
This piece is co-authored by Ilya Reznick

For a moment, imagine a person you would consider generally physically fit. What does that person look like? Now imagine a personal trainer at your local gym and a sumo wrestler. Both are athletes, yet probably only the instructor matches your image of general fitness. They look different because their bodies have been trained for different activities.
With the rise of large language models (LLMs), we have seen our first truly general-purpose machine learning models. Their generality helps us in so many ways:
- The same engineering team can now do sentiment analysis and structured data extraction
- Practitioners in many domains can share knowledge, making it possible for the whole industry to benefit from each other’s experience
- There is a wide range of industries and jobs where the same experience is useful
But as we see with fitness, generality requires a very different assessment from excelling at a particular task, and at the end of the day business value comes from solving particular problems.
This is a good analogy for the difference between LLM model evaluations and task evaluations, often abbreviated as “evals.” Model evaluations are focused on overall general assessment, but task evaluations are focused on assessing performance of a particular task.
There Is More Than One LLM Eval
evals are surprisingly often all you need
— Greg Brockman (@gdb) December 9, 2023
The terms LLM evaluations and LLM evals are thrown around quite generally. OpenAI released some tooling to do LLM evals very early, for example. Their tooling was aimed at LLM model evals. In practice, most practitioners are more concerned with LLM task evaluations but that distinction is frequently not clearly made and can lead to confusion as a result.
What Is the Difference Between LLM Model Evaluations and LLM Task Evaluations?
Model evaluations look at the “general fitness” of the model (how well does it do on a variety of tasks?), while LLM task evaluations are specifically designed to look at how well the model is suited for a particular application.
Similar to how someone who works out and is quite fit generally would likely fare poorly against a professional sumo wrestler in a real competition, model evaluations are often poorly suited compared to task evaluations in assessing your particular needs.
When Should Developers Use Model Evaluations?
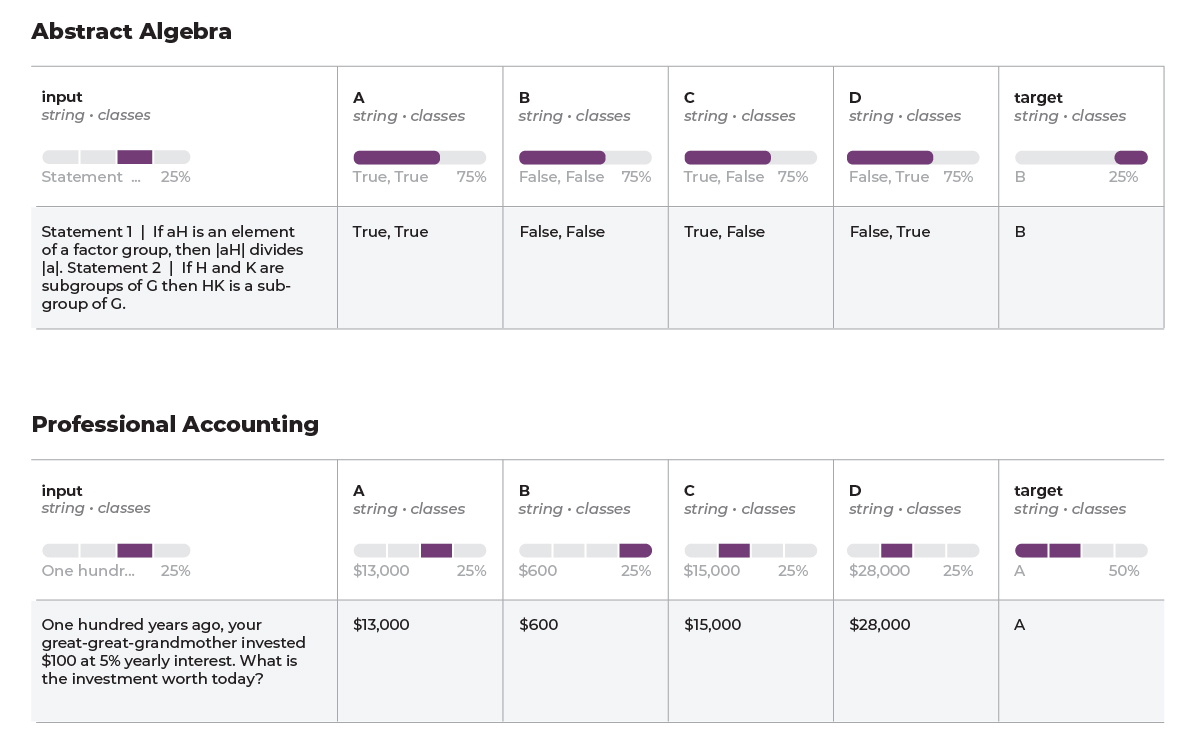
While every question in a model evaluation is different, there is usually a general area of testing. There is a theme or skill that each metric is specifically targeting. For example, HellaSwag performance has become a popular way to measure LLM quality.
