




ML Infrastructure Tools for Model Building

Aparna Dhinakaran
Co-founder & Chief Product Officer
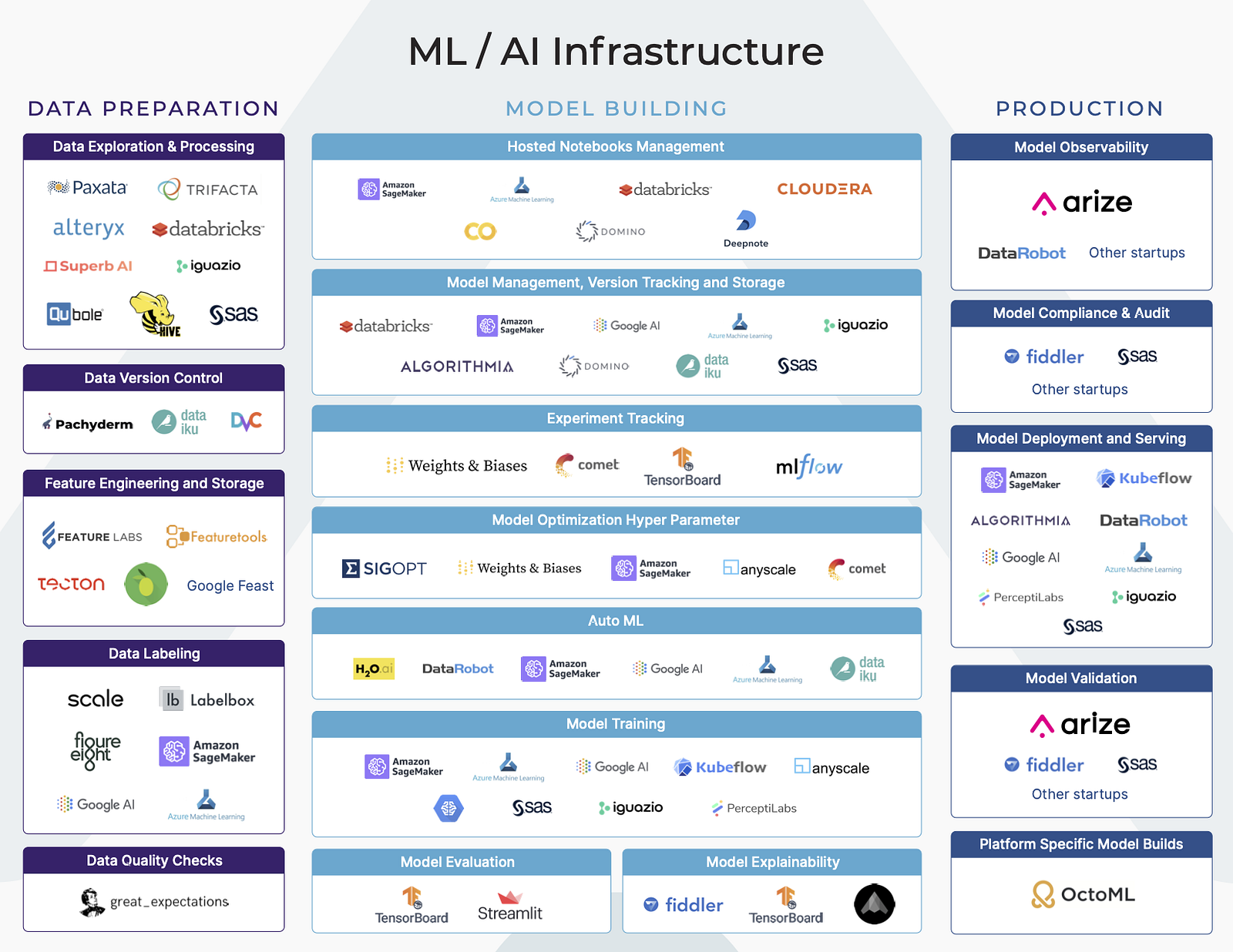
Artificial Intelligence (AI) and Machine Learning (ML) are being adopted by businesses in almost every industry. Many businesses are looking towards ML Infrastructure platforms to propel their movement of leveraging AI in their business. Understanding the various platforms and offerings can be a challenge. The ML Infrastructure space is crowded, confusing, and complex. There are a number of platforms and tools spanning a variety of functions across the model building workflow.
