



April was a big month for Arize, with updates designed to make building, evaluating, and managing your models and prompts even easier. From larger dataset runs in Prompt Playground to new evaluation features, image segmentation support, and a streamlined Python SDK, there’s a lot to explore.
Here’s a look at everything we shipped.
Larger Dataset Runs in Prompt Playground
We’ve increased the row limit for datasets in the playground, so you can run prompts in parallel on up to 100 examples.
Evaluations on Experiments
You can now create and run evals on your experiments from the UI. Compare performance across different prompt templates, models, or configurations without code. More here.
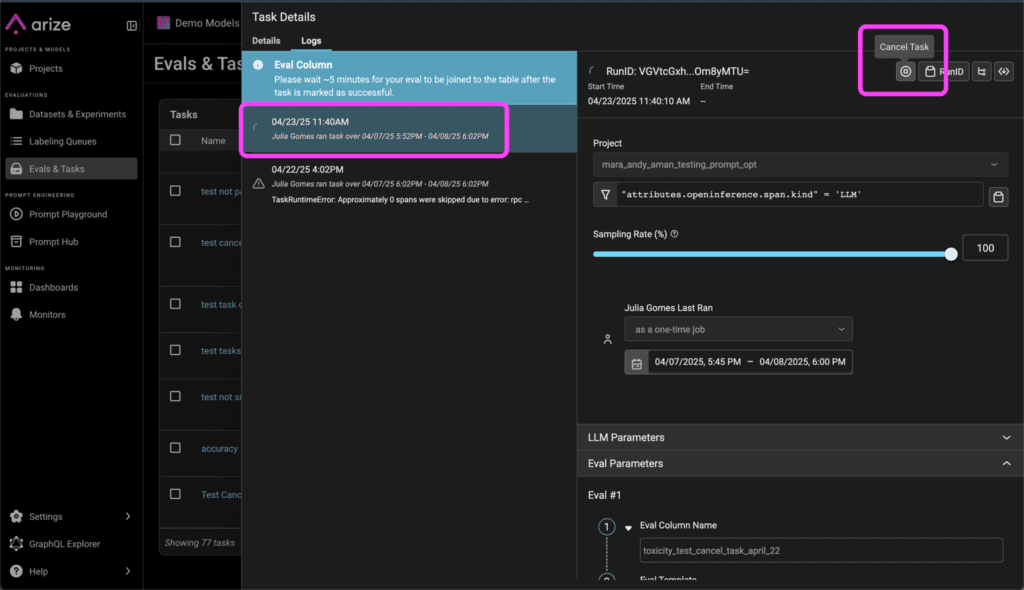
Cancel Running Background Tasks
When running evaluations using background tasks, you can now cancel them mid-flight while observing task logs. More here.
Improved UI Functions in Prompt Playground
We’ve made it easier to view, test, and validate your tool calls in prompt playground. More here.

Compare Prompts Side by Side
Compare the outputs of a new prompt and the original prompt side-by-side. Tweak model parameters and compare results across your datasets. More here.
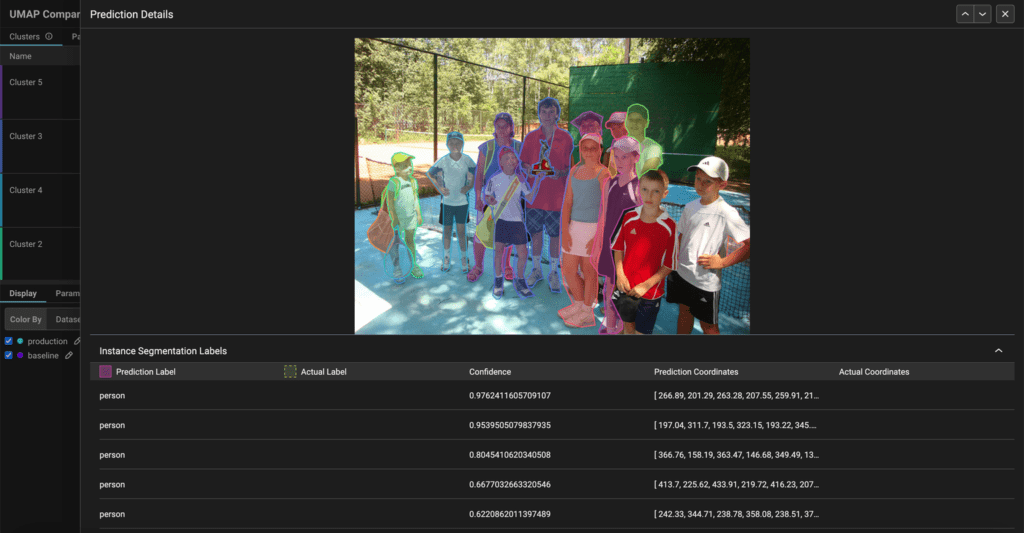
Image Segmentation Support for CV Models
We now support logging image segmentation to Arize. Log your segmentation coordinates and compare your predictions vs. your actuals. More here.
