



Co-authored by Aparna Dhinakaran
2024 has been dubbed as the year of Agents. The year where we move beyond simple RAG flows and enter into the promised land of autonomous AI systems that can take over writing our emails, booking flights, talking to our data, or whatever other task we give them.
Agents might have had a rocky start, but that hasn’t stopped the launch of multiple different frameworks to support their development.
If you’re building an agent today, you not only need to choose the model, use case, and architecture – you also need to choose which framework, if any, to develop it in. Will you go with the long-standing LangGraph, or the newer entrant LlamaIndex Workflows? Or use a collective agent orchestration tool like CrewAI? Or will you go the traditional route and code the whole thing yourself?
This post aims to make that choice a bit easier. Over the past few weeks, I’ve built the same agent in multiple different frameworks to show the strengths and weaknesses of each at a technical level. I came to this project with very few framework preferences, if any, and so aimed to make this as unbiased of a “review” as possible.
If you’ve been struggling to decide between which framework to use, if any at all, with your next agent, read on.
- All of the code for each agent is available on our Phoenix repo here
What kind of agent are we building?
Let’s start with a bit of background on our agent. In order to properly test each framework, the agent needed some basic capabilities. Specifically, it had to include function calling, multiple tools or skills, connections to outside resources, and shared state or memory. I also recognized that real world use cases often grow and expand over time, so the agent should be able to incorporate new skills relatively easily.
For this example, I decided to use a copilot agent built to interact with Phoenix, Arize’s open-source observability tool.
I gave the agent the following capabilities:
- Answering questions about Phoenix, based on Phoenix’s documentation
- “Talking to your data”. Phoenix captures telemetry data about an LLM application it’s attached to. Our agent should be able to answer questions about that data.
- Analyzing data. Our agent should be able to analyze higher level trends and patterns in retrieved telemetry data.
In order to accomplish these, the agent has three starting skills: RAG with phoenix documentation, SQL generation on a trace database, and data analysis.
I used a simple gradio-powered interface for the agent UI, and structured the agent itself as a chatbot.
After defining the basic requirements of the agent, I was ready to jump in!
Pure Code Agent
The first option you have when developing an agent is to skip the frameworks entirely, and build the agent fully yourself.
When embarking on this project, this was the approach I started with. I figured this approach would give me the best understanding of how the agent worked, and help me avoid basing the full agent off an existing tutorial that came along with a framework.
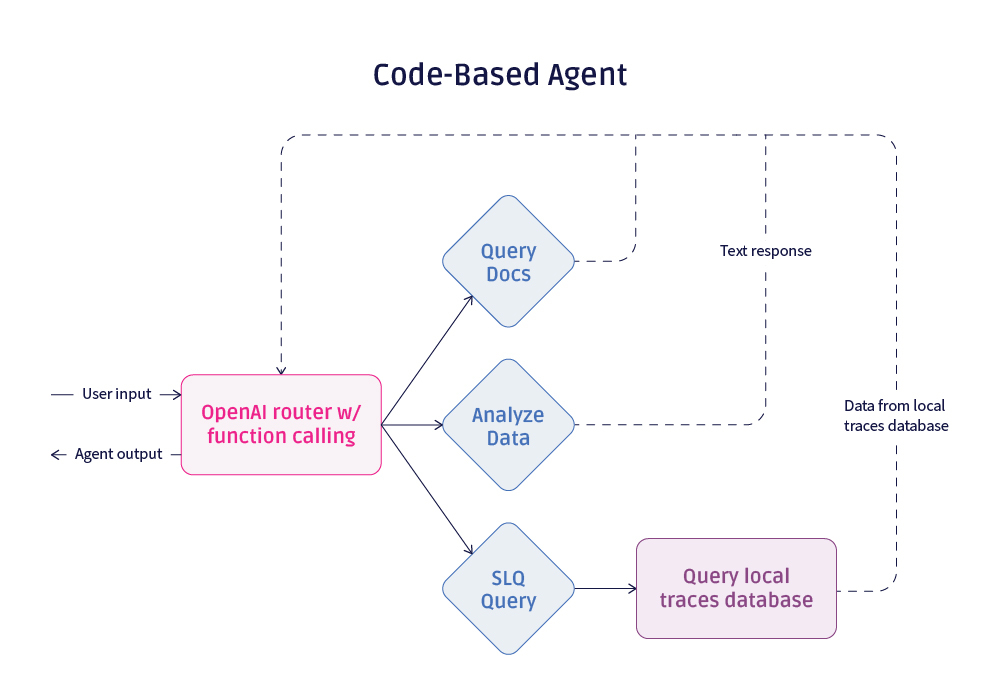
Pure Code Architecture
The code based agent is made up of an OpenAI-powered router that uses function calling to select the right skill to use. After that skill completes, it returns back to the router to either call another skill or respond to the user.
The agent keeps an ongoing list of messages and responses that is passed fully into the router on each call to preserve context through cycles.
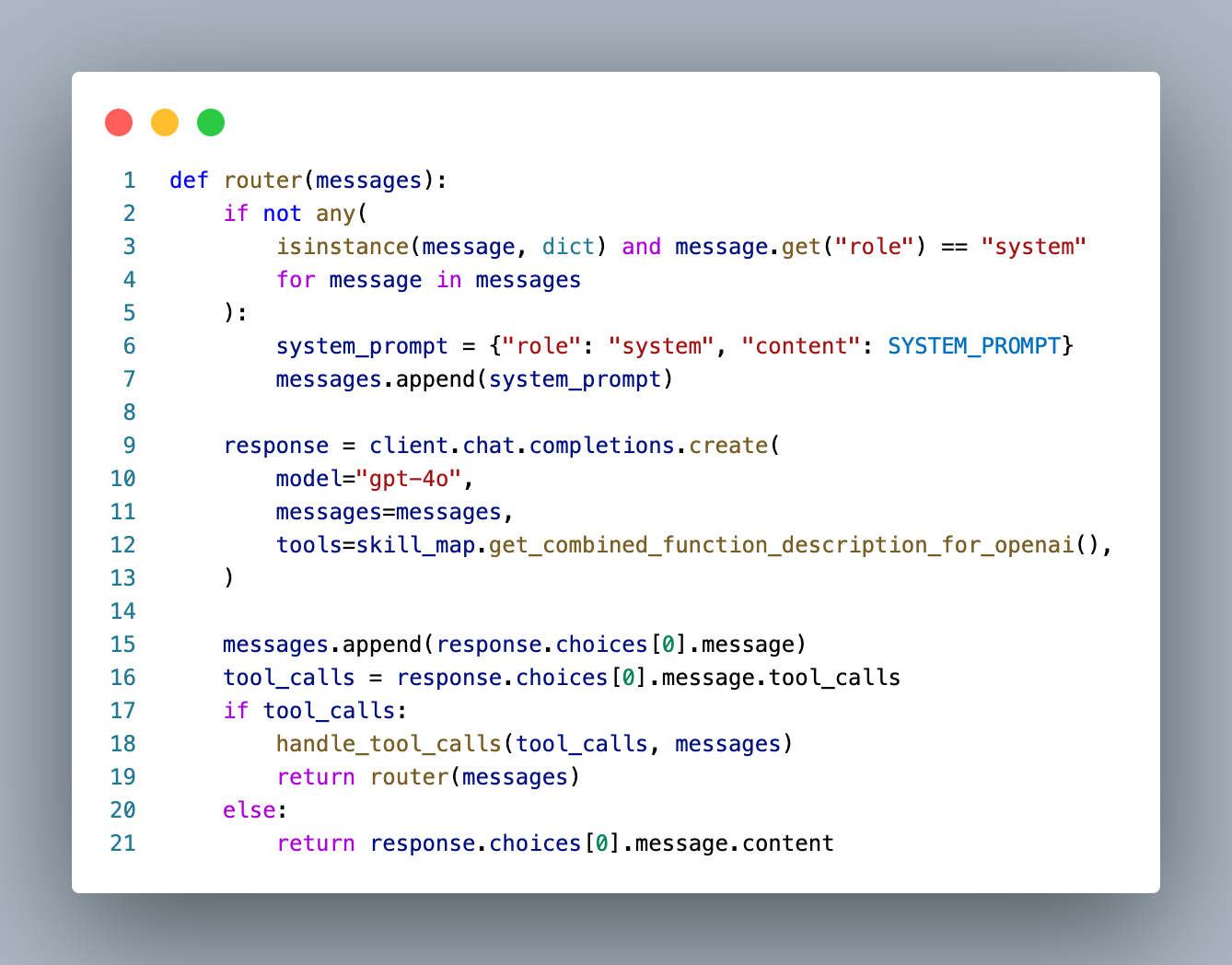
Code-based agent router
The skills themselves are defined in their own classes (e.g. GenerateSQLQuery) that are collectively held in a SkillMap. The router itself only interacts with the SkillMap, which it uses to load skill names, descriptions, and callable functions. This approach means that adding a new skill to the agent is as simple as writing that skill as its own class, then adding it to the list of skills in the SkillMap. The idea here is to make it easy to add new skills without disturbing the router code.
