




Getting To Know MLflow: a Comprehensive Guide to ML Workflow Optimization

Dat Ngo
AI Architect
What is the purpose of a model store in machine learning?
A model store serves as a centralized repository for machine learning models, streamlining storage, organization, and management. During the initial stages of developing machine learning models, practitioners may create and store models in various environments such as Jupyter notebooks or local workspaces. This scattered approach can make it challenging to track crucial information like performance metrics and experiment settings. A model store addresses this issue by providing a one-stop solution for storing and managing all machine learning models, enabling data scientists and machine learning engineers to quickly locate and utilize models for experimentation or deployment to production.
💡 I like to think of a model store as an organized bookshelf. In this case, the books are ML models where all the models are stored, organized, and managed in one neat and central location.
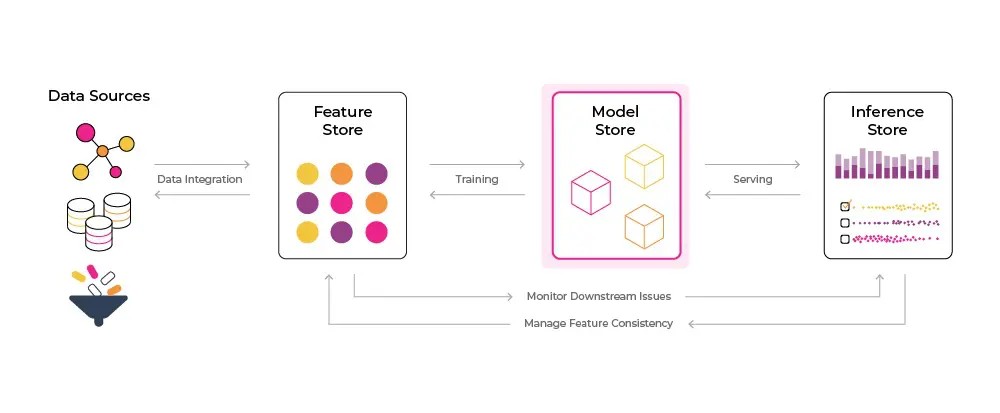
TL;DR on Model Store
- Central location to store all models, data and metadata about model experiments
- Helps facilitate going from experimentation to production more efficiently
What is MLflow and how can it improve machine learning workflows?
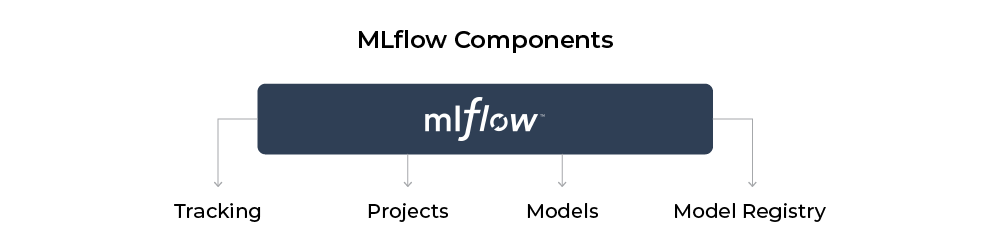
MLflow is a popular open-source platform tailored for the end-to-end machine learning lifecycle, designed to help data scientists and machine learning engineers optimize their workflows and enhance productivity. Developed by Databricks, MLflow comprises four main components: Tracking, Registry, Models, and Projects, each catering to a specific aspect of the machine learning pipeline.
In this guide, we will delve into the four main components of MLflow, exploring them in the order you would typically encounter when deploying a model from scratch. We will discuss the core concepts of each component and provide some tangible code examples and guides for a more hands on understanding.
