


The development of the Transformer model, as introduced in the paper “Attention is all you need,” has had a profound impact on the field of natural language processing (NLP). One notable application of the Transformer model is the Bidirectional Encoder Representations from Transformers (BERT).
How the Transformer Model Revolutionized the NLP Landscape
Traditionally, NLP tasks such as machine translation and language modeling relied on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) to process sequences of text. However, these models suffer from several limitations, including difficulty in handling long-term dependencies and a high computational cost. The Transformer model overcomes these limitations by using self-attention mechanisms that allow the model to attend to different parts of the input sequence, even if they are far apart.
The Transformer model consists of an encoder and a decoder, each consisting of a series of layers. The encoder processes the input sequence, while the decoder generates the output sequence. Each layer in the Transformer consists of two sub-layers: multi-head self-attention and a feed-forward network. The multi-head self-attention layer allows the model to attend to different parts of the input sequence, while the feed-forward network performs non-linear transformations on the output of the self-attention layer.
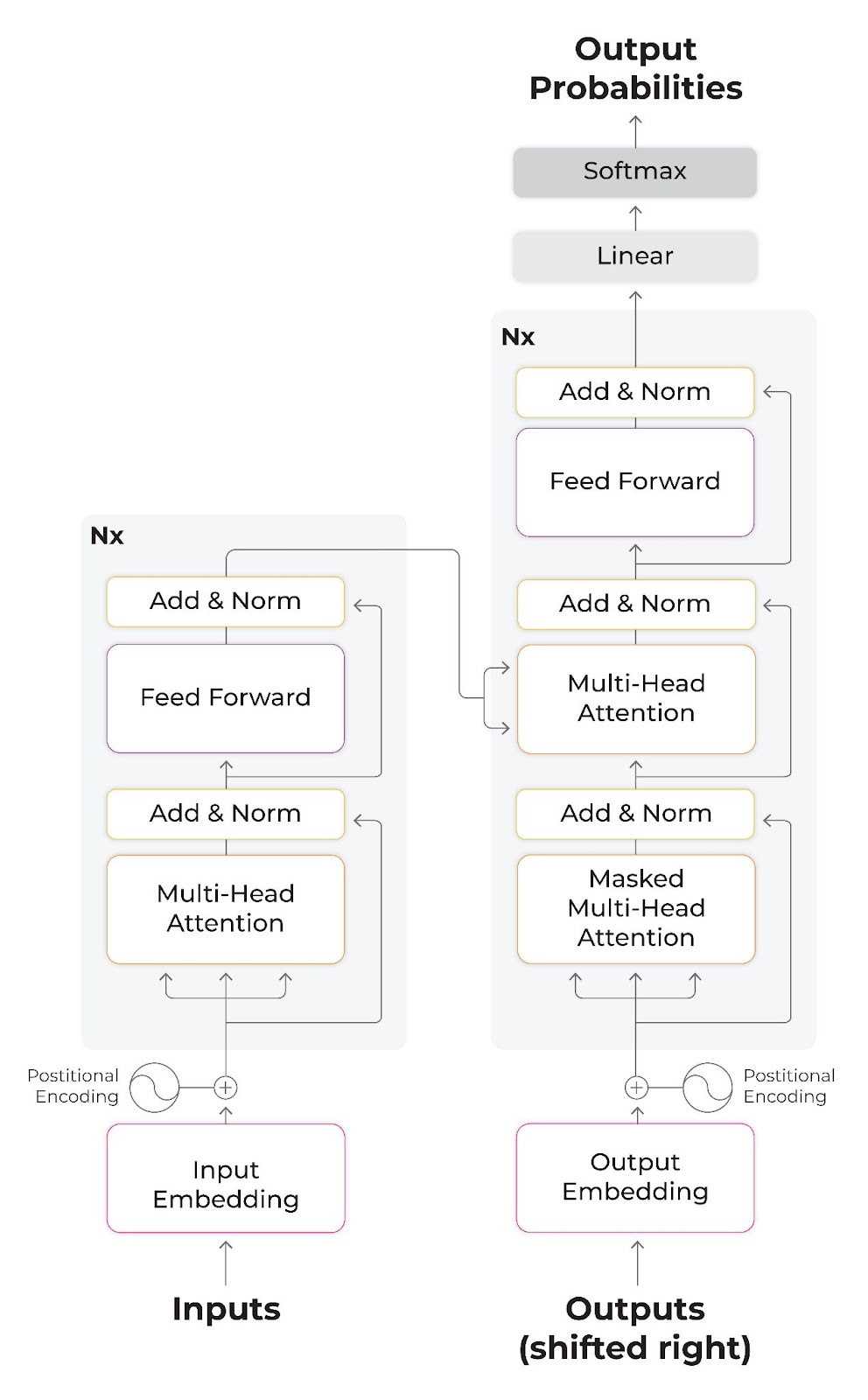
The encoder-decoder structure of the Transformer architecture outlined in “Attention is all you need.”
