

Explore and Monitor Your Modern Deep Learning Models
First-of-its-kind ML observability for unstructured data – monitoring, pattern identification, and targeted improvement for any generative, NLP, and computer vision model.
Embedding Drift Monitoring for Generative, NLP, CV
Quickly detect whether unexpected behaviors are occurring in your unstructured datasets, such as NLP and images, by monitoring model embedding drift.
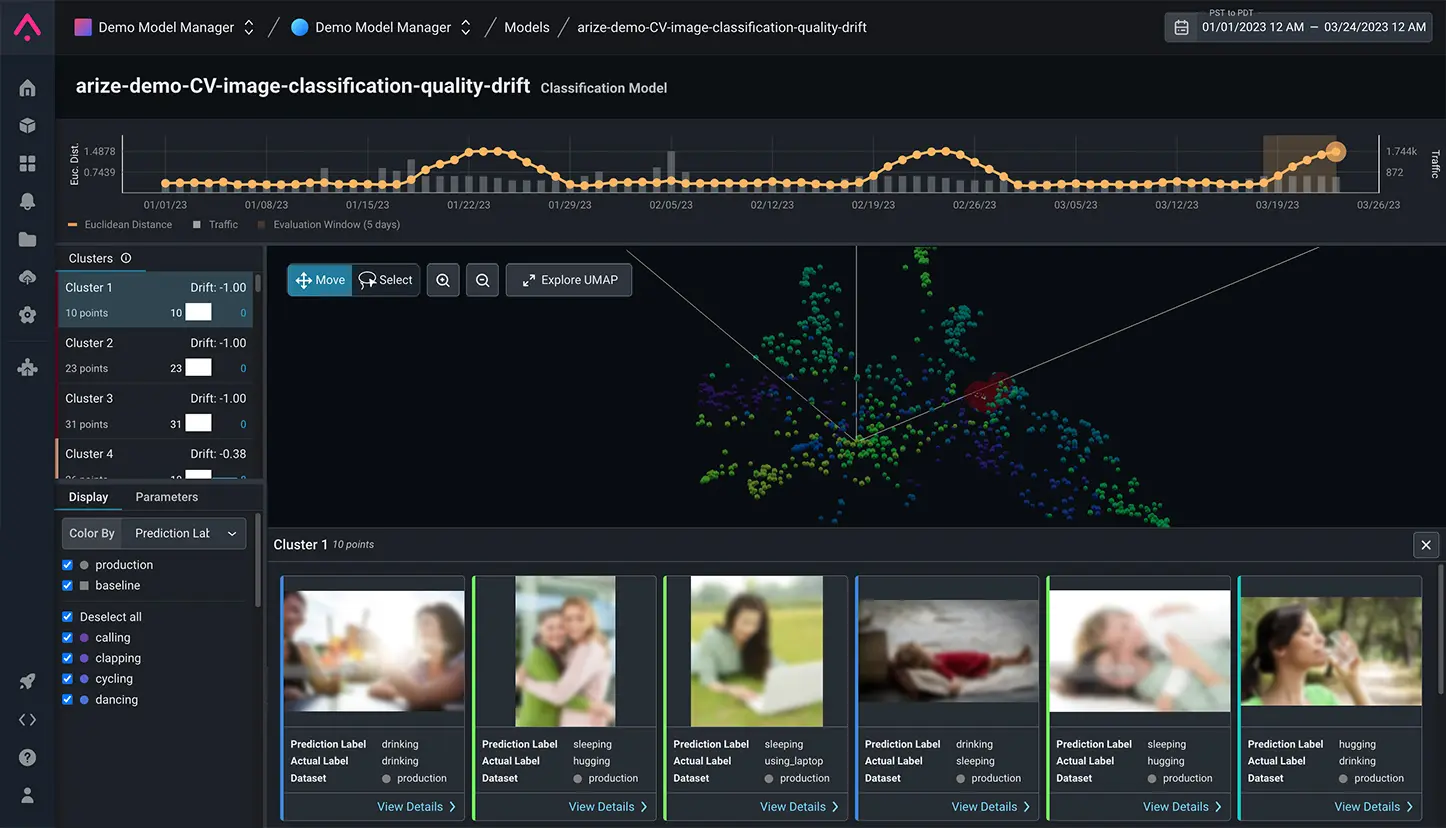

Explore 2D and 3D UMAP Visualizations
Interact with UMAP visualizations to help you deeply explore single or multiple model datasets.
