



In our latest AI research paper reading, we hosted Tara Bogavelli, Machine Learning Engineer at ServiceNow, to discuss her team’s recent work on AgentArch, a new benchmark designed to evaluate and compare AI agent architectures across real-world enterprise workflows.
As Tara described, the motivation behind AgentArch is to “move benchmarking closer to reality.” Instead of synthetic puzzles, it measures performance in environments that mirror how enterprise workflows behave in production.
🎥 Watch the Talk
Evaluating Agent Architectures with AgentArch — Tara Bogavelli, ServiceNow
Highlights from the Talk
(Edited for clarity and brevity)
Tara Bogavelli:
“Most current benchmarks focus on static Q&A. But enterprise agents don’t live in a vacuum, they interact with systems, APIs, and people simultaneously.”
“AgentArch is designed to replicate that reality. It’s a set of benchmark environments that stress-test agents on planning, tool use, and memory the exact things that fail silently in production.”
“The hardest part isn’t getting an agent to respond — it’s getting it to stay coherent across steps. That’s where most architectures break.”
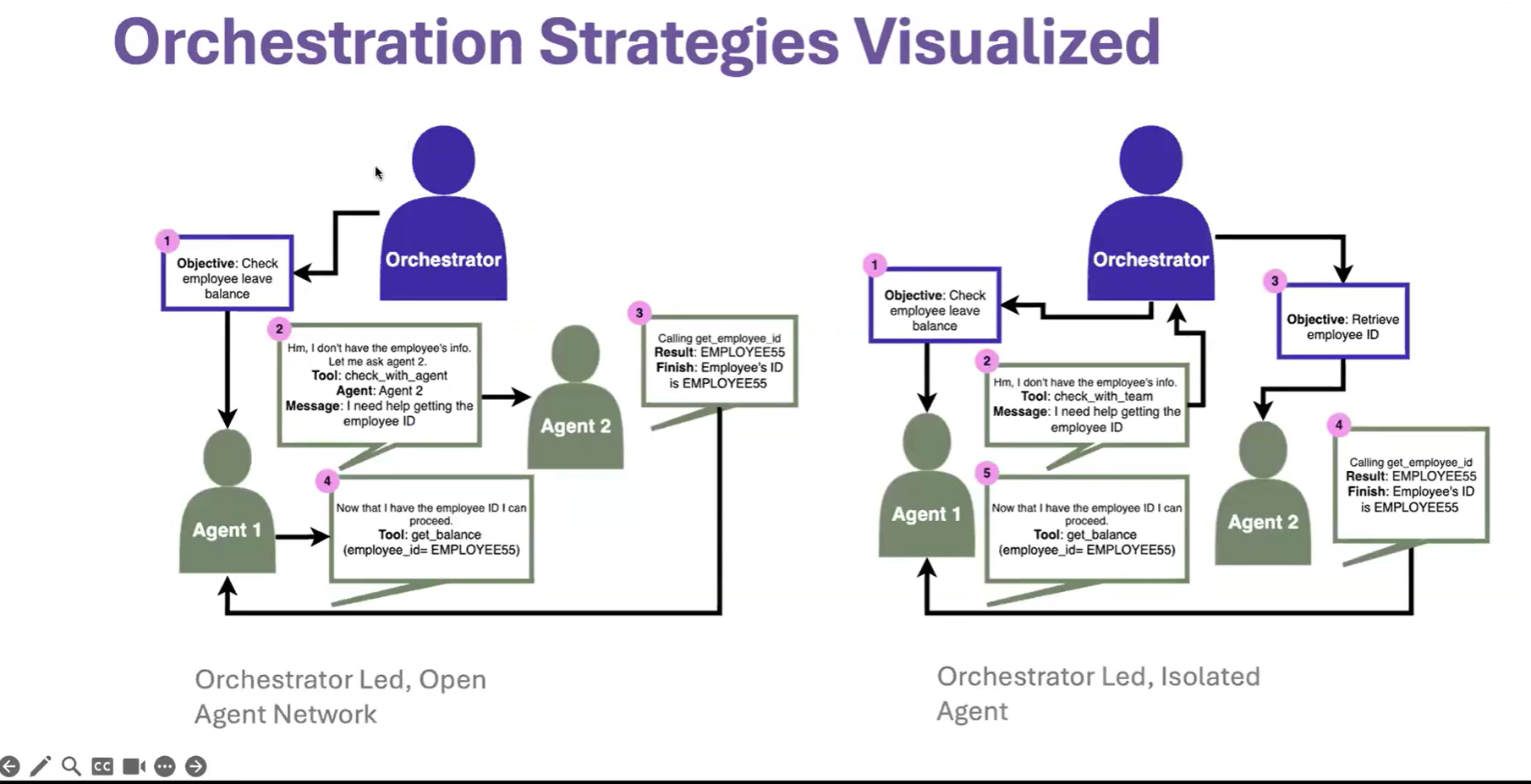
What Is AgentArch?
Tara Bogavelli:
“AgentArch is a modular benchmarking suite for agentic systems operating inside enterprise software ecosystems. It’s built to evaluate how agents actually behave in workflow environments — not just whether they can answer correctly in isolation.”
The framework measures performance across several axes that mirror real enterprise behavior:
- Task Completion Rate
“We wanted to look at end-to-end task success — does the agent finish what it started across multiple workflow steps, rather than just get one answer right?”
- Adaptability
“Agents have to recover gracefully when something changes — maybe an API fails or a workflow state shifts. That recovery ability is a big part of what we test.”
- Tool Calibration
“Most agents over- or under-use tools. We measure how efficiently an agent chooses, uses, and releases external APIs or integrations.”
- Long-Horizon Coherence
“An agent might seem smart for a few turns, but can it stay consistent over 20? Coherence across long sequences is where architectures usually break down. We wanted a benchmark that rewards persistence and context management – not just flashy one-liners or high BLEU scores.”
Why Enterprise Benchmarks Matter
Tara Bogavelli:
“Enterprise workflows have dependencies and friction that research benchmarks just don’t capture,” Tara noted. “Latency, authentication, compliance — all those things shape whether an agent can actually get work done.”
“A lot of agent benchmarks collapse in complexity once they touch real systems with service dependencies and approval flows. An agent that works in a sandbox can completely fail when it encounters an authentication timeout or a partially completed ticket. Those are the moments that define real-world robustness.”
“AgentArch helps us see those failures earlier — and measure them systematically.”

Practical Recommendations
Tara Bogavelli:
“Always benchmark in context — inside simulators that mimic production workflows,” Tara emphasized. “A smaller, well-planned agent can outperform a giant LLM if it’s disciplined about planning.”
“Measure workflow success, not token accuracy. You care about completed processes, not perfect phrasing.”
“And add environmental noise. Random interruptions or delays show you which agents actually hold up.”

Audience Q&A
Q: How does AgentArch differ from benchmarks like SWE-Agent or WebArena?
A: “Those benchmarks are incredible, but they’re task-oriented. AgentArch is workflow-oriented. It’s less about a single job and more about how agents coordinate multiple systems.”
Q: Can AgentArch evaluate closed-source models used internally?
A: “Yes. It’s model-agnostic. You can plug in your own API key, agent loop, or planner. The idea is to compare architecture patterns, not providers.”
Q: What’s next for AgentArch?
A: “We’re expanding to measure collaboration, how multiple agents share state and delegate tasks efficiently. That’s the next frontier for enterprise AI.”