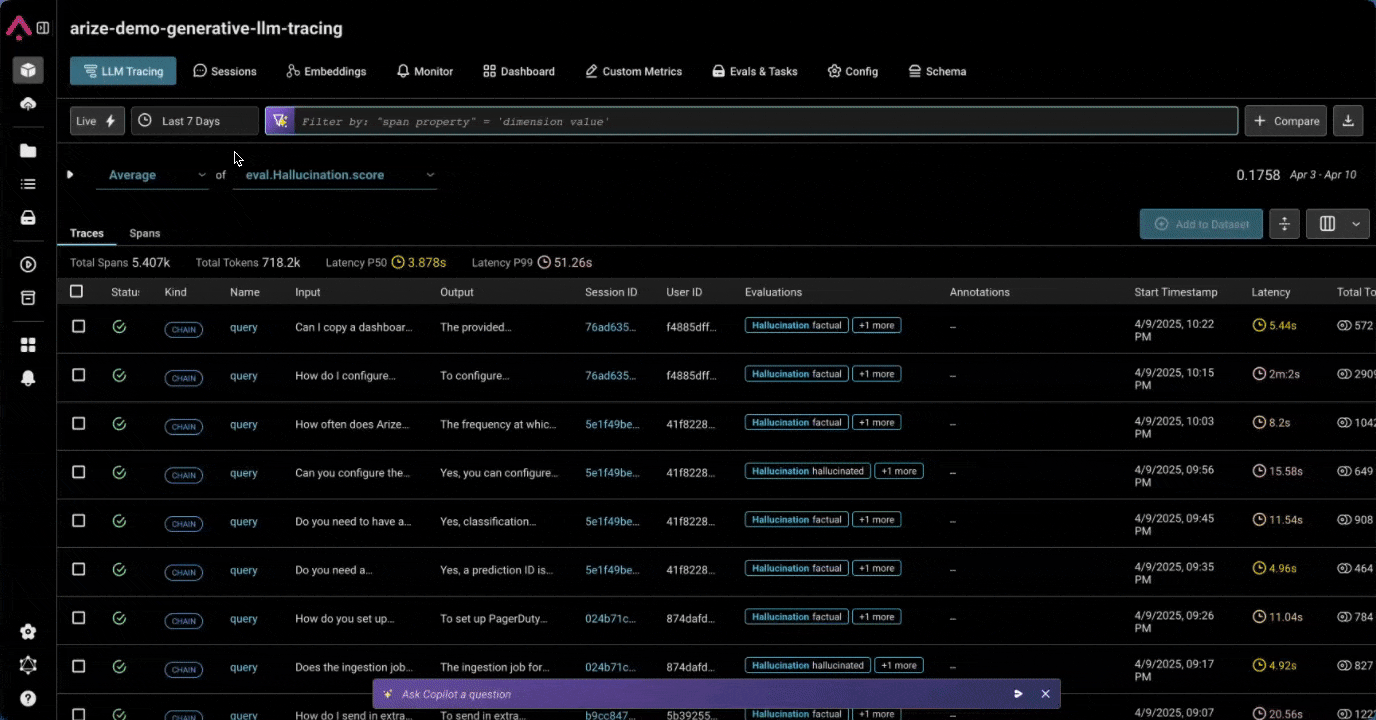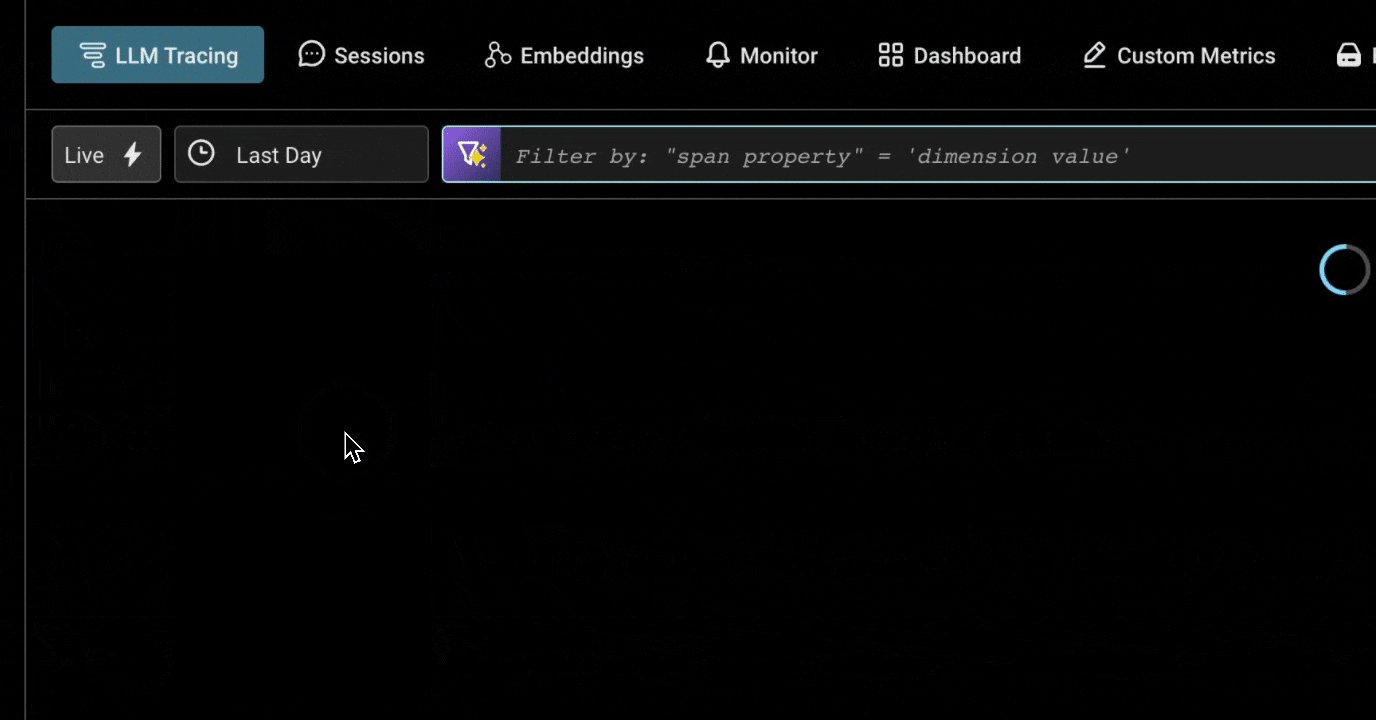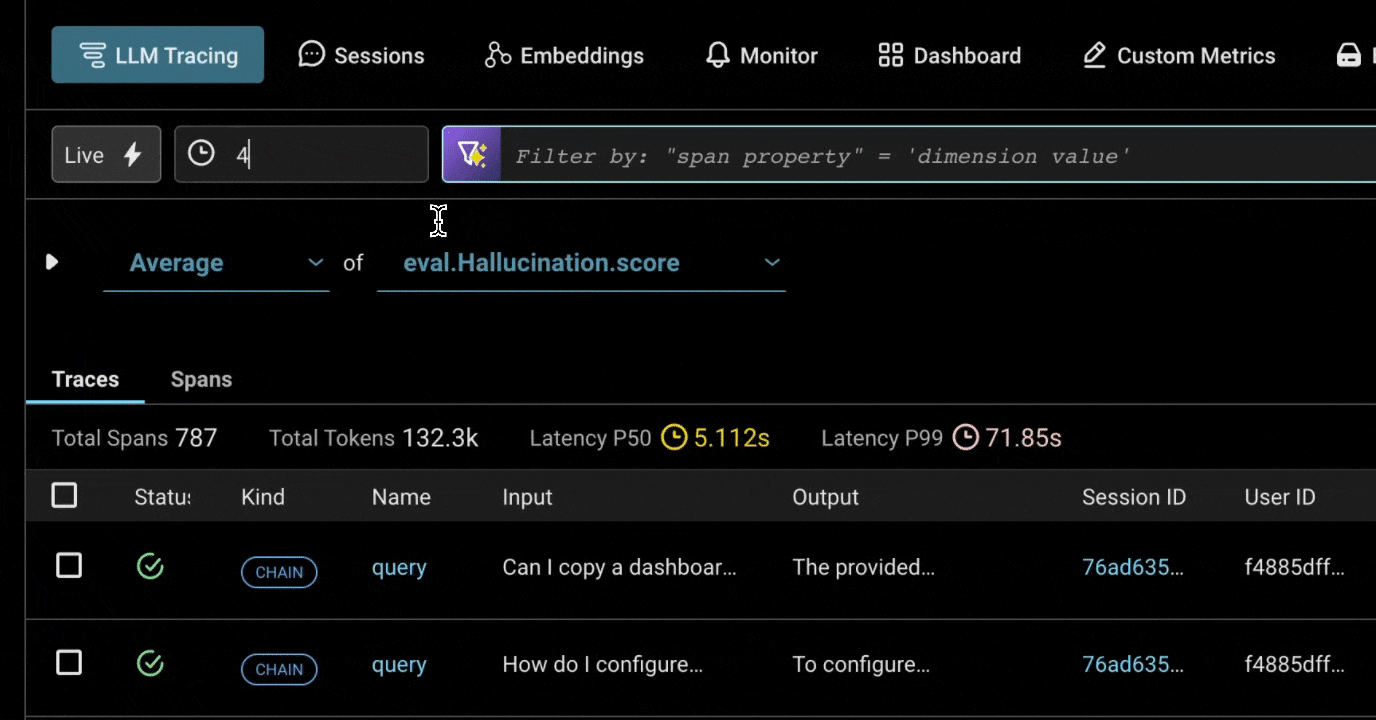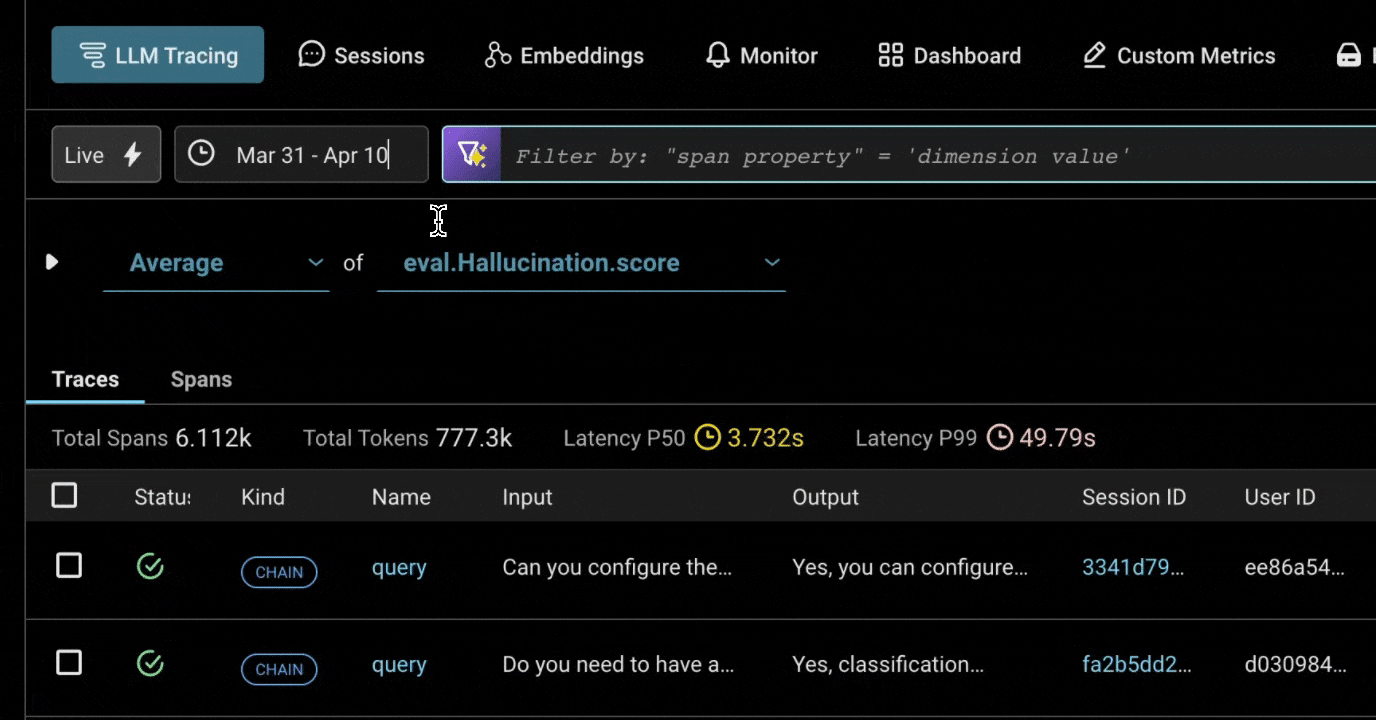
New Time Selector on Your Traces
We’ve made it way easier to drill into