


Written in collaboration with Aman Khan
Structured Data Extraction with OpenAI Function Calling
Structured data extraction is not a new topic in the world of AI; machine learning engineers have been using various techniques to gain insight out of unstructured data since companies first started collecting videos, photos, music, and emails. In fact, the IDC (International Data Corporation) projects that by 2025, the datasphere will amount to 175 zettabytes – with 80% of that data being unstructured! While that number is staggering, a majority of the data stored by companies (as much as 99%) remains unanalyzed. Several factors contribute to this, including data privacy regulations, cost (storage as well as compute), data quality issues and – most commonly – not knowing where to start with an overwhelming amount of data.
While this post does not contain the solution to many companies’ data hoarding, it does cover how the traditional use of unstructured data compares to how large language models (LLMs) perform structured data extraction.
Regardless of where LLMs are today and even if teams are not planning on using generative AI in production, the potential to scale structured data extraction with LLMs in the future will be powerful.
Using LLM functionality as a data preprocessing tool to extract structured data from unstructured sources means accessing more data to train all types of models for production.
Extracting Data from Unstructured Sources
As mentioned, the costs and intricacies involved in deciphering and analyzing unstructured data can be immense. This is also only worthwhile if assuming you house and store useful data. So how can you be sure that the data your company is hoarding is aligned with business objectives? The only way out is through.
Traditional Unstructured Techniques
To review, extracting structured information from unstructured data is a common problem in data analysis, machine learning, and natural language processing. The exact methods and tools used depend on the use case in question, as well as exactly what data you are working with. For example, the most common strategy for extracting keywords from text data is Regular Expressions (Regex). It is rather baffling how fast we all went from using Regex to LLMs! In addition to Regex for text data extraction, natural language processing (NLP) techniques like Named Entity Recognition (NER) and Latent Dirichlet Allocation (LDA) have also been used to extract entities and determine the main topics via Topic Modeling respectively.