The HellaSwag dataset consists of a collection of contexts and multiple-choice questions where each question has multiple potential completions. Only one of the completions is sensible or logically coherent, while the others are plausible but incorrect. These completions are designed to be challenging for AI models, requiring not just linguistic understanding but also common sense reasoning to choose the correct option.
Here is an example:
A tray of potatoes is loaded into the oven and removed. A large tray of cake is flipped over and placed on counter. a large tray of meat
- is placed onto a baked potato
- ls, and pickles are placed in the oven
- is prepared then it is removed from the oven by a helper when done.
Another example is MMLU. MMLU features tasks that span multiple subjects, including science, literature, history, social science, mathematics, and professional domains like law and medicine. This diversity in subjects is intended to mimic the breadth of knowledge and understanding required by human learners, making it a good test of a model’s ability to handle multifaceted language understanding challenges.
Here are some examples—can you solve them?
For which of the following thermodynamic processes is the increase in the internal energy of an ideal gas equal to the heat added to the gas?
- Constant Temperature
- Constant Volume
- Constant Pressure
- Adiabatic
The Hugging Face Leaderboard is perhaps the best known place to get such model evaluations. The leaderboard tracks open source large language models and keeps track of many model evaluation metrics. This is typically a great place to start understanding the difference between open source LLMs in terms of their performance across a variety of tasks.
Multimodal models require even more evals. The Gemini paper demonstrates that multi-modality introduces a host of other benchmarks like VQAv2, which tests the ability to understand and integrate visual information. This information goes beyond simple object recognition to interpreting actions and relationships between them.
Similarly, there are metrics for audio and video information and how to integrate across modalities.

The goal of these tests is to differentiate between two models or two different snapshots of the same model. Picking a model for your application is important, but it is something you do once or at most very infrequently.
