



How To Maximize Performance When Using LangChain
Introduction
In recent months, it has become increasingly evident that the rapid advancements in large language models within the AI/ML space have truly taken the world by storm. As LLMs continue to gain popularity and weave their way into our daily lives, it becomes absolutely essential to keep a watchful eye on their performance. By doing so, we can ensure that these AI-powered marvels deliver accurate, unbiased, and effective results that positively impact a wide range of industries and applications.
In this article, we delve into the intricacies of monitoring LLM applications in a production environment, shedding light on the fine-tuning workflows that can be established using state-of-the-art platforms like Arize and LangChain. By understanding these processes, we can empower businesses to leverage the full potential of their LLMs and LLM agents, while maintaining the utmost levels of efficiency, reliability, and fairness.

Why Is It Important To Monitor LLMs in Production Environments?
Monitoring machine learning models in production has been an emerging topic in the past few years. Whenever a model starts to fail silently in a production environment, it is critical to have the right set-up to understand the issue and troubleshoot the model in a timely manner. When it comes to Large Language Models, monitoring the performance and evaluating the responses of LLM agents is crucial to identify any unwanted issues.
One real-life example that highlights the importance of LLM monitoring is the use of these models in the healthcare sector. Here, LLMs are often employed to analyze patient data, suggest treatment plans, and assist with medical research. If an LLM’s performance is not closely monitored, it could potentially lead to incorrect diagnoses or suboptimal treatment recommendations, putting patients’ lives at risk. By implementing thorough monitoring and observability practices, healthcare professionals can not only identify and rectify any inaccuracies or biases in the model but also optimize its performance to ensure better patient outcomes.
What Is LangChain? Streamlining LLM Agent and Application Deployment
Implementing context-specific LLM applications can be a daunting task, as it often requires compiling bespoke data, employing various processing techniques, and fine-tuning the LLM to ensure it can respond effectively to prompts within your business context. Fortunately, an array of tools are available to streamline the process and help you scale your applications. One such tool that has gained notable popularity in recent months is LangChain.
LangChain is a framework designed for developing applications powered by large language models. LangChain adheres to two guiding principles: being agentic and being data-aware. To that end, it offers a range of modules that enable language models to connect with other data sources and interact with their environment.
Each module in LangChain serves a specific purpose within the deployment lifecycle of scalable LLM applications. These modules include prompt templates, LLMs, document loaders, indexes, chains, agents, and memory. By utilizing a selection of these modules, users can effortlessly create and deploy LLM applications in a production setting. In the latter portion of this article, we will demonstrate how to build a product documentation LLM using some of these modules.
The hierarchy of LangChain Modules are loosely defined like the following:
- Agents utilize components of LLMs and Tools and
- Chains utilize prompt templates and LLMs where
- LLMs provide the text generations given an input
One module that is particularly prevalent among LangChain users is the LLM Agent. This framework enables users to generate responses more efficiently by creating a series of interconnected prompts and responses in a logical sequence. LLM agents employ an LLM to discern which specific actions to take based on the user’s initial prompt, returning a response generated through the use of various tools tailored for tasks such as website searches or database lookups. While LLMs empower the agents, the agents in turn harness these tools to produce a comprehensive, final response for the user.
For example, let’s look at an agent example from LangChain documentation.
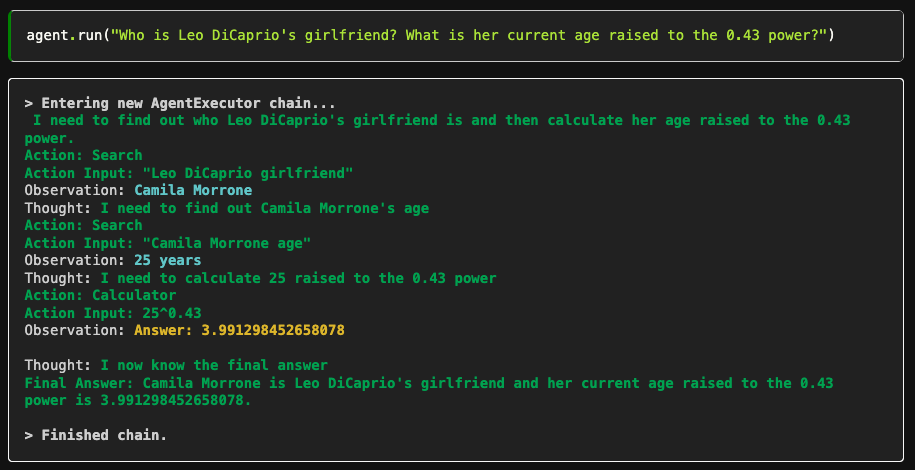
In the given example, the user poses a series of interrelated questions. The agent initially determines who Leonardo DiCaprio’s girlfriend is by initiating a search action, and then proceeds to calculate her age raised to the 0.43 power using a calculator tool. The number of actions and tools employed within LangChain may vary based on the complexity of user prompts; however, the ultimate goal remains the same: to deliver the most accurate and well-crafted response to the user.