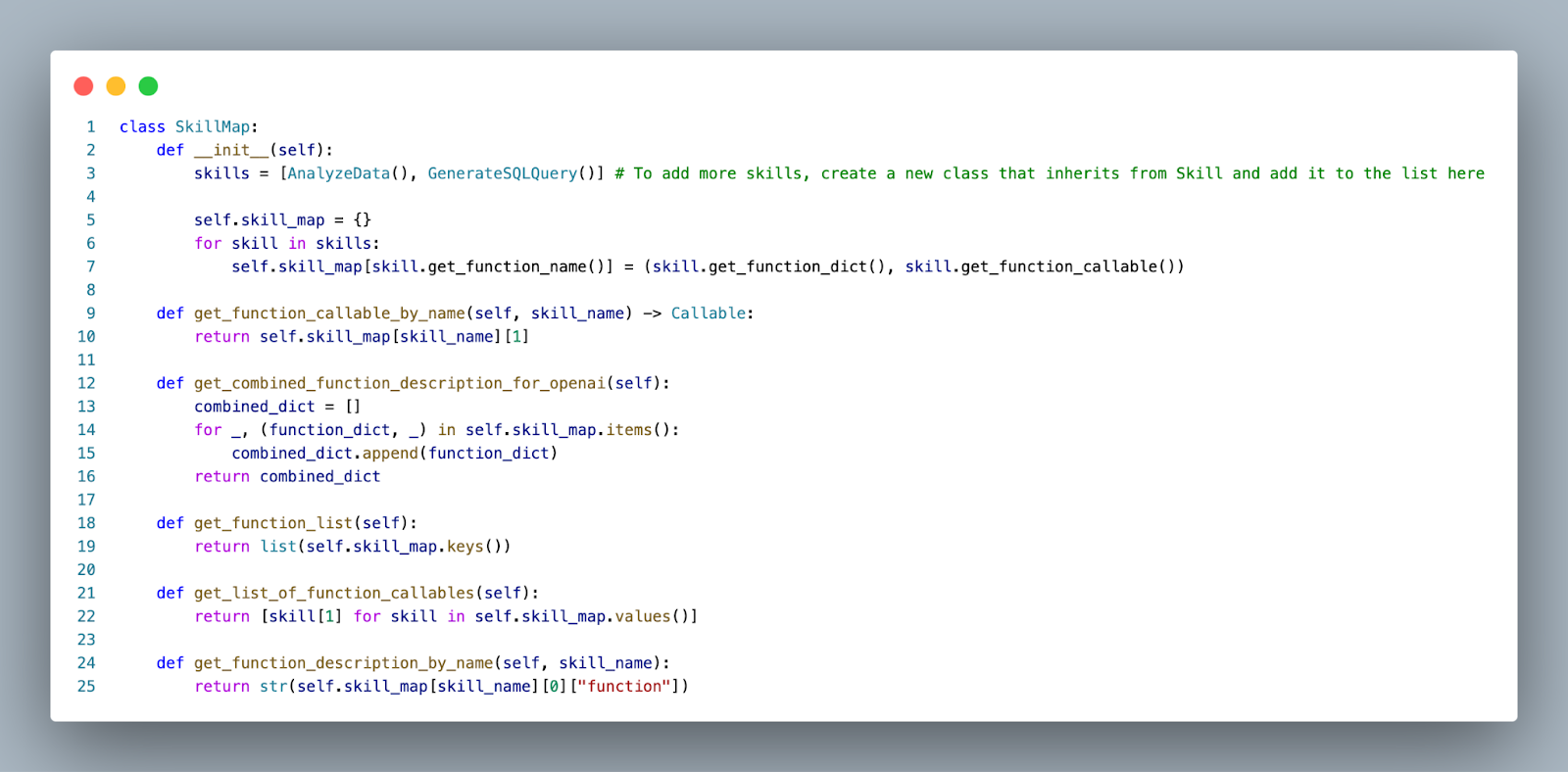
SkillMap defined with two skills
Overall, this approach was fairly straightforward to initially implement. After that easy setup however, I began to run into a few challenges:
Challenges with Pure Code
- Structuring the router system prompt was extremely difficult. My router kept insisting on generating SQL itself, instead of delegating that to the right skill. If you’ve ever tried to get an LLM not to do something, you’ll know how frustrating that experience can be. I eventually found a working prompt, but it took many rounds of debugging.
- Accounting for the different output formats from each step was also difficult. I opted not to use structured outputs, which meant I had to be ready for multiple different formats from each of the LLM calls in my router and skills.
Phoenix helped make this debugging process quite a lot easier – especially because I’d shared the agent with some coworkers to help me test. Phoenix let me inspect full run throughs of my agent and narrow down where my problems were arising from.
