Built with Arize
Top enterprises and organizations leveraging Arize to achieve better production outcomes
Featured Stories

How Handshake Deployed and Scaled 15+ LLM Use Cases In Under Six Months — With Evals From Day One

How Booking.com Scales AI Observability With Arize AI

How TheFork Leverages Online Evals To Boost Conversions with Arize AX on AWS

PagerDuty + Arize: Building End-to-End Observability for AI Agents in Production

How KW® Oversees the Deployment of AI Agents To 161,000 Affiliated Real Estate Agents

Flag Early, Fix Faster: Real-Time Intervention for Supplier Transfers with Wilma

Inside Typeform's AI Agent Stack

How Nebulock Builds SOTA Agents for Cybersecurity

Hyland’s Path to Predictable AI Agents Across Enterprise Content

How Trunk Tools Transforms the $13 Trillion Construction Industry

Arize AI’s AI Engineering Platform for R&D Selected by AFWERX
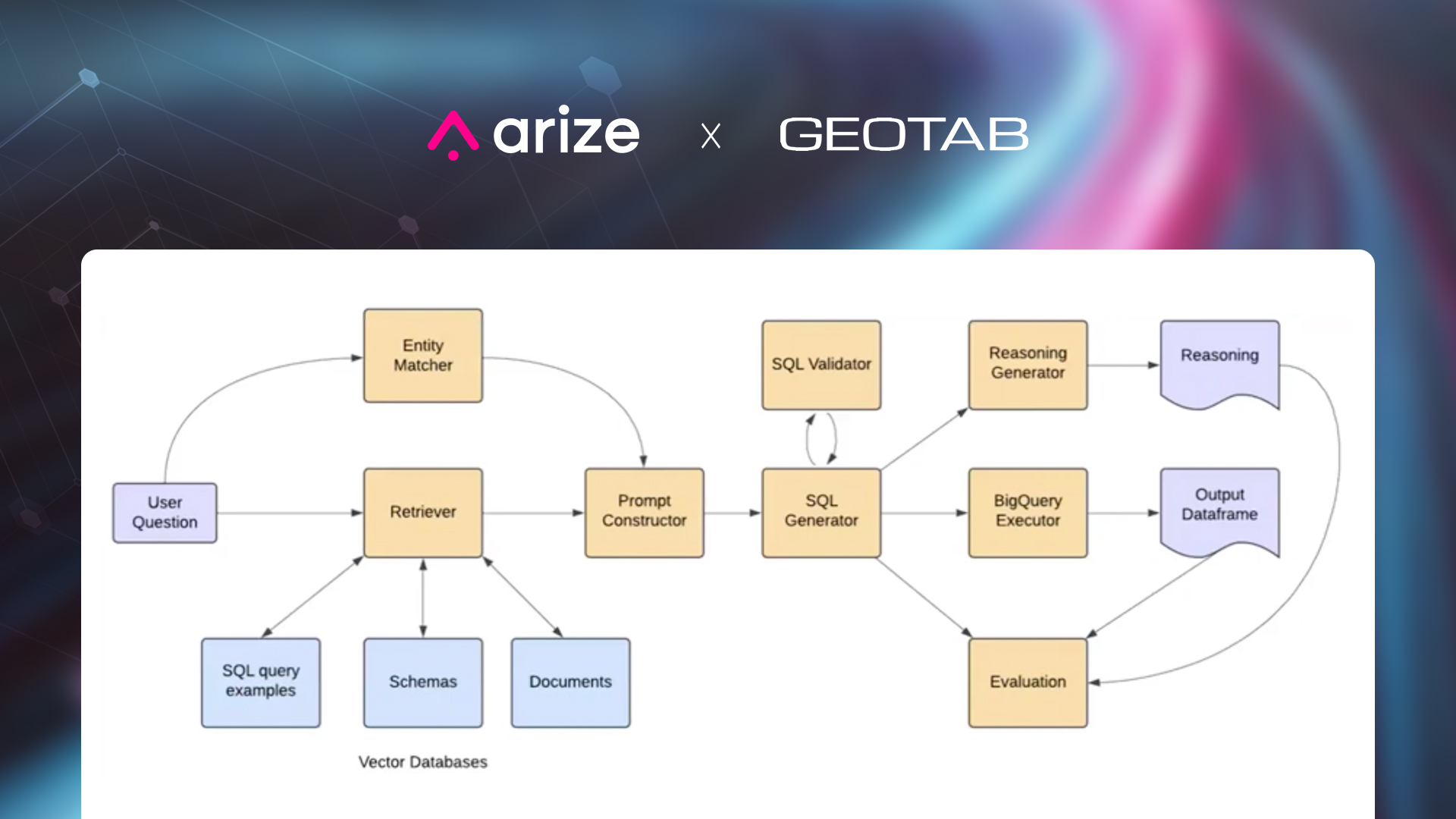
How Geotab and Arize AI Revolutionized Fleet Management with Generative AI