To understand the ecosystem, we broadly break up the machine learning workflow into three stages — data preparation, model building, and production. Understanding what the goals and challenges of each stage of the workflow can help make an informed decision on what ML Infrastructure platforms out there are best suited for your business’s needs.
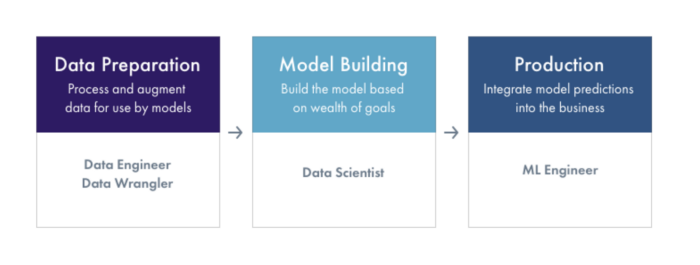
Each of these broad stages of the Machine Learning workflow (Data Preparation, Model Building and Production) have a number of vertical functions. Some of these functions are part of a larger end-to-end platform, while some functions are the main focus of some platforms.
In our last post, we dived in deeper into the Data Preparation part of the ML workflow. In that post, we discussed ML Infrastructure platforms that are focused for data preparation functions. In this post, we will dive deeper into Model Building.
What is Model Building?
The first step of model building begins with understanding the business needs. What business needs is the model addressing? This step begins much further at the planning and ideation phase of the ML workflow. During this phase, similar to the software development lifecycle, data scientists gather requirements, consider feasibility, and create a plan for data preparation, model building, and production. In this stage, they use the data to explore various model building experiments they had considered during their planning phase.
Feature Exploration and Selection
As part of this experimental process, data scientists explore various data input options to select features. Feature selection is the process of finding the feature inputs for machine learning models. For a new model, this can be a lengthy process of understanding the data inputs available, the importance of the input, and the relationships between different feature candidates. There are a number of decisions that can be made here for more interpretable models, shorter training times, cost of acquiring features, and reducing overfitting. Figuring out the right features is a constant iterative process.
ML Infrastructure companies in Feature Extraction: Alteryx/Feature Labs, Paxata(DataRobot)
Model Management
There are a number of modelling approaches that a data scientist can try. Some types of models are better for certain tasks than others (ex — tree based models are more interpretable). As part of the ideation phase, it will be evident if the model is supervised, unsupervised, classification, regression, etc. However, deciding what type of modelling approaches, what hyperparameters, and what features is dependent on experimentation. Some AutoML platforms will try a number of different models with various parameters and this can be helpful to establish a baseline approach. Even done manually, exploring various options can provide the model builder with insights on model interpretability.
Experiment Tracking
While there are a number of advantages and tradeoffs amongst the various types of models, in general, this phase involves a number of experiments. There are a number of platforms to track these experiments, modelling dependencies, and model storage. These functions are broadly categorized as model management. Some platforms primarily focus on experiment tracking. Other companies that have training and/or serving components have model management components for comparing the performance of various models, tracking training/test datasets, tuning and optimizing hyperparameters, storing evaluation metrics, and enabling detailed lineage and version control. Similar to Github for software, these model management platforms should enable version control, historical lineage, and reproducibility.
A tradeoff between these various model management platforms is the cost of integration. Some more lightweight platforms only offer experiment tracking, but can integrate easily with the current environment and be imported into data science notebooks. Others require some more heavy lifting integration and require model builders to move to their platform so there is centralized model management.