By plotting training and production embeddings, you can uncover new patterns emerging that were not present in training.
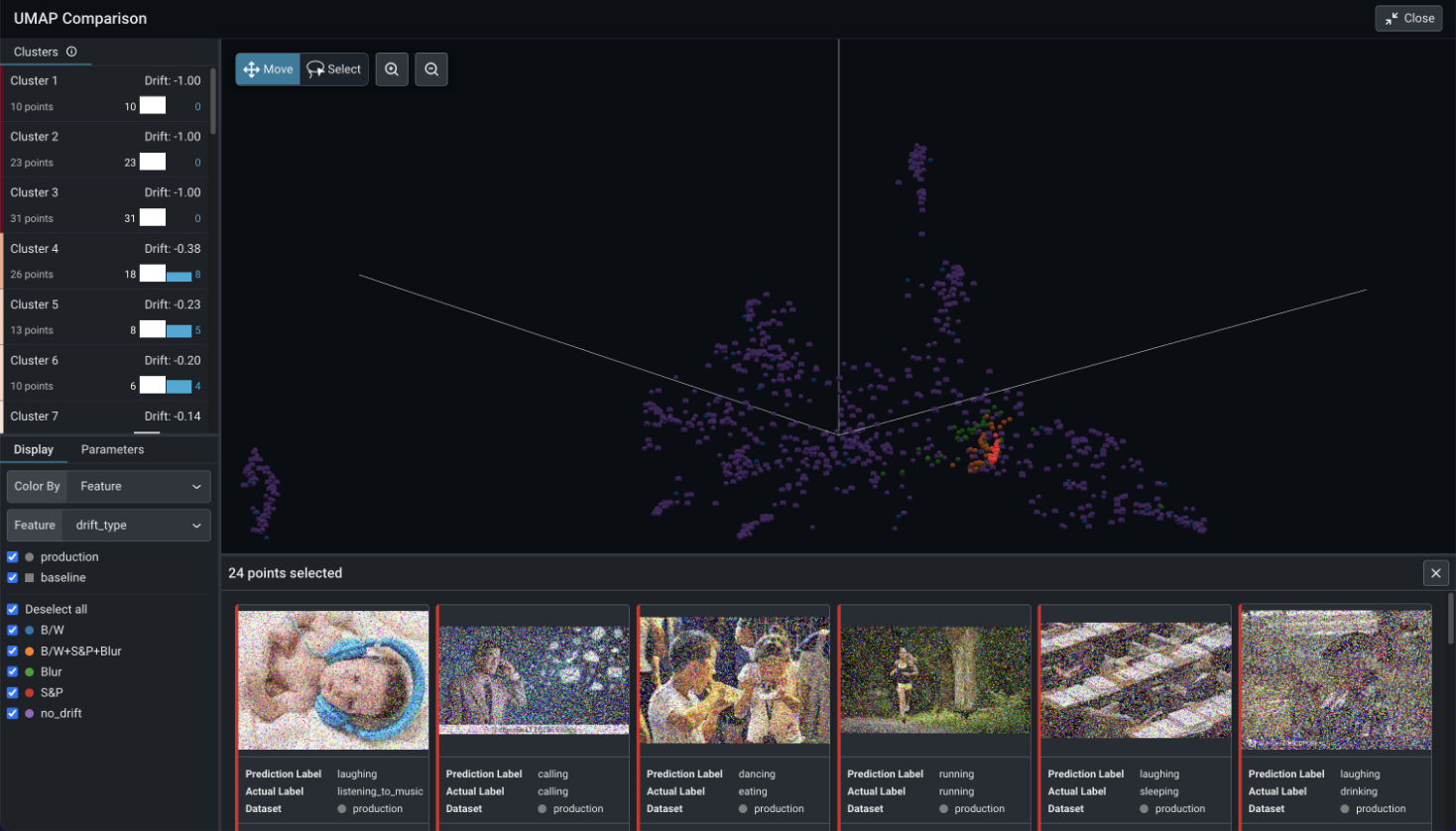


Uncover Clusters of Interest
Automatically surface clusters of data points that differ between your primary and baseline datasets. Configure UMAP parameters to further refine these clusters.