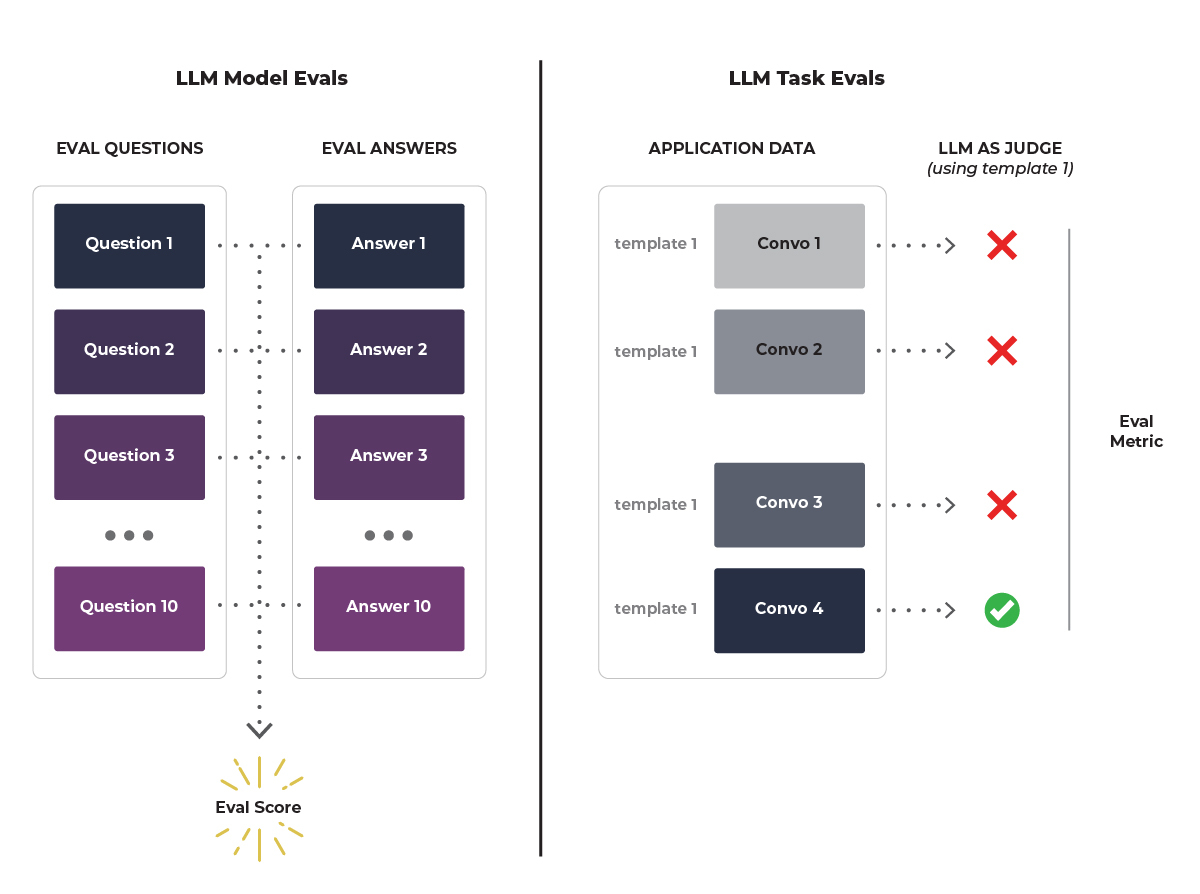
When Should AI Engineers Use Task Evaluations?
LLM task evaluations are needed before any production deployment of an LLM application to ensure effectiveness at performing specialized tasks. With a goal of analyzing the performance of the model using LLM as a judge, task-based evaluations are solving a the most frequent problem faced by AI engineers and answering questions like:
- Did your retrieval system fetch the right data?
- Are there hallucinations in your responses?
- Did the system answer important questions with relevant answers?
Some may feel a bit unsure about an LLM evaluating other LLMs, but we have humans evaluating other humans all the time. The real distinction between model and task evaluations is that for a model evaluation we ask many different questions, but for a task evaluation the question stays the same and it is the data we change. For example, say you areoperating a chatbot. You could use your task evaluation on hundreds of customer interactions and ask it, “Is there a hallucination here?” The question stays the same across all the conversations.
There are several libraries aimed at helping practitioners build these evaluations such as Ragas, Phoenix, OpenAI, and LlamaIndex.
How Do LLM Task Evaluations Work?
The task eval grades performance of every output from the application as a whole. Let’s look at what it takes to put one together.
Establishing a Benchmark
The foundation of effective task evaluations lies in establishing a robust benchmark. This starts with creating a golden dataset that accurately reflects the scenarios the LLM will encounter. This dataset should include ground truth labels, often derived from meticulous human review, to serve as a standard for comparison. Don’t worry, though — you can usually get away with dozens to hundreds of examples here. Selecting the right LLM for evaluation is also critical. While it may differ from the application’s primary LLM, it should align with goals of cost-efficiency and accuracy.