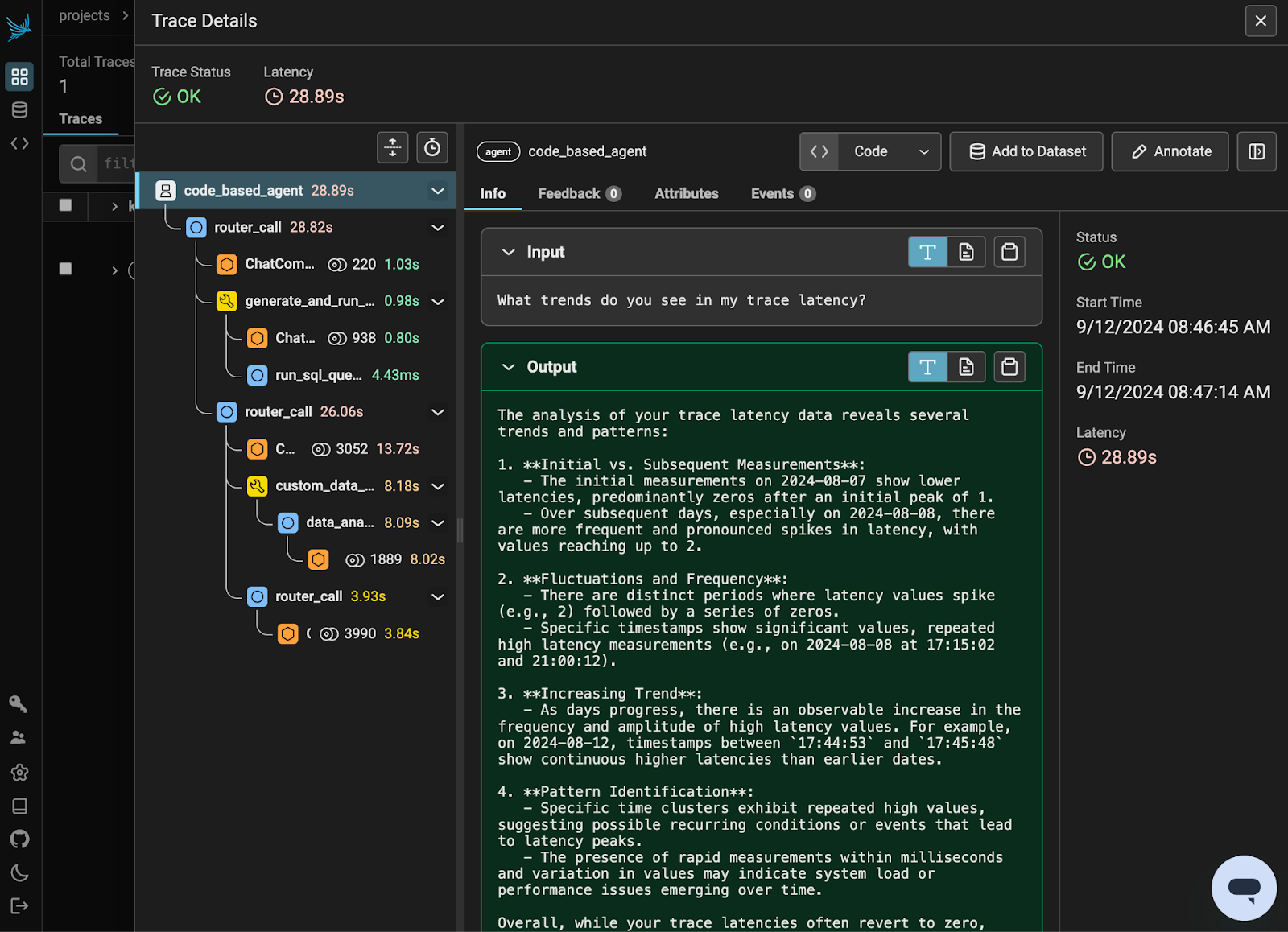
Overall
This code-based approach was a good baseline. The hardest part was convincing the LLM to behave, and the code structure was simple enough to use.
LangGraph
LangGraph is one of the longest standing agent frameworks, releasing in January 2024. The framework is built to address the acyclic nature of existing pipelines and chains by adopting a Pregel graph structure instead. LangGraph makes it easier to define loops in your agent by adding the concepts of nodes, edges, and conditional edges to traverse a graph. LangGraph is built on top of Langchain, and uses the objects and types from that framework.
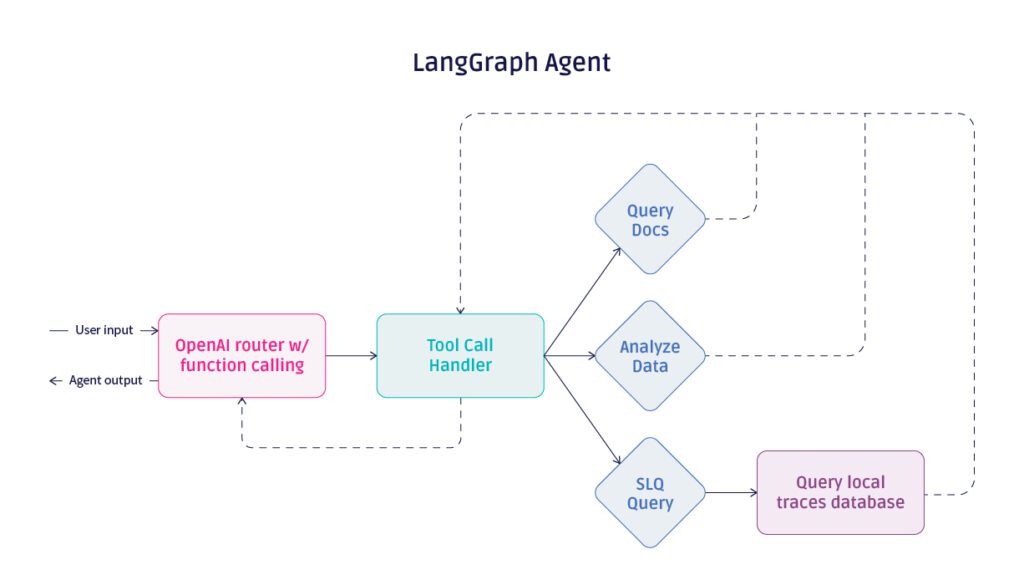
LangGraph Architecture
The LangGraph agent looks similar to the code-based agent on paper, but the code behind it is drastically different. LangGraph still uses a “router” technically, in that it calls OpenAI with functions and uses the response to continue to a new step. However the way the program moves between skills is controlled completely differently.