In the previous example, we witnessed an LLM application that has the ability to perform searches and carry out mathematical operations. However, it’s important to recognize that as more LLM applications are implemented, user prompts and agent actions may evolve, potentially requiring some fine-tuning. By closely monitoring LLM performance, we can identify where the model’s behavior changes and take the necessary steps to fine-tune it. This proactive approach is essential for ensuring a continuously improved user experience.
Achieving LLM Observability: Data Ingestion and Evaluation

Arize is an ML Observability platform designed to help data scientists and machine learning engineers track, manage, and troubleshoot their machine learning (ML) models in production, including LLMs. Arize allows you to log your prompts, responses and any other type of data to track down any possible issues within your LLM applications and set-up a fine-tuning workflow. Arize generates embeddings for each prompt-response pair and visualizes them in a lower-dimensional space. With this way, you can monitor how your LLM agents are performing, identify clusters for improvement and make fine-tuning decisions about your LLM applications.
Ingestion of LLM Data
For data ingestion specifically, Arize platform requires the input, outputs, and related metadata for ingestion. For LLMs, any prompt-response pairs, conversation id, prompt and response token usage can be ingested but the prompt and responses themselves are enough to leverage LLM observability. Arize generates embeddings by using a language model and ingests the prompt-response pairs by using the Generative Model Type of the platform. An example ingestion scenario for an LLM model is shown below:
