
From the basics to how self-attention works, a quick-reference guide to understanding the iconic paper and its practical applications years later
Originally inspired by the human mechanism of selectively focusing on certain aspects of information, attention mechanisms in machine learning models provide a way to weigh the importance of different elements in a given input. The concept first gained significant popularity and importance in the wake of the iconic paper “Attention is All You Need.”

What is Attention in Machine Learning?
Attention is a mechanism in machine learning models that allows them to dynamically focus on specific parts of the input data, assigning varying levels of importance to different elements. It helps in resolving the limitations of fixed-length encoding in traditional neural networks, which can struggle to handle long sequences or complex patterns. By selectively focusing on certain elements of the input, attention mechanisms can improve the model’s overall performance in tasks like natural language processing, image recognition, and speech recognition.
At its core, attention can be thought of as a way of assigning importance weights to different parts of the input, based on their relevance to the task at hand. For example, in natural language processing, attention can be used to determine which words in a sentence are most important for understanding its meaning, while in computer vision, attention can be used to focus on specific regions of an image that are most relevant for object detection or recognition.
How Does It Work and What Are the Common Mechanisms?
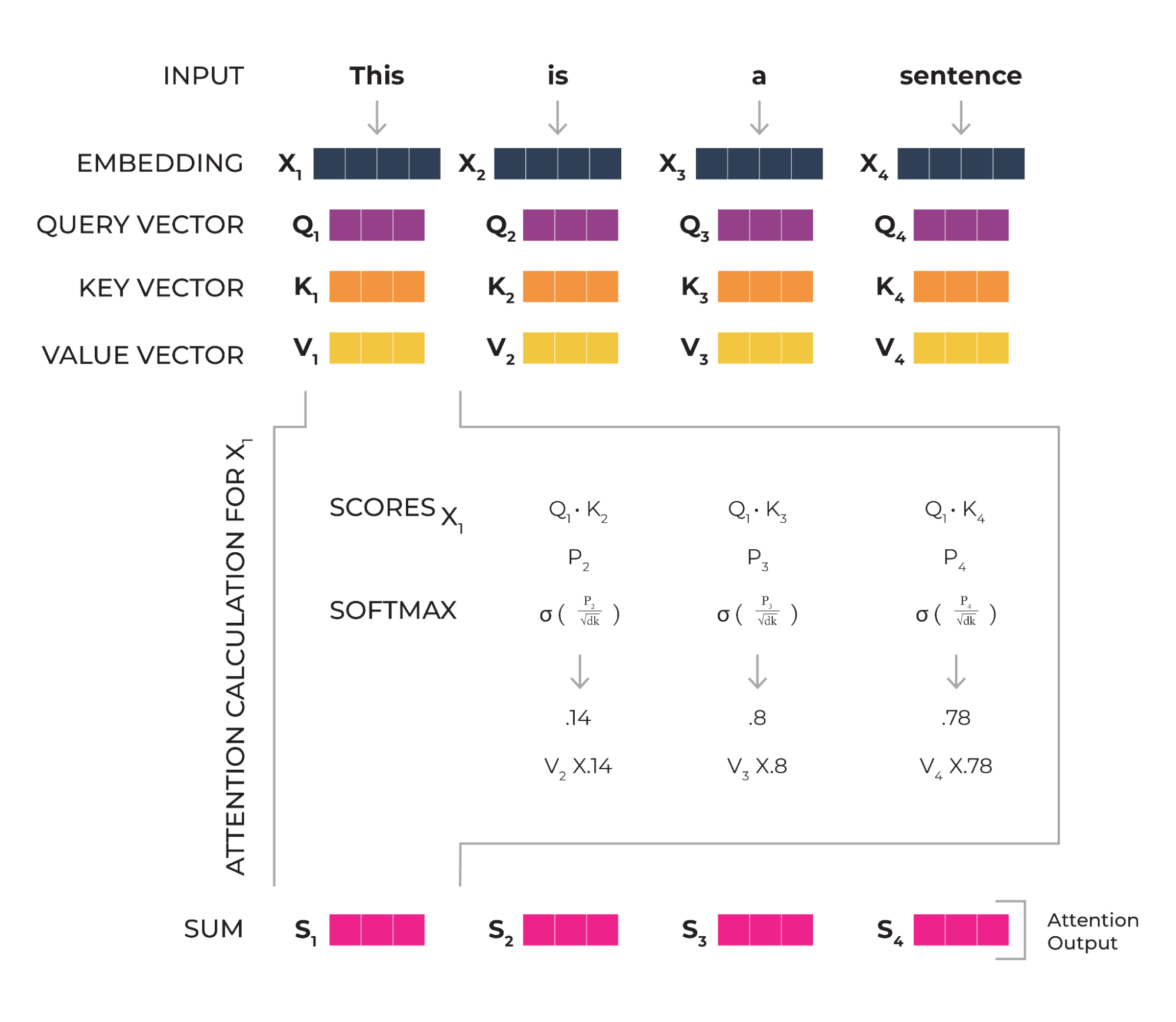
The process of self-attention
There are several common types of attention mechanisms used in machine learning, particularly in natural language processing tasks. These include soft attention, hard attention, self attention, global attention, and local attention. Let’s dive into each.