TL;DR on MLflow
- Widely used open-source platform built by Databricks
- Used for experimentation, reproducibility, deployment, and a central model registry
- Four main components: Tracking, Models, Registry, Projects
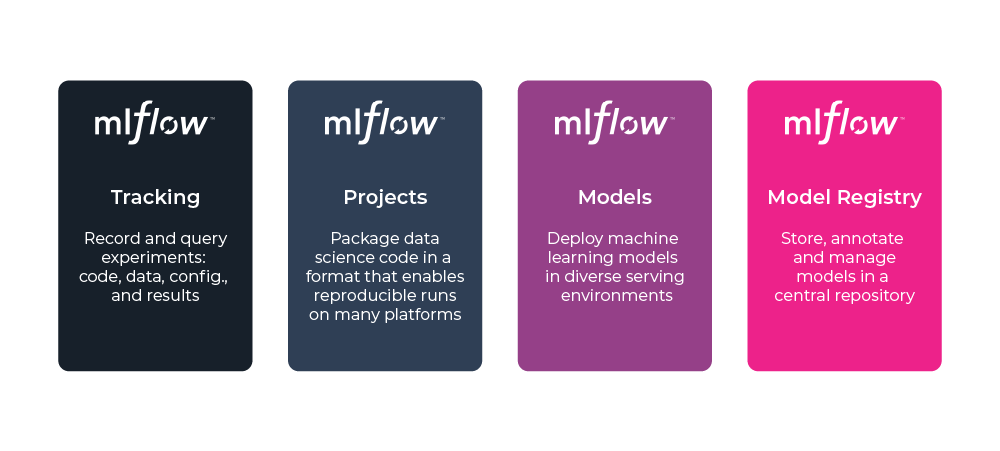
How does MLflow improve collaboration among data scientists and MLOps teams?
MLflow comes equipped with features – like version control, metadata management, and access control – that greatly simplify the process of creating and using machine learning models. By leveraging MLflow’s model store, teams can enhance collaboration, scale machine learning projects, and ensure efficient model management throughout their lifecycle.
What are the benefits of using MLflow Tracking for tracking and logging experiments?
MLflow Tracking is the first component of MLflow, providing a streamlined method for tracking and logging machine learning experiments. With MLflow Tracking, data scientists and machine learning engineers can effortlessly record and compare parameters, code versions, and output metrics from various experiments in a centralized location. This enables them to reproduce past experiments and compare the results of different models with ease.
MLflow Tracking also provides a set of APIs and integrations that make it easy to use with different machine learning frameworks and tools. It supports popular frameworks like TensorFlow, PyTorch, and Scikit-learn, as well as different storage backends like local files, Amazon S3, and Azure Blob Storage. This flexibility allows data scientists and machine learning engineers to use their favorite tools and environments while still benefiting from the tracking and management capabilities of MLflow Tracking. Additionally, MLflow Tracking integrates seamlessly with MLflow Projects and MLflow Registry, providing a cohesive platform for managing the entire machine learning lifecycle.
Beyond tracking experiments, MLflow Tracking allows users to organize and compare different runs effectively. Users can group runs by tags, compare metrics across various runs, and even view data visualizations.
TL;DR on MLflow Tracking
- Record and query experiments: code, data, config, and results
- Simplifies the process of tracking and comparing experiments
- Iterations can be faster and are better organized
How can MLflow Models streamline the process of deploying machine learning models?
MLflow Models, another component of the MLflow platform, focuses on packaging, deploying, and sharing machine learning models. With MLflow Models, practitioners can easily package their models in diverse formats, such as Python functions or Docker containers, and deploy them to various platforms, including local servers or cloud-based environments.
To package a model using MLflow Models, data scientists and machine learning engineers need to define a function that accepts input data and generates predictions based on the trained model. They can then employ the MLflow API to log the function as a model, which can be seamlessly deployed and served as a REST API or within a cloud-based environment.
MLflow Models also offers tools for versioning and managing models. Users can create multiple versions of their models and track changes over time, making it simple to revert to a previous version if necessary. Moreover, MLflow Models provides tools for managing dependencies and reproducibility, ensuring models can be effortlessly recreated in various environments.