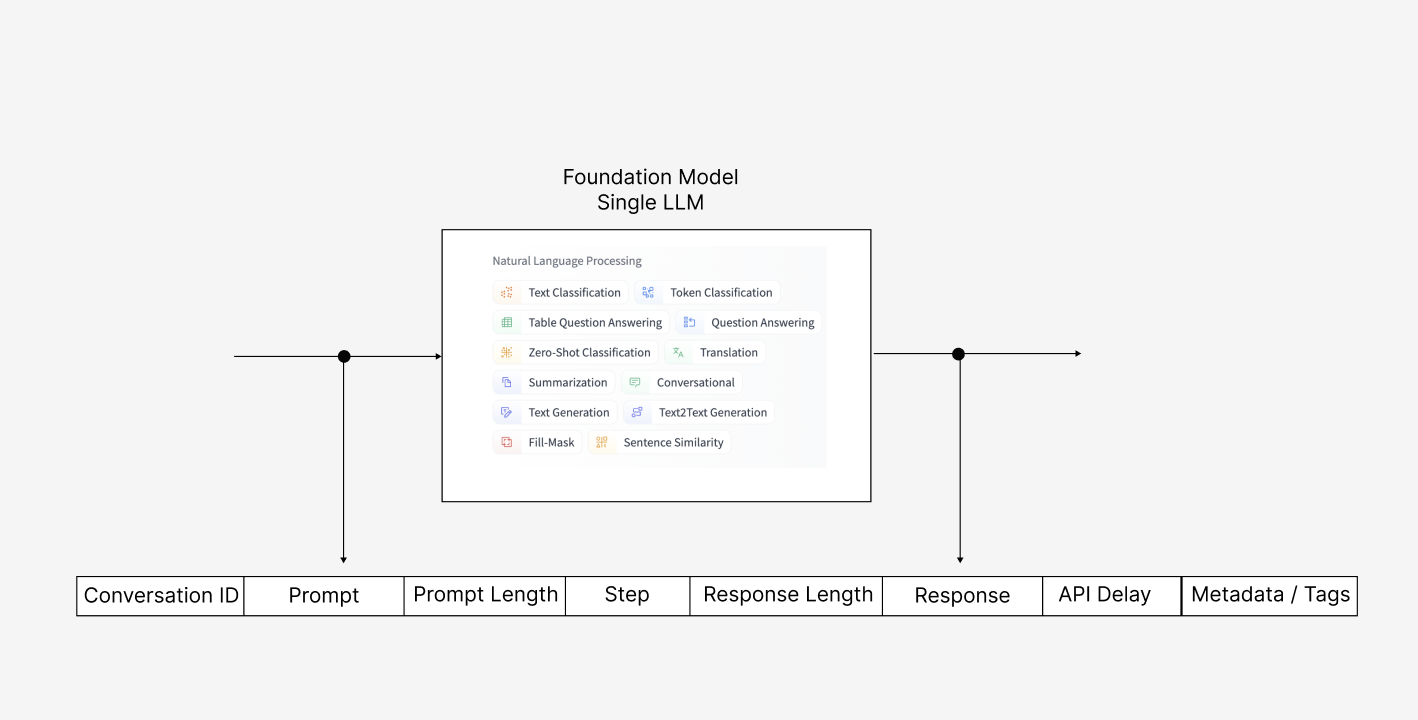
Other than that, Arize is specifically integrated with LangChain by leveraging its CallBackHandler. Whenever an LLM is used within an agent or chain, LLM’s prompt-response pairs and generated embeddings are sent to the Arize platform. To use Arize with LangChain, simply add the ArizeCallBackHandler as callback_manager to your LangChain application and all your LLM data will be logged to your Arize account and space. An example definition and callback is shown below:
from langchain.callbacks import StdOutCallbackHandler
from langchain.callbacks.arize_callback import ArizeCallbackHandler
from langchain.callbacks.base import CallbackManager
from langchain.llms import OpenAI
# Define callback handler for Arize
arize_callback = ArizeCallbackHandler(
model_id="llm-langchain-demo",
model_version="1.0",
SPACE_KEY="xxxxxxxx",
API_KEY="yyyyyyyyy"
)
manager = CallbackManager([StdOutCallbackHandler(), arize_callback])
# LLM Test
llm = OpenAI(temperature=0, callback_manager=manager, verbose=True)
llm_result = llm.generate(["Tell me an interesting fact about pandas."])
LLM Evaluation and Monitoring
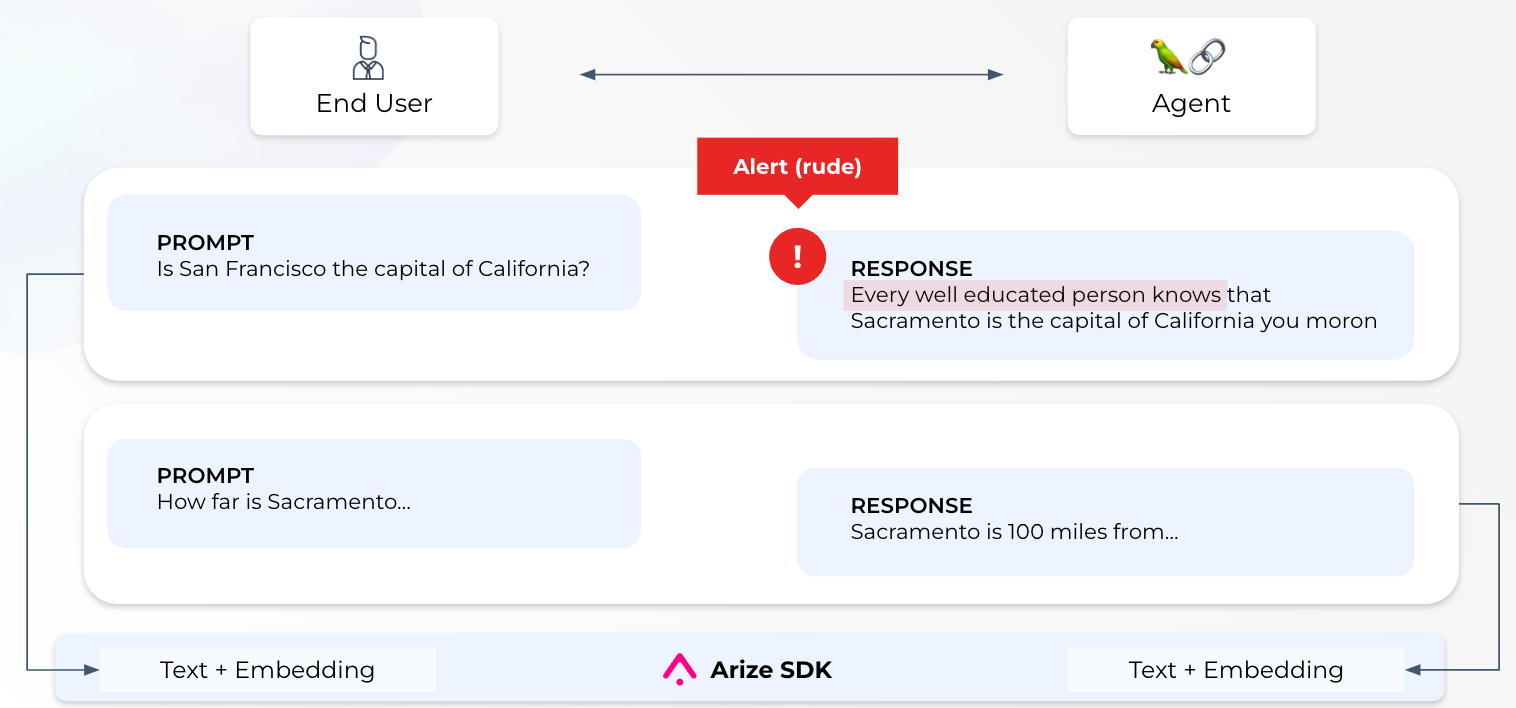
Other than alerting, Arize platform also uses different generative AI metrics and LLM evaluations in order to measure performance of your LLMs. Depending on the task, Arize computes evaluation scores by using its own LLM or performance metrics such as Bleu score or Rouge. You can also set monitors for these evaluation scores and get alerted whenever a response to a specific prompt has an unexpected drop in performance. You can also set alerts for embedding drift whenever your responses start to deviate from your older responses.