Soft Attention
Soft attention assigns continuous weights to input elements, allowing the model to attend to multiple elements simultaneously. Soft attention mechanisms are differentiable, which makes them easier to optimize using gradient-based techniques. These mechanisms have been widely adopted in various deep learning applications, such as neural machine translation, where the model learns to weigh the importance of each word in the input sentence when generating the target translation. Soft attention computes a weighted sum of input elements, where the weights are typically obtained by applying a softmax function to the attention scores.
Hard Attention
Hard attention is an attention mechanism that selects a subset of input elements to focus on, while ignoring the rest. It works by learning to make discrete decisions on which input elements are most relevant for a given task. For instance, in image captioning, hard attention may select specific regions of the image that are most relevant for generating the caption. One of the main challenges with hard attention is that it is non-differentiable, which makes it difficult to optimize using gradient-based methods like backpropagation. To address this, researchers often resort to techniques like reinforcement learning or the use of surrogate gradients.
Self-Attention
Self attention, also known as intra-attention, is an attention mechanism where the model attends to different parts of the input sequence itself, rather than attending to another sequence or a different modality. This mechanism surged in popularity through its use in the transformer architecture, which shows remarkable performance across various natural language processing tasks. In self attention, the model learns to relate different positions of the input sequence to compute a representation of the sequence. This allows the model to capture long-range dependencies and contextual information, leading to improved performance in tasks such as language modeling, machine translation, and text summarization.
Global Attention
Global attention mechanisms focus on all elements of the input sequence when computing attention weights. In this approach, the model computes a context vector by taking a weighted sum of all input elements, where the weights are determined by the attention scores. Global attention is widely used in sequence-to-sequence models, such as those used for machine translation, where the model must attend to all words in the input sentence to generate a coherent translation. One of the benefits of global attention is that it allows the model to capture long-range dependencies and global context, which can be crucial for understanding and generating complex structures.
Local Attention
Local attention mechanisms focus on a smaller, localized region of the input sequence when computing attention weights. Instead of attending to all input elements, the model learns to select a specific region or window around the current position, and computes attention weights only within that region. This can be advantageous in situations where the relevant information is located in a specific, local context, such as when processing time series data or text with strong locality properties. Local attention can also be computationally more efficient than global attention, as it reduces the number of attention computations required, making it suitable for applications with large input sequences or limited computational resources.
What are the Benefits?
Attention mechanisms have demonstrated a multitude of benefits in the realm of machine learning. One of the most notable advantages is the improved performance they bring to tasks such as natural language processing, image recognition, and speech recognition. By allowing the model to selectively focus on important elements, attention mechanisms enhance the accuracy and effectiveness of these tasks.
Moreover, attention helps overcome the limitations of fixed-length encoding, enabling models to work with longer input sequences and maintain relevant information. This ability is crucial when dealing with complex patterns or large amounts of data. Additionally, attention mechanisms often produce interpretable results, as the attention weights provide insights into which parts of the input the model considers important. This interpretability facilitates a deeper understanding of the model’s decision-making process, fostering trust and improving debugging efforts.
Finally, attention mechanisms, particularly local attention, can improve computational efficiency by reducing the scope of the context that the model needs to consider. This reduction allows for faster processing times without sacrificing the quality of the output. Overall, attention mechanisms have contributed significantly to advancements in machine learning, leading to more robust, efficient, and interpretable models.
When and Where To Use
Attention mechanisms have proven valuable in a wide range of applications, but knowing when to use them is essential for optimizing their benefits. Here are some scenarios where incorporating attention mechanisms may be particularly advantageous:
- Sequence-to-sequence tasks: Attention is especially useful in sequence-to-sequence tasks, such as machine translation, speech recognition, and summarization. In these cases, attention allows the model to selectively focus on relevant parts of the input sequence, leading to better context-aware outputs.
- Handling long sequences: When working with long input sequences or complex patterns, attention mechanisms can help overcome the limitations of traditional fixed-length encoding. By enabling the model to focus on specific elements, attention mechanisms can maintain critical information and improve overall performance.
- Tasks requiring context-aware processing: Attention is beneficial in tasks that demand context-aware processing, such as natural language processing or image captioning. By weighing the importance of different elements within the input sequence, attention mechanisms allow models to make more informed decisions based on the broader context.
- Interpretability and explainability: When it is essential to understand the decision-making process of a model, attention mechanisms can provide valuable insights. By highlighting which parts of the input the model focuses on, attention weights can offer a clearer understanding of how the model arrives at its conclusions.
- Computational efficiency: In cases where reducing computational requirements is a priority, local attention mechanisms can be employed. By focusing on a smaller, fixed-size window around the current element, local attention reduces the computational burden while still providing context-aware processing.
While attention mechanisms can be beneficial in these scenarios, it is essential to consider the specific requirements and constraints of the task at hand. Attention mechanisms can add complexity to a model, and in some cases, simpler architectures may suffice. Therefore, it is crucial to carefully evaluate the trade-offs between model complexity, computational demands, and the benefits of attention before incorporating these mechanisms into your machine learning models.
Summary
Attention mechanisms have proved to be a valuable addition to the field of machine learning, enhancing model performance and interpretability in various tasks. By understanding the different types of attention and their benefits, researchers and practitioners can continue to push the boundaries of what machine learning models can achieve.