Lastly, MLflow Models integrates with different platforms, such as Amazon SageMaker, Vertex, and Azure ML, facilitating easy deployment of models to diverse cloud-based environments. This enables data scientists and machine learning engineers to scale their models and make them accessible to other teams or customers.
TL;DR on MLflow Models
- Deploy machine learning models in diverse serving environments
- Streamlines the process of packaging, deploying, and managing ML models to common serving platform formats
What role does MLflow Registry play in version control and collaboration for machine learning models?
MLflow Registry is another component of the MLflow platform, which provides a centralized location for storing, managing, and sharing machine learning models. With MLflow Registry, data scientists and machine learning engineers can easily track and manage different versions of their models, as well as share them with other members of their team or organization.
To use MLflow Registry, data scientists and machine learning engineers first need to create a registry, either by using the MLflow API or by setting up a registry server. Once the registry is set up, they can then use MLflow Models to register their models in the registry, along with metadata such as model version, description, and the user who created it.
MLflow Registry also offers tools for managing access and permissions to different models. Data scientists and machine learning engineers can control who has access to different models and which operations they can perform on them, such as viewing, editing, or deploying.
One of the main benefits of MLflow Registry is that it enables version control and collaboration for machine learning models. Different members of a team can work on different versions of a model, and MLflow Registry allows them to easily track changes and collaborate on different versions. This makes it easier for teams to manage complex machine learning workflows and ensure that models are updated and improved over time.
TL;DR on MLflow Registry
- Store, annotate, discover, and manage models in a central repository
- Ensuring version control and collaboration across different teams and organizations.
How can MLflow Projects help package and share code, data, and environments across machine learning workflows?
Lastly, MLflow Projects offers a standardized method for packaging and sharing code, data, and environments across machine learning workflows. By using MLflow Projects, data scientists and machine learning engineers can organize their code into reproducible and shareable packages, facilitating seamless reproduction and collaboration on experiments.
To utilize MLflow Projects, users organize their machine learning code in a project directory, containing a project file that outlines the dependencies, entry points, and parameters of the project. The project file can be in either YAML or JSON format, enabling users to specify their code’s command-line arguments and the dependencies required for execution.
After defining the project, users can employ the MLflow CLI or API to run the project in various environments, such as local workstations, remote servers, or cloud platforms. MLflow Projects automatically tracks project runs and records their parameters, code versions, and output metrics, which can be viewed and compared using MLflow Tracking.
Additionally, MLflow Projects supports versioning and collaboration, allowing users to manage different project versions and share them with other practitioners. Users can store their projects in version control systems like Git and leverage MLflow Projects to reproduce, modify, and execute them in different environments.
TL;DR on MLflow Projects
- Package data science code in a format to reproduce runs on any platform
- Enable DS/MLEs to collaborate, refine and deploy their experiments efficiently
What are the steps to set up and use MLflow in a Jupyter notebook?
For this tutorial, we can get started with a local instance of MLflow, right from within your Jupyter notebook (you’ll want to run it locally and not from Google Colab). Here are the commands to get set up in your notebook.