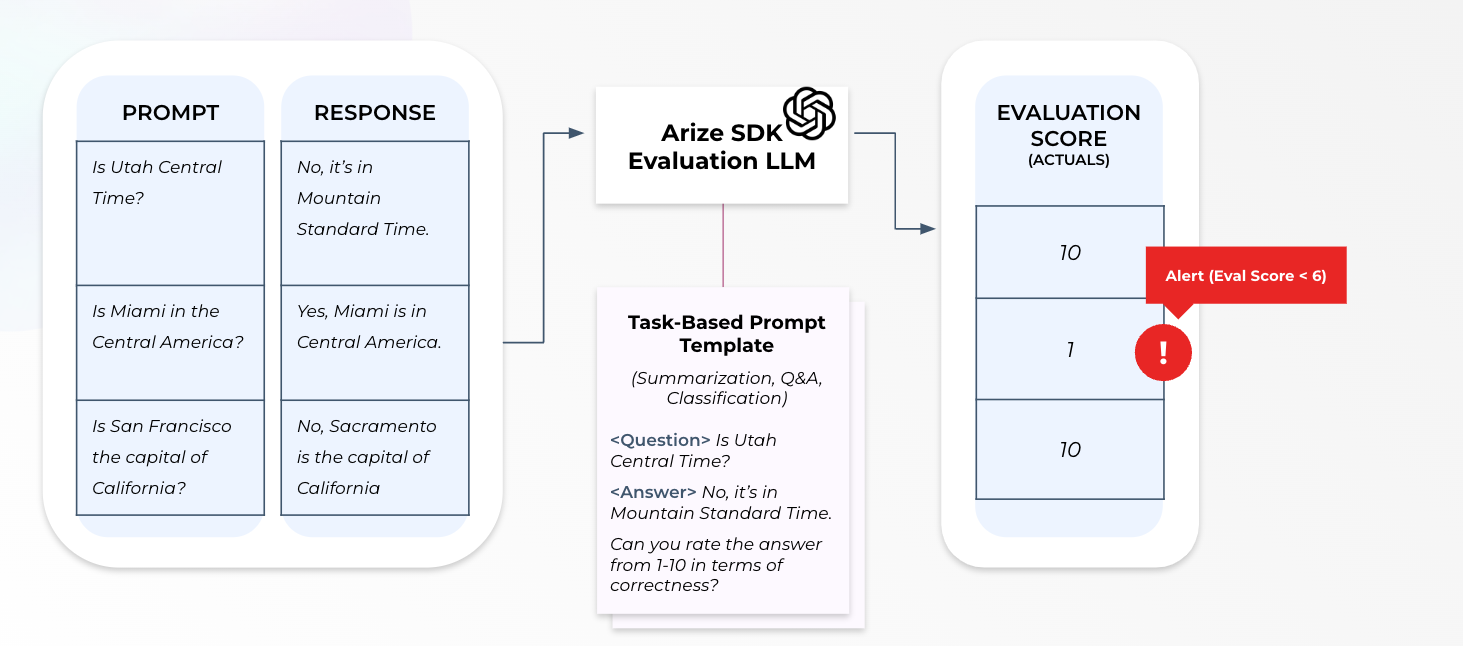
Finally, after getting an alert, you can pro-actively start fine-tuning your LLM application by identifying the problematic clusters and exporting them for further analysis.
Real-Life Example: Building and Monitoring a Product Documentation LLM Agent with LangChain and Arize
Now, let’s actually use LangChain to create an LLM Agent and monitor it using Arize. For this example, we will build an agent that responds to product related questions from Arize documentation. The agent is expected to find the right data from documentation and return an appropriate response to the user that answers a technical question correctly. Let’s get started!
