Legacy Evaluator: This evaluator is from phoenix-evals 1.x and will be removed in a future version. You can migrate the template to a custom evaluator as shown below.
When To Use Summarization Eval Template
This Eval helps evaluate the summarization results of a summarization task. The template variables are:
- document: The document text to summarize
- summary: The summary of the document
Summarization Eval Template
You are comparing a summary to its original document and trying to determine
if the summary is good. Here is the data:
<data>
<summary>
{output}
</summary>
<original_document>
{input}
</original_document>
</data>
Compare the summary above to the original document and determine if the summary is
comprehensive, concise, coherent, and independent relative to the original document.
Your response must be a single word, either "good" or "bad", and should not contain any text
or characters aside from that. "bad" means that the summary is not comprehensive,
concise, coherent, and independent relative to the original document. "good" means the
summary is comprehensive, concise, coherent, and independent relative to the original document.
How To Run the Summarization Eval
from phoenix.evals import ClassificationEvaluator
from phoenix.evals.llm import LLM
SUMMARIZATION_TEMPLATE = """You are comparing a summary to its original document and trying to determine
if the summary is good. Here is the data:
<data>
<summary>
{output}
</summary>
<original_document>
{input}
</original_document>
</data>
Compare the summary above to the original document and determine if the summary is
comprehensive, concise, coherent, and independent relative to the original document.
"bad" means that the summary is not comprehensive, concise, coherent, and independent relative to the original document.
"good" means the summary is comprehensive, concise, coherent, and independent relative to the original document."""
summarization_evaluator = ClassificationEvaluator(
name="summarization",
prompt_template=SUMMARIZATION_TEMPLATE,
model=LLM(provider="openai", model="gpt-4o"),
choices={"bad": 0, "good": 1},
)
result = summarization_evaluator.evaluate({
"input": "Original document text here...",
"output": "Summary text here..."
})
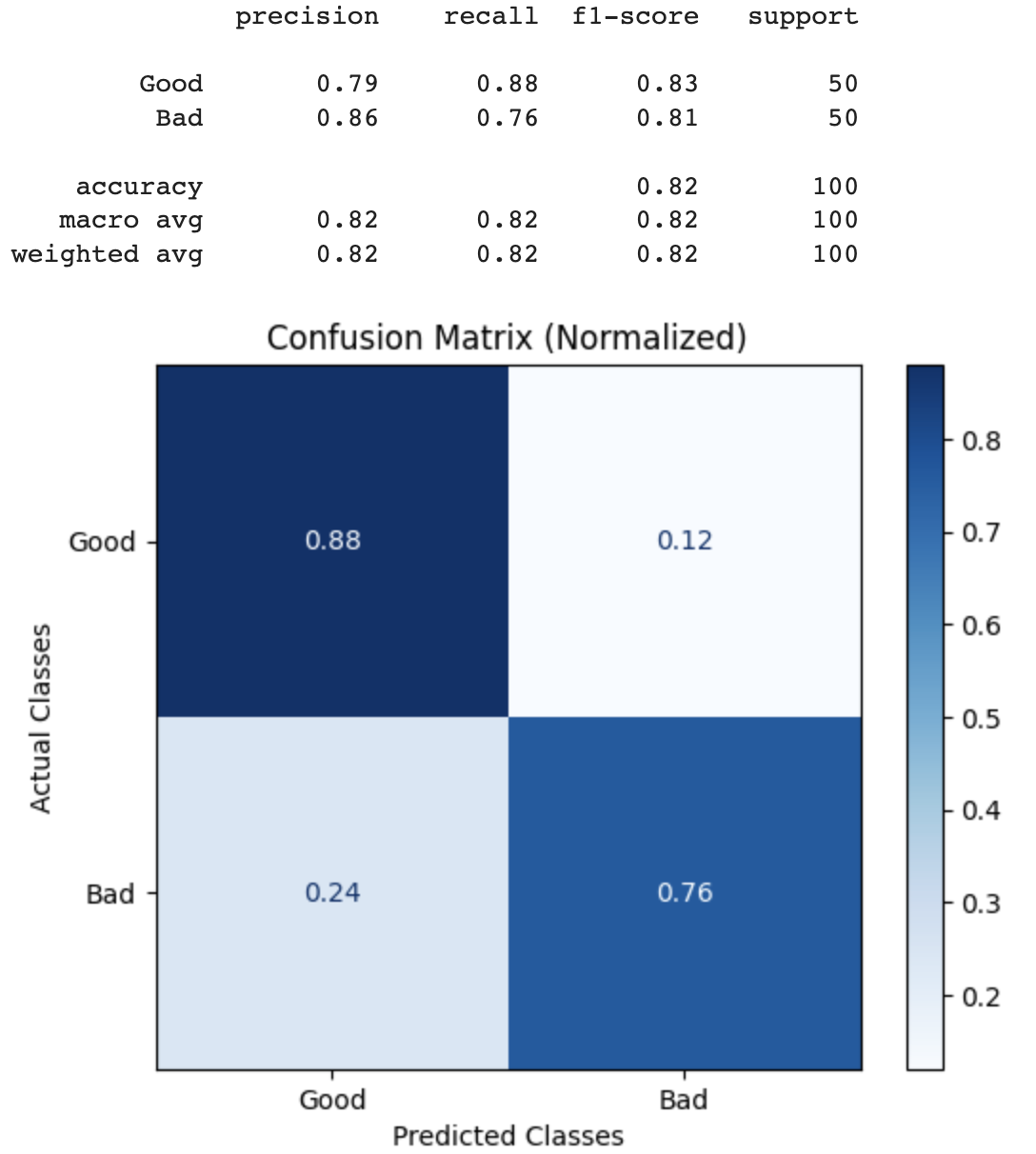
Benchmark Results
This benchmark was obtained using notebook below. It was run using a Daily Mail CNN summarization dataset as a ground truth dataset. Each example in the dataset was evaluating using the SUMMARIZATION_PROMPT_TEMPLATE above, then the resulting labels were compared against the ground truth label in the summarization dataset to generate the confusion matrices below.
Google Colab
colab.research.google.com
GPT-4 Results
| Eval | GPT-4o | GPT-4 |
|---|
| Precision | 0.87 | 0.79 |
| Recall | 0.63 | 0.88 |
| F1 | 0.73 | 0.83 |