

Resource Hub

How to evaluate AI agents, avoid reward hacking, and build better specs
Agent evals are repeatable tests that score whether AI agents completed a task correctly. Learn how to design rubrics, test suites, and trace-based evals that catch failures and prevent reward hacking.
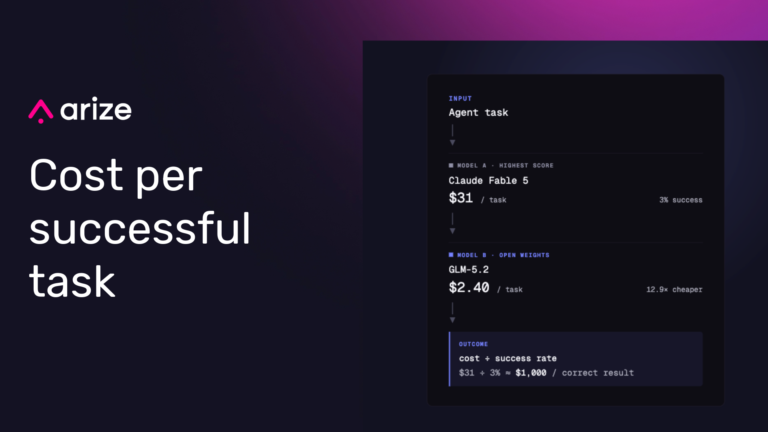
Model subsidies are ending. What do you do now?
Flat-rate AI plans are subsidizing agentic workloads. Learn why LLM inference costs are moving to metered pricing and how evals reveal cost per successful task.

AI evals are a data science problem: What most teams get wrong
Hamel Husain explains why the best AI teams treat LLM judges like classifiers, not dashboards.

Trace and evaluate TrueFoundry AI Gateway traffic in Arize AX
Learn how TrueFoundry AI Gateway exports OpenTelemetry traces to Arize AX so teams can trace, evaluate, and monitor production LLM and agent traffic without embedding a vendor SDK in every service.

Looking for a Langfuse alternative? Here’s when teams move to Arize

Long-horizon agent benchmarks are fragmenting: a field guide to what each one actually measures
A field guide to the new wave of long-horizon agent benchmarks: what each one actually measures, the realism-versus-verifiability bargain it strikes, and the seam where its score leaks.

Project Rosetta Stone: a reference implementation for instrumenting agents in any framework
We've fielded the same question at every conference this year. An engineer has chosen a framework, CrewAI one week, LangGraph the next, Mastra the week after, and wants to see exactly how observability plugs into the one they picked. OpenInference defines the span vocabulary, the
Swarm Management
LLM Tracing

Mean Absolute Percentage Error (MAPE): What You Need To Know
What Is Mean Absolute Percentage Error? One of the most common metrics of model prediction accuracy, mean absolute percentage error (MAPE) is the percentage equivalent of mean absolute error (MAE). Mean...

Why AI token costs don’t tell you if your AI is working
Token spend does not prove AI is creating value. Teams need cost-per-outcome metrics that connect AI usage to resolved tickets, accepted code, shipped features, and other business results.
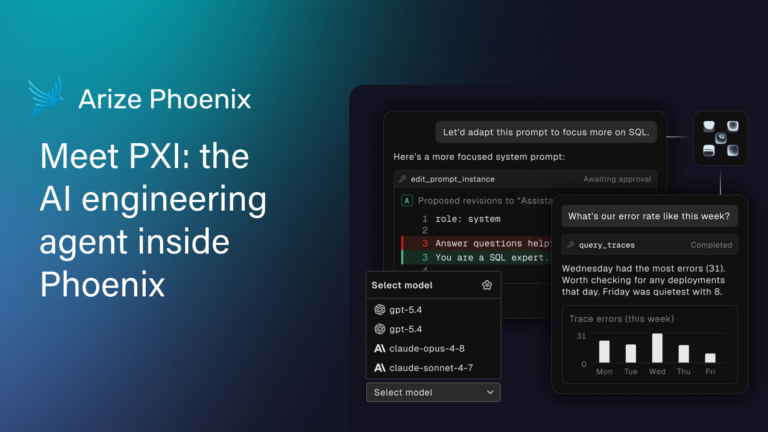
Meet PXI: the AI engineering agent inside Phoenix
An AI engineering agent built into Phoenix. It works like a coding agent, just point it at your telemetry instead of a source tree.
No results found. Try a different filter or search term.