1.4 Billion Smiles: How PepsiCo Scales AI with Purpose

Priceline's Journey Into Evaluating Voice Apps

The Booking team give an inside scoop on how they built a travel agent application—the AI Trip Planner

How Bazaarvoice Navigated the Challenges of Deploying an LLM App

How Atropos Health Accelerates Health Research With LLM Observability

How Flipkart Approaches GenAI Features for 600M+ Users
Customer spotlight



You're in good company













































“As we continue to scale GenAI across PepsiCo’s digital platforms, Arize gives us the visibility, control, and insights essential for building trustworthy, high-performing systems. From early experimentation to deployment, Arize has been instrumental in helping us accelerate, operationalize, and confidently scale our advanced GenAI and computer vision models.”
Charles Holive
SVP, AI Solutions and Platforms, PepsiCo
"As we scale GenAI across Siemens, ensuring accuracy and trust is critical. Arize’s evaluation and monitoring capabilities help us catch potential issues early, giving our teams the confidence to roll out AI responsibly and effectively."
Maximilian Pilz
Head of Applied Artificial Intelligence Solutions, Siemens Digital Industries

“Tripadvisor's billion-plus reviews and contributions are becoming even more important in a world of AI search and recommendations where travel experiences are more conversational, personal and even agentic. As we build out new AI products and capabilities, having the right infrastructure in place to evaluate and observe is important. Arize has been a valuable partner on that front.”
Rahul Todkar
Head of Data and AI, TripAdvisor

"We love Arize for rapid prototyping of LLM projects including Agentic AI Agents. The seamless integration of AI traces, and instrumentation for building evals for LLMOps are a force multiplier for us."
Keller Williams

"At Handshake, ensuring students see the most relevant and qualified job opportunities is core to our mission. Arize gives us the observability we need to understand how these models behave in the wild—tracing outputs, monitoring quality, and managing cost. That visibility lets us iterate quickly and confidently, ensuring our AI systems are both effective and efficient at scale."
Kyle Gallatin
Technical Lead Manager, Machine Learning

"Implementing Arize was one of the most impactful decisions we've made. It completely transformed how we understand and monitor our AI agents—providing deep visibility into every step of their behavior. What started as curiosity quickly became a core part of our workflow. Today, Arize is an essential tool for our team. We use it to test in shadow mode, identify areas for improvement with precision, and move faster with greater confidence. It's saved us countless hours and streamlined our entire development process. As a startup it makes us move faster and saves hours for my team."
Barry Shteiman
CTO, Radiant Security

"Considering nondeterministic nature of AI, visibility that Arize brings is very valuable."
Sreevishnu Nair
Senior Director Architecture and Emerging Technologies

"Our big use case in Arize was around observability and being able to show the value that our AIs bring to the business by reporting outcome statistics into Arize so even non-technical folks can see those dashboards — hey, that model has made us this much money this year, or this client isn’t doing as well there — and get those insights without having to ask an engineer to dig deep in the data."
Lou Kratz
Principle Research Engineer, Bazaarvoice

“Arize observability is pretty awesome!”
Andrei Fajardo
Founding Engineer, LlamaIndex

"For exploration and visualization, Arize is a really good tool."
Rebecca Hyde
Principal Data Scientist, Atropos Health

"From Day 1 you want to integrate some kind of observability. In terms of prompt engineering, we use Arize to look at the traces [from our data pipeline] to see the execution flow … to determine the changes needed there."
Kyle Weston
Lead Data Scientist, GenAI, Geotab