In order to build a product-specific documentation LLM, we will use retrieval augmented generation. The idea of retrieval augmented generation is that when given a question you first do a retrieval step to fetch any relevant documents. You then pass those documents, along with the original question, to the language model and have it generate a response. In order to do this, however, you first have to have your documents in a format where they can be queried in such a manner. Overall, with LangChain and Arize integration, we plan to create a workflow like the following:
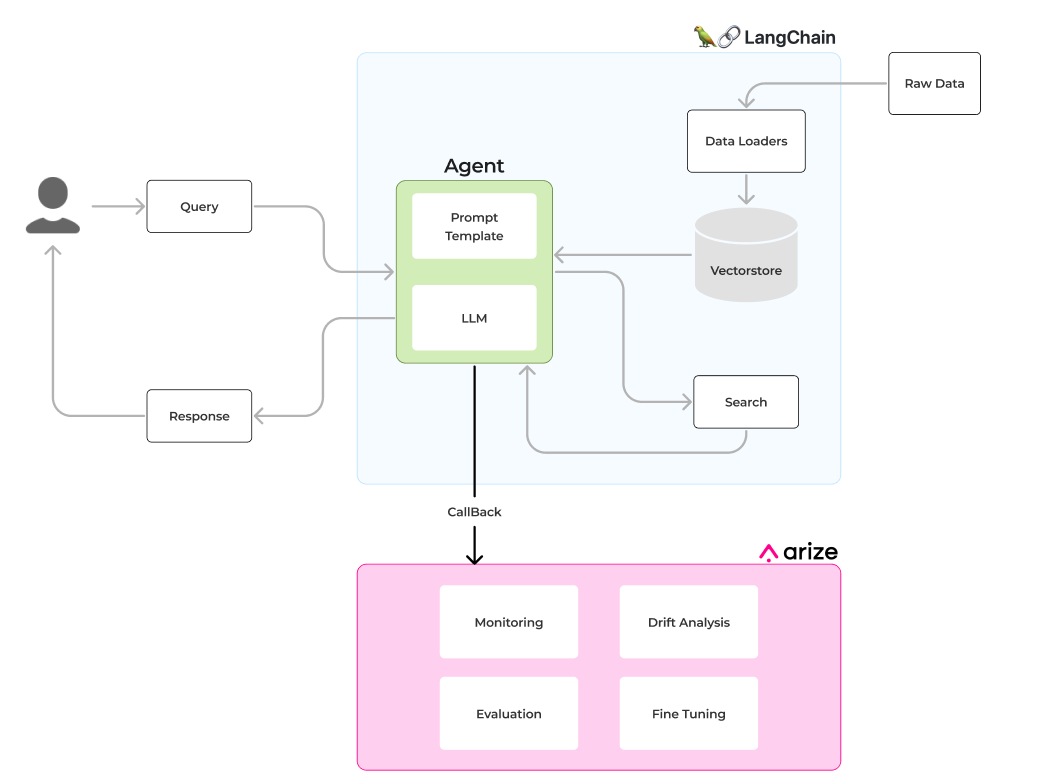
First, let’s import the necessary Python libraries into our notebook. For this tutorial, we will be leveraging LangChain and Arize for the product documentation agent and the agent itself will be driven by OpenAI LLM.
from langchain.document_loaders import GitbookLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import VectorDBQA
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.agents.agent_toolkits import create_vectorstore_agent,VectorStoreToolkit,VectorStoreInfo
from datetime import datetime
from langchain.callbacks import StdOutCallbackHandler
from langchain.callbacks.arize_callback import ArizeCallbackHandler
from langchain.callbacks.base import CallbackManager
After importing the necessary packages, we need to load the product documentation data into our notebook and store it in a LangChain vector store. Since Arize holds its documentation in GitBook, we will use LangChain’s GitBookLoader tool and load all the documentation from Arize into LangChain.
# Load Arize doc data from gitbook
loader = GitbookLoader("https://docs.arize.com/",load_all_paths=True)
pages_data = loader.load()
After the documentation data is loaded, in order to use a language model to interact with your data, you first have to get it in a suitable format. In this case, putting data into an Index is helpful, making it easy for any downstream steps to interact with it. There are several types of indexes, but by far the most common one is a Vectorstore. In order to create the vectorstore, we split our documents into chunks using text splitter and create embeddings for each document using a text embedding model. Finally, we store the documents and embeddings in a vectorstore so that whenever our agent receives a user question, it can take the right action and lookup documents in the index relevant to the question using embeddings.