specific time ranges, with quick presets like “last 15 minutes” and custom shorthand for specific dates and times, such as 10d, 4/1 – 4/6, 4/1 3:00am. More here.
Prompt Hub Python SDK
Access and manage your prompts in code with support for OpenAI and VertexAI. More here.
pip install "arize[PromptHub]"
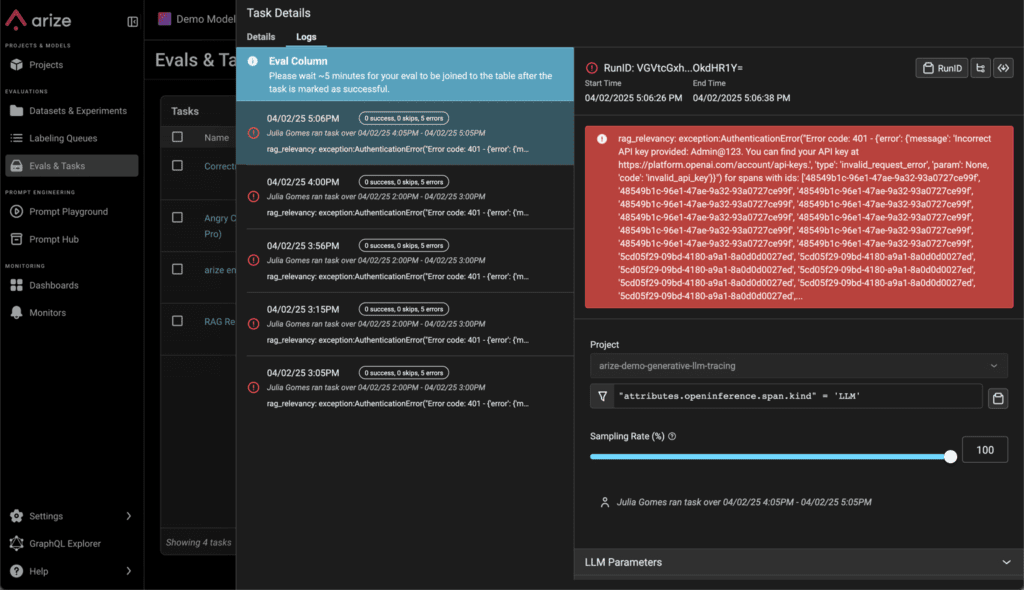
View Task Run History and Errors
Get full visibility into your evaluation task runs, including when it ran, what triggered it, and if there were errors. More here.
Run Evals and Tasks Over a Date Range
Easily run your online evaluation tasks over historical data.
More Resources
- See all updates in our Changelog
- Explore the Arize documentation