"You have to define it not only for your models but also for your products... There are LLM metrics, but also product metrics. How do you combine the two to see where things are failing? That’s where Arize has been a fabulous partner for us to figure out and create that traceability."
Anusua (Anu) Trivedi
Head of Applied AI, U.S. R&D, Flipkart

"Arize has nurtured an active community of LLMOps learners, professionals, and advocates that I’ve personally found very helpful to (try to) stay on top of new developments."
Peter Leimbigler
Data Science Team Leader, Klick

"We found that the platform offered great exploratory analysis and model debugging capabilities, and during the POC it was able to reliably detect model issues."
Mihail Douhaniaris & Martin Jewell
Senior Data Scientist and Senior MLOps Engineer, GetYourGuide

“Michaelangelo is Uber’s end-to-end ML platform that powers 100% business-critical ML use cases at Uber to deliver a consistent user experience across billions of rides and deliveries. Given the vital role ML plays in this process, it’s critical to have tools that build on Michalangelo’s core capabilities and help us stay ahead of potential production ML problems. We’re excited to work with Arize AI to enhance platform ML observability capabilities and make it easier to detect and resolve model performance issues.”
Kai Wang
Product Lead, Uber AI Platform

"Earlier this year, Wayfair chose Arize as its model monitoring solution...Since model monitoring is a vital component of MLOps, Wayfair’s ML platform team is working closely with Arize AI to develop a long term strategy around onboarding."
Duncan McKinnon
Machine Learning Engineer 2, Wayfair
“The ability to quickly change what we’ve built, understand how it’s different from the previous models and know where it has problems is mission-critical … to our commitment to innovation and leadership in the increasingly privacy-focused advertising environment.”
Alok Kothari
Director of Machine Learning, Adobe
"The team evaluated several options and ultimately chose Arize due to its strong support, effective onboarding process, and commitment to helping us scale up our skills to consistently leverage the tool. Arize will help us further improve our models’ performance, ensure the quality of our data, and maintain fairness and transparency in our machine learning processes."
Valeria Gomes
Data Lead, Zippi
"We recently deployed a model that went from inception to production in 46 days – hardly a small endeavor given the model is relied on to score over 50,000 insurance applications daily. Arize is a big part of that success because we can spend our time building and deploying models instead of worrying – at the end of the day, we know that we are going to have confidence when the model goes live and that we can quickly address any issues that may arise."
Alex Post
Lead Machine Learning Engineer, Clearcover

"Machine learning is a discipline where few notice when everything is performing perfectly — and everyone notices when things go wrong. In that sense, it’s not a question of whether you need ML observability — you do — it’s more a matter of whether to build or buy. For us, Arize was the clear choice in terms of cost efficiency and freeing us up to achieve our broader vision."
Richard Woolston
Data Science Manager, America First Credit Union
“Arize was really the first in-market putting the emphasis firmly on ML observability, and I think why I connect so much to Arize’s mission is that for me observability is the cornerstone of operational excellence in general and it drives accountability.”
Wendy Foster
Director of Engineering and Data Science, Shopify
“Some of the tooling — including Arize — is really starting to mature in helping to deploy models and have confidence that they are doing what they should be doing.”
Anthony Goldbloom
Co-Founder & CEO, Kaggle
"Models are never perfect; they are always going to drift based on changing behaviors, changing data, or changing source systems. Having a centralized monitoring platform like Arize is immensely beneficial."
Malav Shah
Data Scientist II, DirectTV
"Arize really values understanding and helping the data scientist – a platform built by and for tech people – which resonates with our team."
Habib Baluwala
Domain Chapter Lead for Commercial Data, SparkNZ
“The Arize AI platform provides an intuitive UI that’s easy to use and can monitor drift and performance of all models across our most advanced communication deployments.”
Brendon Villalobos
Machine Learning Technical Lead, Twilio
“It is critical to be proactive in monitoring fairness metrics of machine learning models to ensure safety and inclusion. We look forward to testing Arize’s Bias Tracing in those efforts.”
Christine Swisher
VP of Data Science, Project Ronin
“As an organization, we generally build rather than buy – particularly for our AI and machine learning infrastructure. So it’s a high burden to meet, and Arize meets it in terms of helping sophisticated organizations like Shelf Engine that don’t do off-the-shelf data science.”
Stefan Kalb
CEO, Shelf Engine