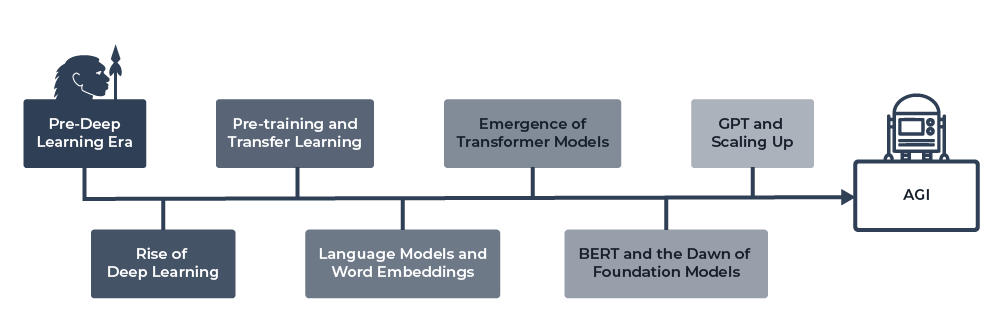
Here is a brief summation of historical milestones.
Pre-Deep Learning Era
Before the rise of deep learning, machine learning models were primarily focused on hand-crafted features and shallow architectures. These models, such as support vector machines (SVMs) and decision trees, required domain-specific expertise to design and engineer features for each task. While these models laid the groundwork for machine learning, they lacked the scalability and adaptability needed for more complex tasks.
The Rise of Deep Learning
The introduction of deep learning in the late 2000s revolutionized the field of AI. Deep learning models, primarily deep neural networks, were able to learn features and representations from raw data, eliminating the need for manual feature engineering. This marked a significant shift in the machine learning landscape, paving the way for more complex and powerful models.
Pre-training and Transfer Learning
The concept of pre-training and transfer learning emerged as a key technique in deep learning. Researchers found that models pre-trained on large datasets could be fine-tuned on smaller, task-specific datasets with better performance than training from scratch. This idea of using pre-trained models as a starting point for new tasks laid the foundation for foundation models.
Language Models and Word Embeddings
In the domain of natural language processing (NLP), the development of word embeddings, such as Word2Vec and GloVe, marked a significant milestone. These models were pre-trained on large text corpora and could generate dense vector representations of words that captured semantic and syntactic information. This marked the beginning of pre-trained models for NLP tasks.
The Emergence of Transformer Models:
In 2017, the introduction of the Transformer architecture marked a turning point in the development of foundation models. The Transformer was designed to handle long-range dependencies in sequences, making it particularly suited for NLP tasks. This architecture laid the groundwork for models such as BERT, GPT, and RoBERTa.
BERT and the Dawn of Foundation Models
Google’s BERT (Bidirectional Encoder Representations from Transformers), introduced in 2018, was a major milestone in foundation models’ history. BERT was pre-trained on large-scale text corpora using a masked language modeling task and could be fine-tuned for various NLP tasks with impressive results. This marked the beginning of the widespread adoption of foundation models in NLP.
GPT and Scaling Up
OpenAI’s GPT (Generative Pre-trained Transformer) series, particularly GPT-3, further popularized the concept of foundation models. By scaling up the model size and training data, GPT-3 demonstrated remarkable capabilities in natural language understanding and generation. The success of GPT-3 underscored the potential of foundation models across a wide range of applications and industries. OpenAI has since iterated on GPT-3 and with the release of GPT-4 foundation models are growing in popularity.
What Are the Most Popular Models?

Breaking Down Significance and Impact
Foundation models have revolutionized the landscape of artificial intelligence and machine learning, largely attributed to their adaptability and accessibility. These models excel across diverse tasks and domains, thanks to their pre-trained knowledge that can be fine-tuned to perform high-level specific tasks like sentiment analysis, language translation, image captioning, or object detection.
Foundation models have exhibited significant performance enhancements in comparison to their predecessors. Their ability to utilize vast data during pre-training enables them to discern intricate patterns and relationships, resulting in more precise predictions and superior generalization capabilities. This heightened performance empowers businesses to obtain more dependable and accurate results, thereby enhancing decision-making and overall efficiency.
By breaking down the barriers to AI, foundation models are making it accessible to a wider audience. The presence of pre-trained models and easy-to-use tools means that even small organizations or those lacking extensive machine learning knowledge can harness the power of AI to meet their unique needs. This broadened access to AI fosters innovation and the creation of new applications across a variety of industries.
One key advantage of foundation models is their facilitation of transfer learning — the capability of a model trained on one task to be fine-tuned and applied to a different, related task. This is especially beneficial for tasks with limited labeled data, as the pre-trained knowledge of foundation models can be used to achieve superior performance with less data. Consequently, foundation models can mitigate data scarcity challenges, which often obstruct AI adoption in niche domains.
What are the Major Implementation Hurdles?
Despite the vast potential of foundation models, their adoption is not without challenges. Here are some of the adoption barriers that we hear frequently from businesses and organizations:
- Data Privacy and Security: Foundation models are trained on vast amounts of data, some of which may contain sensitive or proprietary information. Ensuring that this data is handled securely and that privacy is maintained is a significant challenge. Additionally, the outputs of these models could inadvertently reveal sensitive information that was present in the training data.
