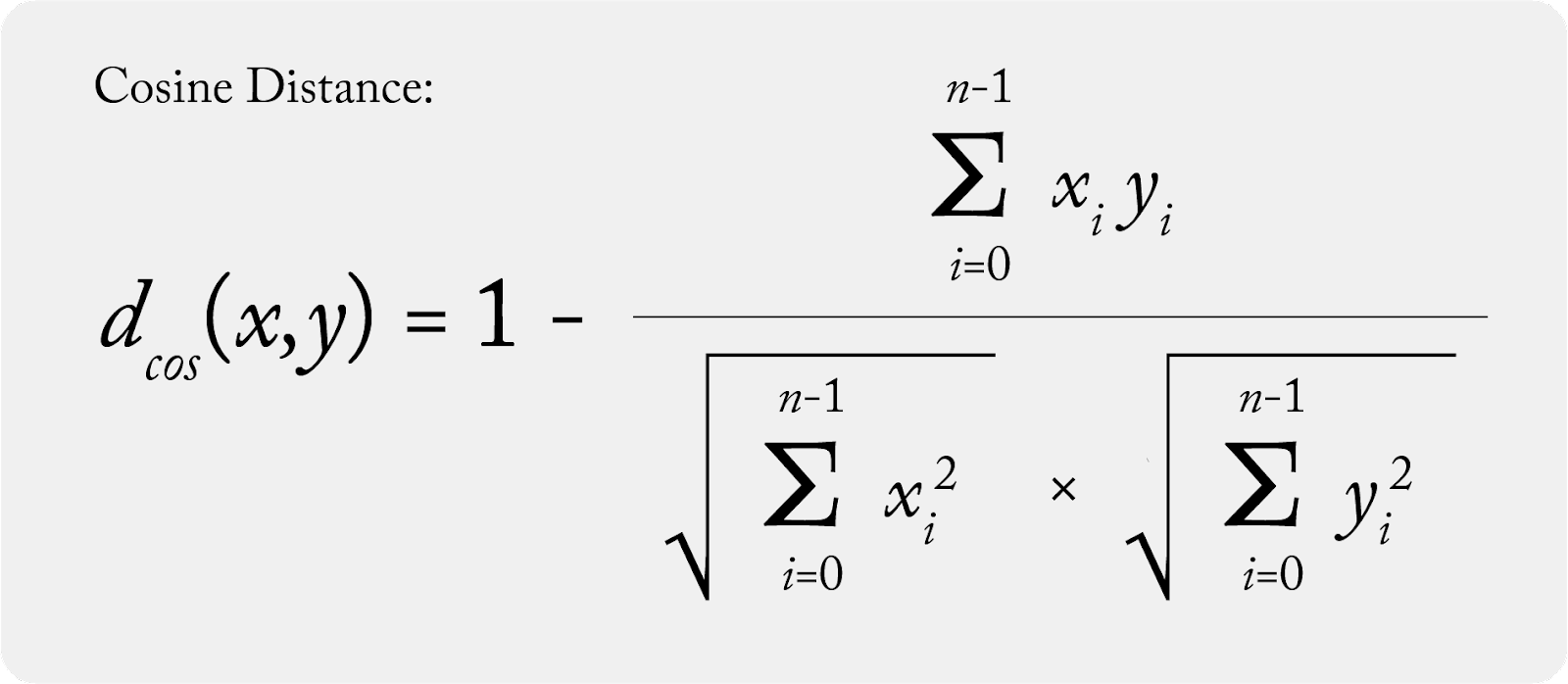Cosine similarity, a key concept in machine learning, measures the cosine of the angle between two non-zero vectors in a multi-dimensional space, thus providing a metric for assessing their directional similarity. In practical terms, this similarity metric is crucial when comparing the orientation rather than the magnitude of vectors, commonly used in high-dimensional data analysis. For instance, in natural language processing, cosine similarity helps determine the likeness in semantic orientation of word embeddings.
The concept of cosine distance, calculated as 1 minus the cosine similarity, serves to quantify the dissimilarity between vectors. This metric is particularly useful when assessing the degree of change or anomaly in machine learning models, such as comparing a production vector (a current model state) against a baseline vector (an established standard or previous model state). A smaller cosine distance implies greater similarity, meaning the current model state closely aligns with the baseline. Conversely, a larger distance signals significant deviation, often prompting further investigation or adjustment in model parameters.