Colorize or filter by feature, prediction label, or correctness, to help you identify patterns or structures in the data, such as mislabeled product reviews, to narrow in on areas to improve.


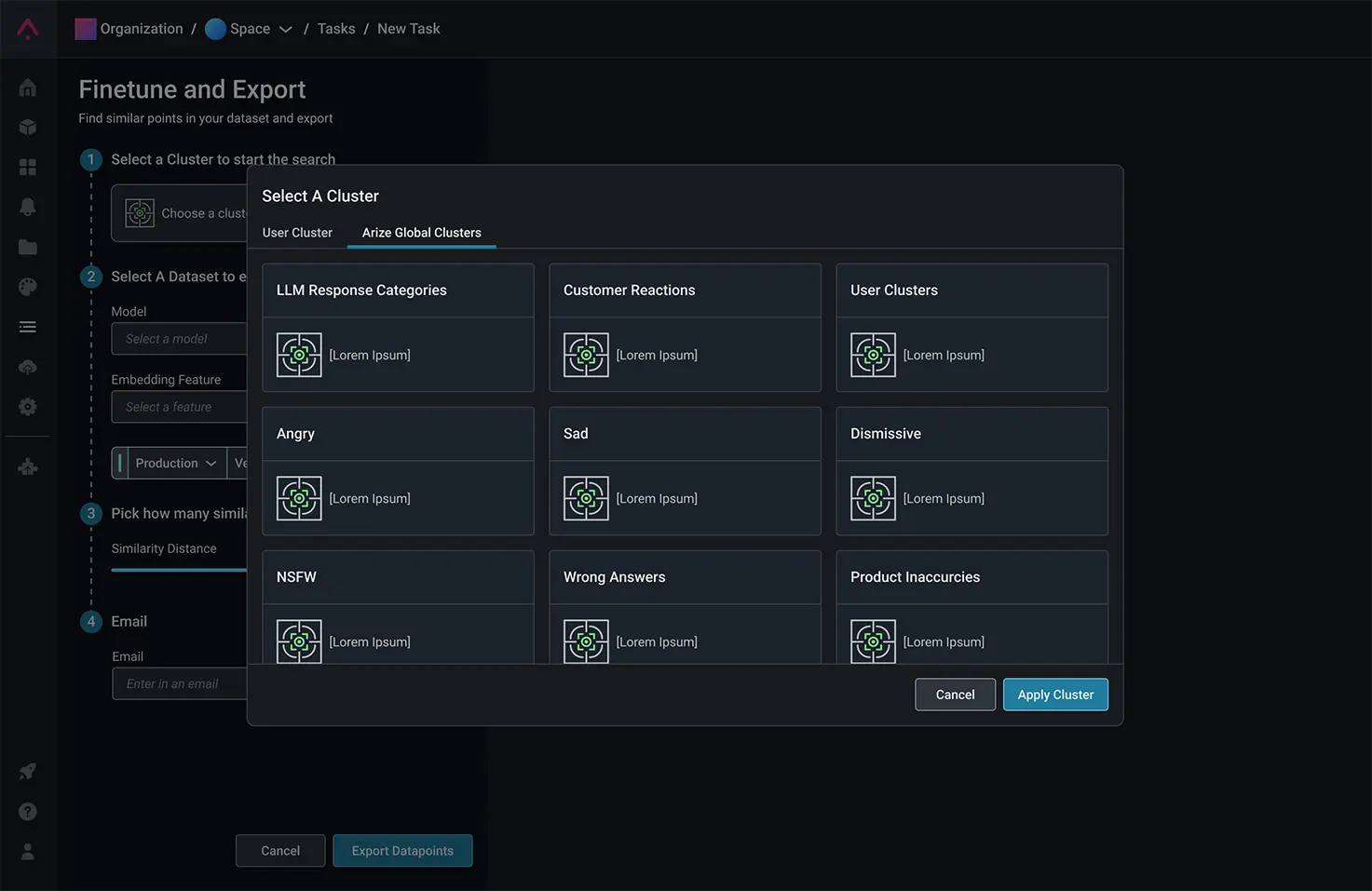
Export for Fine-Tuning
Save and export problem clusters – such as pixelated images, new languages, or problematic responses – for high-value relabeling.