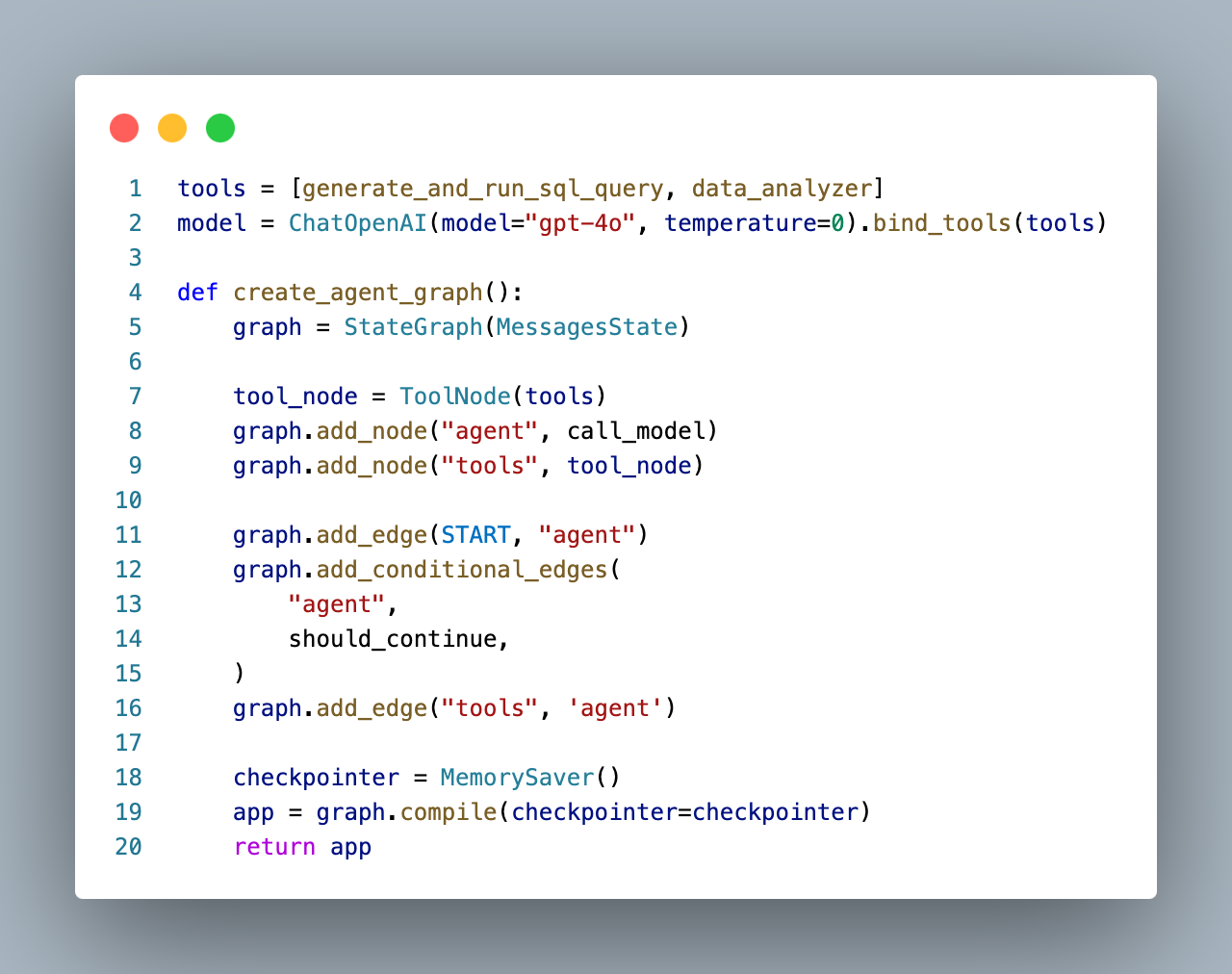
The graph defined here has a node for the initial OpenAI call, called “agent” above, and one for the tool handling step, called “tools”. LangGraph has a built-in object called ToolNode that takes a list of callable tools and triggers them based on a ChatMessage response, before returning to the “agent” node again.

After each call of the “agent” node (or what we referred to as the router in the code-based agent), the should_continue edge decides whether to return the response to the user or pass on to the ToolNode to handle tool calls.
Throughout each node, the “state” stores the list of messages and responses from OpenAI, similar to the code-based agent’s approach.
Challenges Encounterwith LangGraph
Most of the difficulties I ran into using LangGraph stemmed from the need to use Langchain objects for things to flow nicely.
Challenge #1: Function Call Validation
In order to use the ToolNode object, I had to refactor most of my existing Skill code. The ToolNode takes a list of callable functions, which originally made me think I could use my existing functions, however things broke down due to my function parameters.
My skills were defined as classes with a callable member function, meaning they had “self” as their first parameter. GPT 4o was smart enough to not include the “self” parameter in the generated function call, however LangGraph read this as a validation error due to a missing parameter.
This took me hours to figure out, because the error message instead marked the third parameter in my function (“args” on the data analysis skill) as the missing parameter:
pydantic.v1.error_wrappers.ValidationError: 1 validation error for data_analysis_toolSchema
args field required (type=value_error.missing)
It is worth mentioning that the error message originated from Pydantic, not from LangGraph.
I eventually bit the bullet and redefined my skills as basic methods with Langchain’s @tool decorator, and was able to get things working.
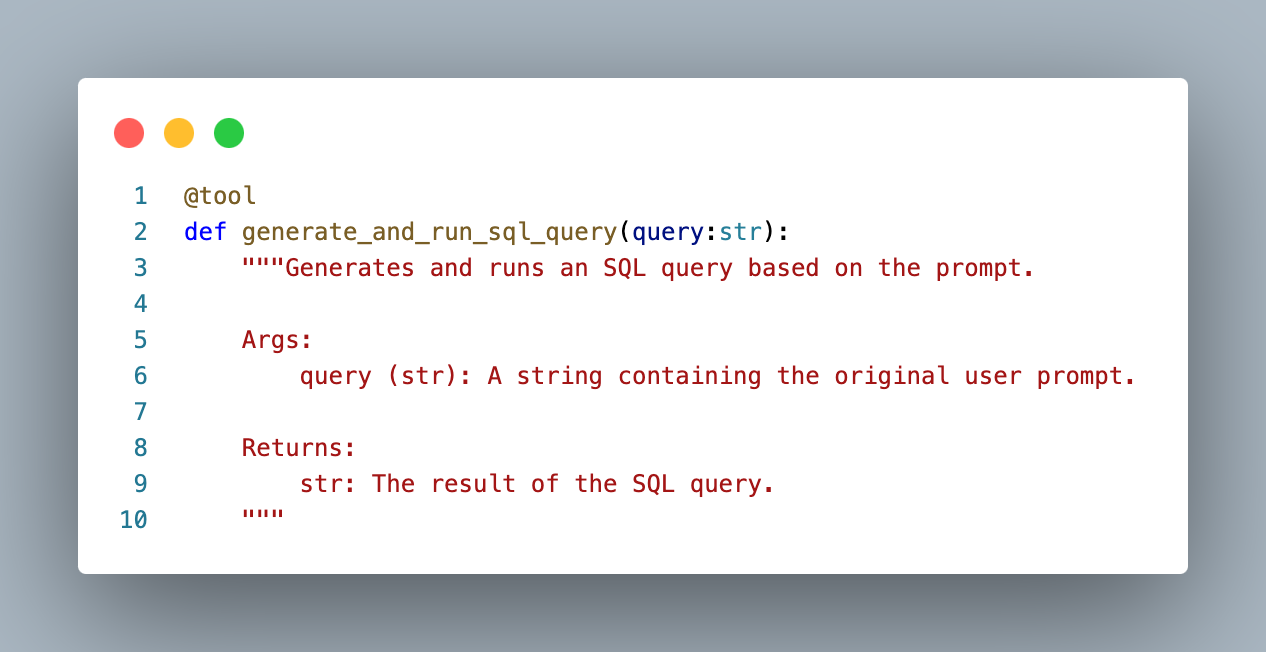
Definition of the generate SQL skill for LangGraph
Challenge #2: Debugging
This is mentioned in the last challenge, but it is worth highlighting fully here: debugging in a framework is difficult. This primarily comes down to two culprits:
- Confusing error messages
- Abstracted concepts that make it harder to view variables
We touched on the confusing error messages already. The abstracted concepts primarily showed up for me when trying to debug the messages being sent around the agent. LangGraph stores these messages in state[“messages”]. Some nodes within the graph pull from these messages automatically, which can make it difficult to understand the value of messages when they are accessed by the node.