The introduction of the Transformer model and its innovations reshaped the field of NLP. The model achieved state-of-the-art results on many NLP tasks, and its attention mechanism became a popular building block for other neural network architectures. The Transformer model was also the foundation for the development of BERT, a pre-trained language model that has achieved even more impressive results on a wide range of NLP tasks.
What Is BERT?
BERT is a pre-trained language model that utilizes the Transformer architecture to generate high-quality representations of text. The model is pre-trained on a large corpus of unlabeled text data, using masked language modeling and next sentence prediction as part of the training process.
Masked language modeling is a technique where a certain percentage of the tokens in a sentence are randomly replaced with a special [MASK] token. The model then has to predict the original token from the context of the other tokens in the sentence. BERT uses this technique during pre-training to learn a deep understanding of how different words are related to each other in context.

Model structure of the label-masked language model. [N-MASK] is a mask token containing negative label information.
Next sentence prediction is a task where the model is given two sentences and has to predict whether they are contiguous in a text or not. BERT uses this task during pre-training to help it learn to understand the relationship between different sentences and how they fit together in a larger piece of text.

Model structure for next sentence prediction.
Together, masked language modeling and next sentence prediction allow BERT to learn a deep understanding of the structure and meaning of natural language text. This pre-training process enables BERT to be fine-tuned on a variety of downstream tasks.
Key Features of the BERT Model
- Bidirectional: Unlike traditional language models that process text in a unidirectional manner (i.e., from left to right or right to left), BERT processes text in both directions, which helps it to better understand the context and meaning of words.
- Transformer-based architecture: BERT uses a transformer-based architecture that enables it to capture long-range dependencies and relationships between words, which is critical for understanding the meaning of text.
- Fine-tuning for downstream tasks: After pre-training, BERT can be fine-tuned for a wide range of downstream NLP tasks, such as text classification, named entity recognition, and question-answering, among others. This means that BERT can be used for a wide range of NLP tasks without the need for significant additional training.
- Contextual word embeddings: BERT generates contextual word embeddings, which means that the meaning of a word is influenced by the words that come before and after it in a sentence. This helps BERT to better capture the nuances and complexities of language.
- State-of-the-art performance: BERT has achieved state-of-the-art performance on a wide range of NLP benchmarks, including the GLUE (General Language Understanding Evaluation) benchmark, which measures performance on a variety of NLP tasks.
Attention
Attention is a core component of BERT. In fact, BERT stacks multiple layers of attention. Each attention layer operates on the output of the layer that came before it; each layer learns a unique attention parameter. BERT also utilizes multihead attention to capture a broader range of relationships between words versus a single attention mechanism. Through this process, it creates a composite representation that the model can reason about.

Model view of attention throughout the entire model. Each cell shows the attention weights for a particular head, indexed by layer (row) and head (column). Source.
So what is attention? Let’s break it down…
Suppose we have a sequence of vectors, X. Attention is a function that takes X as input and returns another sequence Y of the same length, composed of vectors of the same length as those in X. Each vector in Y is a weighted average of the vectors in X. These weights represent how much the model attends to each input.

