


Overview
Model evaluation metrics to measure model performance is a broad subject that includes an immense number of performance metrics. A new metric can come to life in a recently published paper or can be discovered in practice as ML is applied to a new task in the real world.
This course attempts to do three things:
• Provide an intro to a set of the most popular performance metrics in data science
• Give insights and intuition around their use, based on practical experience
• Describe how to use and monitor these metrics in production environments
Data scientists use a large set of common metrics when they build and evaluate models. Model performance evaluation is about measuring model predictions (inferences) relative to how the model performs against ground truth. In the model building process, experiment tracking solutions are normally used to track performance metrics over multiple training and test runs. As models are deployed in the real world, ML monitoring and observability platforms are normally used to track performance over time.
Model Evaluation Metrics By Task
ML performance metrics are typically ML task-specific. Links to relevant course posts appear below (KEEP IN MIND: this is not comprehensive — please check back for updates as we fill this in!).
Tabular



Image






Language Models

Conversational

Fill Mask

Question Answering
- F1 Score
-
Exact Match

Sentence Similarity

Summarization


Translation
Text Generation
- Perplexity
- KL Divergence
-
Cross Entropy
- PSI
Model Performance Management
The idea of model performance management encompasses managing model performance across the full lifecycle from testing through production. The textbook use of performance metrics normally lacks ideas around daily variability of performance, how to handle delays in ground truth, how much and how often to aggregate samples for performance analysis, how to create baselines and how to trace down changes in model performance.
The production environment in many cases can be quite different from the model building environment. These differences can come about in how ground truth is collected and analyzed.
Ground truth collection can vary greatly which greatly affects performance measurement:
- Semi-real time collection – gather ground truth back in less than 24 hours
- Periodic collection of ground truth – weekly or monthly
- Adhoc collection of ground truth – drip in randomly over periods of weeks
The ideal ML deployment scenario, often what they teach you in the classroom, is when you get fast actionable and fast performance information back on the model as soon as you deploy your model to production.
This ideal view looks something like this:

In this example ground truth is surfaced to you for every prediction and there is a direct link between predictions and ground truth, allowing you to directly analyze the performance of your model in production.
In these cases, and a number of others, the model owner has a significant time horizon for receiving ground truth results for their model’s predictions.
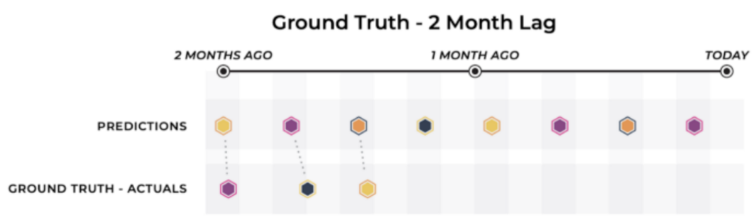
In this above diagram, while we do see that ground truth for the model is eventually determined, the model’s predictions over the last month have not received their corresponding outcomes.
When this ground truth delay is small enough, this scenario doesn’t differ too substantially from real time ground truth, as there is still a reasonable cadence for the model owner to measure performance metrics and update the model accordingly as one would do in the realtime ground truth scenario.
Conclusion
The following sections will go into performance analysis as a practice in more detail and review metrics in more detail.