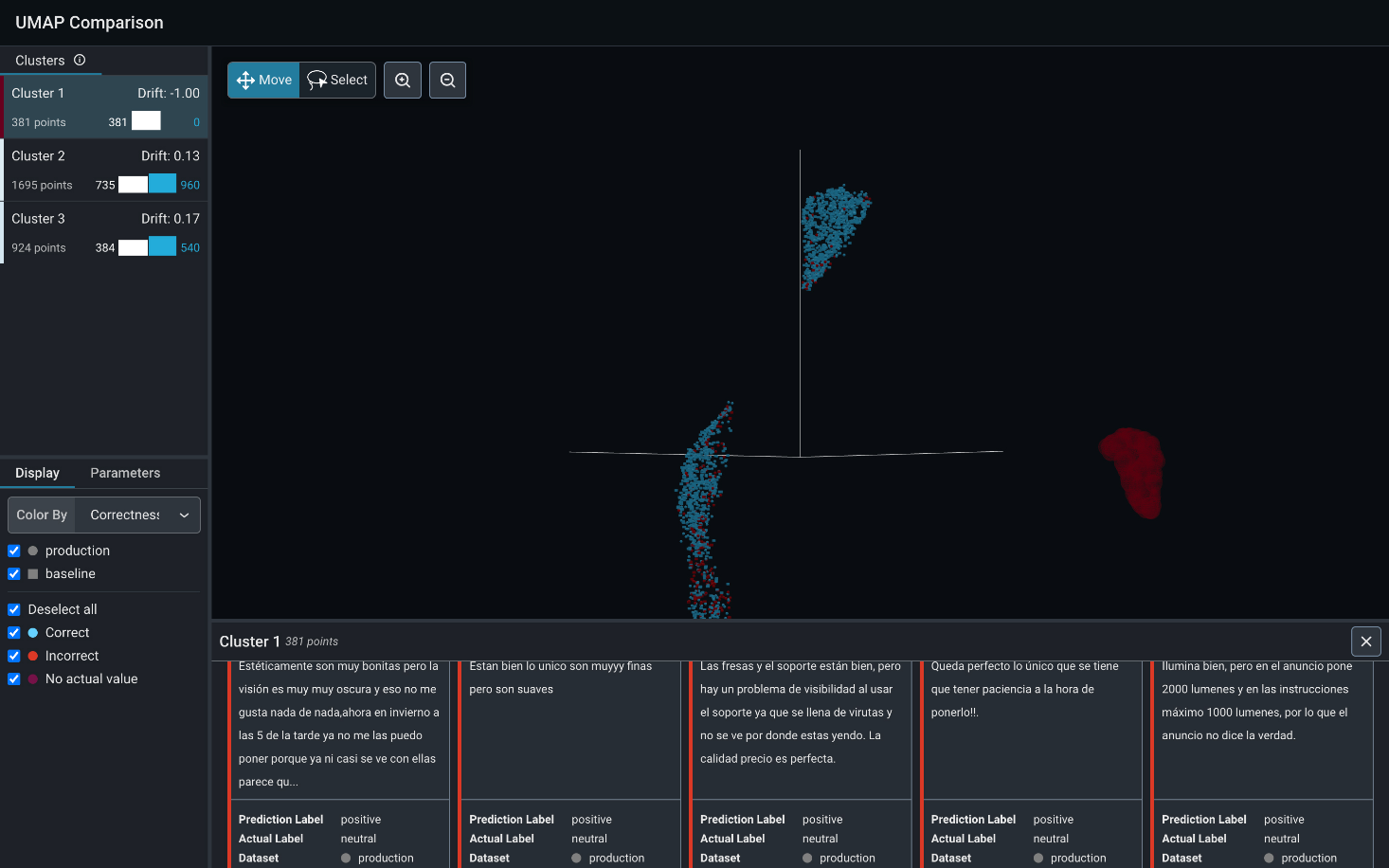
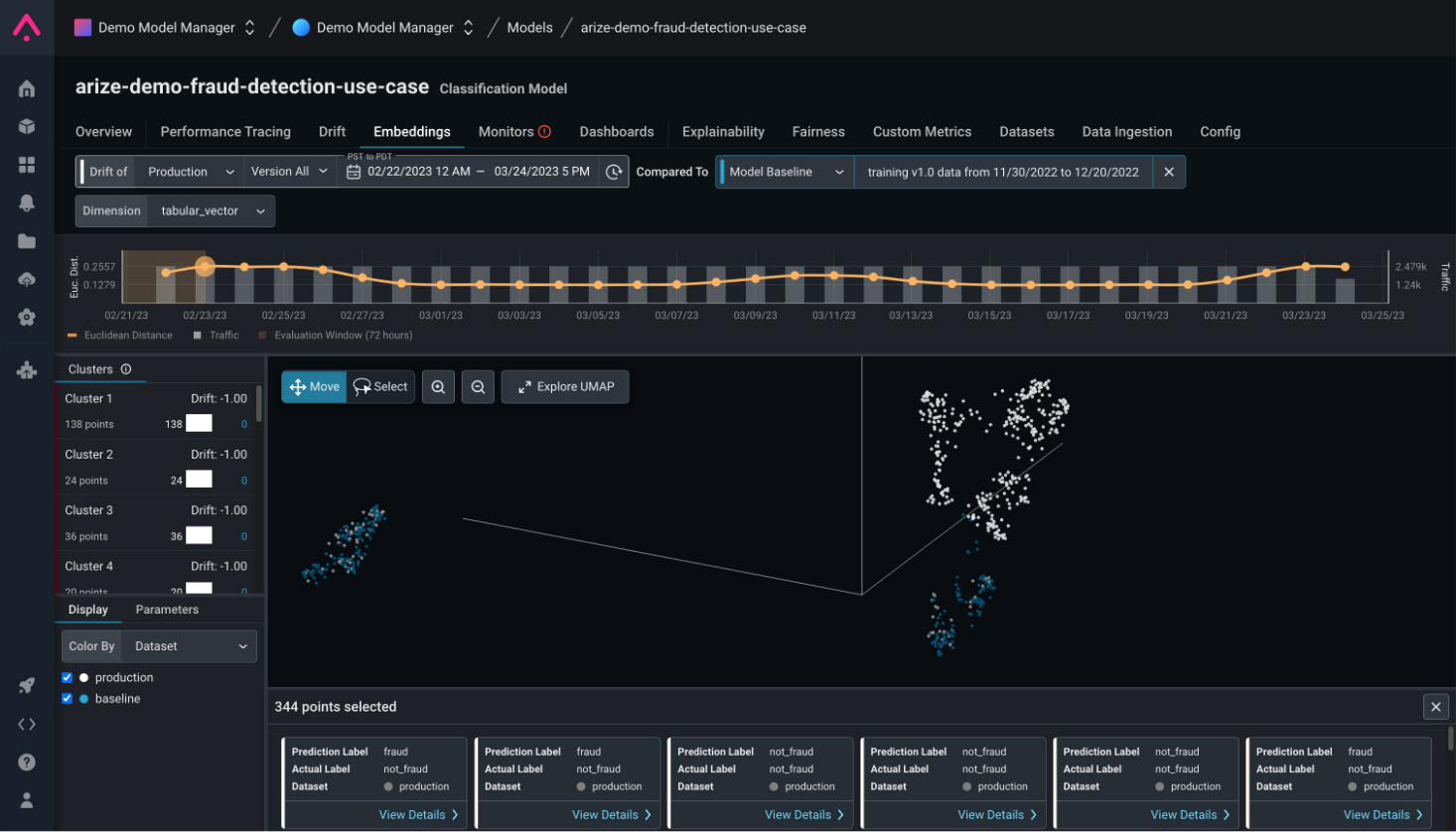
Multi-variate Anomaly Drift for Tabular Data
Uncover patterns and insights for tabular datasets that may not be intuitive when monitoring a single feature.
Catch issues across combinations of features in a single view using embeddings for tabular data.


Auto-Embeddings Generation
With the Arize SDK, you can offload the task of generating embeddings.
Simply pass through your input, and the generator will extract embeddings in the approach best suited for your use case – including word embeddings, auto-encoder, and GAN.
from arize.pandas.embeddings import EmbeddingGenerator, UseCases
generator = EmbeddingGenerator.from_use_case(
use_case=UseCases.CV.IMAGE_CLASSIFICATION,
model_name=”google/vit-base-patch16-224-in21k”,
batch_size=100
)
df[“image_vector”] = generator.generate_embeddings(
local_image_path_col=df[“local_path”]
)


Recommended resources