BERT uses a compatibility function to assign a score to each pair of words indicating how strongly they should attend to one another. This works by assigning a query vector and key vector to each word. This process is done dynamically based on the output from the previous layer. The score assigned is the dot product of the two vectors. The scores are then normalized to be positive and summed to 1 by applying the softmax function.

The neuron view visualizes the intermediate representations (e.g. query and key vectors) that are used to compute attention. Source.
Flavors of BERT
There are several pre-trained versions of BERT available:
- BERT Base: This is the original version of the BERT model, which has 12 layers and 110 million parameters. It is pre-trained on a large corpus of text, and fine-tuned for specific NLP tasks.
- BERT Large: This is a larger version of the BERT model, with 24 layers and 340 million parameters. It is designed to capture even more complex linguistic structures and nuances in language than the base version.
- RoBERTa: RoBERTa (Robustly Optimized BERT approach) is a variant of BERT developed by Facebook AI Research. It is pre-trained on a larger dataset and uses a longer pre-training schedule, which leads to improved performance on several NLP benchmarks.
- DistilBERT: DistilBERT is a distilled version of the BERT model, developed by Hugging Face. It has fewer parameters than the base version, which makes it faster and more memory-efficient, while still achieving similar performance on several NLP tasks.
- ALBERT: ALBERT (A Lite BERT) is a variant of BERT developed by Google, which aims to reduce the number of parameters while maintaining or improving performance. It achieves this by factoring the embedding matrix and sharing parameters across layers.
- ELECTRA: ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) is a variant of BERT developed by Google, which uses a novel pre-training method to improve efficiency and reduce computational costs. It achieves similar or better performance than BERT on several NLP benchmarks.
How To Use BERT
Predictions
To use BERT, you’ll need to fine-tune the model on your specific NLP task. Fine-tuning involves training the model on a labeled dataset that is specific to your task. This process involves replacing the final layer of BERT with a task-specific layer and training the entire model on the labeled dataset.The choice of which pre-trained version to use will depend on the size of your labeled dataset and the complexity of your NLP task.
Implementing BERT Using PyTorch
To get started, first install the required libraries.
!pip install transformers
!pip install torch
Next, you can load a pre-trained BERT model and tokenizer using the transformers library.
import torch
from transformers import BertTokenizer, BertForSequenceClassification
To encode a sentence using BERT, you need to tokenize it first using the tokenizer.
sentences = ["This is a positive sentence.", "This is a negative sentence."]
labels = [1, 0] # 1 is positive, 0 is negative
# Tokenize the input sentences
encoded_inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Create the input tensors
input_ids = encoded_inputs['input_ids']
attention_masks = encoded_inputs['attention_mask']
The tokenized variable will contain a list of token IDs representing the sentence, including special tokens such as [CLS] and [SEP]. To get the embeddings for the sentence, you can pass the token IDs to the BERT model.
# Convert token IDs to tensor
input_ids = torch.tensor([tokenized])
# Get BERT embeddings
with torch.no_grad():
embeddings = model(input_ids)[0]
The embeddings variable will contain a tensor of shape (1, sequence_length, hidden_size), where sequence_length is the length of the tokenized sentence and hidden_size is the size of the BERT model’s hidden layers. You can use the embeddings for various NLP tasks, such as text classification, by adding a classification layer on top of the BERT model. Here’s an example of how to train a simple text classifier using BERT embeddings.