Again, Phoenix made this a little easier to diagnose, since it gave me a nice sequential view of the agents actions:
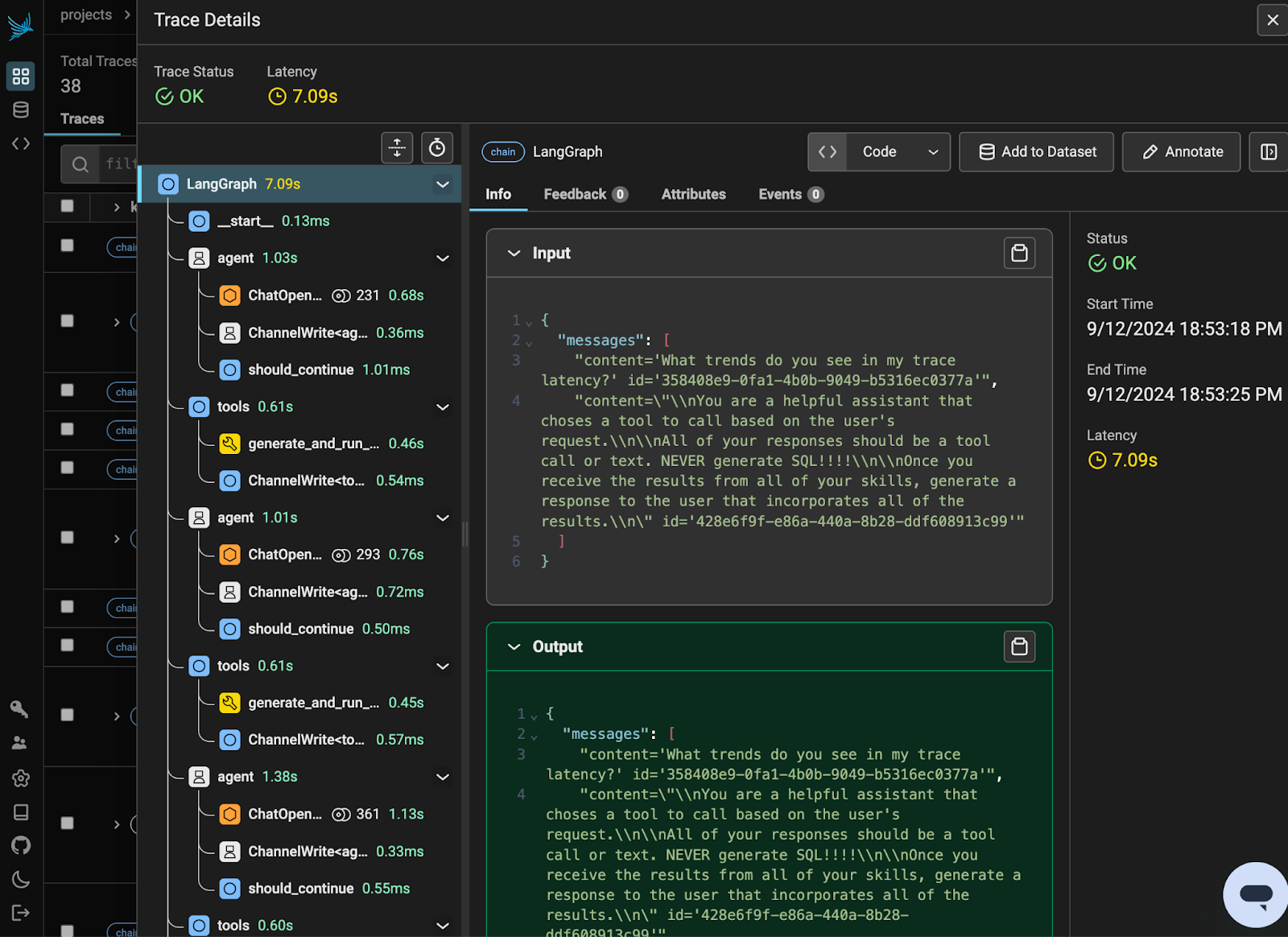
Benefits of LangGraph
LangGraph did make a few things easier for me:
- The graph structure code is very clean and accessible once you get used to it. Especially if you have complex node logic, having a single view of the graph makes it much easier to understand how the agent is connected together.
- Most of my issues came from objects within LangGraph and Langchain. If I already had an application built in Langchain, converting it to use LangGraph would be extremely straightforward.
Generally, my takeaway here is: If you use everything in the framework things work very cleanly, but if you step outside of it, prepare for some debugging headaches.
LlamaIndex Workflows
Workflows are a newer entrant into the agent framework space, releasing earlier this summer. Like LangGraph, they aim to make looping agents easier to build. Workflows also have a particular focus on running asynchronously.
Some elements of Workflows seem to be in direct response to LangGraph – specifically their use of events instead of edges and conditional edges. Workflows use steps (analogous to nodes in LangGraph) to house logic, and emitted and received events to move between steps.
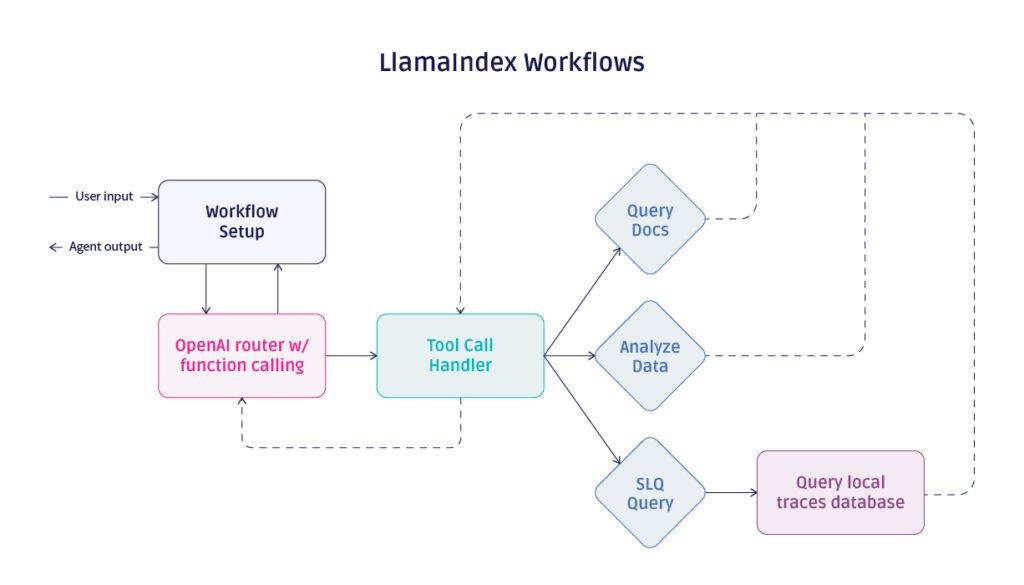
Agent structure in Workflows
The structure above looks similar to the LangGraph structure, save for one addition. I added a setup step to the Workflow to prepare the agent context, more on this below. Despite the similar structure, we once again have very different code powering it.
Workflows Architecture
First, I define the Workflow structure. Similar to LangGraph, this is where I prepared the state and attached the skills to the LLM object.
