Legacy Evaluator: This evaluator is from phoenix-evals 1.x and will be removed in a future version. You can migrate the template to a custom evaluator as shown below.
When To Use Q&A Eval Template
This Eval evaluates whether a question was correctly answered by the system based on the retrieved data. In contrast to retrieval Evals that are checks on chunks of data returned, this check is a system level check of a correct Q&A.
- input: This is the question the Q&A system is running against
- output: This is the answer from the Q&A system.
- reference: This is the context to be used to answer the question, and is what Q&A Eval must use to check the correct answer
Q&A Eval Template
You are given a question, an answer and reference text. You must determine whether the
given answer correctly answers the question based on the reference text.
<data>
<question>
{input}
</question>
<reference>
{reference}
</reference>
<answer>
{output}
</answer>
</data>
Your response must be a single word, either "correct" or "incorrect",
and should not contain any text or characters aside from that word.
"correct" means that the question is correctly and fully answered by the answer.
"incorrect" means that the question is not correctly or only partially answered by the
answer.
How To Run the Q&A Eval
from phoenix.evals import ClassificationEvaluator
from phoenix.evals.llm import LLM
QA_TEMPLATE = """You are given a question, an answer and reference text. You must determine whether the
given answer correctly answers the question based on the reference text.
<data>
<question>
{input}
</question>
<reference>
{reference}
</reference>
<answer>
{output}
</answer>
</data>
"correct" means that the question is correctly and fully answered by the answer.
"incorrect" means that the question is not correctly or only partially answered by the answer."""
qa_evaluator = ClassificationEvaluator(
name="qa_correctness",
prompt_template=QA_TEMPLATE,
model=LLM(provider="openai", model="gpt-4o"),
choices={"incorrect": 0, "correct": 1},
)
result = qa_evaluator.evaluate({
"input": "What is the capital of France?",
"reference": "Paris is the capital and largest city of France.",
"output": "The capital of France is Paris."
})
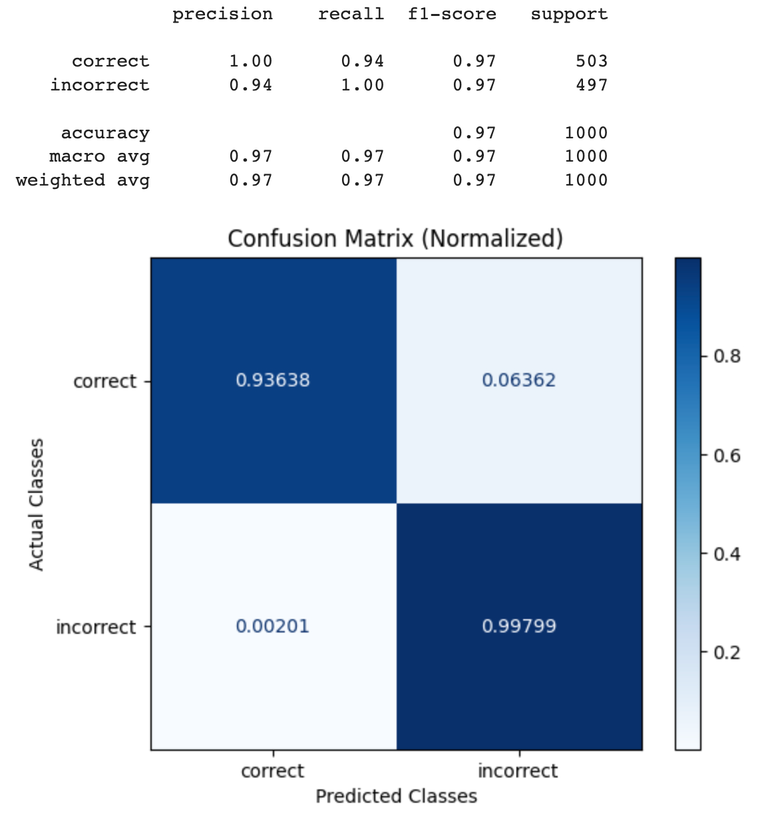
Benchmark Results
The benchmarking dataset used was created based on:
- Squad 2: The 2.0 version of the large-scale dataset Stanford Question Answering Dataset (SQuAD 2.0) allows researchers to design AI models for reading comprehension tasks under challenging constraints. https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/reports/default/15785042.pdf
- Supplemental Data to Squad 2: In order to check the case of detecting incorrect answers, we created wrong answers based on the context data. The wrong answers are intermixed with right answers.
Each example in the dataset was evaluating using the QA_PROMPT_TEMPLATE above, then the resulting labels were compared against the ground truth in the benchmarking dataset.
Google Colab
colab.research.google.com
GPT-4 Results
| Q&A Eval | GPT-4o | GPT-4 |
|---|
| Precision | 1 | 1 |
| Recall | 0.89 | 0.92 |
| F1 | 0.94 | 0.96 |
| Throughput | GPT-4 |
|---|
| 100 Samples | 124 Sec |