from torch.utils.data import DataLoader, Dataset
from transformers import AdamW
# Define dataset
class TextDataset(Dataset):
def __init__(self, texts, labels):
self.texts = texts
self.labels = labels
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
return text, label
# Define training data
train_texts = ["I love using BERT", "BERT is amazing", "BERT is the best"]
train_labels = [1, 1, 0]
train_dataset = TextDataset(train_texts, train_labels)
# Define model
class Classifier(torch.nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.dropout = torch.nn.Dropout(0.1)
self.fc = torch.nn.Linear(hidden_size, 1)
def forward(self, input_ids):
embeddings = self.bert(input_ids)[0]
pooled = embeddings.mean(dim=1)
pooled = self.dropout(pooled)
logits = self.fc(pooled)
return logits
model = Classifier(model.config.hidden_size)
# Define optimizer and loss function
optimizer = AdamW(model.parameters(), lr=1e-5)
criterion = torch.nn.BCEWithLogitsLoss()
# Train model
train_loader = DataLoader(train_dataset, batch_size=1, shuffle=True)
for epoch in range(10):
for texts, labels in train_loader:
optimizer.zero_grad()
input_ids = tokenizer.batch_encode_plus(
texts, add_special_tokens=True, max_length=128
Once you fine-tune the model on your labeled dataset, you can use it to make predictions on new text data. BERT can be used for a wide range of NLP tasks, including sentiment analysis, text classification, and question answering.
Embeddings
When generating embeddings with BERT, the model is used as a feature extractor to encode input text into high-dimensional representations (embeddings) that capture the meaning of the text. These embeddings can then be used as input to downstream models for various NLP tasks, such as clustering, similarity analysis, and classification.
The main difference between using BERT for prediction versus generating embeddings is the type of task that the model is trained on. In the case of prediction, the model is trained on a task-specific dataset with a task-specific output layer, while in the case of generating embeddings, the model is trained on a large corpus of text and used as a feature extractor. Additionally, the fine-tuning process for prediction involves updating the model’s parameters, while generating embeddings does not require any training.
Learning more on how you can generate embeddings using BERT with Arize.
Performance
The performance of BERT is widely regarded as highly effective in NLP tasks. BERT has achieved high quality results on several benchmarks and challenges. While BERT’s performance can vary depending on the specific task and dataset, its success in a range of NLP applications has made it a popular choice for researchers and practitioners in the field.
In terms of inference speed, the size and complexity of the BERT model can also impact its performance. Smaller versions of BERT, such as DistilBERT, are designed to be faster and more memory-efficient, with reduced computational requirements compared to the original BERT model. However, these smaller models may sacrifice some level of accuracy and performance compared to the larger, more complex BERT models.
Overall, while BERT may be slower than some other NLP models, its high level of accuracy and ability to perform well on a wide range of NLP tasks make it a powerful tool for natural language processing.
Why Is BERT Important?
One of the key advantages of BERT is its ability to capture the context and meaning of words within a sentence, which is critical for many NLP tasks. The model achieves this by using pre training with masked language modeling and next sentence prediction and leveraging multihead attention.
BERT has had a significant impact on the field of NLP. Its ability to capture the context and meaning of words within a sentence, combined with its pre-training on a large corpus of data, has enabled it to achieve these results. Understanding BERT and its underlying Transformer architecture can be a valuable skill to have in your toolkit when working on NLP tasks.
How Does BERT Differ From the Transformer Model?
One of the main differences between BERT and the Transformer model is their objectives. The Transformer model is designed to generate output sequences from input sequences, while BERT is designed to generate high-quality representations of text that can be used for a wide range of NLP tasks.
Another key difference between the two models is their training process. The Transformer model is trained on a supervised learning task, where the input and output sequences are aligned. BERT, on the other hand, is pre-trained on an unsupervised learning task, where the model is trained to predict missing words in a sentence or the next sentence in a document.
Despite these differences, BERT and the Transformer model share many similarities. Both models use multi-head self-attention mechanisms to capture the relationships between the words in a sequence. They both also use feedforward neural networks to transform the output of the attention mechanism.
Summary
Overall, the BERT model represents a major breakthrough in the field of NLP, building on the success of the Transformer model introduced in “Attention is all you need.” Its ability to capture the context and meaning of words within a sentence, combined with its pre-training on a large corpus of data, has enabled it to achieve state-of-the-art results on a wide range of NLP tasks. As research in this area continues to advance, we can expect to see even more exciting developments in the use of attention mechanisms and other techniques for natural language processing.