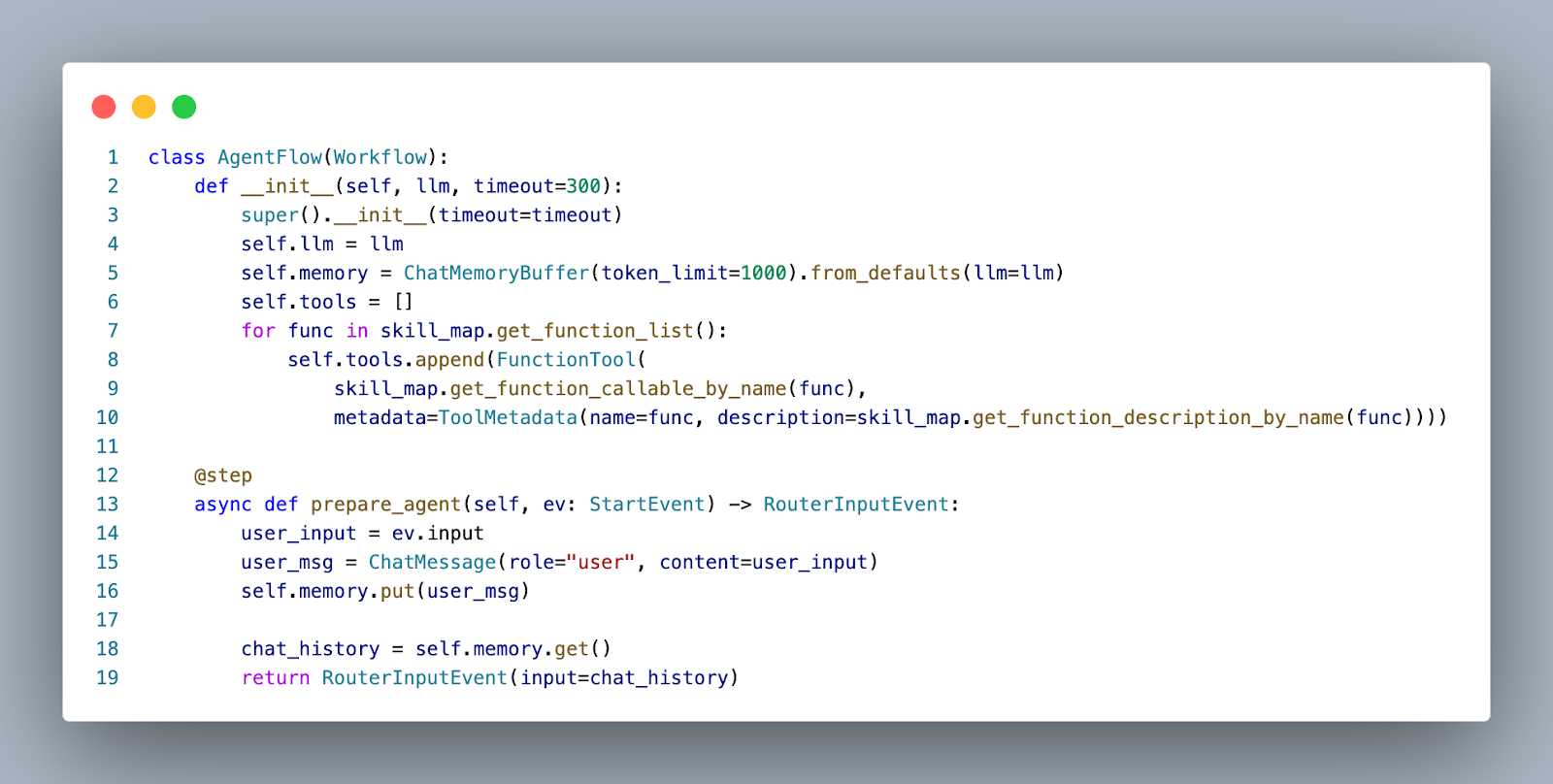
This is also where I define an extra step, “prepare_agent”. This step creates a ChatMessage from the user input and adds it to the workflow memory. Splitting this out as a separate step means that we do return to it as the agent loops through steps, which avoids repeatedly adding the user message to the memory.
In the LangGraph case, I accomplished the same thing with a run_agent method that lived outside the graph. This change is mostly stylistic, however it’s cleaner in my opinion to house this logic with the Workflow / graph as we’ve done here.
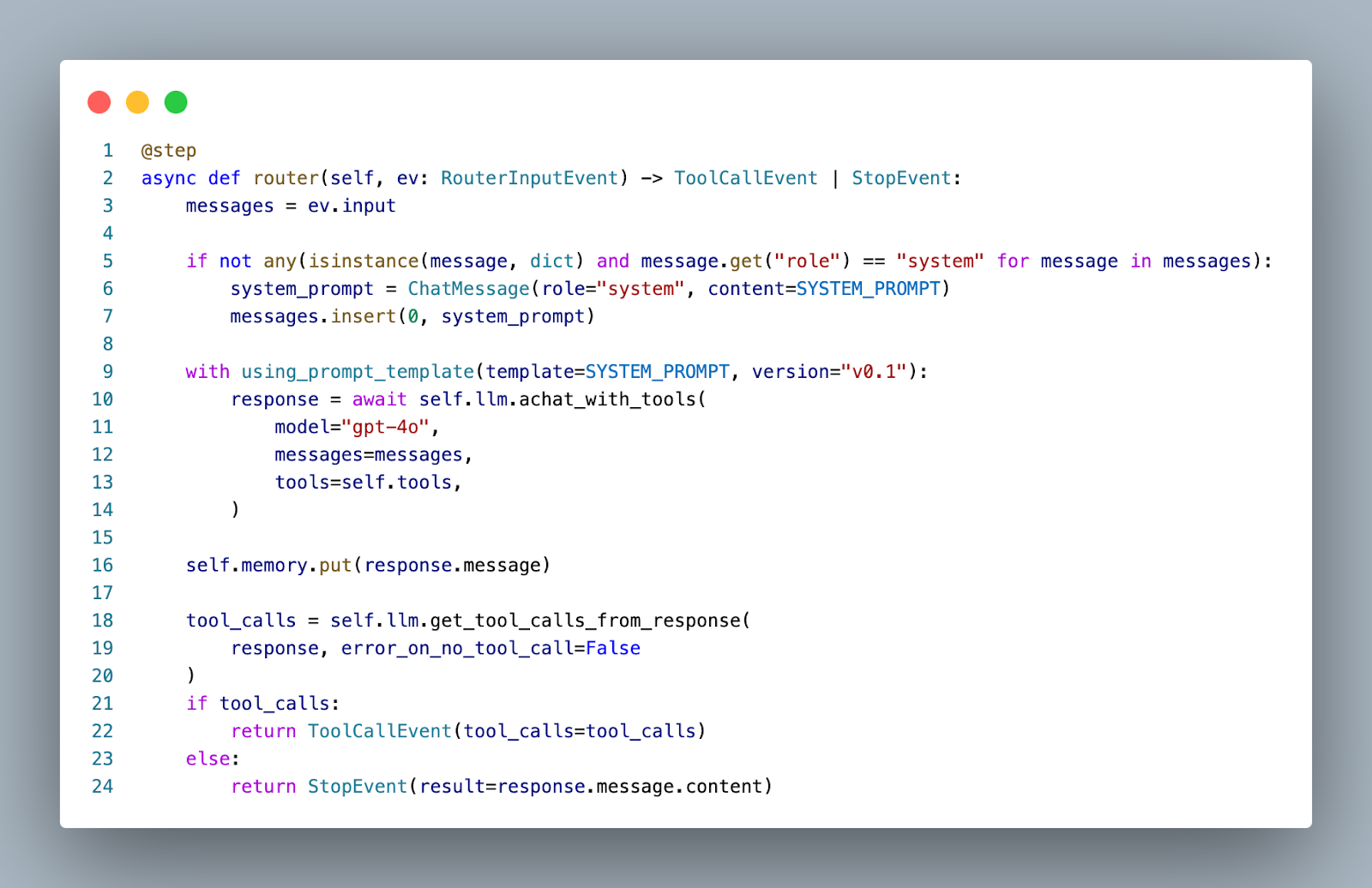
With the Workflow set up, I then defined the routing code:
And the tool call handling code:
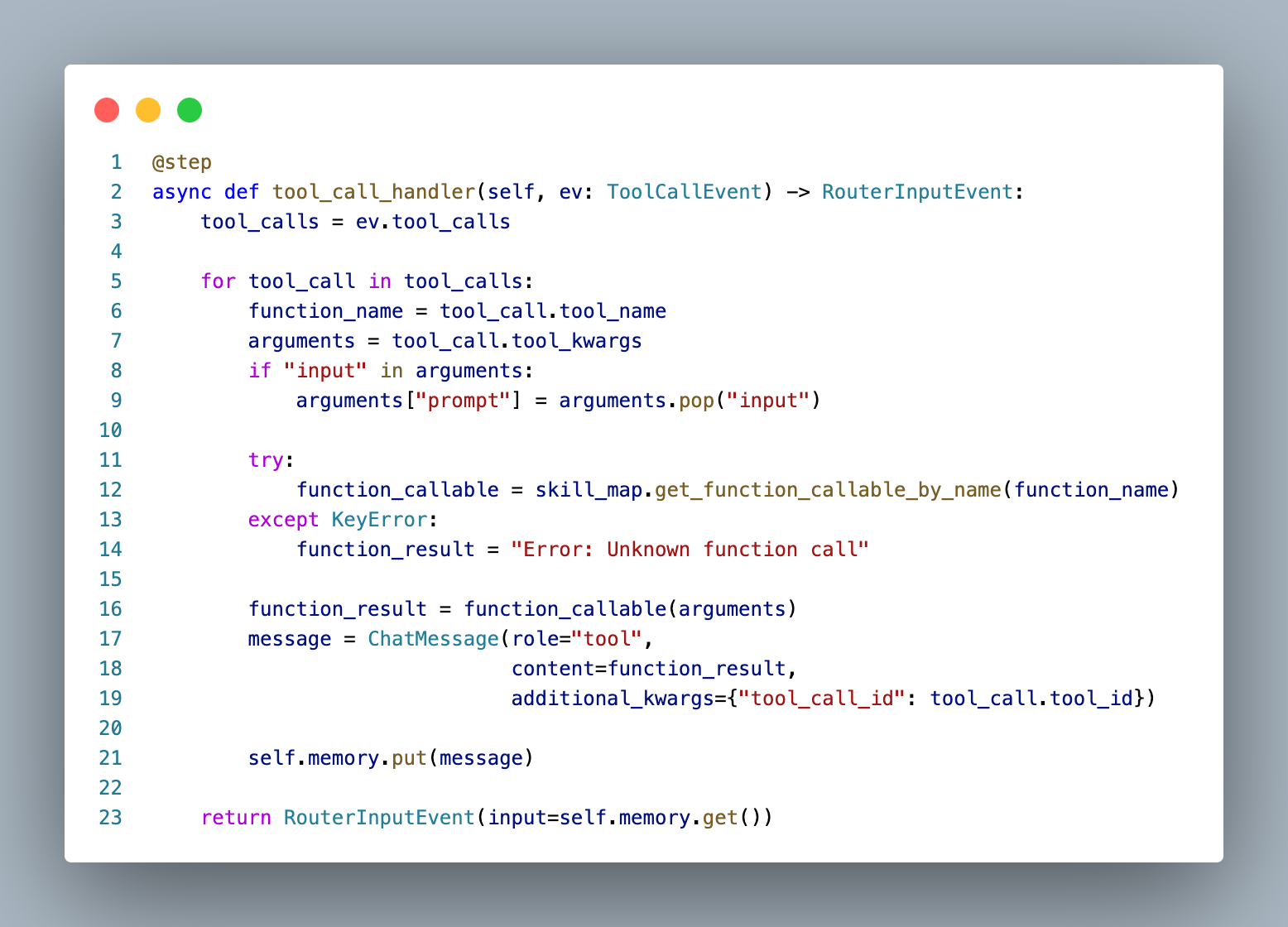
Both of these look much more similar to our code-based agent than the LangGraph agent. This comes down to two reasons:
- Workflows keep the conditional routing logic in the steps as opposed to in conditional edges. Lines 18-24 were a conditional edge in LangGraph, whereas now they are just part of the routing step.
- LangGraph has a ToolNode object that does just about everything in the tool_call_handler method automatically.