While there are many different methods for extracting text from images (object detection, image segmentation, optical character recognition) and audio (speech-to-text, Mel spectrograms, to name a few), this post only covers structured data extraction from written language to demonstrate the role of LLMs.
LLMs for Structured Data Extraction
While traditional text extraction methods are still used frequently, these approaches are starting to lose favor to LLMs due to their efficient and scalable approach to distill relevant data from unstructured text. While research is ongoing on whether or not LLMs are more cost efficient for data extraction tasks (such as scraping text from documents and pulling keywords from queries), it is clear that LLMs are built with comprehensive extraction capabilities. LLMs excel at intuitively grasping the intricacies of language, particularly on extracting structured data from unstructured text.
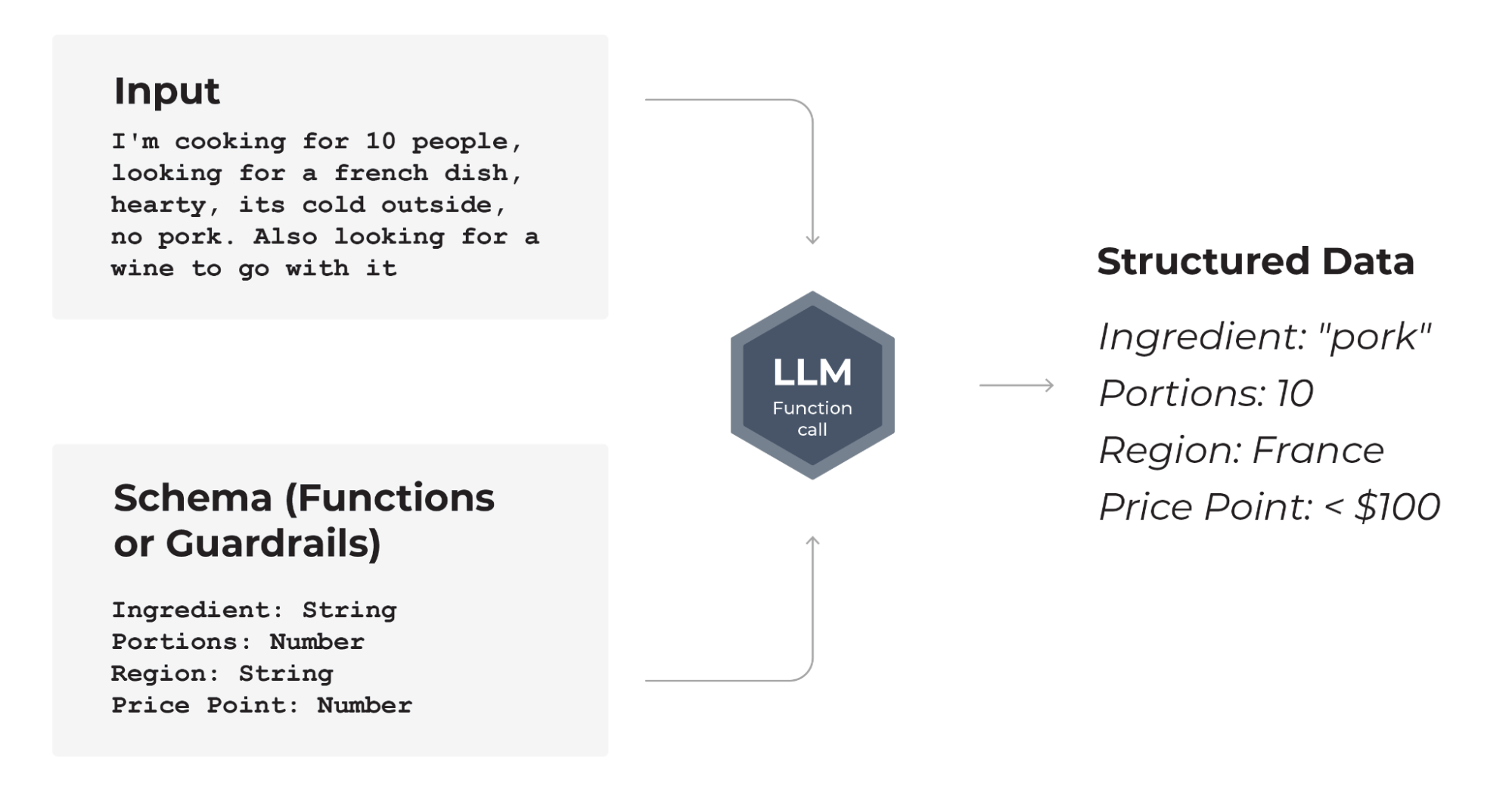
The example above shows how LLMs can efficiently convert unstructured text data into structured information. These extracted attributes can then be used to construct a structured query to find options that might be relevant to the user or enrich company databases for future model training.
Implementing a Structured Extraction Application with Arize Phoenix OSS
The OpenAI API is great for developers looking to build LLM applications with few lines of code. However, it was still difficult for developers to work with unstructured data (mostly strings) without either regular expressions (RegEx) or prompt engineering to extract the information from the text string. OpenAI recently released new OpenAI’s function calling capabilities for GPT-3.5 and GPT-4 models to take user-defined functions as input and generate structure output. With this, you don’t need to write RegEx or perform prompt engineering.
Arize Phoenix comes in as a way to instruct your OpenAI client to record trace data in OpenInference tracing format, inspect the traces and spans of your application to visualize your trace data, and export your trace data to run an evaluation on the quality of your structured extractions. Now, let’s see how to use OpenAI’s function calling feature to perform structured data extraction: the task of transforming unstructured input (e.g., user requests in natural language) into structured format (e.g., tabular format).