First install MLflow
!pip install mlflowNext let’s kick off our MLflow UI
!mlflow uiYou should see something below, once you click the link to your locally hosted MFlow UI
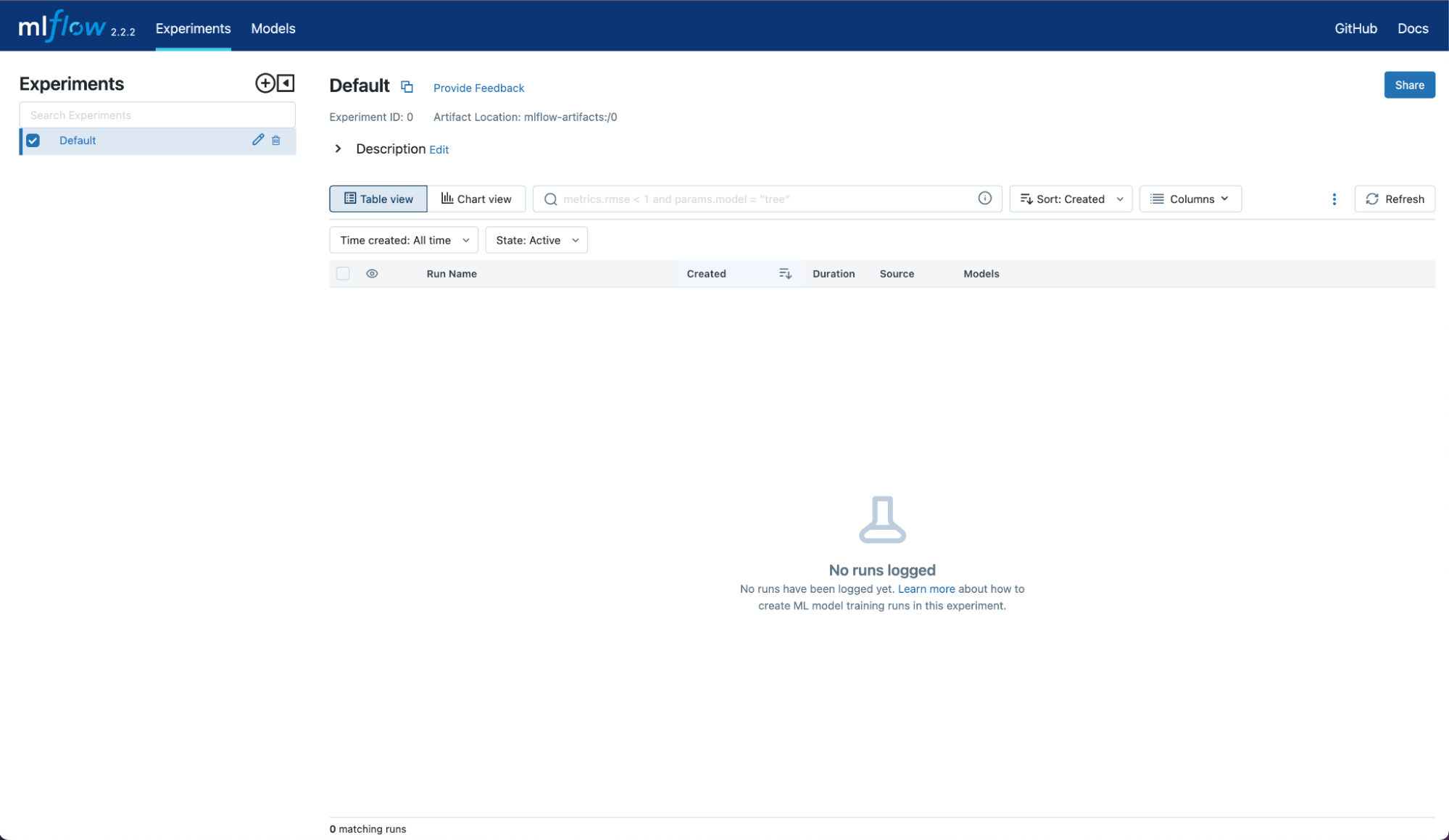
Once you have the MLflow UI open you can go back into your jupyter notebook, and run the following code
Below is a simple LogReg model to simply show how we can log training runs to our instance.
Example Code:
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
score = lr.score(X, y)
print("Score: %s" % score)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(lr, "model")
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)After running the above you should see that you’ve now logged a run into the UI. Congrats, you just tracked your first experiment run!

Want To Go Further?
If you want to go deeper, take a look at these in depth examples provided by MLflow:
Also, be sure to check out Arize + MLflow tutorial!
Questions? Feel free to reach out on the Arize community.