Moving past the routing step, one thing I was very happy to see is that I could use my SkillMap and existing skills from my code-based agent with Workflows. These required no changes to work with Workflows, which made my life much easier.
Challenges with Workflows
Challenge #1: Sync vs Async
While asynchronous execution is preferable for a live agent, debugging a synchronous agent is much easier. Workflows are designed to work asynchronously, and trying to force synchronous execution was very difficult for me.
I initially thought I would just be able to remove the “async” method designations and switch from “achat_with_tools” to “chat_with_tools”. However, I soon realized that underlying methods within the Workflow class were also marked as asynchronous, and I would need to redefine those in order to run synchronously. I ended up sticking to an asynchronous approach, but this didn’t make debugging more difficult. Again, Phoenix really helped here!
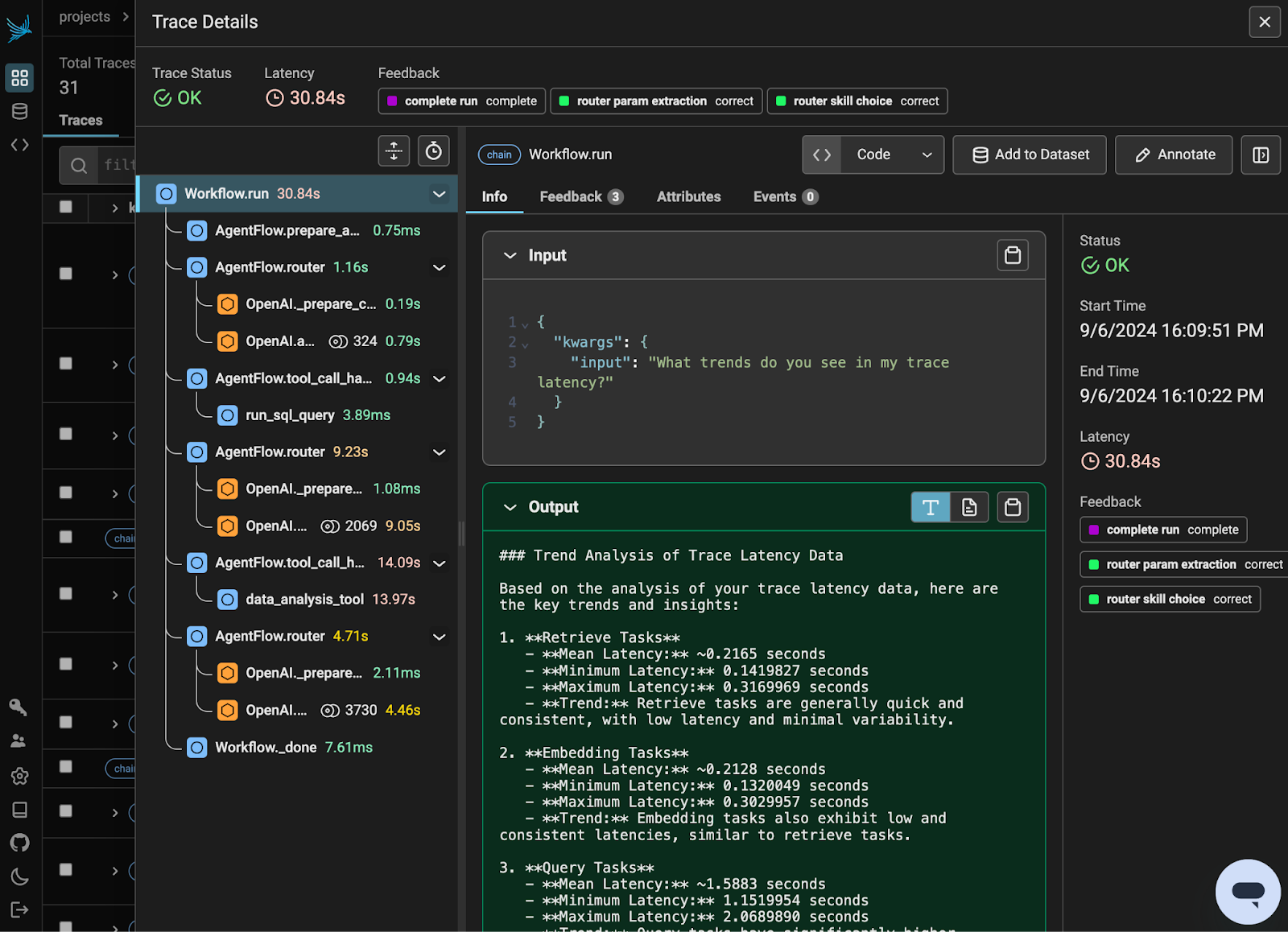
Challenge #2: Pydantic Validation Errors
In a repeat of my woes with LangGraph, I ran into similar problems with confusing Pydantic validation errors on my skills. Fortunately, these were easier to address this time, since Workflows are able to handle member functions just fine. I ultimately just ended up having to be more prescriptive in creating LlamaIndex FunctionTool objects for my skills.