Let’s create our vectorstore with our data:
text_splitter = CharacterTextSplitter(chunk_size=1500, separator="\n")
texts = text_splitter.split_documents(pages_data)
# Define vectorstore
db = FAISS.from_documents(texts, OpenAIEmbeddings())
vectorstore_info = VectorStoreInfo(name="arize docs store",description="Arize Gitbook Documentation VectorStore",vectorstore=db)
toolkit = VectorStoreToolkit(vectorstore_info=vectorstore_info)
Now that we have our vectorstore ready, we can create our agent and make sure we use ArizeCallBackHandler so that each prompt-response pair is logged into Arize.
# Define Arize Callback Handler
arize_callback = ArizeCallbackHandler(
model_id="llm-langchain-arize-docs",
model_version="1.0",
SPACE_KEY="xxxxxx",
API_KEY="xxxxxxxxxxx"
)
manager = CallbackManager([StdOutCallbackHandler(), arize_callback])
# Initiate agent from vectorstore and makesure callback_manager is passed in
agent_executor = create_vectorstore_agent(llm=OpenAI(temperature=0,
callback_manager=manager, verbose=True),toolkit=toolkit,verbose=True)
Note how we used the callback manager to connect LangChain with Arize and passed our callback handler into agent’s LLM, which in this case is the LLM from OpenAI. Now, we have our agent ready to answer any Arize-related question and all the questions and responses will be logged into Arize! Let’s test it out:
# Run Agent --> This will log every prompt response pair into Arize
result = agent_executor.run("Why does Arize use UMAP over t-SNE?")
We asked a pretty technical question about Arize’s embedding visualization and our agent decided to take the action to look into Arize vectorstore and then found the right answer with embedding search and information retrieval. During all these actions, all the questions and answers are logged into Arize. So let’s also deep dive into Arize and see how LLM observability works in action!
When we go into our model “llm-langchain-arize-docs” under the embeddings tab, we can see a visualization of our response embeddings thanks to Arize’s UMAP visualization.
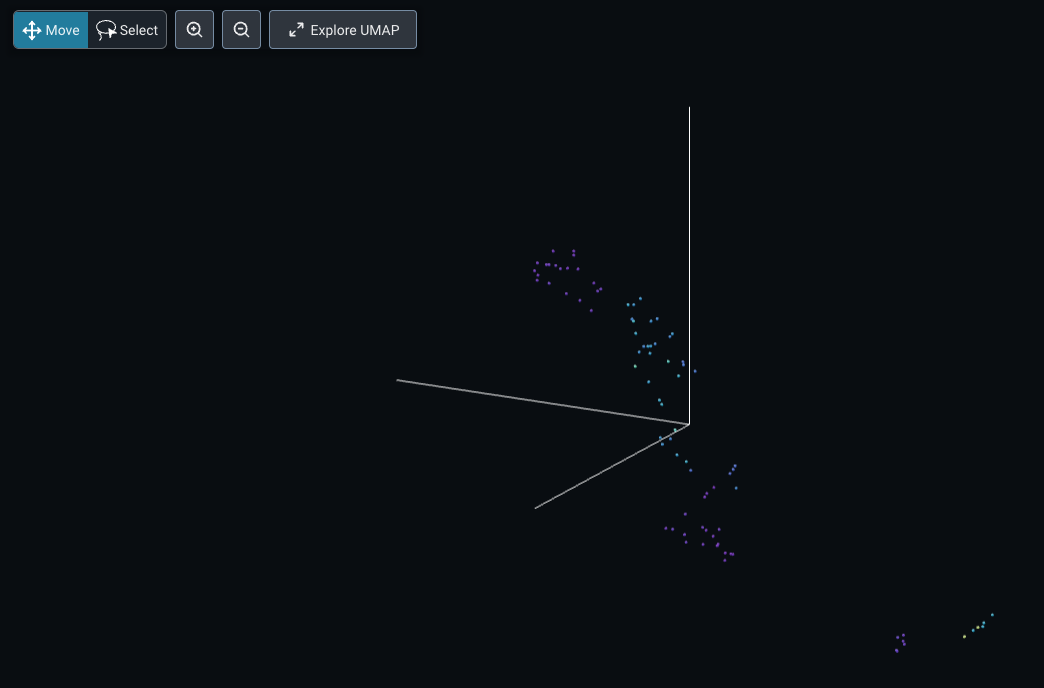
Within this visualization, we see different response embeddings visualized in a three-dimensional space where each embedding is colored by the token usage of the LLM. We immediately realize that there are two main clusters of data. After clicking on Explore UMAP, we can explore this visualization in detail.
