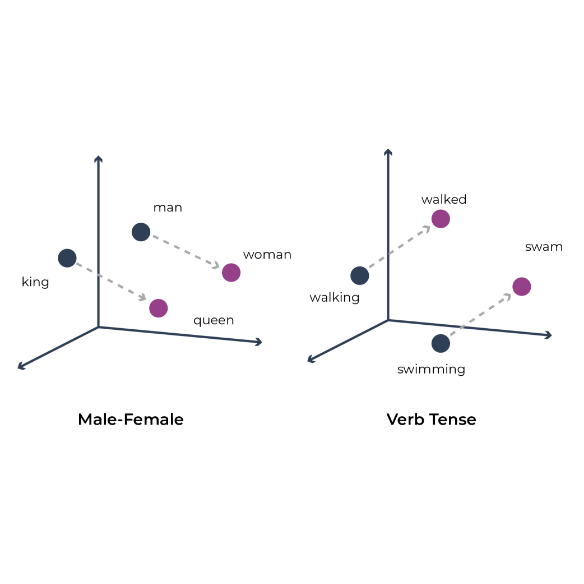
Embeddings are dense, low-dimensional representations of high-dimensional data. They are an extremely powerful tool for input data representation, compression, and cross-team collaboration. Distances between embedding vectors capture similarity between different datapoints, and can capture essential concepts in the original input.
Example:
In natural language processing (see definition of ‘natural language processing), embedding is a term used for the representation of words for text analysis, typically in the form of a real-valued vector that encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning.
Embeddings can also represent images, audio signals, and even large chunks of structured data. Embeddings are everywhere in modern deep learning such as transformers, recommendation engines, SVD matrix decomposition, layers of deep neural networks, encoders and decoders.