- Model Bias and Fairness: Foundation models can inherit biases present in their training data, leading to unfair or discriminatory outcomes. Addressing these biases is a complex problem that requires careful consideration and robust methods for bias detection and mitigation.
- Regulatory Compliance: Depending on the industry and the specific application, businesses may face regulatory challenges related to the use of foundation models. This could include issues related to data privacy, algorithmic fairness, or liability for AI-driven decisions.
- Model Robustness and Reliability: While foundation models demonstrate impressive performance, their ability to adapt effectively to new data or specific use cases may not always be guaranteed. The challenge lies not only in ensuring consistent performance across diverse contexts but also in equipping these models to handle anomalous or adversarial inputs — a task that is far from straightforward.
- Environmental Impact: Training large-scale foundation models is energy-intensive and can contribute to carbon emissions. Organizations adopting these models must consider their environmental impact and explore strategies for more sustainable AI.
What Are the Tradeoffs Between Open-Source vs Proprietary Foundational Models?
The ongoing debate surrounding the open sourcing of foundation models is indeed complex, straddling the realms of ethics, security, and technological advancement. While some argue for keeping these models proprietary to prevent misuse, others advocate for an open approach to ensure broader accessibility and democratic control.
On one hand, there are valid concerns that open sourcing foundation models could enable malicious actors to misuse this powerful technology. They could use it to create deepfakes, spread misinformation, or carry out other harmful activities. Furthermore, proprietary models can be more effectively controlled, monitored, and updated, allowing for swift action to rectify any issues that arise. This approach also protects the significant investment required to develop these models and could incentivize further advancements in the field.
However, the argument for keeping foundation models closed raises its own set of ethical dilemmas. A select few entities with substantial resources and capabilities might amass significant control over technology that is increasingly shaping our world. This could lead to a situation where the interests of these entities outweigh the broader public interest. It may also stifle innovation, as smaller organizations and researchers without access to these models could be left behind.
Open-sourcing foundation models, on the other hand, allows for a more democratic distribution of this technology. It encourages a diverse range of perspectives and inputs, fostering innovation and potentially leading to more robust, versatile, and effective models. Moreover, it can accelerate the democratization of AI, empowering even small organizations and those with limited resources to harness the power of foundation models.
Yet, it’s crucial to note that open sourcing does not mean an absence of control. Robust governance structures and usage guidelines should be implemented to monitor and control the use of these models. Additionally, open sourcing can lead to a broader community of researchers and developers identifying and addressing potential flaws or biases in the models, leading to more reliable and ethical AI systems.
The debate between open source and closed foundation models is multi-faceted, involving various stakeholders and interests. It may not be a matter of choosing one over the other but finding a balance that maximizes the benefits of AI for society while minimizing potential risks. Considerations might include hybrid models, where certain components are open-sourced while others remain proprietary, or tiered access models, where the level of access depends on the potential user’s intent and capabilities.
Envisioning the Future
Democratization of AI
Foundation models will continue to democratize access to AI technologies by lowering the barriers to entry. Pre-trained models, combined with user-friendly tools and platforms, will enable small businesses, researchers, and individual developers to harness the power of AI without requiring extensive resources or expertise. This will lead to increased innovation and the development of novel applications across various industries.
Cross-modal Learning
As foundation models continue to evolve, their ability to handle multiple modalities and perform cross-modal learning will become increasingly important. By learning joint representations from text, images, audio, video, and other data types, foundation models will enable more seamless and sophisticated interactions between humans and AI systems, as well as improve the capabilities of AI in understanding complex, real-world data.
Data Efficiency
Foundation models have the potential to make ML more data-efficient, especially when dealing with tasks that have limited labeled data. By leveraging pre-trained knowledge from foundation models, it is possible to achieve better performance with less data, addressing data scarcity challenges that often hinder AI adoption in niche domains or tasks with limited resources.
Accelerated AI Development
The use of foundation models will accelerate the development and deployment of AI solutions. By providing a strong starting point for specialized models, foundation models can reduce the time and computational resources required for training, allowing businesses and researchers to deploy AI systems more quickly and cost-effectively.
Model Compression and Adaptation
As foundation models continue to grow in size and complexity, research into model compression and adaptation techniques will become increasingly important. These techniques aim to make foundation models more efficient and accessible, enabling their use on edge devices and in resource-constrained environments. This will expand the reach of AI to new applications and industries, further enhancing its impact on society.
Responsible AI and Ethics
With the increasing adoption and influence of foundation models, the need for responsible AI and ethical considerations will become more critical. Researchers and practitioners will need to focus on addressing issues related to fairness, accountability, transparency, and privacy in the design and deployment of foundation models to ensure their benefits are equitably distributed and potential risks are mitigated.
Conclusion
Foundation models have become a cornerstone in the AI landscape, offering innovative capabilities across multiple domains. These large-scale, pre-trained models offer immense potential by learning representations across data types, including text, images, audio, and video. Exemplified by models like GPT-4, foundation models demonstrate impressive versatility and adaptability, and they have paved the way for a new age in AI.
Nevertheless, the incorporation of these robust models introduces complexities and challenges to the field, compounded by the ongoing discourse around the open source versus proprietary nature of their use. Peering into the future, foundation models are poised to reshape AI, opening its doors to a wider audience and hastening the evolution of AI. This potential must be harnessed responsibly and ethically, ensuring equitable and sustainable benefits to society.