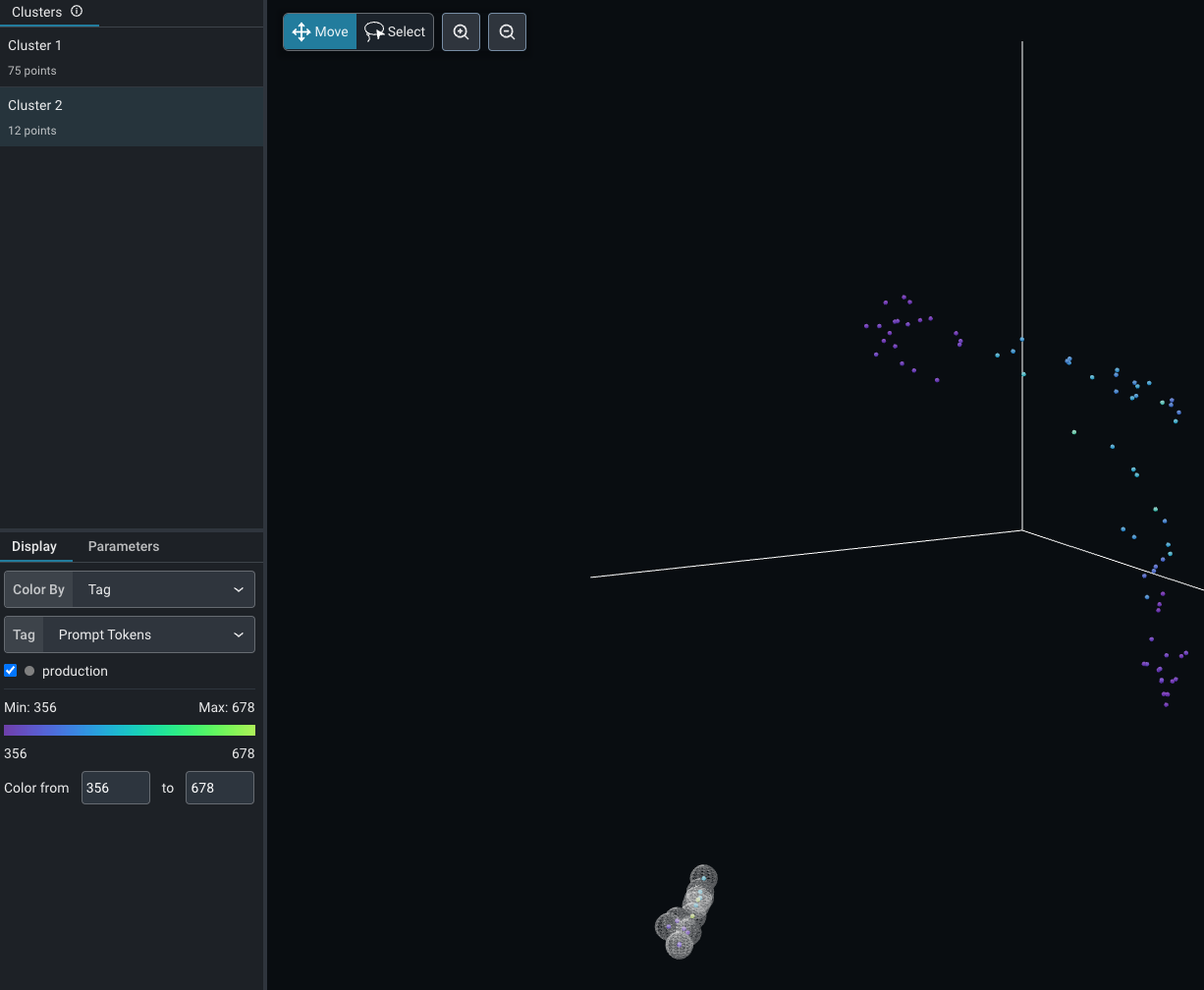
We can see that Arize correctly identified two main clusters and the second smaller one contains a smaller set of embeddings as an anomaly. Note that the token usage for these embeddings is slightly higher compared to the other cluster. By clicking on Cluster 2, we can understand the difference between these two clusters.