Crafting the Evaluation Template
The heart of the task evaluation process is the evaluation template. This template should clearly define the input (like user queries and documents), the evaluation question (such as the relevance of the document to the query), and the expected output formats (binary or multi-class relevance). Adjustments to the template may be necessary to capture nuances specific to your application, ensuring it can accurately assess the LLM’s performance against the golden dataset.
Here is an example of a good template to evaluate Q&A tasks.

Metrics and Iteration
Running the evaluation across your golden dataset allows you to generate key metrics such as accuracy, precision and recall as well as F-score. These metrics provide insight into the evaluation template’s effectiveness and highlight areas for improvement. Iteration is crucial; refining the template based on these metrics ensures the evaluation process remains aligned with the application’s goals without overfitting to the golden dataset.
In task evaluations, relying solely on overall accuracy is insufficient since we always expect significant class imbalance. Precision and recall offer a more robust view of the LLM’s performance, emphasizing the importance of identifying both relevant and irrelevant outcomes accurately. A balanced approach to metrics ensures that evaluations meaningfully contribute to enhancing the LLM application.
Application of LLM Task Evaluations
With a proven evaluation framework in place, the next step is to apply these evaluations directly to your LLM application. This involves integrating the evaluation process into the application’s workflow, allowing for real-time assessment of the LLM’s responses to user inputs. This continuous feedback loop is invaluable for maintaining and improving the application’s relevance and accuracy over time.
Evaluation Across the System Lifecycle
Effective task evaluations are not confined to a single stage but are integral throughout the LLM system’s life cycle. From pre-production benchmarking and testing to ongoing performance assessments in production, evaluations ensure the system remains responsive to user need.
Example: Is a Model Hallucinating?
Let’s look at a hallucination example in more detail.

Datasets
Since hallucinations are a common problem for most practitioners, there are some benchmark datasets available. These are a great first step, but you will often need to have a customized dataset within your company.
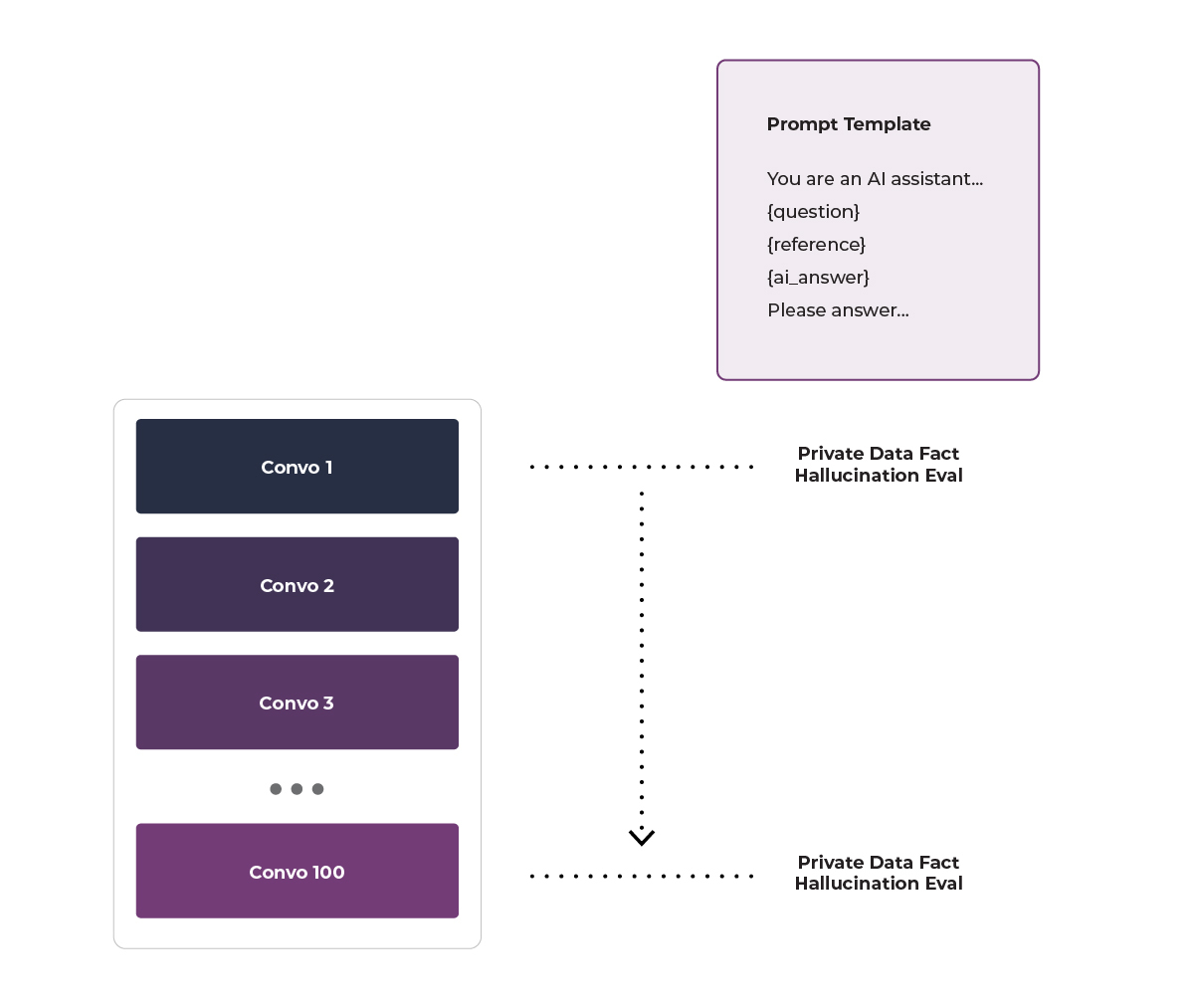
Prompt Template