Structured extraction is a place where it’s simplest to work directly with the OpenAI function calling API. OpenAI functions for structured data extraction recommends providing the following JSON schema object in the form of parameters_schema (the desired fields for structured data output).
parameters_schema = {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": 'The desired destination location. Use city, state, and country format when possible. If no destination is provided, return "unstated".',
},
"budget_level": {
"type": "string",
"enum": ["low", "medium", "high", "not_stated"],
"description": 'The desired budget level. If no budget level is provided, return "not_stated".',
},
"purpose": {
"type": "string",
"enum": ["business", "pleasure", "other", "non_stated"],
"description": 'The purpose of the trip. If no purpose is provided, return "not_stated".',
},
},
"required": ["location", "budget_level", "purpose"],
}
function_schema = {
"name": "record_travel_request_attributes",
"description": "Records the attributes of a travel request",
"parameters": parameters_schema,
}
system_message = (
"You are an assistant that parses and records the attributes of a user's travel request."
)The ChatCompletion call to Open AI would look like:
response = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": travel_request},
],
functions=[function_schema],
# By default, the LLM will choose whether or not to call a function given the conversation context.
# The line below forces the LLM to call the function so that the output conforms to the schema.
function_call={"name": function_schema["name"]},
)One powerful feature of the OpenAI chat completions API is function calling, wherein a user describes the signature and arguments of one or more functions to the OpenAI API via a JSON schema and natural language descriptions, and the LLM decides when to call each function and provides argument values depending on the context of the conversation. In addition to its primary purpose of integrating function inputs and outputs into a sequence of chat messages, function calling is also useful for structured data extraction, since you can specify a “function” that describes the desired format of your structured output. Structured data extraction is useful for a variety of purposes, including ETL or as input to another machine learning model such as a recommender system.
While it’s possible to produce structured output without using function calling via careful prompting, function calling is more reliable at producing output that conforms to a particular format. For more details on OpenAI’s function calling API, see the OpenAI documentation.
Tracing Structured Data Extraction with LLMs in Phoenix
Now let’s go through a colab notebook: Tracing and Evaluating a Structured Data Extraction Application with OpenAI Function Calling (github).
You can use Phoenix spans and traces to inspect the invocation parameters of the function to verify:
- The inputs to the model in form of the the user message
- Your request to OpenAI
- The corresponding generated outputs from the model match what’s expected from the schema and are correct



Dive deeper into this tutorial to learn about:
- Using OpenAI’s function calling feature to perform structured data extraction: the task of transforming unstructured input (e.g., user requests in natural language) into structured format (e.g., tabular format),
- Instrumenting your OpenAI client to record trace data in OpenInference tracing format,
- Inspecting the traces and spans of your application to visualize your trace data,
- Exporting your trace data to run an evaluation on the quality of your structured extractions.
Topics include: OpenAI, structured data extraction, and function calling (note: This notebook requires an OpenAI API key).
Additional Evaluations for Structured Extraction with LLMs
When working with unstructured data, it’s important to have a clear understanding of the desired outcome, as the methods and tools you choose will depend on the specific task at hand. It’s also crucial to continuously evaluate and refine the extraction processes to ensure accuracy and relevancy.
Evals help you continuously understand your system’s performance after deployment. Evaluating LLM applications needs to take place across three environments: pre-production when you’re doing the benchmarking, pre-production when you’re testing your application and production when it’s deployed. Life is messy. Data drifts, users drift, models drift, all in unpredictable ways. Just because your system worked well once doesn’t mean it will do so on Tuesday at 7PM.

Remember that verifying correctness of extraction at scale or in a batch pipeline can be challenging and expensive. It is a best practice not to do LLM evals with one-off code but rather a library that has built-in prompt templates. This increases reproducibility and allows for more flexible evaluation where you can swap out different pieces.

Evaluating data extraction tasks performed by LLMs is challenging with these models being non-determinism and often not having “ground truths” for their language tasks; However, with careful monitoring and LLM observability using LLMs for structured data extraction can scale faster and perform better than any previously used methods.
Ready to dive deeper? Get certified in key areas like Traces and Spans or Agents, Tools, and Chains or ask questions on the Arize community. Additional learning resources on Arize Phoenix and LLM monitoring and observability.