In this phase of the machine learning workflow, data scientists usually spend their time building models in notebooks, training models, storing the model weights in a model store, and then evaluating the results of the model on a validation set. There are a number of platforms that exist to provide compute resources for training. There are also a number of storage options for models depending on how teams want to store the model object.
ML Infrastructure AutoML: H20, SageMaker, DataRobot, Google Cloud ML, Microsoft ML
ML Infrastructure companies in Experiment Tracking: Weights and Biases, Comet ML, ML Flow, Domino, Tensorboard
ML Infrastructure companies in Model Management: Domino Data Labs, SageMaker
ML Infrastructure companies in HyperParameter Opt.: Sigopt, Weights and Biases, SageMaker
Model Evaluation
Once an experimental model has been trained on a training data set with the selected features, the model is evaluated on a test set. This evaluation phase involves the data scientist trying to understand the model’s performance and areas for improvement. Some more advanced ML teams will have an automated backtesting framework for them to evaluate model performance on historical data.
Each experiment tries to beat the baseline model’s performance and considers the tradeoffs in compute costs, interpretability, and ability to generalize. In some more regulated industries, this evaluation process can also encompass compliance and auditing by external reviewers to ensure the model’s reproducibility, performance, and requirements.
ML Infrastructure Model Evaluation: Fiddler AI, Tensorboard, Stealth Startups
ML Infrastructure Pre-Launch Validation: Fiddler AI, Arize AI
One Platform to Rule Them All
A number of companies that center on AutoML or model building, pitch a single platform for everything. They are vying to be the single AI platform an enterprise uses across DataPrep, Model Building and Production. These companies include DataRobot, H20, SageMaker and a number of others.
This set splits into a low-code versus developer centric solutions. Datarobot seems to be focused on the no-code/low code option that allows BI or Finance teams to take up DataScience projects. This is in contrast with SageMaker and H20 which seem to cater to either data scientists or developer first teams that are the more common data science organizations today. The markets in both cases are large and can co-exist but it’s worth noting that not all of the ML Infrastructure companies are selling to the same people or teams.
A number of the more recent entrants in the space can be thought as best of breed solutions for a specific part of the ML Infrastructure food chain. The best analog would be the software engineering space, where your software solutions GitHub, IDE, production monitoring are not all the same end-to-end system. There are reasons why they are different pieces of software; they provide very different functions with clear differentiation.
Challenges
Unlike the software development parallel, reproducibility of models is often considered a challenge. This is primarily due to lack of version control on the data that the model was trained on.
There are a number of challenges in understanding the model’s performance. How can one compare experiments and determine which version of the model is the best balance of performance and tradeoffs? One trade off might be wanting maybe slightly less performing models, but are more interpretable. Some data scientists use built-in model explainability features or explore feature importance using SHAP/LIME.
Another performance challenge is not knowing how your model performance in this experimental stage will translate to the real world. This can be best mitigated with making sure the data in the training data set is a representative distribution to data the model is likely to see in production to prevent overfitting to the training data set. This is where cross validation and backtesting frameworks are helpful.
What happens next?
For a data scientist, it’s important to determine a criteria for when the model is ready to be pushed to production. If there is a pre-existing model deployed in production, it might be when the new version’s performance is higher. Regardless, setting a criterion is important to actually move the experiment to a real world environment.
Once the model has been trained, the model image/weights are stored in a model store. This is usually when the data scientist or engineer responsible for deploying the model into production can fetch the model and use for serving. In some platforms, this deployment can be even simpler and a deployed model can be configured with a REST API that external services can call.
Up Next
We’ll be doing a deeper dive into ML Infrastructure companies in the production segment of the ML Workflow.
Contact Us
If this blog post caught your attention and you’re eager to learn more, follow us on Twitter and Medium! If you’d like to hear more about what we’re doing at Arize AI, reach out to us at contacts@arize.com. If you’re interested in joining a fun, rockstar engineering crew to help make models successful in production, reach out to us at jobs@arize.com!