The next important step is to develop the prompt template. Here again a good library can help you get started. We saw an example prompt template earlier, here we see another specifically for hallucinations. You may need to tweak it for your purposes.

Benchmark Performance
Now you are ready to give your evaluation LLM the queries from your golden dataset and have it label hallucinations. When you look at the results, remember that there should be class imbalance. You want to track precision and recall instead of overall accuracy.
It is very useful to construct a confusion matrix and plot it visually. When you have such a plot, you can feel reassurance about your LLM’s performance. If the performance is not to your satisfaction, you can always optimize the prompt template.

What Happens After an LLM Task Evaluation Is Built?
After the eval is built, you now have a powerful tool that can label all your data with known precision and recall. You can use it to track hallucinations in your system both during development and production phases.
Recap: Differences Between LLM Model Evaluations and LLM Task Evaluations
Let’s sum up the differences between task and model evaluations:
| Category | Model Evaluations | Task Evaluations |
| Foundation of Truth | Relies on benchmark datasets. | Relies on the golden dataset curated by internal experts and augmented with LLMs. |
| Nature of Questions | Involves a standardized set of questions, ensuring a broad evaluation of capabilities. | Utilizes unique, task-specific prompts, adaptable to various data scenarios, to mimic real-world scenarios. |
| Frequency and Purpose | Conducted as a one-off test to grade general abilities, using established benchmarks. | An iterative process, applied repeatedly for system refinement and tuning, reflecting ongoing real-world applications. |
| Value of Explanations | Explanations don’t typically add actionable value; focus is more on outcomes. | Explanations provide actionable insights for improvements, focusing on understanding performance in specific contexts. |
| Persona | LLM researcher evaluating new models and ML practitioner selecting a model for her application. | ML practitioner throughout the lifetime of the application. |
Conclusion
Ultimately, both model evaluations and task evaluations are important in putting together a functional LLM system but it is important to understand when and how to apply each. For most practitioners, the majority of their time will be spent on task evals, which provide a measure of system performance on a specific task.