Benefits of Workflows
I ultimately had a much easier time building the Workflows agent than I did the LangGraph agent, mainly because Workflows still required me to write routing logic and tool handling code myself instead of providing built-in functions. This also means that my Workflow agent looks extremely similar to my code-based agent.
The biggest difference comes in the use of events. I used two custom events to move between steps in my agent:

The emitter-receiver, event-based architecture took the place of me directly calling some of the methods in my agent, like the tool call handler.
If you have more complex systems with multiple steps that are triggering asynchronously and might emit multiple events, this architecture becomes very helpful to manage that cleanly.
To list the benefits I saw:
- Workflows is very lightweight and doesn’t force much structure on you (aside from the use of certain LlamaIndex objects)
- The event-based architecture provides a helpful alternative to direct function calling, especially for complex, asynchronous applications.
Time to Compare
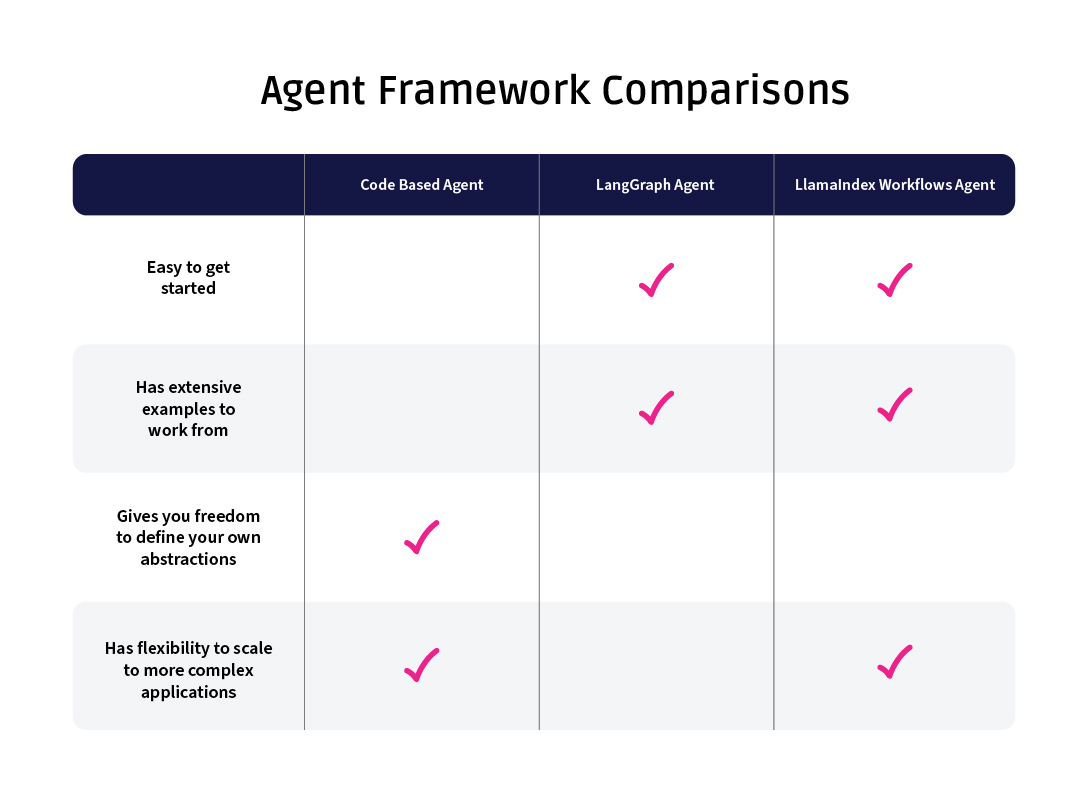
Looking across the three approaches, each one has its benefits.
The no framework approach was the simplest to implement. Because any abstractions were ones that I defined, like the SkillMap object, keeping various types and objects straight was easy. The readability and accessibility of the code entirely comes down to me however, and it’s easy to see how increasingly complex agents could get messy without some enforced structure.
LangGraph provided quite a bit of structure, which made the agent very clearly defined. If I had a broader team collaborating on an agent, this structure would provide a helpful way of enforcing an architecture. I can also envision LangGraph as a good starting point with agents if you’re not as familiar with the structure. That being said, LangGraph does quite a bit for you, and that comes with some serious headaches if you don’t fully buy into the framework. The code may be very clean, but you pay for it with more debugging.
Workflows fall somewhere in the middle. The event-based architecture could be extremely helpful for some projects, and I appreciate that there’s less required use of LlamaIndex types for those who may not be fully using the framework across their application.

Ultimately, the core question may just come down to “are you already using LlamaIndex or Langchain to orchestrate your application?”. LangGraph and Workflows are both so entwined with their respective underlying frameworks, and at this point I don’t think the additional benefits of each agent-specific framework would cause you to switch on their merit alone.
The pure code approach will always be an attractive option. If you have the rigor to document and enforce any abstractions you create, then you can ensure nothing in an external framework slows you down.
Key Questions to help you choose a framework
“It depends” is never a satisfying answer, so let’s at least close out by specifying what choosing the right framework depends on. These three questions should help you decide which framework to use in your next agent project:
- Are you already using LlamaIndex or Langchain for significant pieces of your project?
- If yes, explore that option first.
- Are you familiar with common agent structures, or do you want something telling you how you should structure your agent?
- If you fall into the latter group, try Workflows. If you really fall into the latter group, try LangGraph.
- Has your agent been built before?
- One of the framework benefits is that there are many tutorials and examples built with each. There are far fewer examples of pure code agents to build from.
I hope you’ve found this deep dive helpful. If you have any questions or feedback, I’d love to hear from you!
And if you’re building with agents, Arize has all the tools you need to analyze, understand, and improve your applications: