


Large language models (LLMs) are revolutionizing the AI landscape. Despite being relatively new, many teams are jumping at the opportunity to deploy these powerful models in their organizations. While excitement is high, knowing where to start can be a daunting task.

This post covers the ins-and-outs of deploying LLMs, including: tradeoffs between models, optimization — prompt engineering, fine tuning, and context retrieval — deployment strategies, and what to do after launch.
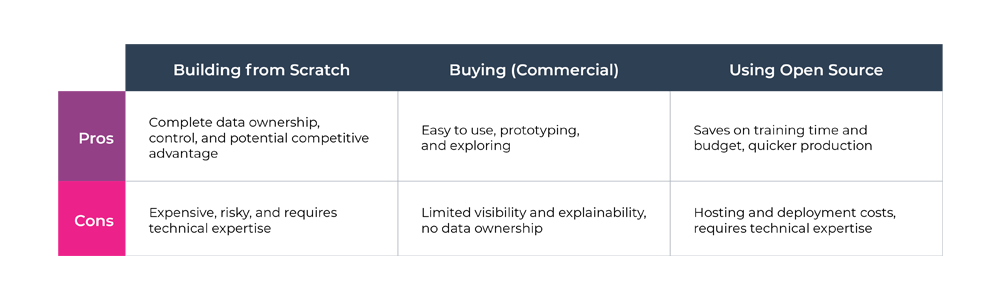
Tradeoffs Between Custom and Commercial Models (Build Versus Buy LLMs)
Benefits of Building
One of the first decisions to make when deciding to deploy a LLM is whether to build a LLM from scratch or use a commercial model. Both options have their advantages, and the answer might actually be both. Let’s get into it.
One benefit of building an LLM from scratch is that you have complete data ownership and privacy. Not only will your proprietary data be kept private but you can also make the most out of it. By leveraging your own data, you have the ability to control where the data powering your LLM comes from. This allows you to make sure the LLM is trained on reliable sources that won’t contribute to bias. You also don’t have to worry about your proprietary data being inadvertently used by a third party for training or leaked.
Using your own data could also lead to superior performance, potentially giving you a competitive advantage. You can also decide exactly what content filters to use based on your specific business use case. For example, you might need a longer sequence length than what a commercial model offers or the ability to add specific content filters to your training data. When you opt to use a commercial LLM, you have to work around the sequence limits and have no visibility of the data used for training.
Commercial models, like GPT-4, are known to have a delay ranging from 5 to 30 seconds depending on the query. This latency issue is not ideal for applications that require real-time responses. When you build your LLM from scratch, you can opt for a smaller model with fewer layers and less parameters which tend to have faster inference speeds than their larger peers.
There’s growing evidence that smaller models can be just as powerful as larger models for domain specific tasks. BioMedLM, a biomedical-specific LLM using a mere 2.7 billion parameters, performed just as well if not better than a 120 billion parameter competitor. Another benefit: your model is smaller this will save you a bunch in training and serving costs.
Since you have complete model ownership when you opt to build from scratch, you also have better introspection and explainability. A commercial model is a black box; since you have little to no access to the inner workings of the model, understanding why the model is behaving the way it does is extremely difficult.
Benefits of Commercial Models
One of the biggest challenges when building an LLM from scratch is the cost. Building a LLM can be extremely expensive. GPT-4, for example, reportedly cost $100 million to train. There’s also a lot of risk. With little room for error, you could end up wasting thousands or even millions of dollars — leaving you with only a suboptimal model. You also need a large volume of high quality and diverse data in order for the model to gain the required generalization capabilities to power your system.
Using a commercial model, on the other hand, means far less training costs. Since you do not have to worry about hosting or pre-training a commercial LLM, the only cost occurs at inference. Training costs would only be acquired from doing tests and experiments during development. Another benefit of commercial LLMs is they require less technical expertise. Finally, commercial models can also are a great tool for prototyping and exploring.
So…Which?
Overall, the choice of whether or not to build or buy an LLM comes down to your specific application, resources, traffic, and data ownership concerns. Teams with domain-specific applications might opt to build a model from scratch whereas teams looking to leverage the latest and greatest to build downstream applications might use a commercial model. Prior to heavily investing in either option, you may want to experiment with the technology to understand what’s possible and carefully consider your specific requirements.
What Are the Benefits of Open Source Over ChatGPT and Other Commercial LLMs?
While build-versus-commercial is the mainstream debate, let’s not forget about the open source options. There have been some impressive open source models that are available for commercial use. Dolly, MPT-7B, and RedPajama are just a few examples of open source models with commercial licenses that are rivaling popular commercial models like GPT-4 and LLaMA.
Open source LLMs allow you to leverage powerful models that have already learned a vast amount of data without having to be dependent on a service. Since you are not starting completely from scratch, there can be huge savings on training time and budget. This allows you to get your model in production sooner.
Just like building and using commercial LLMs, open source LLMs have downsides as well. While you save on costs at inference time by not having to pay a service provider, if you have a low usage then using a commercial model might actually lead to a cost savings. The cost benefits of open source models is seen when the requested volume is more than one million (see: Skanda Vivek’s great piece on LLM economics). The main cost associated with using open source is hosting and deploying these large models. When you have thousands of requests a day, paying a service provider often works out cheaper than paying at inference.
In addition to cost, open source models, while less demanding than building from scratch, still require substantial lift. Similar domain expertise is needed to train, fine-tune, and host an open source LLM. There is also evidence to support that reproducibility is still an issue for open source LLMs. Without the proper expertise you risk wasting time and resources.
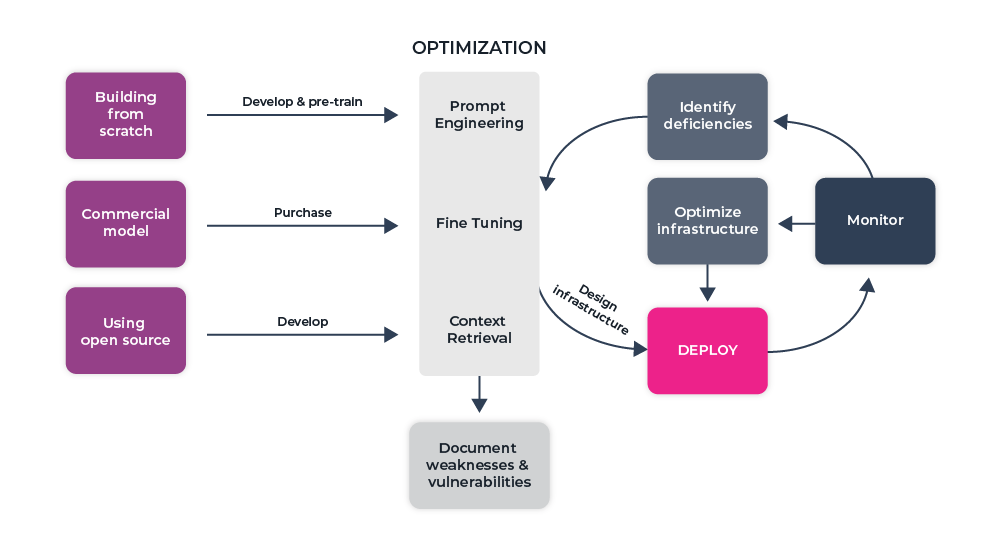
A Practical Guide to Optimization of Foundation Models
The steps to deployment will differ depending on your use case and model choice. Commercial models, for example, do not allow for fine tuning. Instead, you opt for prompt engineering and context retrieval to optimize your LLM. When using an open source or your own LLM, you’ll likely use a combination of these techniques to refine the model’s performance.
Prompt Engineering — Shaping Performance with the Right Instructions
Prompt engineering is a new field in AI where engineers focus on crafting prompts to feed the model, with prompts defined as the set of instructions the LLM will use to perform the task. Prompts play a huge role in optimizing and controlling the performance of LLMs. Prompt engineering allows developers to provide the LLM with context to perform a specific task. A good prompt will assist the model in providing high quality responses that are relevant and accurate. This allows you to harness the power of LLMs without needing extensive fine-tuning.
Since prompts are at the center of guiding model output towards the desired direction, prompt engineering is a crucial step in deploying an LLM. An effective prompt will allow your LLM to correctly and reliably respond to your query. You want your prompt to be clear and include specific instructions. Some best practices for prompts include:
- Write clear and specific instructions
- Use delimiters to indicate specific pieces of the prompt
- Outline the structure of the desired output
- Use guidelines to check if certain conditions are met
- Leverage few-shot prompting to give successful examples of completing the task
Prompt engineering is an iterative process, it is unlikely that you will get the desired outcome from your first shot. You’ll want to create a process to iterate and improve on your prompt. The first step is to create a clear and specific prompt. Run a test with this prompt and observe the outcome, did it meet your expectations? If not, analyze why the prompt might not be generating the desired output. Use this information to refine the prompt. This might include adjusting the language, clarifying, or giving the model more time to think. Repeat this process until you feel confident in your prompt.
It’s worth mentioning that your prompt can also save you money. For example, adding “be concise” to your prompt can limit the response given. When you are using an API, like OpenAI’s API, you are charged based on the tokens given in the response so you’ll want to be sure you’re giving concise responses to ensure you are not racking up costs.
The main takeaway from this is we want to guide the model to pay attention to the latent space that is most relevant to the task at hand. To do this, you want to provide the correct context, instructions, and examples in your prompt. You can even stylize your LLM through prompting and save a huge percentage by simply adding “be concise.” There’s no doubt that prompt engineering is just as important as the foundation models that are being developed. The process is iterative and can be time-consuming but it is essential for having a well-performing and reliable model.
Fine Tuning Foundation Models — Transforming Generalized Models into Specialized Tools
You may be asking yourself how prompt engineering is different from fine tuning a LLM. The answer is simple: the task is the same — getting the model to perform a specific task — but it is done through a different mechanism. In prompt engineering, we are feeding instructions, context and examples to the model to perform a specific task; with fine tuning, we are updating the model’s parameters and training with a task specific dataset. You can think of prompt engineering as “in context learning” whereas fine tuning is “feature learning.” It is important to note that these two tasks are not mutually exclusive, meaning you might employ both methods.
Fine tuning is not a new task that appeared with the rise of LLMs. Fine tuning has been used as a part of transfer learning before transformers, attention mechanisms, and foundation models ever came to exist. The general concept of fine tuning is to take a model trained on a broad data distribution and specialize it by adjusting the parameters. In the context of LLMs, this is no different.
Once pre-training is complete by your internal engineers, it can be fine-tuned for a specific task by training on a smaller task specific set of data . A key component to successful fine tuning is being sure to use data that is representative of the target domain. Remember, the structure of your data is what determines what capabilities your model has so you’ll want to keep this in mind when choosing your dataset.
You can also opt to fine-tune the model’s parameters. Traditionally speaking, there are two different approaches you can take: freezing all the LLM’s layers and only fine tuning the output layer or fine tuning all layers. Generally speaking, fine tuning all layers yields better performance but it does have a higher cost associated with it due to the memory and compute requirements.
In recent years, researchers have found ways to avoid this tradeoff through methods like parameter efficient fine tuning (PEFT) and Low Rank Adaption (LoRA). These methods allow you to efficiently and cost effectively fine tune your models without having to compromise on the performance.
Enhancing LLMs with Context Retrieval
Another common task in developing an LLM system is to add context retrieval to your process. This popular technique allows you to arm your LLM with context not included in the training data without having to undertake total retraining. In this method, you would process your data to be split into chunks and then stored in a vector database. When a user asks a question, the vector database is queried for semantically similar chunks and the most relevant pieces of information are pulled as context for the LLM to generate a response.
Context retrieval can drastically improve the responses given by your LLM. You’ll want to experiment with similarity metrics and chunking methods to ensure the most relevant information is being passed in the prompt. It is also important to pinpoint user queries that are not answered by your knowledge base so that you know which topics to iterate and improve upon. While evaluating the model’s responses and context, it is possible to identify areas where the LLM lacks the knowledge it needs to answer. Using this information, you can add the context your LLM is missing to improve the model’s performance.
Critical Non-Technical Considerations of Foundation Models
Prior to deploying an LLM, it’s important to do a comprehensive evaluation to be aware of the model’s limitations and sources of bias. It is also recommended that you develop techniques, such as human feedback loops, to minimize any unsafe behavior. We have seen real life examples of how users were able to easily manipulate the input of the models and cause the model to respond in nefarious ways. It’s best to ensure you have the proper tools and procedures to mitigate the risk of inappropriate or unsafe behavior.
Once you have identified weaknesses and vulnerabilities, they should be documented along with use case specific best practices for safety. The public should also be made aware of any lessons learned around LLM safety and misuse of the applications. It is likely impossible to eliminate all unintended bias or harm, but by documenting it creates transparency and accountability — all key to developing responsible AI.
To that end, an important component that is too often overlooked when developing an LLM application is thoughtfully collaborating with stakeholders. By including people from diverse backgrounds in your team and soliciting broader perspectives, you can combat biases or failure of the model. Our models are expected to work on the diverse population that exist; the teams who build them should reflect this.
Deployment Strategies
Deploying LLMs can bring a host of new problems. When it comes to the optimal deployment strategy, each use case will be different. You’ll want to consider the problem you are trying to solve to determine the best strategy.
Latency
Different applications have different latency requirements. You’ll want to assess the desired inference speed prior to deployment, making the appropriate hardware choices to meet requirements. GPUS and TPUs, for example, are key when optimizing inference speed. Both are more expensive than CPUs, which are generally slower.
Cost
If you’re building your own model or leveraging open source, you’re going to have to host your model. Because of their significant size, these models require a lot of computational power and memory and end up driving up infrastructure costs. Additionally, to reduce latency you might need to leverage GPUs or TPUs. Optimizing resources is paramount.
Resource Management
As mentioned previously, when you are hosting a model — whether it’s your own in house model or an open source model — it requires a lot of resources. Storing the model in a single storage device is impractical, thus requiring far more storage than conventional models.
Accommodating for memory requirements is also crucial. You can opt for multiple servers, model parallelism, or distributed inference to address these storage capacity issues. Additional requirements might include GPUs, RAM and high-speed storage to improve inference speed. It’s key to have the proper infrastructure to support your LLM, but these resources are costly and challenging to manage. Therefore, careful and thorough planning of your infrastructure is of the utmost importance. Here are some things to consider:
- Deployment options: Cloud-based or on-premise deployment. Cloud deployments are flexible and easy to scale while on-prem deployments might be preferred for applications when data security is important.
- Hardware selection: Choose the hardware that aligns with your needs including processing power, memory, and storage capacity.
- Scaling options: Choose the right inference option.
- Resource optimization: Leverage model compression, quantization or pruning to reduce your memory requirements, enhance computational efficiency, and reduce latency
- Resource utilization: Be sure to only utilize relevant resources or else you might end up eating a lot of unnecessary cost
Security
One of the main considerations enterprises should take when deploying is security and privacy requirements. You’ll want to be sure to have the proper techniques to preserve data privacy. In addition, you might consider encrypting data at rest and in transit to protect it from unauthorized access. It’s also critical to consider legal obligations like General Data Protection Regulation (GDPR) and implement the proper management, privacy, and security practices to ensure compliance.
After the Launch
Once you put the model into production, you will need to monitor and evaluate the model’s performance. You’ll want to do continuous evaluation of the model’s behavior and investigate any degradations. LLMs are sensitive to changes in input and can be negatively influenced leading to inappropriate responses. LLMs are also known to hallucinate so you’ll want to closely evaluate and monitor responses. Often, you may have to return to prompt engineering and update your knowledge base to maintain your model’s performance. As always, it’s important to ensure you have the proper feedback loops and workflows in place to efficiently troubleshoot your model’s performance and quickly take action.
You’ll also want to monitor your resources. This will allow you to identify any underutilized resources and scale back when necessary. It will also help you to identify resource-intensive operations which require the architecture to be optimized.
Summary
Let’s recap. Once you’ve identified your specific use case, you’ll want to decide on whether you will build, buy, or use an open source model. After your chosen model is pre-trained, you will need to utilize an array of strategies to improve response quality and customize the model to your unique task. While performance optimization is key for a successful LLM application, it’s equally important to minimize unsafe behavior. This can be achieved through transparency, establishing feedback loops, and including diverse stakeholders in the development process. The deployment strategy should be tailored to the specific use case, with a clear focus on managing latency and optimizing resources to reduce costs. Post-deployment, the model’s performance and resource utilization should be continuously monitored and evaluated to maintain performance and optimize operations.
In essence, the success of any deployment requires technical expertise, careful planning, and constant oversight to ensure the model functions optimally.
Given that LLMs are in the early stages of development, the best practices for their deployment are likely to continue evolving. We can anticipate the development of superior tools designed to streamline the deployment of these models. Further advancements are likely to yield better techniques for optimizing model performance.
It’s an exciting time in the sense that we are in relatively unchartered territories with LLMs. As we learn and grow, we will see continuous evolution in methodologies, tools, and optimization strategies.