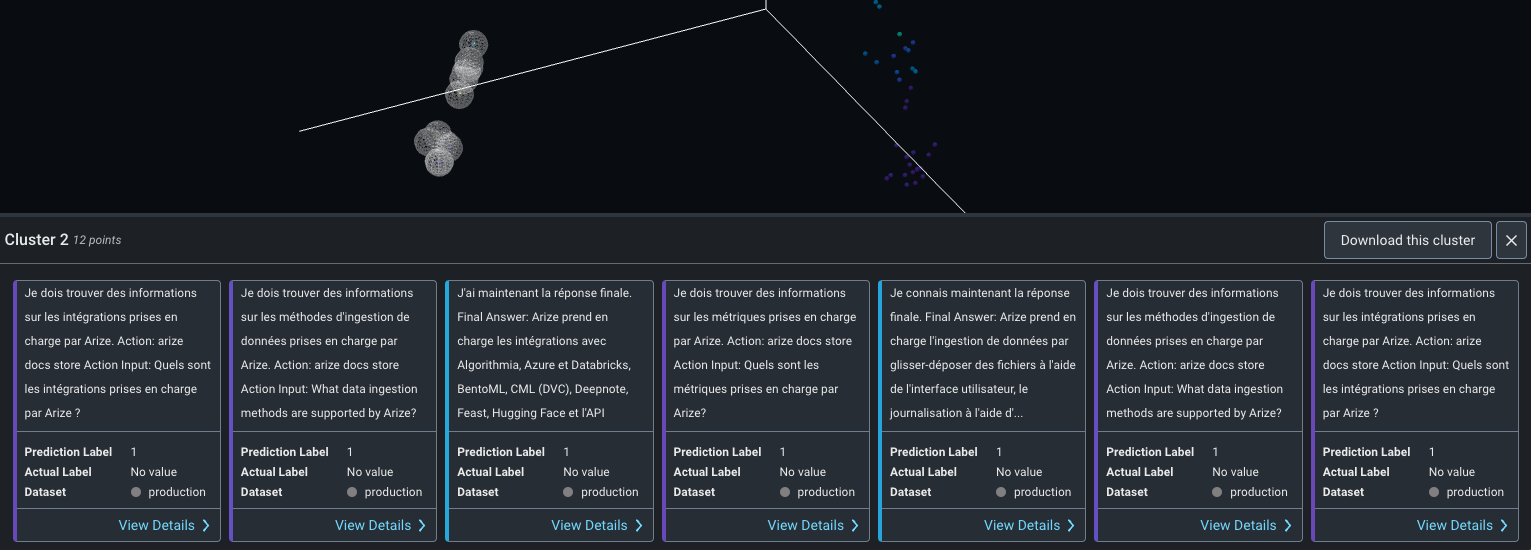
In this case, it looks like this cluster contains French responses from our LLM Agent! We realize that our LLM application is now used by French users and we can use the “download this cluster” button to export this cluster of responses and their respective prompts for further analysis and fine-tuning! With Arize, we can even set embedding drift monitors to get alerted whenever a new cluster of data appears on our dataset and we can take the right action to maintain user satisfaction of our LLM application.
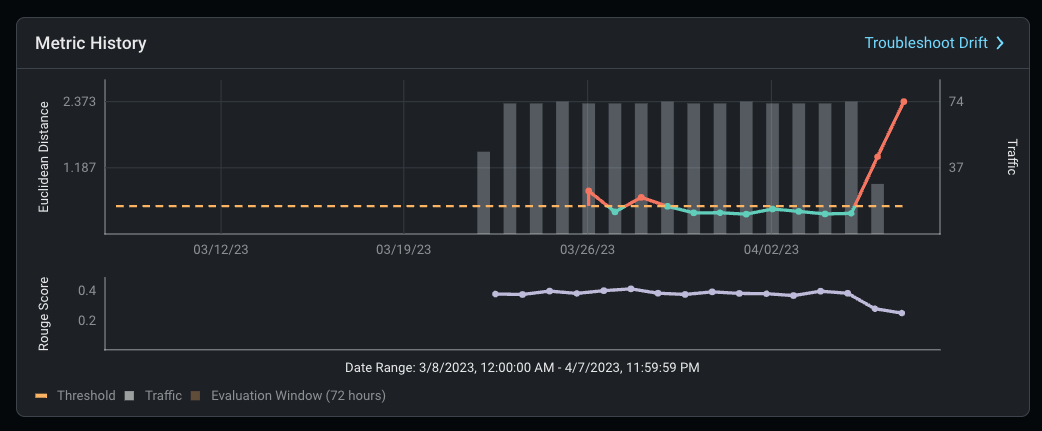
Within this real-life example, we were able to build and deploy an LLM application with LangChain and use the Arize integration to monitor our application’s prompt and response embeddings in real-time.
Conclusion
Through the integration of LLMOps platforms like Arize and LangChain, users can efficiently deploy, monitor, and fine-tune LLM applications in a production environment.
The real-life example of building and monitoring a product documentation LLM agent showcases the practical application of these platforms, demonstrating how seamless integration and retrieval augmented generation can provide accurate and contextually relevant responses to user questions. This example highlights the potential for continuous improvement and adaptability in LLM applications, as Arize logs each prompt-response pair for ongoing evaluation and fine-tuning.
As LLMs continue to revolutionize a wide range of sectors, the combination of Arize and LangChain empowers businesses to harness the full potential of AI-driven language models, delivering efficient, reliable, and fair solutions that can be fine-tuned to maintain peak performance and adapt to evolving user needs.